5.2.6 Model Inference
Feature Overview
This section introduces how to use the model inference feature: input a local image for inference, obtain the rendered image, and save it locally.
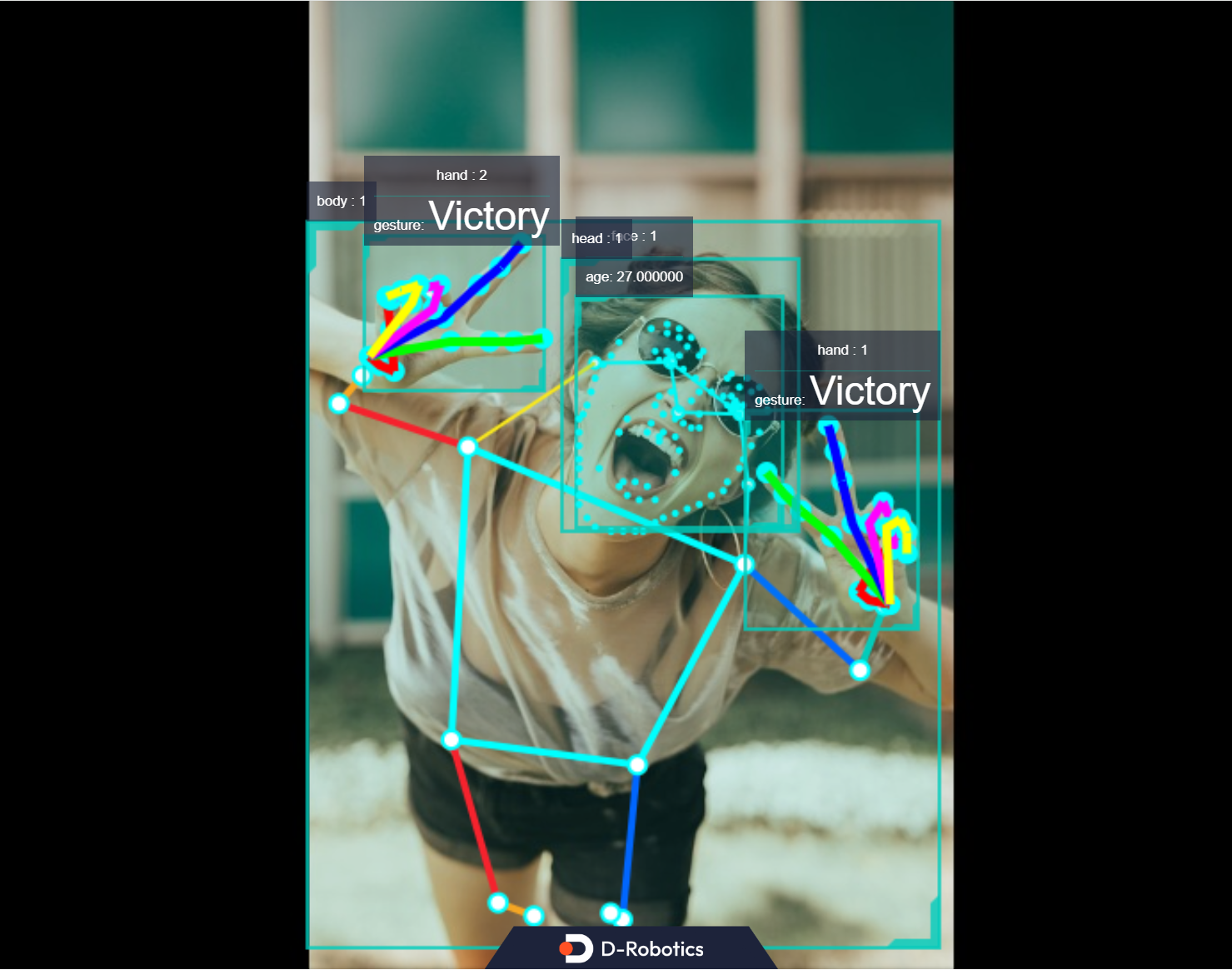
Finally, we demonstrate the combined inference and fusion results of multiple algorithms from TROS application algorithms, including Human Detection and Tracking, Face Age Detection, Face 106 Landmarks Detection, Hand Keypoint Detection, and Gesture Recognition. The example uses input from an MIPI/USB camera or local image playback, with inference results visualized via a web interface.
Code repository: https://github.com/D-Robotics/hobot_dnn
Supported Platforms
| Platform | Runtime Environment |
|---|---|
| RDK X3, RDK X3 Module | Ubuntu 20.04 (Foxy), Ubuntu 22.04 (Humble) |
| RDK X5, RDK X5 Module | Ubuntu 22.04 (Humble) |
| X86 | Ubuntu 20.04 (Foxy) |
For model inference on RDK S100 and RDK Ultra platforms, please refer to the Boxs Algorithm Repository.
Prerequisites
RDK Platform
- RDK has been flashed with Ubuntu 20.04 or Ubuntu 22.04 system image.
- TogetherROS.Bot has been successfully installed on RDK.
X86 Platform
- Confirm that your X86 platform runs Ubuntu 20.04 and has tros.b successfully installed.
Usage Instructions
Using a local JPEG image and a model (FCOS object detection model supporting 80 object categories including people, animals, fruits, vehicles, etc.) specified in the hobot_dnn configuration file, perform inference via image playback and save the rendered output image.
- Foxy
- Humble
# Set up tros.b environment
source /opt/tros/setup.bash
# Set up tros.b environment
source /opt/tros/humble/setup.bash
# Copy required configuration files for the example from tros.b installation path.
# The 'config' directory contains the model used by the example and the local image for playback.
cp -r /opt/tros/${TROS_DISTRO}/lib/dnn_node_example/config/ .
