模型上板运行应用开发说明
RDK X3
模型推理DNN API使用示例说明
概述
本章节介绍模型上板运行 horizon_runtime_sample 示例包的具体用法,开发者可以体验并基于这些示例进行应用开发,降低开发门槛。
示例包提供三个方面的示例:
- 模型推理 dnn API使用示例。
- 自定义算子(custom OP)等特殊功能示例。
- 非NV12输入模型的杂项示例。
详细内容请阅读下文。
horizon_runtime_sample 示例包获取请参考 交付物说明。
示例代码包结构介绍
+---horizon_runtime_sample
|── README.md
├── code # 示例源码
│ ├── 00_quick_start # 快速入门示例,用mobilenetv1读取单张图片进行推理的示例代码
│ │ ├── CMakeLists.txt
│ │ ├── CMakeLists_x86.txt
│ │ └── src
│ ├── 01_api_tutorial # BPU SDK DNN API使用示例代码
│ │ ├── CMakeLists.txt
│ │ ├── mem
│ │ ├── model
│ │ ├── resize
│ │ ├── roi_infer
│ │ └── tensor
│ ├── 02_advanced_samples # 特殊功能示例
│ │ ├── CMakeLists.txt
│ │ ├── custom_identity
│ │ ├── multi_input
│ │ ├── multi_model_batch
│ │ └── nv12_batch
│ ├── 03_misc # 杂项示例
│ │ ├── CMakeLists.txt
│ │ ├── lenet_gray
│ │ └── resnet_feature
│ ├── CMakeLists.txt
│ ├── build_ultra.sh # aarch64编译脚本 RDK Ultra 使用
│ ├── build_xj3.sh # aarch64编译脚本 RDK X3 使用
│ └── deps_gcc9.3 # 编译依赖库
│ └── aarch64
├── ultra
│ ├── data # 预置数据文件
│ │ ├── cls_images
│ │ ├── custom_identity_data
│ │ ├── det_images
│ │ └── misc_data
│ ├── model
│ │ ├── README.md
| | └── runtime -> ../../../model_zoo/runtime/horizon_runtime_sample # 软链接指向OE包中的模型,板端运行环境需要自行指定模型路径
│ ├── script # aarch64示例运行脚本
│ │ ├── 00_quick_start
│ │ ├── 01_api_tutorial
│ │ ├── 02_advanced_samples
│ │ ├── 03_misc
│ │ └── README.md
│ └── script_x86 # x86示例运行脚本
│ ├── 00_quick_start
│ └── README.md
└── xj3
├── data # 预置数据文件
│ ├── cls_images
│ ├── custom_identity_data
│ ├── det_images
│ └── misc_data
├── model
│ ├── README.md
| └── runtime -> ../../../model_zoo/runtime/horizon_runtime_sample # 软链接指向OE包中的模型,板端运行环境需要自行指定模型路径
├── script # aarch64示例运行脚本
│ ├── 00_quick_start
│ ├── 01_api_tutorial
│ ├── 02_advanced_samples
│ ├── 03_misc
│ └── README.md
└── script_x86 # x86示例运行脚本
├── 00_quick_start
└── README.md
- 00_quick_start:快速入门示例,基于
dnnAPI,用mobilenetv1进行单张图片模型推理和结果解析。 - 01_api_tutorial:
dnnAPI使用教学代码, 包括 mem, model, resize, roi_infer 和 tensor 五部分。 - 02_advanced_samples:特殊功能示例,包括 custom_identity, multi_input, multi_model_batch 和 nv12_batch 功能。。
- 03_misc:非NV12输入模型的杂项示例。
- xj3:RDK X3开发板示例运行脚本,预置了数据和相关模型。
- ultra: RDK Ultra开发板示例运行脚本,预置了数据和相关模型。
- build_xj3.sh:RDK X3程序一键编译脚本。
- build_ultra.sh:RDK Ultra程序一键编译脚本。
- deps/deps_gcc9.3:示例代码所需要的三方依赖, 用户在开发自己代码程序的时候可以根据实际情况替换或者裁剪。
私有模型上板运行,请参考 00_quick_start/src/run_mobileNetV1_224x224.cc 示例代码流程进行代码重写,编译成功后可以在开发板上测试验证!
环境构建
开发板准备
-
拿到开发板后,请将开发版镜像更新到最新版本,升级方法请参考系统更新 章节内容。
-
确保本地开发机和开发板可以远程连接。
编译
编译需要当前环境安装好交叉编译工具: aarch64-linux-gnu-g++ , aarch64-linux-gnu-gcc。 请使用D-Robotics 提供的开发机Docker镜像,直接进行编译使用。开发机Docker环境的获取及使用方法,请阅读环境安装 章节内容;
根据自身使用的开发板情况,请使用horizon_runtime_sample/code目录下的 build_xj3.sh 或 build_ultra.sh 脚本,即可一键编译开发板环境下的可执行程序,可执行程序和对应依赖会自动复制到 xj3/script 目录下的 aarch64 目录下 或 ultra/script 目录下的 aarch64 目录下。
工程�通过获取环境变量 LINARO_GCC_ROOT 来指定交叉编译工具的路径,用户使用之前可以检查本地的环境变量是否为目标交叉编译工具。
如果需要指定交叉编译工具路径,可以设置环境变量 LINARO_GCC_ROOT , 或者直接修改脚本 build_xj3.sh 或 build_ultra.sh,指定变量 CC 和 CXX。
export CC=${GCC_ROOT}/bin/aarch64-linux-gnu-gcc
export CXX=${GCC_ROOT}/bin/aarch64-linux-gnu-g++
示例使用
basic_samples 示例
模型推理示例脚本主要在 xj3/script 和 xj3/script_x86 目录下,编译程序后目录结构如下:
# RDK X3 使用脚本信息
├─script
├── 00_quick_start
│ ├── README.md
│ └── run_mobilenetV1.sh
├── 01_api_tutorial
│ ├── model.sh
│ ├── README.md
│ ├── resize_bgr.sh
│ ├── resize_y.sh
│ ├── roi_infer.sh
│ ├── sys_mem.sh
│ └── tensor.sh
├── 02_advanced_samples
│ ├── custom_arm_op_custom_identity.sh
│ ├── README.md
│ └── run_multi_model_batch.sh
├── 03_misc
│ ├── README.md
│ ├── run_lenet.sh
│ └── run_resnet50_feature.sh
├── aarch64 # 编译产生可执行程序及依赖库
│ ├── bin
│ │ ├── model_example
│ │ ├── resize_bgr_example
│ │ ├── resize_y_example
│ │ ├── roi_infer
│ │ ├── run_custom_op
│ │ ├── run_lenet_gray
│ │ ├── run_mobileNetV1_224x224
│ │ ├── run_multi_model_batch
│ │ ├── run_resnet_feature
│ │ ├── sys_mem_example
│ │ └── tensor_example
│ └── lib
│ ├── libdnn.so
│ ├── libhbrt_bernoulli_aarch64.so
│ └── libopencv_world.so.3.4
└── README.md
# RDK Ultra 使用脚本信息
├─script
├── 00_quick_start
│ ├── README.md
│ └── run_mobilenetV1.sh
├── 01_api_tutorial
│ ├── model.sh
│ ├── README.md
│ ├── roi_infer.sh
│ ├── sys_mem.sh
│ └── tensor.sh
├── 02_advanced_samples
│ ├── plugin
│ │ └── custom_arm_op_custom_identity.sh
│ ├── README.md
│ ├── run_multi_input.sh
│ ├── run_multi_model_batch.sh
│ └── run_nv12_batch.sh
├── 03_misc
│ ├── README.md
│ ├── run_lenet.sh
│ └── run_resnet50_feature.sh
├── aarch64 # 编译产生可执行程序及依赖库
│ ├── bin
│ │ ├── model_example
│ │ ├── roi_infer
│ │ ├── run_custom_op
│ │ ├── run_lenet_gray
│ │ ├── run_mobileNetV1_224x224
│ │ ├── run_multi_input
│ │ ├── run_multi_model_batch
│ │ ├── run_nv12_batch
│ │ ├── run_resnet_feature
│ │ ├── sys_mem_example
│ │ └── tensor_example
│ └── lib
│ ├── libdnn.so
│ ├── libhbrt_bayes_aarch64.so
│ └── libopencv_world.so.3.4
└── README.md
- model文件夹下包含模型的路径,其中
runtime文件夹为软链接,链接路径为../../../model_zoo/runtime/horizon_runtime_sample,可直接找到交付包中的模型路径 - 板端运行环境需要将模型放至
model文件夹下
quick_start
00_quick_start 目录下的是模型推理的快速开始示例:
00_quick_start/
├── README.md
└── run_mobilenetV1.sh
run_mobilenetV1.sh:该脚本实现使用mobilenetv1模型读取单张图片进行推理的示例功能。
api_tutorial
01_api_tutorial 目录下的示例,用于介绍如何使用嵌入式API。其目录包含以下脚本:
├── model.sh
├── resize_bgr.sh
├── resize_y.sh
├── roi_infer.sh
├── sys_mem.sh
└── tensor.sh
model.sh:该脚本主要实现读取模型信息的功能。 使用的时候,直接进入 01_api_tutorial 目录,然后直接执行sh model.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
#!/bin/sh
/userdata/ruxin.song/xj3/script/01_api_tutorial# sh model.sh
../aarch64/bin/model_example --model_file_list=../../model/runtime/mobilenetv1/mobilenetv1_nv12_hybrid_horizonrt.bin
I0000 00:00:00.000000 24638 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[HBRT] set log level as 0. version = 3.12.1
[BPU_PLAT]BPU Platform Version(1.2.2)!
[HorizonRT] The model builder version = 1.3.3
I0108 04:19:27.245879 24638 model_example.cc:104] model count:1, model[0]: mobilenetv1_nv12
I0108 04:19:27.246064 24638 model_example.cc:112] hbDNNGetModelHandle [mobilenetv1_nv12] success!
I0108 04:19:27.246139 24638 model_example.cc:189] [mobilenetv1_nv12] Model Info: input num: 1, input[0] validShape: ( 1, 3, 224, 224 ), alignedShape: ( 1, 4, 224, 224 ), tensorLayout: 2, tensorType: 1, output num: 1, output[0] validShape: ( 1, 1000, 1, 1 ), alignedShape: ( 1, 1000, 1, 1 ), tensorLayout: 2, tensorType: 13
resize_bgr.sh:该脚本主要引导如何使用hbDNNResize这个API, 示例实现的代码功能是将一张1352x900大小的图片,截取图片中坐标为[5,19,340,343]的部分,然后resize到402x416并保存下来。 使用的时候,直接进入 01_api_tutorial 目录,然后直接执行sh resize_bgr.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
#!/bin/sh
/userdata/ruxin.song/xj3/script/01_api_tutorial# sh resize_bgr.sh
../aarch64/bin/resize_bgr_example --image_file=../../data/det_images/kite.jpg --resize_height=416 --resize_width=402 --resized_image=./resize_bgr.jpg --crop_x1=5 --crop_x2=340 --crop_y1=19 --crop_y2=343
I0000 00:00:00.000000 24975 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
I0108 06:58:03.327212 24975 resize_bgr_example.cc:116] Original shape: 1352x900 ,dest shape:402x416 ,aligned shape:402x416
[HBRT] set log level as 0. version = 3.12.1
[BPU_PLAT]BPU Platform Version(1.2.2)!
I0108 06:58:03.328739 24975 resize_bgr_example.cc:139] resize success!
I0108 06:58:03.335835 24975 resize_bgr_example.cc:143] wait task done finished!
执行成功后,当前目录会成功保存名称为resize_bgr.jpg的图片。
resize_y.sh:该脚本主要引导如何使用hbDNNResize这个API,示例代码实现的�功能是将一张图片resize到416x402。 使用的时候,直接进入 01_api_tutorial 目录,然后直接执行sh resize_y.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
#!/bin/sh
/userdata/ruxin.song/xj3/script/01_api_tutorial# sh resize_y.sh
../aarch64/bin/resize_y_example --image_file=../../data/det_images/kite.jpg --resize_height=416 --resize_width=402 --resized_image=./resize_y.jpg
I0000 00:00:00.000000 24992 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
I0108 06:59:36.887241 24992 resize_y_example.cc:101] Original shape: 1352x900 ,dest shape:402x416 ,aligned shape:402x416
[HBRT] set log level as 0. version = 3.12.1
[BPU_PLAT]BPU Platform Version(1.2.2)!
I0108 06:59:36.888770 24992 resize_y_example.cc:119] resize success
I0108 06:59:36.891711 24992 resize_y_example.cc:123] wait resize success
I0108 06:59:36.891798 24992 resize_y_example.cc:129] spent time: 0.003463
执行成功后,当前目录会成功保存名称为resize_y.jpg的图片。
-
roi_infer.sh: 该脚本主要引导如何使用hbDNNRoiInfer这个API,示例代码实现的功能是将一张图片resize到模型输入大小,转为nv12数据,并给定roi框进行模型推理(infer)。 使用的时候,直接进入 01_api_tutorial 目录,然后直接执行sh roi_infer.sh即可。 -
sys_mem.sh:该脚本主要引导如何使用hbSysAllocMem、hbSysFlushMem和hbSysFreeMem这几个API。使用的时候,直接进入 01_api_tutorial 目录,执行sh sys_mem.sh即可。 -
tensor.sh:该脚本主要引导如何准备模型输入和输出的tensor。 使用的时候,直接进入 01_api_tutorial 目录,执行sh tensor.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
/userdata/ruxin.song/xj3/script/01_api_tutorial# sh tensor.sh
Tensor data type:0, Tensor layout: 2, shape:1x1x721x1836, aligned shape:1x1x721x1840
Tensor data type:1, Tensor layout: 2, shape:1x3x773x329, aligned shape:1x3x773x336
Tensor data type:2, Tensor layout: 2, shape:1x3x108x1297, aligned shape:1x3x108x1312
Tensor data type:5, Tensor layout: 2, shape:1x3x858x477, aligned shape:1x3x858x477
Tensor data type:5, Tensor layout: 0, shape:1x920x102x3, aligned shape:1x920x102x3
Tensor data type:4, Tensor layout: 2, shape:1x3x723x1486, aligned shape:1x3x723x1486
Tensor data type:4, Tensor layout: 0, shape:1x372x366x3, aligned shape:1x372x366x3
Tensor data type:3, Tensor layout: 2, shape:1x3x886x291, aligned shape:1x3x886x291
Tensor data type:3, Tensor layout: 0, shape:1x613x507x3, aligned shape:1x613x507x3
advanced_samples
02_advanced_samples 目录下的示例,用于介绍自定义算子特殊功能的使用。其目录包含以下脚本:
├── custom_arm_op_custom_identity.sh
└── run_multi_model_batch.sh
custom_arm_op_custom_identity.sh:该脚本主要实现自定义算子模型推理功能, 使用的时候,进入 02_advanced_samples 目录, 然后直接执行sh custom_arm_op_custom_identity.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
/userdata/ruxin.song/xj3/script/02_advanced_samples# sh custom_arm_op_custom_identity.sh
../aarch64/bin/run_custom_op --model_file=../../model/runtime/custom_op/custom_op_featuremap.bin --input_file=../../data/custom_identity_data/input0.bin,../../data/custom_identity_data/input1.bin
I0000 00:00:00.000000 30421 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
I0723 15:06:12.172068 30421 main.cpp:212] hbDNNRegisterLayerCreator success
I0723 15:06:12.172335 30421 main.cpp:217] hbDNNRegisterLayerCreator success
[BPU_PLAT]BPU Platform Version(1.3.1)!
[HBRT] set log level as 0. version = 3.15.3.0
[DNN] Runtime version = 1.15.2_(3.15.3 HBRT)
[A][DNN][packed_model.cpp:217](1563865572232) [HorizonRT] The model builder version = 1.13.5
I0723 15:06:12.240696 30421 main.cpp:232] hbDNNGetModelNameList success
I0723 15:06:12.240784 30421 main.cpp:239] hbDNNGetModelHandle success
I0723 15:06:12.240819 30421 main.cpp:245] hbDNNGetInputCount success
file length: 602112
file length: 602112
I0723 15:06:12.243616 30421 main.cpp:268] hbDNNGetOutputCount success
I0723 15:06:12.244102 30421 main.cpp:297] hbDNNInfer success
I0723 15:06:12.257903 30421 main.cpp:302] task done
I0723 15:06:14.277941 30421 main.cpp:306] write output tensor
模型的第一个输出数据保存至 ``output0.txt`` 文件。
run_multi_model_batch.sh:该脚本主要实现多个小模型批量推理功能, 使用的时候,进入 02_advanced_samples 目录, 然后直接执行sh run_multi_model_batch.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
root@x3sdbx3-hynix2G-3200:/userdata/chaoliang/xj3/script/02_advanced_samples# sh run_multi_model_batch.sh
../aarch64/bin/run_multi_model_batch --model_file=../../model/runtime/googlenet/googlenet_224x224_nv12.bin,../../model/runtime/mobilenetv2/mobilenetv2_224x224_nv12.bin --input_file=../../data/cls_images/zebra_cls.jpg,../../data/cls_images/zebra_cls.jpg
I0000 00:00:00.000000 17060 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[HBRT] set log level as 0. version = 3.13.4
[BPU_PLAT]BPU Platform Version(1.1.1)!
[HorizonRT] The model builder version = 1.3.18
[HorizonRT] The model builder version = 1.3.18
I0317 12:37:18.249785 17060 main.cpp:119] hbDNNInitializeFromFiles success
I0317 12:37:18.250029 17060 main.cpp:127] hbDNNGetModelNameList success
I0317 12:37:18.250071 17060 main.cpp:141] hbDNNGetModelHandle success
I0317 12:37:18.283633 17060 main.cpp:155] read image to nv12 success
I0317 12:37:18.284270 17060 main.cpp:172] prepare input tensor success
I0317 12:37:18.284456 17060 main.cpp:184] prepare output tensor success
I0317 12:37:18.285344 17060 main.cpp:218] infer success
I0317 12:37:18.296559 17060 main.cpp:223] task done
I0317 12:37:18.296701 17060 main.cpp:228] googlenet class result id: 340
I0317 12:37:18.296805 17060 main.cpp:232] mobilenetv2 class result id: 340
I0317 12:37:18.296887 17060 main.cpp:236] release task success
misc
03_misc 目录下的示例,用于介绍非nv12输入模型的使用。其目录包含以下脚本:
├── run_lenet.sh
└── run_resnet50_feature.sh
run_lenet.sh:该脚本主要实现Y数据输入的lenet模型推理功能, 使用的时候,进入 03_misc 目录, 然后直接执行sh run_lenet.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
/userdata/ruxin.song/xj3/script/03_misc# sh run_lenet.sh
../aarch64/bin/run_lenet_gray --model_file=../../model/runtime/lenet_gray/lenet_gray_hybrid_horizonrt.bin --data_file=../../data/misc_data/7.bin --image_height=28 --image_width=28 --top_k=5
I0000 00:00:00.000000 25139 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[HBRT] set log level as 0. version = 3.12.1
[BPU_PLAT]BPU Platform Version(1.2.2)!
