5.2.10 Vision Language Model
Introduction
This section describes how to experience on-device Vision Language Model (VLM) on the RDK platform. Thanks to the excellent results of InternVL and SmolVLM, we have achieved quantization and deployment on the RDK platform. This demo leverages the powerful KV Cache management in llama.cpp, combined with the computational advantages of the RDK platform's BPU module, to enable local VLM model deployment.
Code repository: (https://github.com/D-Robotics/hobot_llamacpp.git)
Supported Platforms
| Platform | OS / Method | Demo Functionality |
|---|---|---|
| RDK X5 | Ubuntu 22.04 (Humble) | On-device Vision Language Model |
Supported Models
| Model Name | Para | Platform | Image Encoder | Language Encoder and Decoder |
|---|---|---|---|---|
| InternVL2_5 | 1B | X5 | vit_model_int16_v2.bin | Qwen2.5-0.5B-Instruct-Q4_0.gguf |
| InternVL2_5 | 1B | S100 | vit_model_int16.hbm | Qwen2.5-0.5B-Instruct-Q4_0.gguf |
| InternVL3 | 1B | X5 | vit_model_int16_VL3_1B_Instruct_X5.bin | qwen2_5_q8_0_InternVL3_1B_Instruct.gguf |
| InternVL3 | 1B | S100 | vit_model_int16_VL3_1B_Instruct.hbm | qwen2_5_q8_0_InternVL3_1B_Instruct.gguf |
| InternVL3 | 2B | X5 | vit_model_int16_VL3_2B_Instruct.bin | qwen2_5_1.5b_q8_0_InternVL3_2B_Instruct.gguf |
| InternVL3 | 2B | S100 | vit_model_int16_VL3_2B_Instruct.hbm | qwen2_5_1.5b_q8_0_InternVL3_2B_Instruct.gguf |
| SmolVLM2 | 256M | X5 | SigLip_int16_SmolVLM2_256M_Instruct_MLP_C1_UP_X5.bin | SmolVLM2-256M-Video-Instruct-Q8_0.gguf |
| SmolVLM2 | 500M | X5 | SigLip_int16_SmolVLM2_500M_Instruct_MLP_C1_UP_X5.bin | SmolVLM2-500M-Video-Instruct-Q8_0.gguf |
Preparation
RDK Platform
- RDK should be flashed with the Ubuntu 22.04 system image.
- TogetheROS.Bot must be successfully installed on the RDK.
Usage
RDK Platform
Use the srpi-config command to set the ION memory size to 1.6GB. For details, refer to the Performance Options section in the RDK User Manual.
After rebooting, set the CPU maximum frequency to 1.5GHz and the scheduling mode to performance with the following commands:
sudo bash -c 'echo 1 > /sys/devices/system/cpu/cpufreq/boost'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu1/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu2/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu3/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu4/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu5/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu6/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu7/cpufreq/scaling_governor'
Currently, two demo modes are provided: direct terminal input (image and text), or subscribing to image and text messages and publishing the results as text.
InternVL
Before running the program, download the model files to the working directory with the following commands:
# Download model files
wget https://huggingface.co/D-Robotics/InternVL2_5-1B-GGUF-BPU/blob/main/Qwen2.5-0.5B-Instruct-Q4_0.gguf
wget https://huggingface.co/D-Robotics/InternVL2_5-1B-GGUF-BPU/blob/main/rdkx5/vit_model_int16_v2.bin
source /opt/tros/humble/setup.bash
cp -r /opt/tros/${TROS_DISTRO}/lib/hobot_llamacpp/config/ .
