3.3.3 YOLOv3 Model Example Introduction
Example Overview
The YOLOv3 object detection example is a Python interface development code example located in /app/pydev_demo/06_yolov3_sample/, demonstrating how to use the YOLOv3 model for object detection tasks. This example shows how to perform object detection on static images, identify multiple objects in the image, and draw detection boxes with confidence information on the image.
Effect Demonstration
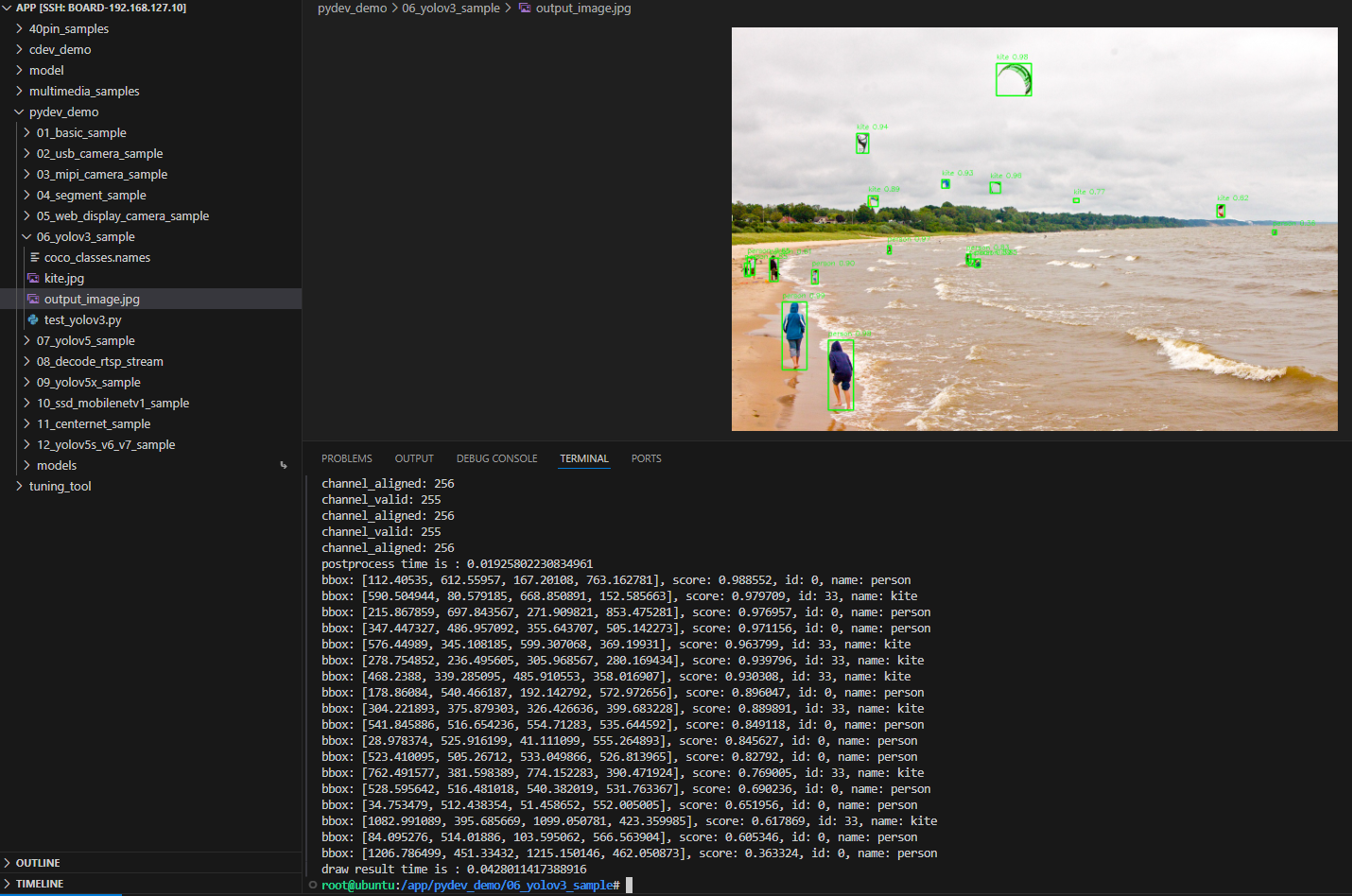
Hardware Preparation
Hardware Connection
This example only requires the RDK development board itself, without additional peripheral connections. Ensure the development board is properly powered and the system is booted.