[HorizonRT] The model builder version = 1.3.3
I0108 07:23:35.507514 25139 run_lenet_gray.cc:145] hbDNNInitializeFromFiles success
I0108 07:23:35.507737 25139 run_lenet_gray.cc:153] hbDNNGetModelNameList success
I0108 07:23:35.507771 25139 run_lenet_gray.cc:160] hbDNNGetModelHandle success
I0108 07:23:35.508070 25139 run_lenet_gray.cc:176] prepare y tensor success
I0108 07:23:35.508178 25139 run_lenet_gray.cc:189] prepare tensor success
I0108 07:23:35.509909 25139 run_lenet_gray.cc:200] infer success
I0108 07:23:35.510721 25139 run_lenet_gray.cc:205] task done
I0108 07:23:35.510790 25139 run_lenet_gray.cc:210] task post process finished
I0108 07:23:35.510832 25139 run_lenet_gray.cc:217] TOP 0 result id: 7
I0108 07:23:35.510857 25139 run_lenet_gray.cc:217] TOP 1 result id: 9
I0108 07:23:35.510879 25139 run_lenet_gray.cc:217] TOP 2 result id: 3
I0108 07:23:35.510903 25139 run_lenet_gray.cc:217] TOP 3 result id: 4
I0108 07:23:35.510927 25139 run_lenet_gray.cc:217] TOP 4 result id: 2
run_resnet50_feature.sh:该脚本主要实现feature�数据输入的resnet50模型推理功能,示例代码对feature数据做了quantize和padding以满足模型的输入条件,然后输入到模型进行infer。 使用的时候,进入 03_misc 目录, 然后直接执行sh run_resnet50_feature.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
/userdata/ruxin.song/xj3/script/03_misc# sh run_resnet50_feature.sh
../aarch64/bin/run_resnet_feature --model_file=../../model/runtime/resnet50_feature/resnet50_feature_hybrid_horizonrt.bin --data_file=../../data/misc_data/np_0 --top_k=5
I0000 00:00:00.000000 25155 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[HBRT] set log level as 0. version = 3.12.1
[BPU_PLAT]BPU Platform Version(1.2.2)!
[HorizonRT] The model builder version = 1.3.3
I0108 07:25:41.300466 25155 run_resnet_feature.cc:136] hbDNNInitializeFromFiles success
I0108 07:25:41.300708 25155 run_resnet_feature.cc:144] hbDNNGetModelNameList success
I0108 07:25:41.300741 25155 run_resnet_feature.cc:151] hbDNNGetModelHandle success
I0108 07:25:41.302760 25155 run_resnet_feature.cc:166] prepare feature tensor success
I0108 07:25:41.302919 25155 run_resnet_feature.cc:176] prepare tensor success
I0108 07:25:41.304678 25155 run_resnet_feature.cc:187] infer success
I0108 07:25:41.373052 25155 run_resnet_feature.cc:192] task done
I0108 07:25:41.373328 25155 run_resnet_feature.cc:197] task post process finished
I0108 07:25:41.373374 25155 run_resnet_feature.cc:204] TOP 0 result id: 74
I0108 07:25:41.373399 25155 run_resnet_feature.cc:204] TOP 1 result id: 815
I0108 07:25:41.373422 25155 run_resnet_feature.cc:204] TOP 2 result id: 73
I0108 07:25:41.373445 25155 run_resnet_feature.cc:204] TOP 3 result id: 78
I0108 07:25:41.373468 25155 run_resnet_feature.cc:204] TOP 4 result id: 72
辅助工具和常用操作
日志
本章节主要包括 示例日志 和 模型推理 DNN API日志 两部分。
其中示例日志是指交付包示例代码中的应用日志;模型推理 dnn API日志是指嵌入式dnn库中的日志。用户根据不同的需求可以获取不同的日志信息。
示例日志
示例日志主要采用glog中的vlog,basic_samples参考示例中,日志内容会全部输出。
模型推理 DNN API日志
关于模型推理 DNN API日志的配置,请阅读《算法工具链产品手册》。
公版模型性能精度测评说明
公版模型性能精度指标
下表提供了典型深度神经网络模型在X3处理器上的性能、精度指标。
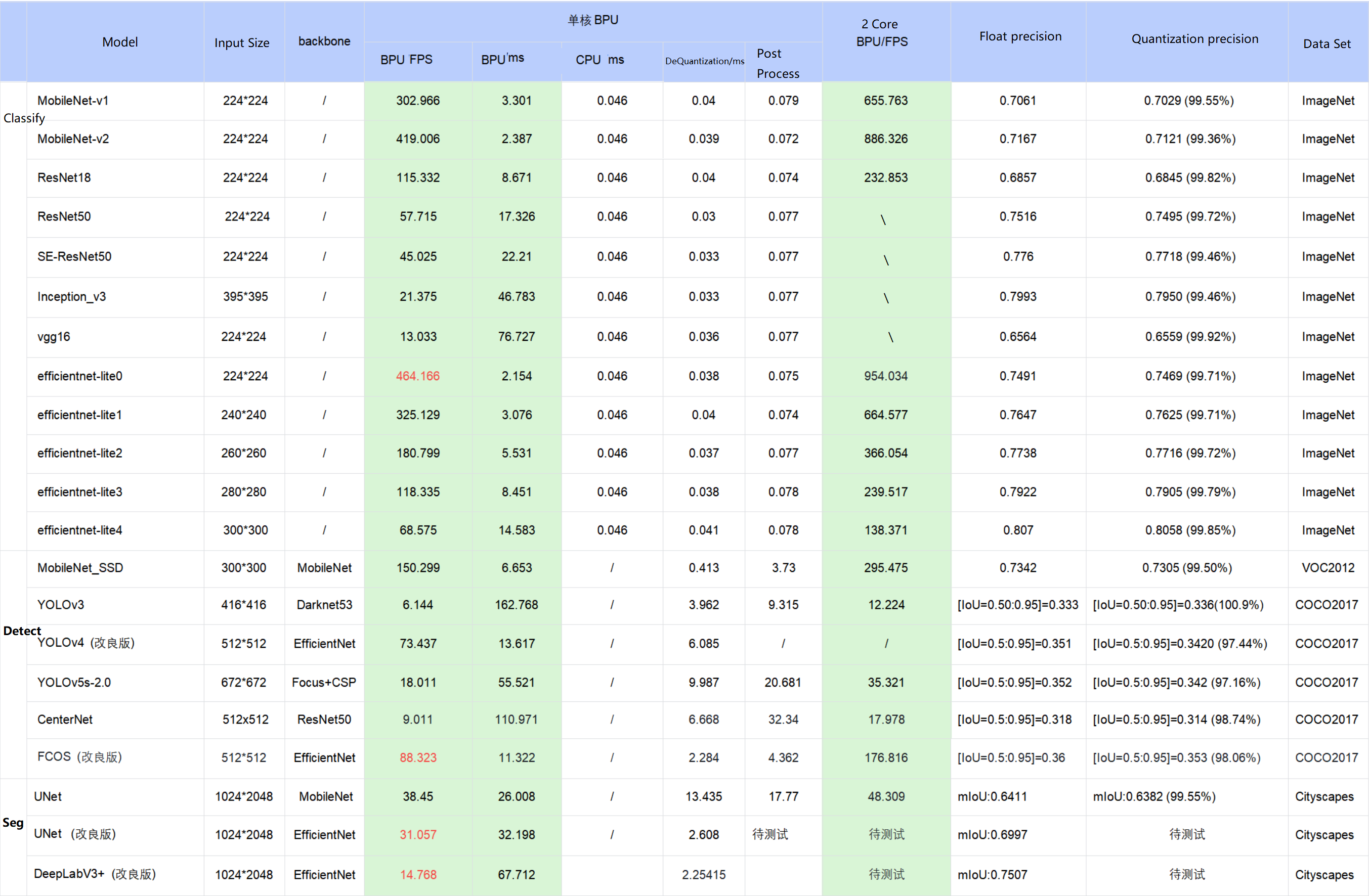
-
表格中的数据均为在D-Robotics RDK X3开发板的实测结果,测试模型均来自于horizon_model_convert_sample 模型示例包;
-
对于模型示例包中的 BPU/CPU 混合异构模型,单帧的耗时主要由输入量化CPU节点、模型BPU算子、模型CPU算子、输出反量化CPU节点、CPU后处理等模块构成,具体说明如下:
a. 输入量化CPU节点:完成float32到int8的输入量化操作,该节点只在使用 featuremap 输入的模型中包含。量化耗时与输入 shape 大小成正比
b. 模型CPU算子:
ⅰ. 检测模型中未包含 CPU 算子
ⅱ. 分类模型尾部的 Softmax 和 Reshape 为 CPU 算子
ⅲ. 分割模型 DeepLabV3+ 尾部的 Argmax 为 CPU 算子
c. 输出反量化CPU节点:完成int8到float32的输出反量化操作。量化耗时与输出 shape 大小成正比
d. D-Robotics 目前支持将模型的 量化/反量化节点手动摘除,由用户自行融入前后处理代码中实现,以减少数据重复遍历的损耗。以 EfficientDet 模型为例,摘除了反量化节点合入后处理,推理性能从 66FPS提高到100FPS
e. 目前D-Robotics 示例模型的后处理均未做针对性的性能优化,您可以根据实际需求采用如近似高效实现等优化手段进行代码级加速
-
在实际应用中,BPU 和 CPU 可以并发运行,提高整体推理速度。
-
若实测性能与上述表格的测试结果不一致,有几个方面可能导致此种情况:
a. DDR带宽的影响,开发板只能运行ai_benchmark程序。
b. 算法工具链版本与系统镜像版本不完全匹配,最理想的情况是配套使用发布包的算法工具链和系统镜像。
c. CPU降频影响,目前开发板重启后默认启用自动降频,为了获得最好的性能,您需要在开发板上执行关闭降频命令:
echo performance > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor。
评测方法说明
简介
本章节介绍公版模型精度性能评测 ai_benchmark 示例包的具体用法, 示例包中预置了源码、可执行程序和评测脚本,开发者可以直接在D-Robotics 开发板上体验并基于这些示例进行嵌入式应用开发,降低开发门槛。
示例包提供常见的分类、检测和分割模型的性能评测和精度评测示例,详细内容请阅读下文。
公版模型精度性能评测 ai_benchmark 示例包获取,请参考《交付物说明》。
示例代码包结构
ai_benchmark/code # 示例源码文件夹
├── build_ptq_xj3.sh # RDK X3 使用
├── build_ptq_ultra.sh # RDK Ultra 使用
├── CMakeLists.txt
├── deps/deps_gcc9.3 # 第三方依赖库,gcc9.3为deps_gcc9.3
│ ├── aarch64
│ └── vdsp
├── include # 源码头文件
│ ├── base
│ ├── input
│ ├── method
│ ├── output
│ ├── plugin
│ └── utils
├── README.md
└── src # 示例源码
├── input
├── method
├── output
├── plugin
├── simple_example.cc # 示例主程序
└── utils
ai_benchmark/xj3 # 示例包运行环境
└── ptq # PTQ方案模型示例
├── data # 模型精度评测数据集
├── mini_data # 模型性能评测数据集
│ ├── cifar10
│ ├── cityscapes
│ ├── coco
│ ├── culane
│ ├── flyingchairs
│ ├── imagenet
│ ├── kitti3d
│ ├── mot17
│ ├── nuscenes
│ ├── nuscenes_lidar
│ └── voc
├── model # PTQ方案nv12模型
│ ├── README.md
│ └── runtime -> ../../../../model_zoo/runtime/ai_benchmark/ptq # 软链接指向OE包中的模型,板端运行环境需要自行指定模型路径
├── README.md
├── script # 执行脚本
│ ├── aarch64 # 编译产生可执行文件及依赖库
│ ├── classification # 分类模型示例
│ │ ├── efficientnet_lite0
│ │ ├── efficientnet_lite1
│ │ ├── efficientnet_lite2
│ │ ├── efficientnet_lite3
│ │ ├── efficientnet_lite4
│ │ ├── googlenet
│ │ ├── mobilenetv1
│ │ ├── mobilenetv2
│ │ └── resnet18
│ ├── config # 模型推理配置文件
│ │ └── data_name_list
│ ├── detection # 检测模型示例
│ │ ├── centernet_resnet50
│ │ ├── efficientdetd0
│ │ ├── fcos_efficientnetb0
│ │ ├── preq_qat_fcos_efficientnetb0
│ │ ├── preq_qat_fcos_efficientnetb1
│ │ ├── preq_qat_fcos_efficientnetb2
│ │ ├── ssd_mobilenetv1
│ │ ├── yolov2_darknet19
│ │ ├── yolov3_darknet53
│ │ └── yolov5s
│ ├── segmentation # 分割模型示例
│ │ ├── deeplabv3plus_efficientnetb0
│ │ ├── fastscnn_efficientnetb0
│ │ └── unet_mobilenet
│ ├── base_config.sh # 基础配置
│ └── README.md
└─��─ tools # 精度评测工具
├── python_tools
└── README.md
ai_benchmark/ultra # 示例包运行环境
└── ptq # PTQ方案模型示例
├── data # 模型精度评测数据集
├── mini_data # 模型性能评测数据集
│ ├── cifar10
│ ├── cityscapes
│ ├── coco
│ ├── culane
│ ├── flyingchairs
│ ├── imagenet
│ ├── kitti3d
│ ├── mot17
│ ├── nuscenes
│ ├── nuscenes_lidar
│ └── voc
├── model # PTQ方案nv12模型
│ │ ├── README.md
│ │ └── runtime -> ../../../../model_zoo/runtime/ai_benchmark/ptq # 软链接指向OE包中的模型,板端运行环境需要自行指定模型路径
├── README.md
├── script # 执行脚本
│ ├── aarch64 # 编译产生可执行文件及依赖库
│ ├── classification # 分类模型示例
│ │ ├── efficientnasnet_m
│ │ ├── efficientnasnet_s
│ │ ├── efficientnet_lite0
│ │ ├── efficientnet_lite1
│ │ ├── efficientnet_lite2
│ │ ├── efficientnet_lite3
│ │ ├── efficientnet_lite4
│ │ ├── googlenet
│ │ ├── mobilenetv1
│ │ ├── mobilenetv2
│ │ ├── resnet18
│ │ └── vargconvnet
│ ├── config # 模型推理配置文件
│ │ └── model
│ ├── detection # 检测模型示例
│ │ ├── centernet_resnet101
│ │ ├── preq_qat_fcos_efficientnetb0
│ │ ├── preq_qat_fcos_efficientnetb2
│ │ ├── preq_qat_fcos_efficientnetb3
│ │ ├── ssd_mobilenetv1
│ │ ├── yolov2_darknet19
│ │ ├── yolov3_darknet53
│ │ ├── yolov3_vargdarknet
│ │ └── yolov5x
│ ├── segmentation # 分割模型示例
│ │ ├── deeplabv3plus_efficientnetb0
│ │ ├── deeplabv3plus_efficientnetm1
│ │ ├── deeplabv3plus_efficientnetm2
│ │ └── fastscnn_efficientnetb0
│ ├── env.sh # 基础环境脚本
│ └── README.md
└── tools # 精度评测工具
├── python_tools
└── README.md
- code:该目录内是评测程序的源码,用来进行模型性能和精度评测。
- xj3: 提供了已经编译好的应用程序,以及各种评测脚本,用来测试多种模型在D-Robotics BPU上运行的性能,精度等(RDK X3 使用)。
- ultra: 提供了已经编译好的应用程序,以及各种评测脚本,用来测试多种模型在D-Robotics BPU上运行的性能,精度等(RDK Ultra 使用)。
- build_ptq_xj3.sh:开发板程序一键编译脚本(RDK X3 使用)。
- build_ptq_ultra.sh:开发板程序一键编译脚本(RDK Ultra 使用)。
- deps/deps_gcc9.3:示例代码所需要的依赖,主要如下所示:
gflags glog hobotlog nlohmann opencv rapidjson
示例模型
我们提供了开源的模型库,里面包含常用的分类、检测和分割模型,模型的命名规则为:{model_name}_{backbone}_{input_size}_{input_type},开发者可以直接使用。
以下表格中的bin模型都是通过 horizon_model_convert_sample 模型转换示例包转换编译出来的,请阅读《交付物说明》 章节内容进行获取。
| MODEL | MODEL NAME |
|---|---|
| centernet_resnet101 | centernet_resnet101_512x512_nv12.bin |
| deeplabv3plus_efficientnetb0 | deeplabv3plus_efficientnetb0_1024x2048_nv12.bin |
| deeplabv3plus_efficientnetm1 | deeplabv3plus_efficientnetm1_1024x2048_nv12.bin |
| efficientnasnet_m | efficientnasnet_m_300x300_nv12.bin |
| efficientnet_lite4 | efficientnet_lite4_300x300_nv12.bin |
| fastscnn_efficientnetb0 | fastscnn_efficientnetb0_1024x2048_nv12.bin |
| googlenet | googlenet_224x224_nv12.bin |
| mobilenetv1 | mobilenetv1_224x224_nv12.bin |
| mobilenetv2 | mobilenetv2_224x224_nv12.bin |
| preq_qat_fcos_efficientnetb0 | fcos_efficientnetb0_512x512_nv12.bin |
| preq_qat_fcos_efficientnetb2 | fcos_efficientnetb2_768x768_nv12.bin |
| resnet18 | resnet18_224x224_nv12.bin |
| ssd_mobilenetv1 | ssd_mobilenetv1_300x300_nv12.bin |
| vargconvnet | vargconvnet_224x224_nv12.bin |
| yolov3_darknet53 | yolov3_darknet53_416x416_nv12.bin |
| yolov5s | yolov5s_672x672_nv12.bin |
| yolov5x | yolov5x_672x672_nv12.bin |
公共数据集
测评示例中用到的数据集主要有VOC数据集、COCO数据集、ImageNet、Cityscapes数据集、FlyingChairs数据集、KITTI数据集、Culane数据集、Nuscenes数据集和Mot17数据集。
请在linux环境下进行下载,获取方式如下:
VOC:http://host.robots.ox.ac.uk/pascal/VOC/ (使用VOC2012版本)
COCO:https://cocodataset.org/#download
ImageNet:https://www.image-net.org/download.php
Cityscapes:https://github.com/mcordts/cityscapesScripts
FlyingChairs:https://lmb.informatik.uni-freiburg.de/resources/datasets/FlyingChairs.en.html
KITTI3D:https://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
CULane:https://xingangpan.github.io/projects/CULane.html
nuScenes:https://www.nuscenes.org/nuscenes#download
mot17:https://opendatalab.com/MOT17
环境构建
开发板准备
-
拿到开发板后,请将开发版镜像更新到最新版本,升��级方法请参考安装系统 章节内容。
-
确保本地开发机和开发板可以远程连接。
编译环境准备
编译需要当前环境安装好交叉编译工具 gcc-ubuntu-9.3.0-2020.03-x86_64-aarch64-linux-gnu。请使用D-Robotics 提供的开发机Docker镜像,直接进行编译使用。开发机Docker环境的获取及使用方法,请阅读环境安装 章节内容;
请使用code目录下的 build_ptq_xj3.sh 或 build_ptq_ultra.sh 脚本,即可一键编译开发板环境下的可执行程序,可执行程序和对应依赖会自动复制到 xj3/ptq/script 目录下的 aarch64 目录下 或 ultra/ptq/script 目录下的 aarch64 目录下。
需要注意 build_ptq_xj3.sh 和 build_ptq_ultra.sh 脚本里指定的交叉编译工具链的位置是 /opt 目录下,用户如果安装在其他位置,可以手动修改下脚本。
export CC=/opt/gcc-ubuntu-9.3.0-2020.03-x86_64-aarch64-linux-gnu/bin/aarch64-linux-gnu-gcc
export CXX=/opt/gcc-ubuntu-9.3.0-2020.03-x86_64-aarch64-linux-gnu/bin/aarch64-linux-gnu-g++
测评示例使用说明
评测示例脚本主要在 script 和 tools 目录下。 script是开发板上运行的评测脚本,包括常见分类,检测和分割模型。每个模型下面有三个脚本,分别表示:
- fps.sh:利用多线程调度实现fps统计,用户可以根据需求自由设置线程数。
- latency.sh:实现单帧延迟统计(一个线程,单帧)。
- accuracy.sh:用于精度评测。
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
script:
├── aarch64 # 编译产生的可执行文件及依赖库
│ ├── bin
│ └── lib
├── base_config.sh # 基础配置
├── config # image_name配置文件
│ ├── data_name_list
| | ├── coco_detlist.list
│ | ├── imagenet.list
│ | └── voc_detlist.list
├── classification # 分类模型评测
│ ├── efficientnet_lite0
│ │ ├── accuracy.sh
│ │ ├── fps.sh
│ │ ├── latency.sh
│ │ ├── workflow_accuracy.json
│ │ ├── workflow_fps.json
│ │ └── workflow_latency.json
│ ├── mobilenetv1
│ ├── .....