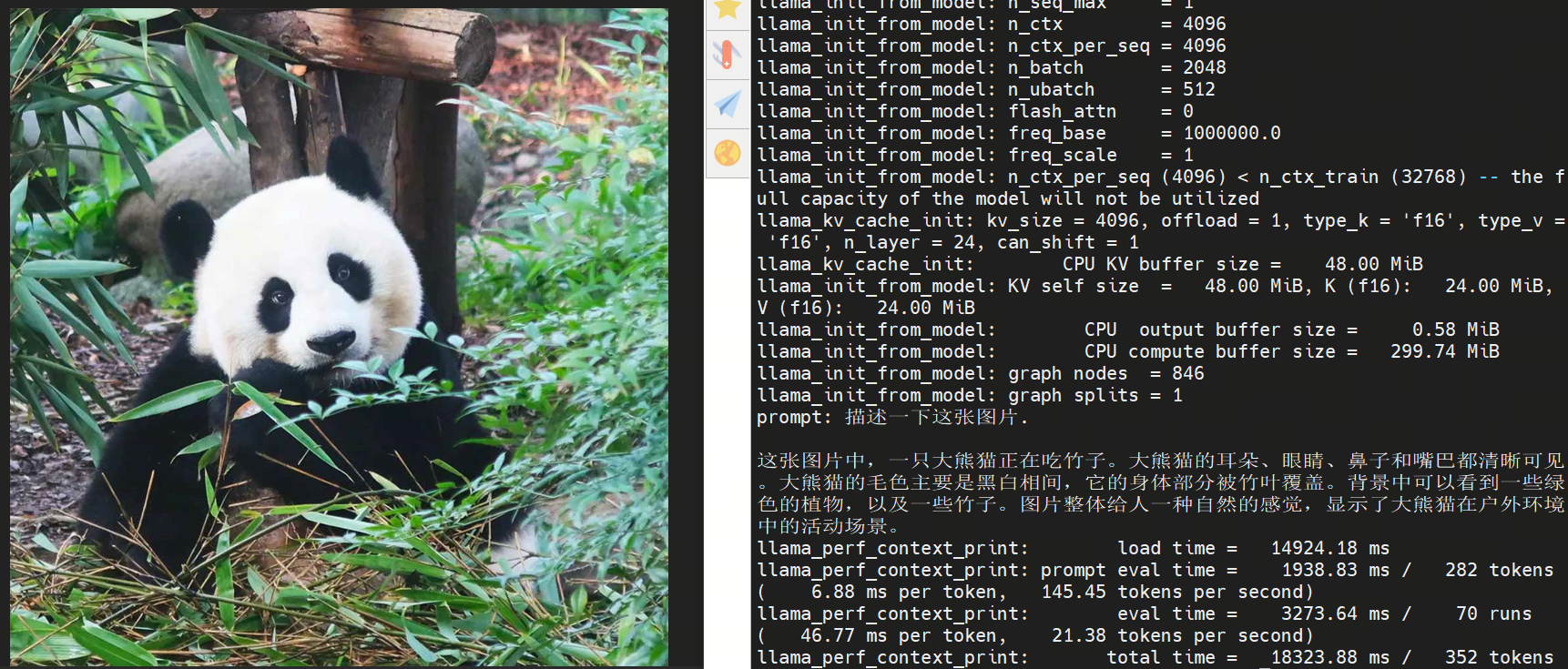
ros2 run hobot_llamacpp hobot_llamacpp --ros-args -p feed_type:=0 -p image:=config/image2.jpg -p image_type:=0 -p user_prompt:="Describe the image." -p model_file_name:=vit_model_int16_v2.bin -p llm_model_name:=Qwen2.5-0.5B-Instruct-Q4_0.gguf
After starting the program, you can use a local image and custom prompt for output.
SmolVLM
Before running the program, download the model files to the working directory with the following commands:
# Download model files
wget https://huggingface.co/D-Robotics/SmolVLM2-256M-Video-Instruct-GGUF-BPU/resolve/main/rdkx5/SigLip_int16_SmolVLM2_256M_Instruct_MLP_C1_UP_X5.bin
wget https://huggingface.co/D-Robotics/SmolVLM2-256M-Video-Instruct-GGUF-BPU/resolve/main/SmolVLM2-256M-Video-Instruct-Q8_0.gguf
source /opt/tros/humble/setup.bash
cp -r /opt/tros/${TROS_DISTRO}/lib/hobot_llamacpp/config/ .