# Perform inference using a local JPG image and save the rendered result
ros2 launch dnn_node_example dnn_node_example_feedback.launch.py dnn_example_config_file:=config/fcosworkconfig.json dnn_example_image:=config/target.jpg
Upon successful execution, the rendered image will be automatically saved in the current working directory as render_feedback_0_0.jpeg. Press Ctrl+C to exit the program.
For explanations of command-line parameters and instructions on subscribing to images published by a camera for algorithm inference, please refer to the README.md file in the source code of the dnn_node_example package.
Result Analysis
The terminal outputs the following logs:
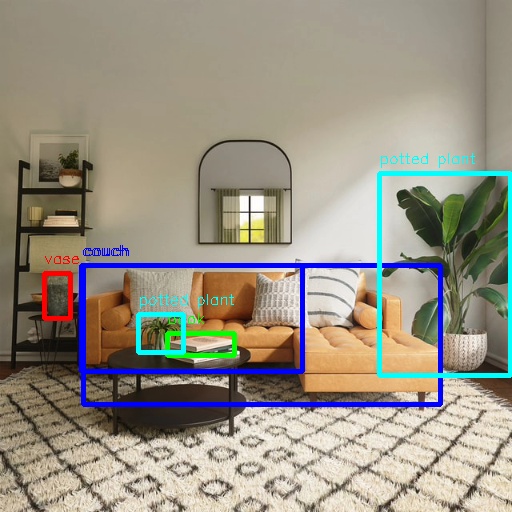
[example-1] [INFO] [1679901151.612290039] [ImageUtils]: target size: 6
[example-1] [INFO] [1679901151.612314489] [ImageUtils]: target type: couch, rois.size: 1
[example-1] [INFO] [1679901151.612326734] [ImageUtils]: roi.type: couch, x_offset: 83 y_offset: 265 width: 357 height: 139
[example-1] [INFO] [1679901151.612412454] [ImageUtils]: target type: potted plant, rois.size: 1
[example-1] [INFO] [1679901151.612426522] [ImageUtils]: roi.type: potted plant, x_offset: 379 y_offset: 173 width: 131 height: 202
[example-1] [INFO] [1679901151.612472961] [ImageUtils]: target type: book, rois.size: 1
[example-1] [INFO] [1679901151.612497709] [ImageUtils]: roi.type: book, x_offset: 167 y_offset: 333 width: 67 height: 22
[example-1] [INFO] [1679901151.612522859] [ImageUtils]: target type: vase, rois.size: 1
[example-1] [INFO] [1679901151.612533487] [ImageUtils]: roi.type: vase, x_offset: 44 y_offset: 273 width: 26 height: 45
[example-1] [INFO] [1679901151.612557172] [ImageUtils]: target type: couch, rois.size: 1
[example-1] [INFO] [1679901151.612567740] [ImageUtils]: roi.type: couch, x_offset: 81 y_offset: 265 width: 221 height: 106
[example-1] [INFO] [1679901151.612606444] [ImageUtils]: target type: potted plant, rois.size: 1
[example-1] [INFO] [1679901151.612617518] [ImageUtils]: roi.type: potted plant, x_offset: 138 y_offset: 314 width: 45 height: 38
[example-1] [WARN] [1679901151.612652352] [ImageUtils]: Draw result to file: render_feedback_0_0.jpeg
The log indicates that the algorithm detected 6 objects from the input image, reporting each object’s category (target type) and bounding box coordinates (top-left corner x_offset, y_offset, and dimensions width, height). The rendered image is saved as render_feedback_0_0.jpeg.
Rendered image render_feedback_0_0.jpeg:
Multi-Algorithm Inference
This section demonstrates simultaneous inference using multiple algorithms, with fused results displayed via a web interface.
This feature is supported only in TROS Humble 2.3.1 and later versions.
For TROS release notes, see: Release Notes.
To check your TROS version, see: Version Check Guide.
Using MIPI/USB Camera for Image Publishing
# Set up tros.b environment
source /opt/tros/humble/setup.bash
# Copy required configuration files for the example from tros.b installation path.
cp -r /opt/tros/${TROS_DISTRO}/lib/mono2d_body_detection/config/ .
cp -r /opt/tros/${TROS_DISTRO}/lib/hand_lmk_detection/config/ .
cp -r /opt/tros/${TROS_DISTRO}/lib/hand_gesture_detection/config/ .
# Configure MIPI camera
export CAM_TYPE=mipi
# For USB camera, use: export CAM_TYPE=usb
# Launch the example
ros2 launch hand_gesture_detection hand_gesture_fusion.launch.py
Using Local Image Playback
# Set up tros.b environment
source /opt/tros/humble/setup.bash
# Copy required configuration files for the example from tros.b installation path.
cp -r /opt/tros/${TROS_DISTRO}/lib/mono2d_body_detection/config/ .
cp -r /opt/tros/${TROS_DISTRO}/lib/hand_lmk_detection/config/ .
cp -r /opt/tros/${TROS_DISTRO}/lib/hand_gesture_detection/config/ .
# Configure local image playback
export CAM_TYPE=fb
# Launch the example
ros2 launch hand_gesture_detection hand_gesture_fusion.launch.py publish_image_source:=config/person_face_hand.jpg publish_image_format:=jpg publish_output_image_w:=960 publish_output_image_h:=544 publish_fps:=30
Open a browser on your PC and navigate to http://IP:8000 to view the image and algorithm-rendered results (replace IP with your RDK’s IP address):