│ └── resnet18
├── detection # 检测模型
| ├── centernet_resnet50
│ │ ├── accuracy.sh
│ │ ├── fps.sh
│ │ ├── latency.sh
│ │ ├── workflow_accuracy.json
│ │ ├── workflow_fps.json
│ │ └── workflow_latency.json
│ ├── yolov2_darknet19
│ ├── yolov3_darknet53
│ ├── ...
│ └── efficientdetd0
└── segmentation # 分割模型
├── deeplabv3plus_efficientnetb0
│ ├── accuracy.sh
│ ├── fps.sh
│ ├── latency.sh
│ ├── workflow_accuracy.json
│ ├── workflow_fps.json
│ └── workflow_latency.json
├── fastscnn_efficientnetb0
└── unet_mobilenet
tools目录下是精度评测需要的脚本。主要包括 python_tools 下的精度计算脚本。
tools:
python_tools
└── accuracy_tools
├── cityscapes_metric.py
├── cls_eval.py
├── coco_metric.py
├── coco_det_eval.py
├── config.py
├── parsing_eval.py
├── voc_det_eval.py
└── voc_metric.py
评测前需要执行以下命令,将 ptq 目录拷贝到开发板上,然后将 model_zoo/runtime 拷贝到 ptq/model 目录下。
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
scp -r ai_toolchain_package/Ai_Toolchain_Package-release-vX.X.X-OE-vX.X.X/ai_benchmark/xj3/ptq root@192.168.1.10:/userdata/ptq/
scp -r model_zoo/runtime root@192.168.1.10:/userdata/ptq/model/
性能评测
性能评测分为latency和fps两方面。
- 测评脚本使用说明
进入到需要评测的模型目录下,执行 sh latency.sh 即可测试出单帧延迟。如下图所示:
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
I0419 02:35:07.041095 39124 output_plugin.cc:80] Infer latency: [avg: 13.124ms, max: 13.946ms, min: 13.048ms], Post process latency: [avg: 3.584ms, max: 3.650ms, min: 3.498ms].
infer表示模型推理耗时。Post process表示后处理耗时。
进入到需要评测的模型目录下执行 sh fps.sh 即可测试出帧率。如下图所示:
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
I0419 02:35:00.044417 39094 output_plugin.cc:109] Throughput: 176.39fps # 模型帧率
该功能采用多线程并发方式,旨在让模型可以在BPU上达到极致的性能。由于多线程并发及数据采样的原因,在程序启动阶段帧率值会较低,之后帧率会上升并逐渐趋于稳定,帧率的浮动范围控制在0.5%之内。
- 命令行参数说明
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
fps.sh 脚本内容如下:
#!/bin/sh
source ../../base_config.sh
export SHOW_FPS_LOG=1
export STAT_CYCLE=10 # 设置环境变量,FPS 统计周期
${app} \
--config_file=workflow_fps.json \
--log_level=1
latency.sh 脚本内容如下:
#!/bin/sh
source ../../base_config.sh
export SHOW_LATENCY_LOG=1 # 设置环境变量,打印 LATENCY 级别log
export STAT_CYCLE=5 # 设置环境变量,LATENCY 统计周期
${app} \
--config_file=workflow_latency.json \
--log_level=1
- 配置文件说明
注意:max_cache参数生效时会预处理图片并读取到内存中,为保障您的程序稳定运行,请不要设置过大的值,建议您的数值设置不超过30。
以fcos_efficientnetb0模型为例,workflow_fps.json 配置文件内容如下:
{
"input_config": {
"input_type": "image", # 输��入数据格式,支持图像或者bin文件
"height": 512, # 输入数据高度
"width": 512, # 输入数据宽度
"data_type": 1, # 输入数据类型:HB_DNN_IMG_TYPE_NV12
"image_list_file": "../../../mini_data/coco/coco.lst", # 预处理数据集lst文件所在路径
"need_pre_load": true, # 是否使用预加载方式读取数据集
"limit": 10,
"need_loop": true, # 是否循环读取数据进行评测
"max_cache": 10
},
"output_config": {
"output_type": "image", # 可视化输出数据类型
"image_list_enable": true,
"in_order": false # 是否按顺序输出
},
"workflow": [
{
"method_type": "InferMethod", # Infer推理方式
"unique_name": "InferMethod",
"method_config": {
"core": 0, # 推理core id
"model_file": "../../../model/runtime/fcos_efficientnetb0/fcos_efficientnetb0_512x512_nv12.bin" # 模型文件
}
},
{
"thread_count": 4, # 后处理线程数
"method_type": "PTQFcosPostProcessMethod", # 后处理方法
"unique_name": "PTQFcosPostProcessMethod",
"method_config": { # 后处理参数
"strides": [
8,
16,
32,
64,
128
],
"class_num": 80,
"score_threshold": 0.5,
"topk": 1000,
"det_name_list": "../../config/data_name_list/coco_detlist.list"
}
}
]
}
workflow_latency.json 如下:
{
"input_config": {
"input_type": "image",
"height": 512,
"width": 512,
"data_type": 1,
"image_list_file": "../../../mini_data/coco/coco.lst",
"need_pre_load": true,
"limit": 1,
"need_loop": true,
"max_cache": 10
},
"output_config": {
"output_type": "image",
"image_list_enable": true
},
"workflow": [
{
"method_type": "InferMethod",
"unique_name": "InferMethod",
"method_config": {
"core": 0,
"model_file": "../../../model/runtime/fcos_efficientnetb0/fcos_efficientnetb0_512x512_nv12.bin"
}
},
{
"thread_count": 1,
"method_type": "PTQFcosPostProcessMethod",
"unique_name": "PTQFcosPostProcessMethod",
"method_config": {
"strides": [
8,
16,
32,
64,
128
],
"class_num": 80,
"score_threshold": 0.5,
"topk": 1000,
"det_name_list": "../../config/data_name_list/coco_detlist.list"
}
}
]
}
精�度评测
模型精度评测分为四步:
- 数据预处理。
- 数据挂载。
- 模型推理。
- 精度计算。
-
数据预处理
对于PTQ模型:数据预处理需要在x86开发机环境下运行 hb_eval_preprocess 工具,对数据集进行预处理。
所谓预处理是指图片数据在送入模型之前的特定处理操作,例如:图片resize、crop和padding等。
该工具集成于开发机模型转换编译的环境中,原始数据集经过工具预处理之后,会生成模型对应的前处理二进制文件.bin文件集.
直接运行 hb_eval_preprocess --help 可查看工具使用规则。
- 关于
hb_eval_preprocess工具命令行参数,可键入hb_eval_preprocess -h, 或查看 PTQ量化原理及步骤说明的 hb_eval_preprocess工具 一节内容。
下面将详细介绍示例包中每一个模型对应的数据集,以及对应数据集的预处理操作:
VOC数据集:该数据集主要用于ssd_mobilenetv1模型的评测, 其目录结构如下,示例中主要用到Main文件下的val.txt文件,JPEGImages中的源图片和Annotations中的标注数据:
.
└── VOCdevkit # 根目录
└── VOC2012 # 不同年份的数据集,这里只下载了2012的,还有2007等其它年份的
├── Annotations # 存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等
├── ImageSets # 该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本
│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages # 存放源图片
├── SegmentationClass # 存放的是图片,语义分割相关
└── SegmentationObject # 存放的是图片,实例分割相关
对数据集进行预处理:
hb_eval_preprocess -m ssd_mobilenetv1 -i VOCdevkit/VOC2012/JPEGImages -v VOCdevkit/VOC2012/ImageSets/Main/val.txt -o ./pre_ssd_mobilenetv1
COCO数据集:该数据集主要用于yolov2_darknet19、yolov3_darknet53、yolov5s、efficientdetd0、fcos_efficientnetb0和centernet_resnet50等检测模型的评测, 其目录如下,示例中主要用到annotations文件夹下的instances_val2017.json标注文件和images中的图片:
.
├── annotations # 存放标注数据
└── images # 存放源图片
对数据集进行预处理:
hb_eval_preprocess -m model_name -i coco/coco_val2017/images -o ./pre_model_name
ImageNet数据集:该数据集主要用于EfficientNet_lite0、EfficientNet_Lite1、EfficientNet_Lite2、EfficientNet_Lite3、EfficientNet_Lite4、MobileNet、GoogleNet、ResNet等分类模型的评测, 示例中主要用到了标注文件val.txt 和val目录中的源图片:
.
├── val.txt
└── val
对数据集进行预处理:
hb_eval_preprocess -m model_name -i imagenet/val -o ./pre_model_name
Cityscapes数据集:该数据集用于deeplabv3plus_efficientnetb0、deeplabv3plus_efficientnetm1、deeplabv3plus_efficientnetm2和fastscnn_efficientnetb0等分割模型的评测。 示例中主要用到了./gtFine/val中的标注文件和./leftImg8bit/val中的源图片。
.
├── gtFine
│ └── val
│ ├── frankfurt
│ ├── lindau
│ └── munster
└── leftImg8bit
└── val
├── frankfurt
├── lindau
└── munster
对数据集进行预处理:
hb_eval_preprocess -m unet_mobilenet -i cityscapes/leftImg8bit/val -o ./pre_unet_mobilenet
示例中精度计算脚本的运行流程是:
1、根据 workflow_accurary.json 中的 image_list_file 参数值,去寻找对应数据集的 lst 文件;
2、根据 lst 文件存储的前处理文件路径信息,去加载每一个前处理文件,然后进行推理
所以,生成预处理文件之后,需要生成对应的lst文件,将每一张前处理文件的路径写入到lst文件中,而这个路径与数据集在开发板端的存放位置有关。
这里我们推荐其存放位置与 script 文件夹同级目录,如下:
# RDK X3 使用如下格式:
|-- ptq
| |-- data
| | |-- cityscapes
| | | -- xxxx.bin # 前处理好的二进制文件
| | | -- ....
| | | -- cityscapes.lst # lst文件:记录每一个前处理文件的路径
| | |-- coco
| | | -- xxxx.bin
| | | -- ....
| | | -- coco.lst
| | |-- imagenet
| | | -- xxxx.bin
| | | -- ....
| | | -- imagenet.lst
| | `-- voc
| | | -- xxxx.bin
| | | -- ....
| | `-- voc.lst
| |-- model
| | |-- ...
| |-- script
| | |-- ...
# RDK Ultra 使用如下格式:
|-- ptq
| |-- data
| | |-- cityscapes
| | | |-- pre_deeplabv3plus_efficientnetb0
| | | | |-- xxxx.bin # 前处理好的二进制文件
| | | | |-- ....
| | | |-- pre_deeplabv3plus_efficientnetb0.lst # lst文件:记录每一个前处理文件的路径
| | | |-- pre_deeplabv3plus_efficientnetm1
| | | |-- pre_deeplabv3plus_efficientnetm1.lst
| | | |-- pre_deeplabv3plus_efficientnetm2
| | | |-- pre_deeplabv3plus_efficientnetm2.lst
| | | |-- pre_fastscnn_efficientnetb0
| | | |-- pre_fastscnn_efficientnetb0.lst
| | |-- coco
| | | |-- pre_centernet_resnet101
| | | | |-- xxxx.bin
| | | | |-- ....
| | | |-- pre_centernet_resnet101.lst
| | | |-- pre_yolov3_darknet53
| | | |-- pre_yolov3_darknet53.lst
| | | |-- pre_yolov3_vargdarknet
| | | |-- pre_yolov3_vargdarknet.lst
| | | |-- pre_yolov5x
| | | |-- pre_yolov5x.lst
| | | |-- pre_preq_qat_fcos_efficientnetb0
| | | |-- pre_preq_qat_fcos_efficientnetb0.lst
| | | |-- pre_preq_qat_fcos_efficientnetb2
| | | |-- pre_preq_qat_fcos_efficientnetb2.lst
| | | |-- pre_preq_qat_fcos_efficientnetb3
| | | |-- pre_preq_qat_fcos_efficientnetb3.lst
| | |-- imagenet
| | | |-- pre_efficientnasnet_m
| | | | |-- xxxx.bin
| | | | |-- ....
| | | |-- pre_efficientnasnet_m.lst
| | | |-- pre_efficientnasnet_s
| | | |-- pre_efficientnasnet_s.lst
| | | |-- pre_efficientnet_lite4
| | | |-- pre_efficientnet_lite4.lst
| | | |-- pre_googlenet
| | | |-- pre_googlenet.lst
| | | |-- pre_mobilenetv1
| | | |-- pre_mobilenetv1.lst
| | | |-- pre_mobilenetv2
| | | |-- pre_mobilenetv2.lst
| | | |-- pre_resnet18
| | | |-- pre_resnet18.lst
| | | |-- pre_vargconvnet
| | | |-- pre_vargconvnet.lst
| | |-- voc
| | | |-- pre_ssd_mobilenetv1
| | | | |-- xxxx.bin
| | | | |-- ....
| | | |-- pre_ssd_mobilenetv1.lst
| |-- model
| | |-- ...
| |-- script
| | |-- ...
与之对应的lst文件,参考生成方式如下:
# RDK X3 请使用如下命令:
find ../../../data/coco/fcos -name "*bin*" > ../../../data/coco/coco.lst
# RDK Ultra 请使用如下命令:
find ../../../data/coco/pre_centernet_resnet101 -name "*bin*" > ../../../data/coco/pre_centernet_resnet101.lst
这样生成的lst文件中存储的路径为一个相对路径: ../../../data/ 或 ../../../data/coco/pre_centernet_resnet101/ ,可以与 workflow_accuracy.json 默认的配置路径吻合。
如果需要更改前处理数据集的存放位置,则需要�确保对应的 lst 文件可以被 workflow_accuracy.json 读取到;其次需要确保程序根据 lst 中的路径信息,能读取到对应的前处理文件。
-
数据挂载
由于数据集相对较大,不适合直接放在开发板上,可以采用nfs挂载的方式供开发板读取。
开发机PC端(需要root权限):
- 编辑 /etc/exports, 增加一行:
/nfs *(insecure,rw,sync,all_squash,anonuid=1000,anongid=1000,no_subtree_check)。/nfs表示本机挂载路径,可替换为用户指定目录 - 执行命令
exportfs -a -r,使/etc/exports 生效。
开发板端:
- 创建需要挂载的目录:
mkdir -p /mnt。 mount -t nfs {PC端IP}:/nfs /mnt -o nolock。
完成将PC端的/nfs文件夹挂载至板端/mnt文件夹。按照此方式,将包含预处理数据的文件夹挂载至板端,并将/data目录软链接至板端/ptq目录下,与/script同级目录。
-
模型推理
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
挂载完数据后,请登录开发板,开发板登录方法,请阅读开发板登录 章节内容,登录成功后,执行 fcos_efficientnetb0/ 目录下的accuracy.sh脚本,如下所示:
/userdata/ptq/script/detection/fcos# sh accuracy.sh
../../aarch64/bin/example --config_file=workflow_accuracy.json --log_level=2
...
I0419 03:14:51.158655 39555 infer_method.cc:107] Predict DoProcess finished.
I0419 03:14:51.187361 39556 ptq_fcos_post_process_method.cc:123] PTQFcosPostProcessMethod DoProcess finished, predict result: [{"bbox":[-1.518860,71.691170,574.934631,638.294922],"prob":0.750647,"label":21,"class_name":"
I0118 14:02:43.636204 24782 ptq_fcos_post_process_method.cc:123] PTQFcosPostProcessMethod DoProcess finished, predict result: [{"bbox":[3.432283,164.936249,157.480042,264.276825],"prob":0.544454,"label":62,"class_name":"
...
开发板端程序会在当前目录生成 eval.log 文件,该文件就是预测结果文件。
-
精度计算
精度计算部分请在 开发机 模型转换的环境下操作
精度计算的脚本在 python_tools 目录下,其中 accuracy_tools 中的:
cls_eval.py是用来计算分类模型的精度;
coco_det_eval.py是用来计算使用COCO数据集评测的检测模型的精度;
parsing_eval.py是用来计算使用Cityscapes数据集评测的分割模型的精度。
voc_det_eval.py是用来计算使用VOC数据集评测的检测模型的精度。
- 分类模型
使用CIFAR-10数据集和ImageNet数据集的分类模型计算方式如下:
#!/bin/sh
python3 cls_eval.py --log_file=eval.log --gt_file=val.txt
log_file:分类模型的预测结果文件。gt_file:CIFAR-10和ImageNet数据集的标注文件。
- 检测模型
使用COCO数据集的检测模型精度计算方式如下:
#!/bin/sh
python3 coco_det_eval.py --eval_result_path=eval.log --annotation_path=instances_val2017.json
eval_result_path:检测模型的预测结果文件。annotation_path:COCO数据集的标注文件。
使用VOC数据集的检测模型精度计算方式如下:
#!/bin/sh
python3 voc_det_eval.py --eval_result_path=eval.log --annotation_path=../Annotations --val_txt_path=../val.txt
eval_result_path:检测模型的预测结果文件。annotation_path:VOC数据集的标注文件。val_txt_path:VOC数据集中ImageSets/Main文件夹下的val.txt文件。
- 分割模型
使用Cityscapes数据集的分割模型精度计算方式如下:
:linenos:
#!/bin/sh
python3 parsing_eval.py --width=output_width --height=output_height --log_file=eval.log --gt_path=cityscapes/gtFine/val
width: 分割模型的输出宽度height: 分割模型的输出高度log_file:分割模型的预测结果文件。gt_path:Cityscapes数据集的标注文件。
模型集成
模型后处理集成主要有2个步骤,以centernet_resnet50模型集成为例:
- 增加后处理文件
ptq_centernet_post_process_method.cc,以及头文件ptq_centernet_post_process_method.h。 - 增加模型运行脚本及配置文件。
后处理文件添加
以下示例是使用 RDK X3 开发板举例,若使用 RDK Ultra 开发板信息会有所差异,以具体为准!