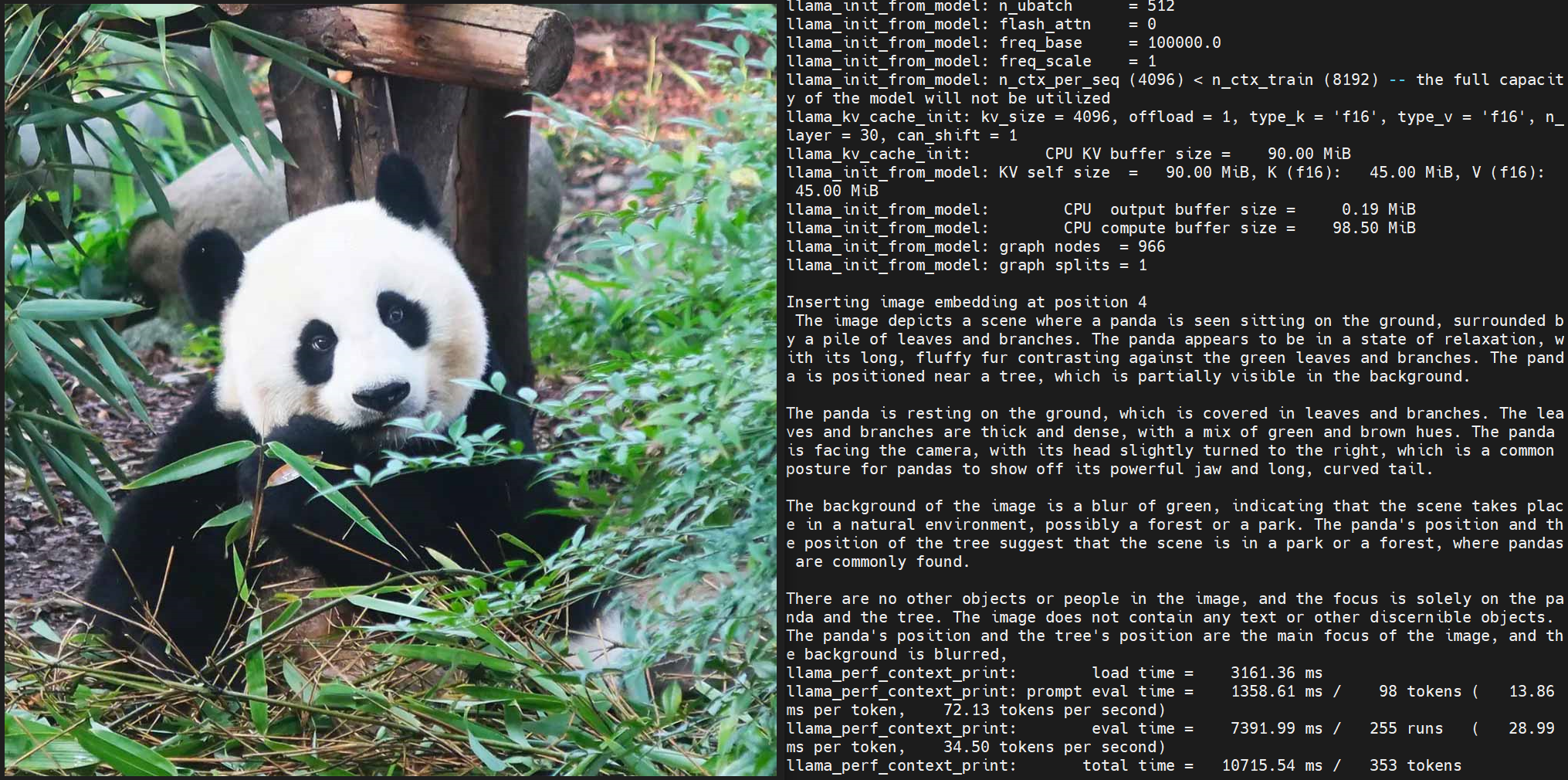
ros2 run hobot_llamacpp hobot_llamacpp --ros-args -p feed_type:=0 -p model_type:=1 -p image:=config/image2.jpg -p image_type:=0 -p user_prompt:="Describe the image." -p model_file_name:=SigLip_int16_SmolVLM2_256M_Instruct_MLP_C1_UP_X5.bin -p llm_model_name:=SmolVLM2-256M-Video-Instruct-Q8_0.gguf
After starting the program, you can use a local image and custom prompt for output.
Notes
Ensure the development board more than 1.6GB size of ION memory, otherwise the model may fail to load.