Quick Start
Code and Board Location
Navigate to /app/pydev_demo/06_yolov3_sample/ location, where you can see the YOLOv3 example contains the following files:
root@ubuntu:/app/pydev_demo/06_yolov3_sample# tree
.
├── coco_classes.names
├── kite.jpg
└── test_yolov3.py
Compilation and Execution
The Python example does not require compilation and can be run directly:
Execution Effect
After running, the program will load the pre-trained YOLOv3 model, perform object detection on the kite.jpg image, and generate the result image output_image.jpg with detection boxes.
root@ubuntu:/app/pydev_demo/06_yolov3_sample# ./test_yolov3.py
[BPU_PLAT]BPU Platform Version(1.3.6)!
[HBRT] set log level as 0. version = 3.15.55.0
[DNN] Runtime version = 1.24.5_(3.15.55 HBRT)
[A][DNN][packed_model.cpp:247][Model](2025-09-10,10:35:11.677.325) [HorizonRT] The model builder version = 1.23.5
[W][DNN]bpu_model_info.cpp:491][Version](2025-09-10,10:35:12.46.71) Model: yolov3_vargdarknet_416x416_nv12. Inconsistency between the hbrt library version 3.15.55.0 and the model build version 3.15.47.0 detected, in order to ensure correct model results, it is recommended to use compilation tools and the BPU SDK from the same OpenExplorer package.
tensor type: NV12
data type: uint8
layout: NCHW
shape: (1, 3, 416, 416)
3
tensor type: int32
data type: int32
layout: NHWC
shape: (1, 13, 13, 255)
tensor type: int32
data type: int32
layout: NHWC
shape: (1, 26, 26, 255)
tensor type: int32
data type: int32
layout: NHWC
shape: (1, 52, 52, 255)
inferece time is : 0.020566940307617188
channel_valid: 255
channel_aligned: 256
channel_valid: 255
channel_aligned: 256
channel_valid: 255
channel_aligned: 256
postprocess time is : 0.01925802230834961
bbox: [112.40535, 612.55957, 167.20108, 763.162781], score: 0.988552, id: 0, name: person
bbox: [590.504944, 80.579185, 668.850891, 152.585663], score: 0.979709, id: 33, name: kite
bbox: [215.867859, 697.843567, 271.909821, 853.475281], score: 0.976957, id: 0, name: person
bbox: [347.447327, 486.957092, 355.643707, 505.142273], score: 0.971156, id: 0, name: person
bbox: [576.44989, 345.108185, 599.307068, 369.19931], score: 0.963799, id: 33, name: kite
bbox: [278.754852, 236.495605, 305.968567, 280.169434], score: 0.939796, id: 33, name: kite
bbox: [468.2388, 339.285095, 485.910553, 358.016907], score: 0.930308, id: 33, name: kite
bbox: [178.86084, 540.466187, 192.142792, 572.972656], score: 0.896047, id: 0, name: person
bbox: [304.221893, 375.879303, 326.426636, 399.683228], score: 0.889891, id: 33, name: kite
bbox: [541.845886, 516.654236, 554.71283, 535.644592], score: 0.849118, id: 0, name: person
bbox: [28.978374, 525.916199, 41.111099, 555.264893], score: 0.845627, id: 0, name: person
bbox: [523.410095, 505.26712, 533.049866, 526.813965], score: 0.82792, id: 0, name: person
bbox: [762.491577, 381.598389, 774.152283, 390.471924], score: 0.769005, id: 33, name: kite
bbox: [528.595642, 516.481018, 540.382019, 531.763367], score: 0.690236, id: 0, name: person
bbox: [34.753479, 512.438354, 51.458652, 552.005005], score: 0.651956, id: 0, name: person
bbox: [1082.991089, 395.685669, 1099.050781, 423.359985], score: 0.617869, id: 33, name: kite
bbox: [84.095276, 514.01886, 103.595062, 566.563904], score: 0.605346, id: 0, name: person
bbox: [1206.786499, 451.33432, 1215.150146, 462.050873], score: 0.363324, id: 0, name: person
draw result time is : 0.0428011417388916
root@ubuntu:/app/pydev_demo/06_yolov3_sample#
Detailed Introduction
Example Program Parameter Options Description
The YOLOv3 object detection example does not require command line parameters and can be run directly. The program will automatically load the kite.jpg image in the same directory for detection processing.
Software Architecture Description
The software architecture of the YOLOv3 object detection example includes the following core components:
-
Model Loading: Using the pyeasy_dnn module to load the pre-trained YOLOv3 model
-
Image Preprocessing: Converting input images to the required NV12 format and specified dimensions (416x416) for the model
-
Model Inference: Calling the model for forward computation to generate feature maps
-
Post-processing: Using the libpostprocess library to parse model outputs and generate detection results
-
Result Visualization: Drawing detection bounding boxes and category information on the original image
-
Result Saving: Saving the visualized results as image files

API Process Description
-
Model Loading: models = dnn.load('../models/yolov3_416x416_nv12.bin')
-
Image Preprocessing: Adjusting image dimensions and converting to NV12 format
-
Model Inference: outputs = models[0].forward(nv12_data)
-
Post-processing Configuration: Setting post-processing parameters (dimensions, thresholds, etc.)
-
Result Parsing: Calling the post-processing library to parse output tensors
-
Result Visualization: Drawing detection boxes and label information on the original image
-
Result Saving: Saving the results as an image file

FAQ
Q: What should I do if I encounter "No module named 'hobot_dnn'" error when running the example?
A: Please ensure the RDK Python environment is correctly installed, including the hobot_dnn module and other official dedicated inference libraries.
Q: How to change the test image?
A: Place the new image file in the example directory and modify img_file = cv2.imread('your_image_path') in the code.
Q: What should I do if the detection results are inaccurate?
A: The YOLOv3 model is trained on the COCO dataset and may require fine-tuning for specific scenarios or using more suitable models.
Q: How to adjust the detection threshold?
A: Modify the value of yolov3_postprocess_info.score_threshold in the code. For example, changing it to 0.5 can improve detection sensitivity.
Q: Can real-time video stream processing be achieved?
A: The current example is designed for single images, but the code can be modified to achieve real-time object detection for video streams.
Q: How to obtain other pre-trained YOLO models?
A: You can refer to the model_zoo repository or Toolchain's basic model repository