后处理代码文件可直接复用src/method目录下任意后处理文件,主要修改 InitFromJsonString 函数,以及 PostProcess 函数即可。
InitFromJsonString 函数主要是读取workflow.json中的后处理相关的参数配置,用户可自定义设置相应的输入参数。
PostProcess 函数主要完成后处理的逻辑。
后处理.cc文件放置于 ai_benchmark/code/src/method/ 路径下,
.h头文件放置于 ai_benchmark/code/include/method/ 路径下:
|--ai_benchmark
| |--code # 示例源码
| | |--include
| | | |--method # 在此文件夹中添加头文件
| | | | |--ptq_centernet_post_process_method.h
| | | | |--......
| | | | |--ptq_yolo5_post_process_method.h
| | |--src
| | | |--method # 在此文件夹中添加后处理.cc文件
| | | | |--ptq_centernet_post_process_method.cc
| | | | |--......
| | | | |--ptq_yolo5_post_process_method.cc
增加模型运行脚本及配置文件
脚本目录结构如下:
|--ai_benchmark
| |--xj3/ptq/script # 示例脚本文件夹
| | |--detection
| | | |--centernet_resnet50
| | | | |--accuracy.sh # 精度测试脚本
| | | | |--fps.sh # 性能测试脚本
| | | | |--latency.sh # 单帧延时示例脚本
| | | | |--workflow_accuracy.json # 精度配置文件
| | | | |--workflow_fps.json # 性能配置文件
| | | | |--workflow_latency.json # 单帧延时配置文件
辅助工具和常用操作
日志系统使用说明
日志系统主要包括 示例日志 和 模型推理API DNN日志 两部分。
其中示例日志是指交付包示例代码中的应用日志;DNN日志是指lib dnn库中的日志。
用户根据不同的需求可以获取不同的日志。
- 示例日志
- 日志等级。示例日志主要采用glog中的vlog,主要分为四个自定义等级:
0(SYSTEM),该等级主要用来输出报错信息;1(REPORT),该等级在示例代码中主要用来输出性能数据;2(DETAIL),该等级在示例代码中主要用来输出系统当前状态信息;3(DEBUG),该等级在示例代码中主要用来输出调试信息。 日志等级设置规则:假设设置了级别为P,如果发生了一个级别Q比P低, 则可以启动,否则屏蔽掉;默认DEBUG>DETAIL>REPORT>SYSTEM。
- 日志等级设置。通过
log_level参数来设置日志等级,在运行示例的时候,指定log_level参数来设置等级, 比如指定log_level=0,即输出SYSTEM日志;如果指定log_level=3, 则输出DEBUG、DETAIL、REPORT和SYSTEM日志。
- 模型推理API DNN日志
关于模型推理 DNN API日志的配置,请阅读《算法工具链产品手册》。
算子耗时说明
对模型算子(OP)性能的统计是通过设置 HB_DNN_PROFILER_LOG_PATH 环境变量实现的,本节介绍模型的推理性能分析,有助于开发者了解模型的真实推理性能情况。
对该变量的类型和取值说明如下:
export HB_DNN_PROFILER_LOG_PATH=${path}:表示OP节点dump的输出路径,程序正常运行完退出后,产生profiler.log文件。
- 示例说明
以下示例是使用 RDK X3 开发板举例,若使用 RDK Ultra 开发板信息会有所差异,以具体为准!
以下代码块以mobilenetv1模型为例,开启单个线程同时RunModel,设置 export HB_DNN_PROFILER_LOG_PATH=./,则统计输出的信息如下:
{
"perf_result": {
"FPS": 677.6192525182025,
"average_latency": 11.506142616271973
},
"running_condition": {
"core_id": 0,
"frame_count": 200,
"model_name": "mobilenetv1_224x224_nv12",
"run_time": 295.151,
"thread_num": 1
}
}
***
{
"chip_latency": {
"BPU_inference_time_cost": {
"avg_time": 11.09122,
"max_time": 11.54,
"min_time": 3.439
},
"CPU_inference_time_cost": {
"avg_time": 0.18836999999999998,
"max_time": 0.4630000000000001,
"min_time": 0.127
}
},
"model_latency": {
"BPU_MOBILENET_subgraph_0": {
"avg_time": 11.09122,
"max_time": 11.54,
"min_time": 3.439
},
"Dequantize_fc7_1_HzDequantize": {
"avg_time": 0.07884999999999999,
"max_time": 0.158,
"min_time": 0.068
},
"MOBILENET_subgraph_0_output_layout_convert": {
"avg_time": 0.018765,
"max_time": 0.08,
"min_time": 0.01
},
"Preprocess": {
"avg_time": 0.0065,
"max_time": 0.058,
"min_time": 0.003
},
"Softmax_prob": {
"avg_time": 0.084255,
"max_time": 0.167,
"min_time": 0.046
}
},
"task_latency": {
"TaskPendingTime": {
"avg_time": 0.029375,
"max_time": 0.059,
"min_time": 0.009
},
"TaskRunningTime": {
"avg_time": 11.40324,
"max_time": 11.801,
"min_time": 4.008
}
}
}
以上输出了 model_latency 和 task_latency。其中model_latency中输出了模型每个OP运行所需要的耗时情况,task_latency中输出了模型运行中各个task模块的耗时情况。
程序只有正常退出才会输出profiler.log文件。
dump工具
本节主要介绍dump工具的开启方法,一般不需要关注,只有在模型精度异常情况时开启使用。
通过设置 export HB_DNN_DUMP_PATH=${path} 这个环境变量,可以dump出模型推理过程中每个节点的输入和输出, 根据dump的输出结果,可以排查模型推理在开发机模拟器和开发板是否存在一致性问题:即相同模型,相同输入,开发板和开发机模拟器的输出结果是否完全相同。
模型上板分析工具说明
概述
本章节介绍D-Robotics 算法工具链中模型上板推理的快速验证工具,方便开发者可以快速获取到 ***.bin 模型的信息、模型推理的性能、模型debug等内容。
hrt_model_exec 工具使用说明
hrt_model_exec 工具,可以快速在开发板上评测模型的推理性能、获取模型信息等。
目前工��具提供了三类功能,如下表所示:
| 编号 | 子命令 | 说明 |
|---|---|---|
| 1 | model_info | 获取模型信息,如:模型的输入输出信息等。 |
| 2 | infer | 执行模型推理,获取模型推理结果。 |
| 3 | perf | 执行模型性能分析,获取性能分析结果。 |
工具也可以通过 -v 或者 --version 命令,查看工具的 dnn 预测库版本号。
例如: hrt_model_exec -v 或 hrt_model_exec --version
输入参数描述
在开发板上运行 hrt_model_exec 、 hrt_model_exec -h 或 hrt_model_exec --help 获取工具的使用参数详情。
如下图中所示:
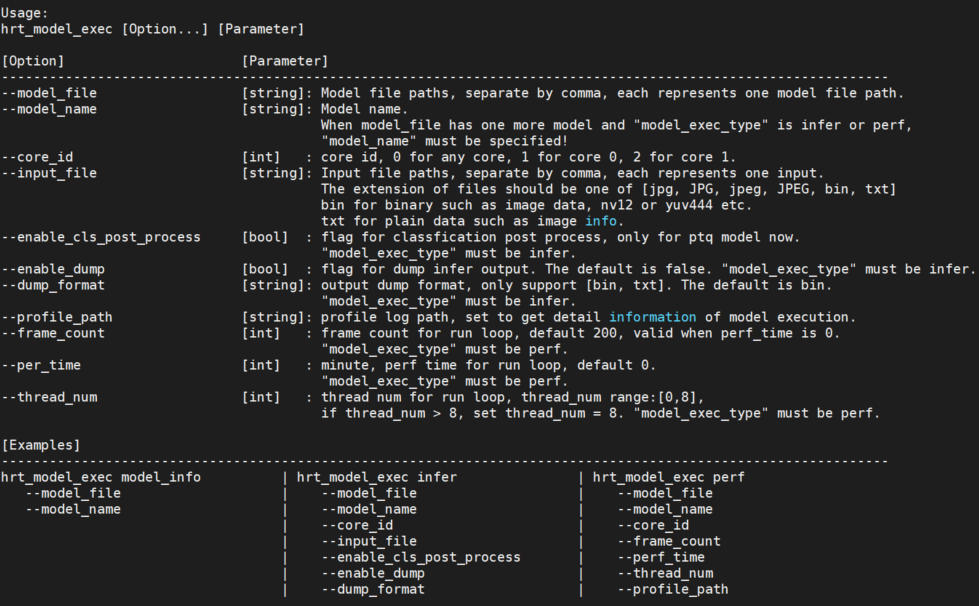
| 编号 | 参数 | 类型 | 说明 |
|---|---|---|---|
| 1 | model_file | string | 模型文件路径,多个路径可通过逗号分隔。 |
| 2 | model_name | string | 指定模型中某个模型的名称。 |
| 3 | core_id | int | 指定运行核。 |
| 4 | input_file | string | 模型输入信息,多个可通过逗号分隔。 |
| 5 | roi_infer | bool | 使能resizer模型推理。 |
| 6 | roi | string | 指定推理resizer模型时所需的roi区域。 |
| 7 | frame_count | int | 执行模型运行帧数。 |
| 8 | dump_intermediate | string | dump模型每一层输入和输出。 |
| 9 | enable_dump | bool | 使能dump模型输入和输出。 |
| 10 | dump_precision | int | 控制txt格式输出float型数据的小数点位数。 |
| 11 | hybrid_dequantize_process | bool | 控制txt格式输出float类型数据。 |
| 12 | dump_format | string | dump模型输入和输出的格式。 |
| 13 | dump_txt_axis | int | 控制txt格式输入输出的换行规则。 |
| 14 | enable_cls_post_process | bool | 使能分类后处理。 |
| 15 | perf_time | int | 执行模型运行时间。 |
| 16 | thread_num | int | 指定程�序运行线程数。 |
| 17 | profile_path | string | 模型性能/调度性能统计数据的保存路径。 |
使用说明
本节介绍 hrt_model_exec 工具的三个子功能的具体使用方法
model_info
- 概述
该参数用于获取模型信息,模型支持范围:QAT模型,PTQ模型。
该参数与 model_file 一起使用,用于获取模型的详细信息;
模型的信息包括:模型输入输出信息 hbDNNTensorProperties 和模型的分段信息 stage ;模型的分段信息是:一张图片可以分多个阶段进行推理,stage信息为[x1, y1, x2, y2],分别为图片推理的左上角和右下角坐标,目前D-Robotics RDK Ultra的bayes架构支持这类分段模型的推理,RDK X3上模型均为1个stage。
不指定 model_name ,则会输出模型中所有模型信息,指定 model_name ,则只输出对应模型的信息。
- 示例说明
- 单模型
hrt_model_exec model_info --model_file=xxx.bin
- 多模型(输出所有模型信息)
hrt_model_exec model_info --model_file=xxx.bin,xxx.bin
- 多模型--pack模型(输出指定模型信息)
hrt_model_exec model_info --model_file=xxx.bin --model_name=xx
输入参数补充说明
- 重复输入
若重复指定参数输入,则会发生参数覆盖的情况,例如:获取模型信息时重复指定了两个模型文件,则会取后面指定的参数输入 yyy.bin:
hrt_model_exec model_info --model_file=xxx.bin --model_file=yyy.bin
若重复指定输入时,未加命令行参--model_file,则会取命令行参数后面的值,未加参数的不识别,
例如:下例会忽略 yyy.bin,参数值为 xxx.bin:
hrt_model_exec model_info --model_file=xxx.bin yyy.bin
infer
- 概述
该参数用于输入自定义��图片后,模型推理一帧,并给出模型推理结果。
该参数需要与 input_file 一起使用,指定输入图片路径,工具根据模型信息resize图片,整理模型输入信息。
程序单线程运行单帧数据,输出模型运行的时间。
- 示例说明
- 单模型
hrt_model_exec infer --model_file=xxx.bin --input_file=xxx.jpg
- 多模型
hrt_model_exec infer --model_file=xxx.bin,xxx.bin --model_name=xx --input_file=xxx.jpg

-
可选参数
参数 说明 core_id指定模型推理的核id,0:任意核,1:core0,2:core1;默认为 0。roi_infer使能resizer模型推理;若模型输入包含resizer源,设置为 true,默认为false。roiroi_infer为true时生效,设置推理resizer模型时所需的roi区域以分号间隔。frame_count设置 infer运行帧数,单帧重复推理,可与enable_dump并用,验证输出一致性,默认为1。dump_intermediatedump模型每一层输入数据和输出数据,默认值 0,不dump数据。1:输出文件类型为bin;2:输出类型为bin和txt,其中BPU节点输出为aligned数据;3:输出类型为bin和txt,其中BPU节点输出为valid数据。enable_dumpdump模型输出数据,默认为 false。dump_precision控制txt格式输出float型数据的小数点位数,默认为 9。hybrid_dequantize_process控制txt格式输出float类型数据,若输出为定点数据将其进行反量化处理,目前只支持四维模型。 dump_formatdump模型输出文件的类型,可选参数为 bin或txt,默认为bin。dump_txt_axisdump模型txt格式输出的换行规则;若输出维度为n,则参数范围为[0, n], 默认为 4。enable_cls_post_process使能分类后处理,目前只支持ptq分类模型,默认 false。
多输入模型说明
工具 infer 推理功能支持多输入模型的推理,支持图片输入、二进制文件输入以及文本文件输入,输入数据用逗号隔开。
模型的输入信息可以通过 model_info 进行查看。
- 示例说明
hrt_model_exec infer --model_file=xxx.bin --input_file=xxx.jpg,input.txt
输入参数补充说明
input_file
图片类型的输入,其文件名后缀必须为 bin / JPG / JPEG / jpg / jpeg 中的一种�,feature输入后缀名必须为 bin / txt 中的一种。
每个输入之间需要用英文字符的逗号隔开 ,,例如: xxx.jpg,input.txt。
enable_cls_post_process
使能分类后处理。子命令为 infer 时配合使用,目前只支持在PTQ分类模型的后处理时使用,变量为 true 时打印分类结果。
参见下图:
roi_infer
若模型包含resizer输入源, infer 和 perf 功能都需要设置 roi_infer 为true,并且配置与输入源一一对应的 input_file 和 roi 参数。
如:模型有三个输入,输入源顺序分别为[ddr, resizer, resizer],则推理两组输入数据的命令行如下:
// infer
hrt_model_exec infer --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
// perf
hrt_model_exec perf --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
每个 roi 输入之间需要用英文字符的分号隔开。
dump_intermediate
dump模型每一层节点的输入数据和输出数据。 dump_intermediate=0 时,默认dump功能关闭;
dump_intermediate=1 时,模型中每一层节点输入数据和输出数据以 bin 方式保存,其中 BPU 节点输出为 aligned 数据;
dump_intermediate=2 时,模型中每一层节点输入数据和输出数据以 bin 和 txt 两种方式保存,其中 BPU 节点输出为 aligned 数据;
dump_intermediate=3 时,模型中每一层节点输入数据和输出数据以 bin 和 txt 两种方式保存,其中 BPU 节点输出为 valid 数据。
如: 模型有两个输入,输入源顺序分别为[pyramid, ddr],将模型每一层节点的输入和输出保存为 bin 文件,其中 BPU 节点输出按 aligned 类型保存,则推理命令行如下:
hrt_model_exec infer --model_file=xxx.bin --input_file="xx0.jpg,xx1.bin" --dump_intermediate=1
dump_intermediate 参数支持 infer 和 perf 两种模式。
hybrid_dequantize_process
控制txt格式输出float类型数据。 hybrid_dequantize_process 参数在 enable_dump=true 时生效。
当 enable_dump=true 时,若设置 hybrid_dequantize_process=true ,反量化整型输出数据,将所有输出按float类型保存为 txt 文件,其中模型输出为 valid 数据,支持配置 dump_txt_axis 和 dump_precision;
若设置 hybrid_dequantize_process=false ,直接保存模型输出的 aligned 数据,不做任何处理。
如: 模型有3个输出,输出Tensor数据类型顺序分别为[float,int32,int16], 输出txt格式float类型的 valid 数据, 则推理命令行如下:
// 输出float类型数据
hrt_model_exec infer --model_file=xxx.bin --input_file="xx.bin" --enable_dump=true --hybrid_dequantize_process=true
hybrid_dequantize_process 参数目前只支持四维模型。
perf
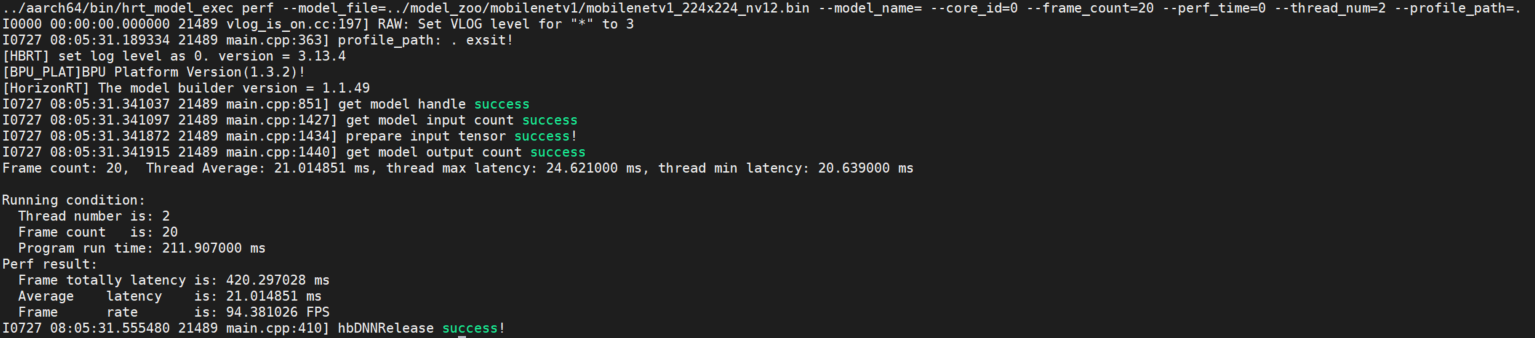
- 概述
该参数用于测试模型的推理性能。 使用此工具命令,用户无需输入数据,程序会根据模型信息自动构造模型的输入tensor,tensor数据为随机数。 程序��默认单线程运行200帧数据,当指定perf_time参数时,frame_count参数失效,程序会执行指定时间后退出。 程序运行完成后,会输出模型运行的程序线程数、帧数、模型推理总时间,模型推理平均latency,帧率信息等。
程序每200帧打印一次性能信息:latnecy的最大、最小、平均值,不足200帧程序运行结束打印一次。
- 示例说明
- 单模型
hrt_model_exec perf --model_file=xxx.bin
- 多模型
hrt_model_exec perf --model_file=xxx.bin,xxx.bin --model_name=xx
-
可选参数
参数 说明 core_id指定模型推理的核id,0:任意核,1:core0,2:core1;默认为 0。input_file模型输入信息,多个可通过逗号分隔。 roi_infer使能resizer模型推理;若模型输入包含resizer源,设置为 true,默认为false。roiroi_infer为true时生效,设置推理resizer模型时所需的roi区域以分号间隔。frame_count设置 perf运行帧数,当perf_time为0时生效,默认为200。dump_intermediatedump模型每一层输入数据和输出数据,默认值 0,不dump数据。1:输出文件类型为bin;2:输出类型为bin和txt,其中BPU节点输出为aligned数据;3:输出类型为bin和txt,其中BPU节点输出为valid数据。perf_time设置 perf运行时间,单位:分钟,默认为0。thread_num设置程序运行线程数,范围[1, 8], 默认为 1, 设置大于8时按照8个线程处理。profile_path统计工具日志产生路径,运行产生profiler.log和profiler.csv,分析op耗时和调度耗时。时。
多线程Latency数据说明
多线程的目的是为了充分利用BPU资源,多线程共同处理 frame_count 帧数据或执行perf_time时间,直至数据处理完成/执行时间结束程序结束。
在多线程 perf 过程中可以执行以下命令,实时获取BPU资源占用率情况。
hrut_somstatus -n 10000 –d 1
输出内容如下:
=====================1=====================
temperature-->
CPU : 37.5 (C)
cpu frequency-->
min cur max
cpu0: 240000 1200000 1200000
cpu1: 240000 1200000 1200000
cpu2: 240000 1200000 1200000
cpu3: 240000 1200000 1200000
bpu status information---->
min cur max ratio
bpu0: 400000000 1000000000 1000000000 0
bpu1: 400000000 1000000000 1000000000 0
以上示例展示的为 RDK X3 开发板的输出日志, 若使用 RDK Ultra 开发板,直接使用上述命令获取即可。
在 perf 模式下,单线程的latency时间表示模型的实测上板性能,
而多线程的latency数据表示的是每个线程的模型单帧处理时间,其相对于单线程的时间要长,但是多线程的总体处理时间减少,其帧率是提升的。
输入参数补充说明
profile_path
profile日志文件产生目录。
该参数通过设置环境变量 export HB_DNN_PROFILER_LOG_PATH=${path} 查看模型运行过程中OP以及任务调度耗时。
一般设置 --profile_path="." 即可,代表在当前目录下生成日志文件,日志文件为profiler.log。
thread_num
线程数(并行度),数值表示最多有多少个任务在并行处理。 测试延时时,数值需要设置为1,没有资源抢占发生,延时测试更准确。 测试吞吐时,建议设置>2 (BPU核心个数),调整线程数使BPU利用率尽量高,吞吐测试更准确。
// 双核FPS
hrt_model_exec perf --model_file xxx.bin --thread_num 8 --core_id 0
// Latency
hrt_model_exec perf --model_file xxx.bin --thread_num 1 --core_id 1
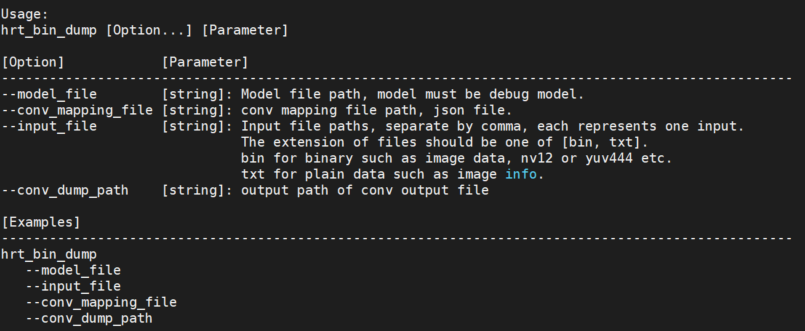
hrt_bin_dump 工具使用说明
hrt_bin_dump 是 PTQ debug模型的layer dump工具,工具的输出文件为二进制文件。
输入参数描述
| 编号 | 参数 | 类型 | 描述 | 说明 |
|---|---|---|---|---|
| 1 | model_file | string | 模型文件路径。 | 必须为debug model。即模型的编译参数 layer_out_dump 需要设置为 True,指定模型转换过程中输出各层的中间结果。 |
| 2 | input_file | string | 输入文件路径。 | 模型的输入文件,支持 hbDNNDataType 所有类型的输入; IMG类型文件需为二进制文件(后缀必须为.bin),二进制文件的大小应与模型的输入信息相匹配,如:YUV444文件大小为 :math:height * width * 3; TENSOR类型文件需为二进制文件或文本文件(后缀必须为.bin/.txt),二进制文件的大小应与模型的输入信息相匹配,文本文件的读入数据个数必须大于等于模型要求的输入数据个数,多余的数据会被丢弃;每个输入之间通过逗号分隔,如:模型有两个输入,则: --input_file=kite.bin,input.txt。 |
| 3 | conv_mapping_file | string | 模型卷积层配置文件。 | 模型layer配置文件,配置文件中标明了模型各层信息,在模型编译过程中生成。文件名称一般为: model_name_quantized_model_conv_output_map.json。 |
| 4 | conv_dump_path | string | 工具输出路径。 | 工具的输出路径,该路径应为合法路径。 |
使用说明
工具提供dump卷积层输出功能,输出文件为二进制文件。
直接运行 hrt_bin_dump 获取工具使用详情。
参见下图:
工具也可以通过 -v 或者 --version 命令,查看工具的 dnn 预测库版本号。
例如: hrt_bin_dump -v 或 hrt_bin_dump --version
示例说明
以mobilenetv1的debug模型为例,创建outputs文件夹,执行以下命令:
./hrt_bin_dump --model_file=./mobilenetv1_hybrid_horizonrt.bin --conv_mapping_file=./mobilenetv1_quantized_model_conv_output_map.json --conv_dump_path=./outputs --input_file=./zebra_cls.bin
运行日志参见以下截图:

在路径 outputs/ 文件夹下可以查看输出,参见以下截图:

RDK X5
模型推理DNN API使用示例说明
概述
本章节介绍模型上板运行 horizon_runtime_sample 示例包的具体用法,开发者可以体验并基于这些示例进行应用开发,降低开发门槛。
示例包提供三个方面的示例:
- 模型推理 dnn API使用示例。
- 自定义算子(custom OP)等特殊功能示例。
- 非NV12输入模型的杂项示例。
详细内容请阅读下文。
小技巧:
horizon_runtime_sample 示例包获取请参考《交付物说明》。
示例代码包结构介绍
+---horizon_runtime_sample
|-- code # 示例源码
| |-- 00_quick_start # 快速入门示例,用mobilenetv1读取单张图片进行推理的示例代码
| | |-- CMakeLists.txt
| | |-- CMakeLists_x86.txt
| | `-- src
| |-- 01_api_tutorial # BPU SDK DNN API使用示例代码
| | |-- CMakeLists.txt
| | |-- mem
| | |-- model
| | |-- roi_infer
| | `-- tensor
| |-- 02_advanced_samples # 特殊功能示例
| | |-- CMakeLists.txt
| | |-- custom_identity
| | |-- multi_input
| | |-- multi_model_batch
| | `-- nv12_batch
| |-- 03_misc # 杂项示例
| | |-- CMakeLists.txt
| | |-- lenet_gray
| | `-- resnet_feature
| |-- build_x5.sh # 上板aarch64编译脚本
| |-- build_x86.sh # PC端X86编译脚本
| |-- CMakeLists.txt
| |-- CMakeLists_x86.txt
| `-- deps_gcc11.3 # 编译依赖库
| |-- aarch64
| `-- x86
|-- README.md
`-- x5
|-- data # 预置数据文件
| |-- cls_images
| |-- custom_identity_data
| |-- det_images
| |-- dsl_data
| `-- misc_data
|-- model
| |-- README.md
| `-- runtime -> ../../../model_zoo/runtime/horizon_runtime_sample # 软链接指向OE包中的模型,板端运行环境需要自行指定模型路径
|-- script # aarch64示例运行脚本
| |-- 00_quick_start
| |-- 01_api_tutorial
| |-- 02_advanced_samples
| |-- 03_misc
| `-- README.md
`-- script_x86 # x86示例运行脚本
|-- 00_quick_start
`-- README.md
- code:该目录内是示例的源码。
- code/00_quick_start:快速入门示例,基于 dnn API,用mobilenetv1进行单张图片模型推理和结果解析。
- code/01_api_tutorial:dnn API使用教学代码,包括 mem, model , roi_infer 和 tensor 四部分。
- code/02_advanced_samples:�特殊功能示例,包括 custom_identity, multi_input, multi_model_batch 和 nv12_batch 功能。
- ode/03_misc:非NV12输入模型的杂项示例。
- code/build_x5.sh:程序一键编译脚本。
- code/build_x86.sh:x86仿真环境一键编译脚本。
- code/deps_gcc11.3:示例代码所需要的三方依赖, 用户在开发自己代码程序的时候可以根据实际情况替换或者裁剪。
- x5:示例运行脚本,预置了数据和相关模型
注意:
私有模型上板运行,请参考 00_quick_start/src/run_mobileNetV1_224x224.cc 示例代码流程进行代码重写,编译成功后可以在开发板上测试验证!
环境构建
开发板准备
-
拿到开发板后,请将开发版镜像更新到最新版本,升级方法请参考系统更新 章节内容。
-
确保本地开发机和开发板可以远程连接。
编译
编译需要当前环境安装好交叉编译工具: arm-gnu-toolchain-11.3.rel1-x86_64-aarch64-none-linux-gnu。 请使用X5算法工具链提供的开发机Docker镜像,直接进行编译使用。开发机Docker环境的获取及使用方法,请阅读环境安装 章节内容;
根据自身使用的开发板情况,请使用horizon_runtime_sample/code目录下的 build_x5.sh 脚本,即可一键编译开发板环境下的可执行程序,可执行程序和对应依赖会自动复制到 x5/script 目录下的 aarch64 目录下。
备注:
工程通过获取环境变量 LINARO_GCC_ROOT 来指定交叉编译工具的路径,用户使用之前可以检查本地的环境变量是否为目标交叉编译工具。
如果需要指定交叉编译工具路径,可以设置环境变量 LINARO_GCC_ROOT , 或者直接修改脚本 build_x5.sh,指定变量 CC 和 CXX。
export CC=/opt/arm-gnu-toolchain-11.3.rel1-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-gcc
export CXX=/opt/arm-gnu-toolchain-11.3.rel1-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-g++
示例使用
basic_samples 示例
模型推理示例脚本主要在 x5/script 和 x5/script_x86 目录下,编译程序后目录结构如下:
# X5 使用脚本信息
├── data
│ ├── cls_images
│ │ ├── cat_cls.jpg
│ │ └── zebra_cls.jpg
│ ├── custom_identity_data
│ │ ├── input0.bin
│ │ └── input1.bin
│ ├── det_images
│ │ └── kite.jpg
│ ├── dsl_data
│ │ └── zebra_bgr.bin
│ └── misc_data
│ ├── 7.bin
│ └── np_0
├── model
│ ├── README.md
│ └── runtime -> ../../../model_zoo/runtime/horizon_runtime_sample
├── script # 编译产生可执行程序及依赖库
│ ├── 00_quick_start
│ │ ├── README.md
│ │ └── run_mobilenetV1.sh
│ ├── 01_api_tutorial
│ │ ├── README.md
│ │ ├── model.sh
│ │ ├── roi_infer.sh
│ │ ├── sys_mem.sh
│ │ └── tensor.sh
│ ├── 02_advanced_samples
│ │ ├── README.md
│ │ ├── plugin
│ │ │ └── custom_arm_op_custom_identity.sh
│ │ ├── run_multi_input.sh
│ │ ├── run_multi_model_batch.sh
│ │ └── run_nv12_batch.sh
│ ├── 03_misc
│ │ ├── README.md
│ │ ├── run_lenet.sh
│ │ └── run_resnet50_feature.sh
│ ├── README.md
│ └── aarch64
│ ├── bin
│ │ ├── model_example
│ │ ├── roi_infer
│ │ ├── run_custom_op
│ │ ├── run_lenet_gray
│ │ ├── run_mobileNetV1_224x224
│ │ ├── run_multi_model_batch
│ │ ├── run_resnet_feature
│ │ ├── sys_mem_example
│ │ └── tensor_example
│ └── lib
│ ├── libdnn.so
│ ├── libhbrt_bayes_aarch64.so
│ └── libopencv_world.so.3.4
└── script_x86
├── 00_quick_start
│ ├── README.md
│ └── run_mobilenetV1.sh
└── README.md
备注:
- model文件夹下包含模型的路径,其中
runtime文件夹为软链接,链接路径为../../../model_zoo/runtime/horizon_runtime_sample,可直接找到交付包中的模型路径 - 板端运行环境需要将模型放至
model文件夹下
quick_start
00_quick_start 目录下的是模型推理的快速开始示例:
00_quick_start/
├── README.md
└── run_mobilenetV1.sh
run_mobilenetV1.sh:该脚本实现使用mobilenetv1模型读取单张图片进行推理的示例功能。使用的时候,进入 00_quick_start 目录, 然后直接执行 sh run_mobilenetV1.sh 即可,如下代码块所示:
#!/bin/sh
root@x5dvb:/userdata/app/horizon/basic_samples/x5/script/00_quick_start# sh run_mobilenetV1.sh
../aarch64/bin/run_mobileNetV1_224x224 --model_file=../../model/runtime/mobilenetv1/mobilenetv1_224x224_nv12.bin --image_file=../../data/cls_images/zebra_cls.jpg --top_k=5
I0000 00:00:00.000000 10765 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[BPU_PLAT]BPU Platform Version(1.3.3)!
[HBRT] set log level as 0. version = 3.15.18.0
[DNN] Runtime version = 1.17.2_(3.15.18 HBRT)
[A][DNN][packed_model.cpp:225][Model](2023-04-11,17:51:17.206.804) [HorizonRT] The model builder version = 1.15.0
I0411 17:51:17.244180 10765 run_mobileNetV1_224x224.cc:135] DNN runtime version: 1.17.2_(3.15.18 HBRT)
I0411 17:51:17.244376 10765 run_mobileNetV1_224x224.cc:252] input[0] name is data
I0411 17:51:17.244508 10765 run_mobileNetV1_224x224.cc:268] output[0] name is prob
I0411 17:51:17.260176 10765 run_mobileNetV1_224x224.cc:159] read image to tensor as nv12 success
I0411 17:51:17.262075 10765 run_mobileNetV1_224x224.cc:194] TOP 0 result id: 340
I0411 17:51:17.262118 10765 run_mobileNetV1_224x224.cc:194] TOP 1 result id: 292
I0411 17:51:17.262148 10765 run_mobileNetV1_224x224.cc:194] TOP 2 result id: 282
I0411 17:51:17.262177 10765 run_mobileNetV1_224x224.cc:194] TOP 3 result id: 83
I0411 17:51:17.262205 10765 run_mobileNetV1_224x224.cc:194] TOP 4 result id: 290
api_tutorial
01_api_tutorial 目录下的示例,用于介绍如何使用嵌入式API。其目录包含以下脚本:
├── model.sh
├── roi_infer.sh
├── sys_mem.sh
└── tensor.sh
model.sh:该脚本主要实现读取模型信息的功能。 使用的时候,直接进入 01_api_tutorial 目录,然后直接执行sh model.sh即可,如下所示:
#!/bin/sh
root@x5dvb-hynix8G:/userdata/horizon/x5/script/01_api_tutorial# sh model.sh
../aarch64/bin/model_example --model_file_list=../../model/runtime/mobilenetv1/mobilenetv1_224x224_nv12.bin
I0000 00:00:00.000000 10810 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[BPU_PLAT]BPU Platform Version(1.3.3)!
[HBRT] set log level as 0. version = 3.15.18.0
[DNN] Runtime version = 1.17.2_(3.15.18 HBRT)
[A][DNN][packed_model.cpp:225][Model](2023-04-11,17:53:28.970.396) [HorizonRT] The model builder version = 1.15.0
I0411 17:53:29.007853 10810 model_example.cc:104] model count:1, model[0]: mobilenetv1_224x224_nv12
I0411 17:53:29.007939 10810 model_example.cc:112] hbDNNGetModelHandle [mobilenetv1_224x224_nv12] success!
I0411 17:53:29.008011 10810 model_example.cc:186] [mobilenetv1_224x224_nv12] Model Info: input num: 1, input[0] validShape: ( 1, 3, 224, 224 ), alignedShape: ( 1, 3, 224, 224 ), tensorType: 1, output num: 1, output[0] validShape: ( 1, 1000, 1, 1 ), alignedShape: ( 1, 1000, 1, 1 ), tensorType: 13
-
roi_infer.sh: 该脚本主要引导如何使用hbDNNRoiInfer这个API,示例代码实现的功能是将一张图片resize到模型输入大小,转为nv12数据,并给定roi框进行模型推理(infer)。 使用的时候,直接进入 01_api_tutorial 目录,然后直接执行sh roi_infer.sh即可。 -
sys_mem.sh:该脚本主要引导如何使用hbSysAllocMem、hbSysFlushMem和hbSysFreeMem这几个API。使用的时候,直接进入 01_api_tutorial 目录,执行sh sys_mem.sh即可。 -
tensor.sh:该脚本主要引导如何准备模型输入和输出的tensor。 使用的时候,直接进入 01_api_tutorial 目录,执行sh tensor.sh即可,如下所示:
root@x5dvb-hynix8G:/userdata/horizon/x5/script/01_api_tutorial# sh tensor.sh
*****************************test_prepare_free_fn*************************************************
Tensor data type:0, Tensor layout: 2, shape:1x1x721x1836, aligned shape:1x1x721x1840
Tensor data type:1, Tensor layout: 2, shape:1x3x773x329, aligned shape:1x3x773x336
Tensor data type:2, Tensor layout: 2, shape:1x3x108x1297, aligned shape:1x3x108x1312
Tensor data type:5, Tensor layout: 2, shape:1x3x858x477, aligned shape:1x3x858x477
Tensor data type:5, Tensor layout: 0, shape:1x920x102x3, aligned shape:1x920x102x3
Tensor data type:4, Tensor layout: 2, shape:1x3x723x1486, aligned shape:1x3x723x1486
Tensor data type:4, Tensor layout: 0, shape:1x372x366x3, aligned shape:1x372x366x3
Tensor data type:3, Tensor layout: 2, shape:1x3x886x291, aligned shape:1x3x886x291
Tensor data type:3, Tensor layout: 0, shape:1x613x507x3, aligned shape:1x613x507x3
*****************************test_prepare_free_fn************************************************
*****************************test_info_fn********************************************************
Tensor data type:14, shape:1x1x1x3x2, stride:24x24x24x8x4, ndim: 5, data:
[[[[[0, 1], [2, 3], [4, 5]]]]]
Tensor data type:9, shape:3x3x1x2x1, stride:6x2x2x1x1, ndim: 5, data:
[[[[[0], [1]]], [[[2], [3]]], [[[4], [5]]]], [[[[6], [7]]], [[[8], [9]]],
[[[10], [11]]]], [[[[12], [13]]], [[[14], [15]]], [[[16], [17]]]]]
*****************************test_info_fn********************************************************
********************test_dequantize_fn***********************************************************
Tensor data type:8, shape:1x1x2x4, ndim: 4, quantiType: 2, quantizeAxis: 1,
quantizeValue: (0.1,), data: [[[[0, 1, 2, 3], [4, 5, 6, 7]]]],
dequantize data: [[[[0, 0.1, 0.2, 0.3], [0.4, 0.5, 0.6, 0.7]]]]
Tensor data type:8, shape:2x4x1x1, ndim: 4, quantiType: 2, quantizeAxis: 3,
quantizeValue: (0.1,),
data: [[[[0]], [[1]], [[2]], [[3]]], [[[4]], [[5]], [[6]], [[7]]]],
dequantize data: [[[[0]], [[0.1]], [[0.2]], [[0.3]]], [[[0.4]], [[0.5]], [[0.6]], [[0.7]]]]
********************test_dequantize_fn***********************************************************
advanced_samples
02_advanced_samples 目录下的示例,用于介绍自定义算子特殊功能的使用。其目录包含以下脚本:
├── plugin
│ └── custom_arm_op_custom_identity.sh
├── README.md
├── run_multi_input.sh
├── run_multi_model_batch.sh
└── run_nv12_batch.sh
custom_arm_op_custom_identity.sh:该脚本主要实现自定义算子模型推理功能, 使用的时候,进入 02_advanced_samples 目录, 然后直接执行sh custom_arm_op_custom_identity.sh即可,如下所示:
root@x5dvb-hynix8G:/userdata/horizon/x5/script/02_advanced_samples# sh custom_arm_op_custom_identity.sh
../../aarch64/bin/run_custom_op --model_file=../../../model/runtime/custom_op/custom_op_featuremap.bin --input_file=../../../data/custom_identity_data/input0.bin,../../../data/custom_identity_data/input1.bin
I0000 00:00:00.000000 10841 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
I0411 17:55:59.928918 10841 main.cpp:212] hbDNNRegisterLayerCreator success
I0411 17:55:59.929064 10841 main.cpp:217] hbDNNRegisterLayerCreator success
[BPU_PLAT]BPU Platform Version(1.3.3)!
[HBRT] set log level as 0. version = 3.15.18.0
[DNN] Runtime version = 1.17.2_(3.15.18 HBRT)
[A][DNN][packed_model.cpp:225][Model](2023-04-11,17:56:00.667.991) [HorizonRT] The model builder version = 1.15.0
I0411 17:56:00.676071 10841 main.cpp:232] hbDNNGetModelNameList success
I0411 17:56:00.676204 10841 main.cpp:239] hbDNNGetModelHandle success
I0411 17:56:00.676276 10841 main.cpp:245] hbDNNGetInputCount success
file length: 602112
file length: 602112
I0411 17:56:00.687402 10841 main.cpp:268] hbDNNGetOutputCount success
I0411 17:56:00.687788 10841 main.cpp:297] hbDNNInfer success
I0411 17:56:00.695663 10841 main.cpp:302] task done
I0411 17:56:03.145243 10841 main.cpp:306] write output tensor
模型的第一个输出数据保存至 output0.txt 文件。
run_multi_input.sh:该脚本主要实现多个小模型批量推理功能, 使用的时候,进入 02_advanced_samples 目录, 然后直接执行sh run_multi_input.sh即可,如下所示:
root@x5dvb:/userdata/horizon/x5/script/02_advanced_samples# sh run_multi_input.sh
../aarch64/bin/run_multi_input --model_file=../../model/runtime/mobilenetv2/mobilenetv2_multi_224x224_gray.bin --image_file=../../data/cls_images/zebra_cls.jpg --top_k=5
I0000 00:00:00.000000 10893 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[BPU_PLAT]BPU Platform Version(1.3.3)!
[HBRT] set log level as 0. version = 3.15.18.0
[DNN] Runtime version = 1.17.2_(3.15.18 HBRT)
[A][DNN][packed_model.cpp:225][Model](2023-04-11,17:57:03.277.375) [HorizonRT] The model builder version = 1.15.0
I0411 17:57:03.327527 10893 multi_input.cc:148] read image to tensor as bgr success
I0411 17:57:03.329546 10893 multi_input.cc:183] TOP 0 result id: 340
I0411 17:57:03.329598 10893 multi_input.cc:183] TOP 1 result id: 292
I0411 17:57:03.329628 10893 multi_input.cc:183] TOP 2 result id: 352
I0411 17:57:03.329656 10893 multi_input.cc:183] TOP 3 result id: 351
I0411 17:57:03.329684 10893 multi_input.cc:183] TOP 4 result id: 282
run_multi_model_batch.sh:该脚本主要实现多个小模型批量推理功能, 使用的时候,进入 02_advanced_samples 目录, 然后直接执行sh run_multi_model_batch.sh即可,如下代码块所示:
root@x5dvb-hynix8G:/userdata/horizon/x5/script/02_advanced_samples# sh run_multi_model_batch.sh
../aarch64/bin/run_multi_model_batch --model_file=../../model/runtime/googlenet/googlenet_224x224_nv12.bin,../../model/runtime/mobilenetv2/mobilenetv2_224x224_nv12.bin --input_file=../../data/cls_images/zebra_cls.jpg,../../data/cls_images/zebra_cls.jpg
I0000 00:00:00.000000 10916 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[BPU_PLAT]BPU Platform Version(1.3.3)!
[HBRT] set log level as 0. version = 3.15.18.0
[DNN] Runtime version = 1.17.2_(3.15.18 HBRT)
[A][DNN][packed_model.cpp:225][Model](2023-04-11,17:57:43.547.52) [HorizonRT] The model builder version = 1.15.0
[A][DNN][packed_model.cpp:225][Model](2023-04-11,17:57:51.811.477) [HorizonRT] The model builder version = 1.15.0
I0411 17:57:51.844280 10916 main.cpp:117] hbDNNInitializeFromFiles success
I0411 17:57:51.844388 10916 main.cpp:125] hbDNNGetModelNameList success
I0411 17:57:51.844424 10916 main.cpp:139] hbDNNGetModelHandle success
I0411 17:57:51.875140 10916 main.cpp:153] read image to nv12 success
I0411 17:57:51.875686 10916 main.cpp:170] prepare input tensor success
I0411 17:57:51.875875 10916 main.cpp:182] prepare output tensor success
I0411 17:57:51.876082 10916 main.cpp:216] infer success
I0411 17:57:51.878844 10916 main.cpp:221] task done
I0411 17:57:51.878948 10916 main.cpp:226] googlenet class result id: 340
I0411 17:57:51.879084 10916 main.cpp:230] mobilenetv2 class result id: 340
I0411 17:57:51.879177 10916 main.cpp:234] release task success
run_nv12_batch.sh:该脚本主要实现batch模型推理功能,Infer1是分开设置输入张量每个batch的地址,Infer2是只设置一个地址,包含所有的batch, 使用的时候,进入02_advanced_samples目录, 然后直接执行sh run_nv12_batch.sh即可,如下代码块所示:
root@x5dvb:/userdata/horizon/x5/script/02_advanced_samples# sh run_nv12_batch.sh
../aarch64/bin/run_nv12_batch --model_file=../../model/runtime/googlenet/googlenet_4x224x224_nv12.bin --image_file=../../data/cls_images/zebra_cls.jpg,../../data/cls_images/cat_cls.jpg,../../data/cls_images/zebra_cls.jpg,../../data/cls_images/cat_cls.jpg --top_k=5
I0000 00:00:00.000000 21511 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[BPU_PLAT]BPU Platform Version(1.3.3)!
[HBRT] set log level as 0. version = 3.15.18.0
[DNN] Runtime version = 1.17.2_(3.15.18 HBRT)
I0705 11:39:43.429180 21511 nv12_batch.cc:151] Infer1 start
I0705 11:39:43.488143 21511 nv12_batch.cc:166] read image to tensor as nv12 success
I0705 11:39:43.491156 21511 nv12_batch.cc:201] Batch[0]:
I0705 11:39:43.491211 21511 nv12_batch.cc:203] TOP 0 result id: 340
I0705 11:39:43.491240 21511 nv12_batch.cc:203] TOP 1 result id: 83
I0705 11:39:43.491266 21511 nv12_batch.cc:203] TOP 2 result id: 41
I0705 11:39:43.491298 21511 nv12_batch.cc:203] TOP 3 result id: 912
I0705 11:39:43.491324 21511 nv12_batch.cc:203] TOP 4 result id: 292
I0705 11:39:43.491348 21511 nv12_batch.cc:201] Batch[1]:
I0705 11:39:43.491374 21511 nv12_batch.cc:203] TOP 0 result id: 282
I0705 11:39:43.491398 21511 nv12_batch.cc:203] TOP 1 result id: 281
I0705 11:39:43.491422 21511 nv12_batch.cc:203] TOP 2 result id: 285
I0705 11:39:43.491447 21511 nv12_batch.cc:203] TOP 3 result id: 287
I0705 11:39:43.491472 21511 nv12_batch.cc:203] TOP 4 result id: 283
I0705 11:39:43.491497 21511 nv12_batch.cc:201] Batch[2]:
I0705 11:39:43.491514 21511 nv12_batch.cc:203] TOP 0 result id: 340
I0705 11:39:43.491539 21511 nv12_batch.cc:203] TOP 1 result id: 83
I0705 11:39:43.491564 21511 nv12_batch.cc:203] TOP 2 result id: 41
I0705 11:39:43.491587 21511 nv12_batch.cc:203] TOP 3 result id: 912
I0705 11:39:43.491612 21511 nv12_batch.cc:203] TOP 4 result id: 292
I0705 11:39:43.491637 21511 nv12_batch.cc:201] Batch[3]:
I0705 11:39:43.491662 21511 nv12_batch.cc:203] TOP 0 result id: 282
I0705 11:39:43.491685 21511 nv12_batch.cc:203] TOP 1 result id: 281
I0705 11:39:43.491710 21511 nv12_batch.cc:203] TOP 2 result id: 285
I0705 11:39:43.491734 21511 nv12_batch.cc:203] TOP 3 result id: 287
I0705 11:39:43.491760 21511 nv12_batch.cc:203] TOP 4 result id: 283
I0705 11:39:43.492235 21511 nv12_batch.cc:223] Infer1 end
I0705 11:39:43.492276 21511 nv12_batch.cc:228] Infer2 start
I0705 11:39:43.549713 21511 nv12_batch.cc:243] read image to tensor as nv12 success
I0705 11:39:43.552248 21511 nv12_batch.cc:278] Batch[0]:
I0705 11:39:43.552292 21511 nv12_batch.cc:280] TOP 0 result id: 340
I0705 11:39:43.552320 21511 nv12_batch.cc:280] TOP 1 result id: 83
I0705 11:39:43.552345 21511 nv12_batch.cc:280] TOP 2 result id: 41
I0705 11:39:43.552371 21511 nv12_batch.cc:280] TOP 3 result id: 912
I0705 11:39:43.552397 21511 nv12_batch.cc:280] TOP 4 result id: 292
I0705 11:39:43.552421 21511 nv12_batch.cc:278] Batch[1]:
I0705 11:39:43.552445 21511 nv12_batch.cc:280] TOP 0 result id: 282
I0705 11:39:43.552469 21511 nv12_batch.cc:280] TOP 1 result id: 281
I0705 11:39:43.552495 21511 nv12_batch.cc:280] TOP 2 result id: 285
I0705 11:39:43.552520 21511 nv12_batch.cc:280] TOP 3 result id: 287
I0705 11:39:43.552567 21511 nv12_batch.cc:280] TOP 4 result id: 283
I0705 11:39:43.552592 21511 nv12_batch.cc:278] Batch[2]:
I0705 11:39:43.552616 21511 nv12_batch.cc:280] TOP 0 result id: 340
I0705 11:39:43.552641 21511 nv12_batch.cc:280] TOP 1 result id: 83
I0705 11:39:43.552665 21511 nv12_batch.cc:280] TOP 2 result id: 41
I0705 11:39:43.552690 21511 nv12_batch.cc:280] TOP 3 result id: 912
I0705 11:39:43.552716 21511 nv12_batch.cc:280] TOP 4 result id: 292
I0705 11:39:43.552739 21511 nv12_batch.cc:278] Batch[3]:
I0705 11:39:43.552763 21511 nv12_batch.cc:280] TOP 0 result id: 282
I0705 11:39:43.552788 21511 nv12_batch.cc:280] TOP 1 result id: 281
I0705 11:39:43.552812 21511 nv12_batch.cc:280] TOP 2 result id: 285
I0705 11:39:43.552837 21511 nv12_batch.cc:280] TOP 3 result id: 287
I0705 11:39:43.552861 21511 nv12_batch.cc:280] TOP 4 result id: 283
I0705 11:39:43.553154 21511 nv12_batch.cc:300] Infer2 end
misc
03_misc 目录下的示例,用于介绍非nv12输入模型的使用。其目录包含以下脚本:
├── run_lenet.sh
└── run_resnet50_feature.sh
run_lenet.sh:该脚本主要实现Y数据输入的lenet模型推理功能, 使用的时候,进入 03_misc 目录, 然后直接执行sh run_lenet.sh即可,如下所示:
root@x5dvb-hynix8G:/userdata/horizon/x5/script/03_misc# sh run_lenet.sh
../aarch64/bin/run_lenet_gray --model_file=../../model/runtime/lenet_gray/lenet_28x28_gray.bin --data_file=../../data/misc_data/7.bin --image_height=28 --image_width=28 --top_k=5
I0000 00:00:00.000000 10979 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[BPU_PLAT]BPU Platform Version(1.3.3)!
[HBRT] set log level as 0. version = 3.15.18.0
[DNN] Runtime version = 1.17.2_(3.15.18 HBRT)
[A][DNN][packed_model.cpp:225][Model](2023-04-11,18:02:12.605.436) [HorizonRT] The model builder version = 1.15.0
I0411 18:02:12.613317 10979 run_lenet_gray.cc:128] hbDNNInitializeFromFiles success
I0411 18:02:12.613404 10979 run_lenet_gray.cc:136] hbDNNGetModelNameList success
I0411 18:02:12.613440 10979 run_lenet_gray.cc:143] hbDNNGetModelHandle success
I0411 18:02:12.614181 10979 run_lenet_gray.cc:159] prepare y tensor success
I0411 18:02:12.614310 10979 run_lenet_gray.cc:172] prepare tensor success
I0411 18:02:12.614503 10979 run_lenet_gray.cc:182] infer success
I0411 18:02:12.615538 10979 run_lenet_gray.cc:187] task done
[W][DNN][hb_sys.cpp:108][Mem](2023-04-11,18:02:12.615.583) memory is noncachable, ignore flush operation
I0411 18:02:12.615624 10979 run_lenet_gray.cc:192] task post process finished
I0411 18:02:12.615667 10979 run_lenet_gray.cc:198] TOP 0 result id: 7
I0411 18:02:12.615698 10979 run_lenet_gray.cc:198] TOP 1 result id: 9
I0411 18:02:12.615727 10979 run_lenet_gray.cc:198] TOP 2 result id: 3
I0411 18:02:12.615754 10979 run_lenet_gray.cc:198] TOP 3 result id: 4
I0411 18:02:12.615782 10979 run_lenet_gray.cc:198] TOP 4 result id: 2
run_resnet50_feature.sh:该脚本主要实现feature数据输入的resnet50模型推理功能,示例代码对feature数据做了quantize和padding以满足模型的输入条件,然后输入到模型进行infer。 使用的时候,进入 03_misc 目录, 然后直接执行sh run_resnet50_feature.sh即可,如下所示:
root@x5dvb-hynix8G:/userdata/horizon/x5/script/03_misc# sh run_resnet50_feature.sh
../aarch64/bin/run_resnet_feature --model_file=./resnet50_64x56x56_featuremap_modified.bin --data_file=../../data/misc_data/np_0 --top_k=5
I0000 00:00:00.000000 11024 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[BPU_PLAT]BPU Platform Version(1.3.3)!
[HBRT] set log level as 0. version = 3.15.18.0
[DNN] Runtime version = 1.17.2_(3.15.18 HBRT)
[A][DNN][packed_model.cpp:225][Model](2023-04-11,18:03:30.317.594) [HorizonRT] The model builder version = 1.15.1
I0411 18:03:30.523054 11024 run_resnet_feature.cc:160] hbDNNInitializeFromFiles success
I0411 18:03:30.523152 11024 run_resnet_feature.cc:168] hbDNNGetModelNameList success
I0411 18:03:30.523188 11024 run_resnet_feature.cc:175] hbDNNGetModelHandle success
I0411 18:03:30.529860 11024 run_resnet_feature.cc:346] input data size: 802816; input valid size: 200704; input aligned size: 229376
I0411 18:03:30.536860 11024 run_resnet_feature.cc:357] tensor padding featuremap success
I0411 18:03:30.536912 11024 run_resnet_feature.cc:190] prepare feature tensor success
I0411 18:03:30.537052 11024 run_resnet_feature.cc:200] prepare tensor success
I0411 18:03:30.537197 11024 run_resnet_feature.cc:210] infer success
I0411 18:03:30.541096 11024 run_resnet_feature.cc:215] task done
[W][DNN][hb_sys.cpp:108][Mem](2023-04-11,18:03:30.541.149) memory is noncachable, ignore flush operation
I0411 18:03:30.541409 11024 run_resnet_feature.cc:220] task post process finished
I0411 18:03:30.541453 11024 run_resnet_feature.cc:226] TOP 0 result id: 74
I0411 18:03:30.541483 11024 run_resnet_feature.cc:226] TOP 1 result id: 815
I0411 18:03:30.541512 11024 run_resnet_feature.cc:226] TOP 2 result id: 73
I0411 18:03:30.541538 11024 run_resnet_feature.cc:226] TOP 3 result id: 78
I0411 18:03:30.541565 11024 run_resnet_feature.cc:226] TOP 4 result id: 72
辅助工具和常用操作
日志
本章节主要包括 示例日志 和 模型推理 DNN API日志 两部分。
其中示例日志是指交付包示例代码中的应用日志;模型推理 dnn API日志是指嵌入式dnn库中的日志。用户根据不同的需求可以获取不同的日志信息。
示例日志
示例日志主要采用glog中的vlog,basic_samples参考示例中,日志内容会全部输出。
模型推理 DNN API日志
关于模型推理 DNN API日志的配置,请阅读《算法工具链产品手册》 。
公版模型性能精度测评说明
本章节介绍公版模型精度性能评测 ai_benchmark 示例包的具体用法, 示例包中预置了源码、可执行程序和评测脚本,开发者可以直接在X5开发板上体验并基于这些示例进行嵌入式应用开发,降低开发门槛。
示例包提供常见的分类、检测、分割、光流、追踪估计,雷达多任务,bev和深度估计模型的性能和精度评测示例,详细内容请阅读下文。
小技巧:
公版模型精度性能评测 ai_benchmark 示例包获取,请参考《交付物说明》。
发布物说明
示例代码包结构
ai_benchmark/code/ # 示例源码文件夹
├── build_ptq_x5.sh
├── build_qat_x5.sh
├── CMakeLists.txt
├── deps_gcc11.3 # 第三方依赖库
├── include # 源码头文件
├── README.md
└── src # 示例源码
ai_benchmark/x5 # 示例包运行环境
├── ptq # PTQ方案模型示例
│ ├── data # 模型精度评测数据集
│ ├── mini_data # 模型性能评测数据集
│ ├── model # PTQ方案nv12模型
│ │ ├── README.md
│ │ └── runtime -> ../../../../model_zoo/runtime/ai_benchmark/ptq # 软链接指向工具链SDK包中的模型,板端运行环境需要自行指定模型路径
│ ├── README.md
│ ├── script # 执行脚本
│ │ ├── aarch64 # 编译产生可执行文件及依赖库
│ │ ├── classification # 分类模型示例
│ │ ├── config # 模型推理配置文件
│ │ ├── detection # 检测模型示例
│ │ ├── segmentation # 分割模型示例
│ │ ├── env.sh # 基础环境脚本
│ │ └── README.md
│ └── tools # 精度评测工具
└── qat # QAT方案模型示例
├── data # 模型精度评测数据集
├── mini_data # 模型性能评测数据集
├── model # QAT方案nv12模型
│ ├── README.md
│ └── runtime -> ../../../../model_zoo/runtime/ai_benchmark/qat # 软链接指向工具链SDK包中的模型,板端运行环境需要自行指定模型路径
├── README.md
├── script # 执行脚本
│ ├── aarch64 # 编译产生可执行文件及依赖库
│ ├── bev # bev模型示例
│ ├── classification # 分类模型示例
│ ├── config # 模型推理配置文件
│ ├── detection # 检测模型示例
│ ├── disparity_pred # 深度估计模型示例
│ ├── multitask # 多任务模型示例
│ ├── opticalflow # 光流模型示例
│ ├── segmentation # 分割模型示例
│ ├── tracking # 追踪模型示例
│ ├── traj_pred # 轨迹预测示例
│ ├── env.sh # 基础环境脚本
│ └── README.md
└── tools # 前处理及精度评测工具
- code:该目录内是评测程序的源码,用来进行模型性能和精度评测。
- x5:该目录内提供了已经编译好的应用程序,以及各种评测脚本,用来测试多种模型在X5 BPU上运行的性能和精度等。
- build_ptq_x5.sh:PTQ真机程序一键编译脚本。
- build_qat_x5.sh:QAT真机程序一键编译脚本。
- deps_gcc11.3:示例代码所需要的依赖,主要如下所示:
appsdk gflags glog nlohmann opencv rapidjson
示例模型
示例包的模型发布物包括PTQ模型和QAT模型发布物:
-
PTQ模型model_zoo请在
horizon_model_convert_sample/01_common/model_zoo/runtime/ai_benchmark/ptq路径下进行获取。 -
QAT模型model_zoo请在
horizon_model_convert_sample/01_common/model_zoo/runtime/ai_benchmark/qat路径下进行获取。
其中包含常用的分类、检测、分割和光流预测等模型,模型命名规则为 {model_name}_{backbone}_{input_size}_{input_type}。
小技巧: horizon_model_convert_sample 模型转换示例包,请在linux服务器上执行命令: wget -c ftp://oeftp@sunrise.horizon.cc:10021/model_convert_sample/horizon_model_convert_sample.tar.xz --ftp-password=Oeftp~123$% 获取。
公共数据集
测评示例中用到的数据集主要有VOC数据集、COCO数据集、ImageNet、Cityscapes数据集、FlyingChairs数据集、KITTI数据集、Culane数据集、Nuscenes数据集、Mot17数据集、Carfusion数据集、Argoverse 1数据集和SceneFlow数据集。
请在Linux环境下进行下载,获取方式如下:
环境构建
开发板准备
-
拿到开发板后,请将开发版镜像更新到最新版本,升级方法请参考安装系统 章节内容。
-
确保本地开发机和开发板可以远程连接。
编译环境准备
编译需要当前环境安装好交叉编译工具 arm-gnu-toolchain-11.3.rel1-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-gcc。请使用X5算法工具链提供的开发机Docker镜像,直接进行编译使用。开发机Docker环境的获取及使用方法,请阅读环境安装 章节内容;
请使用code目录下的 build_ptq_x5.sh 脚本,即可一键编译开发板环境下的可执行程序,可执行程序和对应依赖会自动复制到 x5/ptq/script 目录下的 aarch64 目录下。
备注:
需要注意 build_ptq_x5.sh 脚本里指定的交叉编译工具链的位置是 /opt 目录下,用户如果安装在其他位置,可以手动修改下脚本。
export CC=/opt/arm-gnu-toolchain-11.3.rel1-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-gcc
export CXX=/opt/arm-gnu-toolchain-11.3.rel1-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-g++
测评示例使用说明
评测示例脚本主要在 script 和 tools 目录下。 script是开发板上运行的评测脚本,包括常见分类,检测和分割模型。每个模型下面有三个脚本,分别表示:
- fps.sh:利用多线程调度实现fps统计,用户可以根据需求自由设置线程数。
- latency.sh:实现单帧延迟统计(一个线程,单帧)。
- accuracy.sh:用于精度评测。
script:
├── aarch64 # 编译产生的可执行文件及依赖库
│ ├── bin
│ └── lib
├── env.sh # 基础配置
├── config
│ ├── model
│ │ ├── data_name_list # image_name配置文件
│ │ └── input_init # 模型输入配置文件
│ ├── preprocess
│ │ └── centerpoint_preprocess_5dim.json # 前处理配置文件
│ └── reference_points # 模型参考点信息
│ │ ├── bev_mt_gkt_mixvargenet_multitask_nuscenes
│ │ └── ...
├── detection # 检测模型
│ ├── fcos_efficientnetb0_mscoco # 在此目录中还有其他模型, 仅以此模型目录为参考
│ │ ├── accuracy.sh
│ │ ├── fps.sh
│ │ ├── latency.sh
│ │ ├── workflow_accuracy.json # 精度配置文件
│ │ ├── workflow_fps.json # 性能配置文件
│ │ └── workflow_latency.json # 单帧延时配置文件
│ └──...
├── ...
└── README.md
- ptq/tools 目录下主要包括 python_tools 下的精度计算脚本,用于PTQ模型的精度评测。
python_tools
└── accuracy_tools
├── cityscapes_metric.py
├── cls_eval.py
├── coco_metric.py
├── config.py
├── coco_det_eval.py
├── parsing_eval.py
├── voc_det_eval.py
└── voc_metric.py
- qat/tools 目录下主要包括前处理脚本及精度计算脚本,用于QAT模型的精度评测。
tools/
├── eval_preprocess
│ ├── util
│ ├── ......
│ └── voc.py
├── python_tools
│ └── accuracy_tools
│ ├── argoverse_util
│ ├── nuscenes_metric_pro
│ ├── whl_package
│ ├── bev_eval.py
│ ├── ......
│ └── yolov3_eval.py
└── README.md
注意:
评测前需要执行以下命令,将 ptq 或 qat 目录拷贝到开发板上,然后将 model_zoo/runtime 拷贝到 ptq/model 或 qat/model目录下。
scp -r ai_toolchain_package/Ai_Toolchain_Package-release-vX.X.X-OE-vX.X.X/ai_benchmark/x5/ptq root@192.168.1.10:/userdata/ptq/
scp -r model_zoo/runtime root@192.168.1.10:/userdata/ptq/model/
scp -r ai_toolchain_package/Ai_Toolchain_Package-release-vX.X.X-OE-vX.X.X/ai_benchmark/x5/qat root@192.168.1.10:/userdata/ptq/
scp -r model_zoo/runtime root@192.168.1.10:/userdata/qat/model/
json配置文件参数信息
本小节按照输入配置项(input_config)、输出配置项(output_config)及workflow配置项的维度, 分别对workflow_fps.json、workflow_latency.json及workflow_accuracy.json中的配置项进行简单说明。
注意: 下方给出的配置项参数信息为通用配置项信息,一些示例模型由于模型特殊性,还会有额外的配置项,具体请您参考示例模型json文件。
输入配置项(input_config)
| 参数名称 | 参数说明 | 涉及json文件 |
|---|---|---|
| input_type | 设置输入数据格式,支持图像或者bin文件。 | fps.json、latency.json、accuracy.json |
| height | 设置输入数据高度。 | fps.json、latency.json、accuracy.json |
| width | 设置输入数据宽度。 | fps.json、latency.json、accuracy.json |
| data_type | 设置输入数据类型,支持类型可参考 hbDNNDataType 小节。 对应数据类型由上到下排序,分别对应数字0,1,2... 如HB_DNN_IMG_TYPE_Y对应数字0, HB_DNN_IMG_TYPE_NV12对应数字1, HB_DNN_IMG_TYPE_NV12_SEPARATE对应数字2... | fps.json、latency.json、accuracy.json |
| image_list_file | 设置预处理数据集lst文件所在路径。 | fps.json、latency.json、accuracy.json |
| need_pre_load | 设置是否使用预加载方式对数据集读取。 | fps.json、latency.json、accuracy.json |
| limit | 设置处理中和处理完的输入数据量间差值的阈值,用于控制输入数据的处理线程。 | fps.json、latency.json、accuracy.json |
| need_loop | 设置是否循环读取数据进行评测。 | fps.json、latency.json、accuracy.json |
| max_cache | 设置预加载的数据个数。 请注意: 此参数生效时会预处理图片并读取到内存中,为保障您的程序稳定运行,请不要设置过大的值,建议您的数值设置不超过30。 | fps.json、latency.json、accuracy.json |
输出配置项(output_config)
| 参数名称 | 参数说明 | 涉及json文件 |
|---|---|---|
| output_type | 设置输出数据类型。 | fps.json、latency.json、accuracy.json |
| in_order | 设置是否按顺序进行输出。 | fps.json、latency.json、accuracy.json |
| enable_view_output | 设置是否将输出结果可视化。 | fps.json、latency.json |
| image_list_enable | 可视化时,设置为true,则可将输出结果保存为图像类型。 | fps.json、latency.json |
| view_output_dir | 设置可视化结果输出文件路径。 | fps.json、latency.json |
| eval_enable | 设置是否对精度进行评估。 | accuracy.json |
| output_file | 设置模型输出结果文件。 | accuracy.json |
- workflow配置项
模型推理配置项:
| 参数名称 | 参数说明 | 涉及json文件 |
|---|---|---|
| method_type | 设置模型推理方法,此处需配置为 InferMethod。 | fps.json、latency.json、accuracy.json |
| method_config | 设置模型推理参数。 | fps.json、latency.json、accuracy.json |
| - core:设置推理core id。 请注意: x5只有一个bpu核,这里只能设置为0(core any)或者1(core 0)。 | ||
| - model_file:指定模型文件。 |
- 后处理配置项:
| 参数名称 | 参数说明 | 涉及json文件 |
|---|---|---|
| thread_count | 设置后处理线程数,取值范围为 1-8。 | fps.json、latency.json、accuracy.json |
| method_type | 设置后处理方法。 | fps.json、latency.json、accuracy.json |
| method_config | 设置后处理参数。 | fps.json、latency.json、accuracy.json |
性能评测
性能评测分为latency和fps两方面。
测评脚本使用说明
进入到需要评测的模型目录下,执行 sh latency.sh 即可测试出单帧延迟。如下图所示:
I0419 02:35:07.041095 39124 output_plugin.cc:80] Infer latency: [avg: 13.124ms, max: 13.946ms, min: 13.048ms], Post process latency: [avg: 3.584ms, max: 3.650ms, min: 3.498ms].
备注:
infer表示模型推理耗时。Post process表示后处理耗时。
进入到需要评测的模型目录下执行 sh fps.sh 即可测试出帧率。如下图所示:
I0419 02:35:00.044417 39094 output_plugin.cc:109] Throughput: 1129.39fps # 模型帧率
备注: 该功能采用多线程并发方式,旨在让模型可以在BPU上达到极致的性能。由于多线程并发及数据采样的原因,在程序启动阶段帧率值会较低,之后帧率会上升并逐渐趋于稳定,帧率的浮动范围控制在0.5%之内。
命令行参数说明
fps.sh 脚本内容如下:
#!/bin/sh
source ../../base_config.sh
export SHOW_FPS_LOG=1
export STAT_CYCLE=100 # 设置环境变量,FPS 统计周期
${app} \
--config_file=workflow_fps.json \
--log_level=1
latency.sh 脚本内容如下:
#!/bin/sh
source ../../base_config.sh
export SHOW_LATENCY_LOG=1 # 设置环境变量,打印 LATENCY 级别log
export STAT_CYCLE=50 # 设置环境变量,LATENCY 统计周期
${app} \
--config_file=workflow_latency.json \
--log_level=1
结果可视化
如果您希望可以看到模型单次推理出来效果,可以修改workflow_latency.json��,重新运行latency.sh脚本,即可在output_dir目录下生成展示效果。
注意: 生成展示效果时,由于dump效果的原因,脚本运行会变慢。 仅支持运行latency.sh脚本dump。
可视化操作步骤 参考如下:
- 修改workflow_latency.json配置文件
"output_config": {
"output_type": "image",
"enable_view_output": true, # 开启可视化
"view_output_dir": "./output_dir", # 可视化结果输出路径
"image_list_enable": true,
"in_order": false
}
- 执行latency.sh脚本
sh latency.sh
注意: bev模型可视化需要指定场景信息和homography矩阵路径,homography矩阵用于相机视角和鸟瞰图的转换,不同场景有各自的homography矩阵。
bev模型的workflow_latency.json配置文件建议修改成如下形式:
"output_config": {
"output_type": "image",
"enable_view_output": true, # 开启可视化
"view_output_dir": "./output_dir", # 可视化结果输出路径
"bev_ego2img_info": [
"../../config/visible/bev/scenes.json", # 输入的场景信息
"../../config/visible/bev/boston.bin", # boston场景的homography矩阵
"../../config/visible/bev/singapore.bin" # singapore场景的homography矩阵
],
"image_list_enable": true,
"in_order": false
}
不同类别的模型可以实现的 可视化效果 也不相同,参考下表:
- 分类

- 2d检测

- 3d检测

- 分割

- 关键点

- 车道线

- 光流

- 雷达
- 雷达多任务


- bev








- 轨迹预测
- 深度估计

注意: 轨迹预测可视化时如果需要可视化minidata以外的图片,需要额外配置道路信息、轨迹信息文件到 minidata/argoverse1/visualization 中,生成配置文件可使用 densetnt_process.py 预处理脚本,将 --is-gen-visual-config 参数设为 true。
精度评测
模型精度评测分为四步:
- 数据预处理。
- 生成lst文件。
- 数据挂载。
- 模型推理。
- 精度计算。
数据预处理
对于PTQ模型:数据预处理需要在x86开发机环境下运行 hb_eval_preprocess 工具,对数据集进行预处理。
所谓预处理是指图片数据在送入模型之前的特定处理操作,例如:图片resize、crop和padding等。
该工具集成于开发机模型转换编译的环境中,原始数据集经过工具预处理之后,会生成模型对应的前处理二进制文件.bin文件集.
直接运行 hb_eval_preprocess --help 可查看工具使用规则。
小技巧:
- 关于
hb_eval_preprocess工具命令行参数,可键入hb_eval_preprocess -h, 或查看 PTQ量化原理及步骤说明的 hb_eval_preprocess工具 一节内容。
PTQ模型数据预处理:
下面将详细介绍示例包中每一个模型对应的数据集,以及对应数据集的预处理操作:
PTQ模型使用到的数据集包括以下几种:
VOC数据集:该数据集主要用于ssd_mobilenetv1模型的评测, 其目录结构如下,示例中主要用到Main文件下的val.txt文件,JPEGImages中的源图片和Annotations中的标注数据:
.
└── VOCdevkit # 根目录
└── VOC2012 # 不同年份的数据集,这里只下载了2012的,还有2007等其它年份的
├── Annotations # 存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等
├── ImageSets # 该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本
│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages # 存放源图片
├── SegmentationClass # 存放的是图片,语义分割相关
└── SegmentationObject # 存放的是图片,实例分割相关
对数据集进行预处理:
hb_eval_preprocess -m ssd_mobilenetv1 -i VOCdevkit/VOC2012/JPEGImages -v VOCdevkit/VOC2012/ImageSets/Main/val.txt -o ./pre_ssd_mobilenetv1
COCO数据集:该数据集主要用于centernet_resnet101、detr_efficientnetb3_mscoco、detr_resnet50_mscoco、yolov2_darknet19、yolov3_darknet53、yolov3_vargdarknet、yolov5x、preq_qat_fcos_efficientnetb0、preq_qat_fcos_efficientnetb2和preq_qat_fcos_efficientnetb3等检测模型的评测, 其目录如下,示例中主要用到annotations文件夹下的instances_val2017.json标注文件和images中的图片:
.
├── annotations # 存放标注数据
└── images # 存放源图片
对数据集进行预处理:
hb_eval_preprocess -m model_name -i coco/coco_val2017/images -o ./pre_model_name
ImageNet数据集:该数据集主要用于efficientnasnet_m、efficientnasnet_s、efficientnet_lite0、efficientnet_lite1、efficientnet_lite2、efficientnet_lite3、efficientnet_lite4、googlenet、mobilenetv1、mobilenetv2、resnet18和vargconvnet等分类模型的评测, 示例中主要用到了标注文件val.txt 和val目录中的源图片:
.
├── val.txt
└── val
对数据集进行预处理:
hb_eval_preprocess -m model_name -i imagenet/val -o ./pre_model_name
Cityscapes数据集:该数据集用于deeplabv3plus_efficientnetb0、deeplabv3plus_efficientnetm1、deeplabv3plus_efficientnetm2和fastscnn_efficientnetb0等分割模型的评测。 示例中主要用到了./gtFine/val中的标注文件和./leftImg8bit/val中的源图片。
.
├── gtFine
│ └── val
│ ├── frankfurt
│ ├── lindau
│ └── munster
└── leftImg8bit
└── val
├── frankfurt
├── lindau
└── munster
对数据集进行预处理:
hb_eval_preprocess -m model_name -i cityscapes/leftImg8bit/val -o ./pre_model_name
QAT模型数据预处理:
QAT模型数据预处理需要在x86仿真环境下执行 ai_benchmark/x5/qat/tools/eval_preprocess 中对应模型的前处理脚本。
下面将详细介绍示例包中模型对应的数据集,以及其预处理操作。
请注意: 使用前请修改脚本中的数据集路径及保存路径使脚本正常运行。
ImageNet数据集:该数据集主要用于QAT分类模型mixvargenet_imagenet、mobilenetv1_imagenet、mobilenetv2_imagenet、resnet50_imagenet、horizon_swin_transformer_imagenet和vargnetv2_imagenet的评测.
对数据集进行预处理:
python3 imagenet.py --image-path=./standard_imagenet/val/ --save-path=./pre_model_name
VOC数据集:该数据集主要用于检测模型yolo_mobilenetv1_voc的评测。
对数据集进行预处理:
python3 voc.py --image-path=./VOCdevkit/VOC2012/JPEGImages/ --save-path=./pre_yolov3_mobilenetv1
COCO数据集:该数据集主要用于QAT检测模型fcos_efficientnetb0_mscoco和retinanet_vargnetv2_fpn_mscoco的评测。
对数据集进行预处理:
# fcos_efficientnetb0_mscoco
python3 fcos_process.py --image-path=./mscoco/images/val2017/ --label-path=./mscoco/images/annotations/instances_val2017.json --save-path=./pre_fcos_efficientnetb0
# retinanet_vargnetv2_fpn_mscoco
python3 retinanet_process.py --image-path=./mscoco/images/val2017/ --label-path=./mscoco/images/annotations/instances_val2017.json --save-path=./pre_retinanet
-
Cityscapes:该数据集主要用于QAT分割模型unet_mobilenetv1_cityscapes的评测,不需要前处理直接使用验证集数据即可。 -
FlyingChairs:该数据集主要用于QAT光流模型pwcnet_pwcnetneck_flyingchairs的评测。本数据集您可以于FlyingChairs数据集官网下载地址 <https://lmb.informatik.uni-freiburg.de/resources/datasets/FlyingChairs.en.html>_ 下载,示例中主要用到了 FlyingChairs_release/data 中的数据和 ./FlyingChairs_train_val.txt 标注文件。
.
├── FlyingChairs_release
│ └── data
│ ├── 00001_img1.ppm
│ ├── 00001_img2.ppm
│ └── 00001_flow.ppm
├── FlyingChairs_train_val.txt
注意:
{id}_img1.ppm和{id}_img2.ppm是一个图像对,图像宽度大小是512,高度大小是38,id是从00001至22872的序号,每一图像对的标签是{id}_flow.flo。- FlyingChairs_train_val 文件是用于划分训练集和验证集,标签值为2表示验证集。
对数据集进行预处理:
python3 pwcnet_process.py --input-path=./flyingchairs/FlyingChairs_release/data/ --val-file=./flyingchairs/FlyingChairs_train_val.txt --output-path=./pre_pwcnet_opticalflow
Kitti3D:该数据集主要用于QAT检测模型pointpillars_kitti_car的评测。本数据集您可以于Kitti3D数据集官网下载地址 <https://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d>_ 下载。
.
├── kitti3d
├── data_object_calib.zip # camera calibration matrices of object data set
├── data_object_image_2.zip # left color images of object data set
├── data_object_label_2.zip # taining labels of object data set
└── data_object_veloodyne.zip # velodyne point cloud
.
├── kitti3d_origin
├── ImageSets
│ ├── test.txt
│ ├── train.txt
│ ├── trainval.txt
│ └── val.txt
├── testing
│ ├── calib
│ ├── image_2
│ └── velodyne
└── training
├── calib
├── image_2
├── label_2
└── velodyne
对数据集进行预处理:
python3 pointpillars_process.py --data-path=./kitti3d_origin --save-path=./pre_kitti3d --height=1 --width=150000
Culane:该数据集主要用于QAT检测模型ganet_mixvargenet_culane的评测。本数据集您可以于Culane数据集官网下载地址 <https://xingangpan.github.io/projects/CULane.html>_ 下载。
.
├── culane
├── annotations_new.tar.gz
├── driver_23_30frame.tar.gz
├── driver_37_30frame.tar.gz
├── driver_100_30frame.tar.gz
├── driver_161_90frame.tar.gz
├── driver_182_30frame.tar.gz
├── driver_193_90frame.tar.gz
├── laneseg_label_w16.tar.gz
└── list.tar.gz
其中 annotations_new.tar.gz 需要最后解压,以对原始的注释文件进行更正,建议您将下载的数据集解压成如下结构:
.
├── culane # 根目录
├── driver_23_30frame # 数据集和注释
│ ├── 05151640_0419.MP4 # 数据集的一段,包含每一帧图片
│ │ ├──00000.jpg # 源图片
│ │ ├──00000.lines.txt # 注释文件,其中每个行给出车道标记关键点的x,y坐标
│ ......
├── driver_37_30frame
├── driver_100_30frame
├── driver_161_90frame
├── driver_182_30frame
├── driver_193_90frame
├── laneseg_label_w16 # 车道分段标签
└── list # 训练,验证,测试列表
对数据集进行预处理:
python3 ganet_process.py --image-path=./culane --save-path=./pre_culane
Nuscenes:该数据集主要用于QAT检测模型fcos3d_efficientnetb0_nuscenes,centerpoint_pointpillar_nuscenes,lidar多任务模型centerpoint_mixvargnet_multitask_nuscenes和bev模型bev_gkt_mixvargenet_multitask_nuscenes,bev_lss_efficientnetb0_multitask_nuscenes,bev_ipm_efficientnetb0_multitask_nuscenes,bev_ipm_4d_efficientnetb0_multitask_nuscenes,detr3d_efficientnetb3_nuscenes的评测。本数据集您可以于Nuscenes数据集官网下载地址 <https://www.nuscenes.org/nuscenes#download>_ 下载。
.
├── Nuscenes
├── nuScenes-map-expansion-v1.3.zip
├── nuScenes-map-expansion-v1.2.zip
├── nuScenes-map-expansion-v1.1.zip
├── nuScenes-map-expansion-v1.0.zip
├── v1.0-mini.tar
├── v1.0-test_blobs.tar
├── v1.0-test_meta.tar
├── v1.0-trainval01_blobs.tar
├── v1.0-trainval02_blobs.tar
├── v1.0-trainval03_blobs.tar
├── v1.0-trainval04_blobs.tar
├── v1.0-trainval05_blobs.tar
├── v1.0-trainval06_blobs.tar
├── v1.0-trainval07_blobs.tar
├── v1.0-trainval08_blobs.tar
├── v1.0-trainval09_blobs.tar
├── v1.0-trainval10_blobs.tar
└── v1.0-trainval_meta.tar
对于lidar多任�务模型,还需从官网下载lidar分割标签lidarseg,并按照nuscenes官网教程更新v1.0-trainval,建议您将下载的数据集解压成如下结构:
.
├── Nuscenes
├── can_bus
├── lidarseg
├── maps
├── nuscenes
│ └── meta
│ ├── maps
│ ├── v1.0-mini
│ └── v1.0-trainval
├── samples
├── sweeps
├── v1.0-mini
└── v1.0-trainval
请注意:
- fcos3d_process.py除了生成预处理图片外,还会对待使用的相机内参进行处理,生成相应的相机内参配置文件。
- centerpoint_preprocess.py,bev_preprocess.py和lidar_preprocess.py除了生成预处理数据外,还会在预处理数据路径下生成一个
val_gt_infos.pkl文件用于精度计算。 - bev_preprocess.py需要通过
--model指定模型的名称,可选项有bev_gkt_mixvargenet_multitask_nuscenes,bev_ipm_4d_efficientnetb0_multitask_nuscenes,bev_ipm_efficientnetb0_multitask_nuscenes,bev_lss_efficientnetb0_multitask_nuscenes,detr3d_efficientnetb3_nuscenes。
对数据集进行预处理:
# fcos3d_efficientnetb0_nuscenes
python3 fcos3d_process.py --src-data-dir=./Nuscenes --file-path=../../script/config/model/data_name_list/nuscenes_names.txt --save-path=./processed_fcos3d_images
# centerpoint_pointpillar_nuscenes
python3 centerpoint_preprocess.py --data-path=./Nuscenes --save-path=./nuscenes_lidar_val
# bev model
python3 bev_preprocess.py --model=model_name --data-path=./Nuscenes --meta-path=./Nuscenes/meta --reference-path=../../script/config/reference_points --save-path=./nuscenes_bev_val
# centerpoint_mixvargnet_multitask_nuscenes
python3 lidar_preprocess.py --data-path=./Nuscenes --save-path=./nuscenes_lidar_val
Mot17:该数据集用于QAT追踪模型motr_efficientnetb3_mot17的评测。本数据集您可以于Mot17数据集官网下载地址 <https://opendatalab.com/MOT17>_ 下载。
.
├── valdata # 根目录
├── gt_val
│ ├── MOT17-02-SDP
│ ├�── MOT17-04-SDP
│ ├── MOT17-05-SDP
│ ├── MOT17-09-SDP
│ ├── MOT17-10-SDP
│ ├── MOT17-11-SDP
│ ├── MOT17-13-SDP
├── images
│ └── train
│ ├── MOT17-04-SDP
│ ├── MOT17-05-SDP
│ ├── MOT17-09-SDP
│ ├── MOT17-10-SDP
│ ├── MOT17-11-SDP
│ ├── MOT17-13-SDP
└── mot17.val
对数据集进行预处理:
python3 motr_process.py --image-path=./valdata/images/train --save-path=./processed_motr
Carfusion:该数据集用于QAT检测模型keypoint_efficientnetb0_carfusion的评测。本数据集您可以于Carfusion数据集官网下载地址 <http://www.cs.cmu.edu/~ILIM/projects/IM/CarFusion/cvpr2018/index.html>_ 下载。
.
├── carfusion # 根目录
├── train
└── test
对数据集进行预处理:
# 首先生成评测需要的数据(如您第一次使用本数据集,必须使用下方脚本生成)
python3 gen_carfusion_data.py --src-data-path=carfusion --out-dir=cropped_data --num-workers 2
执行第一个脚本后的目录如下:
.
├── cropped_data # 根目录
├── test
└── simple_anno
保证data-root指定的地址与cropped_data同一级,然后运行下方指令:
python3 keypoints_preprocess.py --data-root=./ --label-path=cropped_data/simple_anno/keypoints_test.json --save-path=./processed_carfusion
Argoverse1:该数据集用于QAT检测模型densetnt_vectornet_argoverse1的评测。本数据集您可以于Argoverse1数据集官网下载地址 <https://www.argoverse.org/av1.html>_ 下载。
.
├── carfusion # 根目录
├── train
└── test
对数据集进行预处理:
# 首先生成评测需要的数据(如您第一次使用本数据集,必须使用下方脚本生成)
python3 gen_carfusion_data.py --src-data-path=carfusion --out-dir=cropped_data --num-workers 2
执行第一个脚本后的目录如下:
.
├── arogverse-1 # 根目录
├── map_files
└── val
densetnt_process.py除了生成预处理输入外,还会在src-path下生成相应的评测meta文件。评测仅需使用 --src-path 和 --dst-path 两个参数即可,无需关注其他参数。
python3 densetnt_process.py --src-path=arogverse-1 --dst-path=processed_arogverse1
SceneFlow:该数据集用于QAT深度估计模型stereonetplus_mixvargenet_sceneflow的评测。本数据集您可以于SceneFlow数据集官网下载地址 <https://lmb.informatik.uni-freiburg.de/resources/datasets/SceneFlowDatasets.en.html>_ 下载。
.
├── SceneFlow # 根目录
├── FlyingThings3D
│ ├── disparity
│ ├── frames_finalpass
└── SceneFlow_finalpass_test.txt
对数据集进行预处理:
# stereonet_preprocess.py除了生成预处理数据外,还会在预处理数据路径下生成一个 ``val_gt_infos.pkl`` 文件用于精度计算。
python3 stereonet_preprocess.py --data-path=SceneFlow/ --data-list=SceneFlow/SceneFlow_finalpass_test.txt --save-path=sceneflow_val
生成lst文件
示例中精度计算脚本的运行流程是:
1、根据 workflow_accurary.json 中的 image_list_file 参数值,去寻找对应数据集的 lst 文件;
2、根据 lst 文件存储的前处理文件路径信息,去加载每一个前处理文件,然后进行推理
所以,生成预处理文件之后,需要生成对应的lst文件,将每一张前处理�文件的路径写入到lst文件中,而这个路径与数据集在板端的存放位置有关。
这里我们推荐其存放位置与 ./data/dataset_name/pre_model_name 预处理数据文件夹同级目录。
PTQ预处理数据集结构如下:
|── ptq
| |── data
| | |── cityscapes
| | | |── pre_deeplabv3plus_efficientnetb0
| | | | |── xxxx.bin # 前处理好的二进制文件
| | | | |── ....
| | | |── pre_deeplabv3plus_efficientnetb0.lst # lst文件:记录每一个前处理文件的路径
| | | |── ....
| | |── ....
| |── model
| | |── ...
| |── script
| | |── ...
QAT预处理数据集结构如下:
|── qat
| |── data
| | |── carfusion
| | | |── pre_keypoints
| | | | |── xxxx # 前处理好的数据
| | | | |── ....
| | | |── pre_carfusion.lst # lst文件:记录每一个前处理文件的路径
| | |── ....
| |── model
| | |── ...
| |── script
| | |── ...
与之对应的lst文件,参考生成方式如下:
注意: 除Densetnt_vectornet_argoverse1、Bev、Motr_efficientnetb3_mot17和Stereonetplus_mixvargenet_sceneflow模型外,其余模型的lst文件参考生成方式:
find ../../../data/coco/pre_centernet_resnet101 -name "*bin*" > ../../../data/coco/pre_centernet_resnet101.lst
注意: -name 后的参数需要根据预处理后的数据集格式进行对应调整,如bin、png。
这样生成的lst文件中存储的路径为一个相对路径: ../../../data/ 或 ../../../data/coco/pre_centernet_resnet101/ ,可以与 workflow_accuracy.json 默认的配置路径吻合。
如果需要更改前处理数据集的存放位置,则需要确保对应的 lst 文件可以被 workflow_accuracy.json 读取到;其次需要确保程序根据 lst 中的路径信��息,能读取到对应的前处理文件。
argoverse1:
sh generate_acc_lst.sh
这样生成的lst文件中存储的路径为一个相对路径: ../../../data/argoverse1/densetnt/ ,可以与 workflow_accuracy.json 默认的配置路径吻合。
对于Densetnt_vectornet_argoverse1、Bev、Motr_efficientnetb3_mot17和Stereonetplus_mixvargenet_sceneflow模型,lst文件参考生成方式:
Densetnt:
sh generate_acc_lst.sh
这样生成的lst文件中存储的路径为一个相对路径: ../../../data/argoverse1/densetnt/ ,可以与 workflow_accuracy.json 默认的配置路径吻合。
Bev:
以bev_ipm_efficientnetb0_multitask模型为例,该模型有图像和参考点两种输入,同一帧输入的图片和参考点名称相同。为了保证输入相对应,在执行 find 命令时需要添加 sort 按名称进行排序。参考生成方式:
find ../../../data/nuscenes_bev/images -name "*bin*" | sort > ../../../data/nuscenes_bev/images.lst
find ../../../data/nuscenes_bev/reference_points0 -name "*bin*" | sort > ../../../data/nuscenes_bev/reference_points0.lst
detr3d_efficientnetb3_nuscenes,除了图像和参考点还有coords,masks和position embedding输入,生成lst方式如下:
# detr3d_efficientnetb3_nuscenes:
find ../../../data/nuscenes_bev/coords0 -name "*bin*" | sort > ../../../data/nuscenes_bev/coords0.lst
find ../../../data/nuscenes_bev/coords1 -name "*bin*" | sort > ../../../data/nuscenes_bev/coords1.lst
find ../../../data/nuscenes_bev/coords2 -name "*bin*" | sort > ../../../data/nuscenes_bev/coords2.lst
find ../../../data/nuscenes_bev/coords3 -name "*bin*" | sort > ../../../data/nuscenes_bev/coords3.lst
find ../../../data/nuscenes_bev/masks -name "*bin*" | sort > ../../../data/nuscenes_bev/masks.lst
请注意: bev模型中,detr3d_efficientnetb3_nuscenes的 reference_points 用于模型后处理,需要在 workflow_accuracy.json 配置正确的路径,确保程序能够读到对应的参考点文件。此外,bev_ipm_4d_efficientnetb0_multitask是时序模型,该模型对输入顺序有要求。因此,我们提供了专门的脚本 gen_file_list.sh 用于生成lst文件,使用方式如下:
sh gen_file_list.sh
这样生成的lst文件中存储的路径为一个相对路径: ../../../data/nuscenes_bev/ ,可以与 workflow_accuracy.json 默认的配置路径吻合。如果需要更改前处理数据集的存放位置,则需要确保对应的 lst 文件可以被 workflow_accuracy.json 读取到。其次需要确保程序根据 lst 中的路径信息,能读取到对应的前处理文件。
Motr:
sh generate_acc_lst.sh
这样生成的lst文件中存储的路径为一个相对路径: ../../../data/mot17/motr/ ,可以与 workflow_accuracy.json 默认的配置路径吻合。如果需要更改前处理数据集的存放位置,则需要确保对应的 lst 文件可以被 workflow_accuracy.json 读取到。其次需要确保程序根据 lst 中的路径信息,能读取到对应的前处理文件。
Stereonetplus:
以stereonetplus_mixvargenet_sceneflow模型为例,为了保证同一帧输入的左右视图相对应,在执行 find 命令时需要添加 sort 按名称进行排序,参考生成方式如下:
find ../../../data/sceneflow/left -name "*png*" | sort > ../../../data/sceneflow/left.lst
find ../../../data/sceneflow/right -name "*png*" | sort > ../../../data/sceneflow/right.lst
这样生成的lst文件中存储的路径为一个相对路径: ../../../data/mot17/motr/ ,可以与 workflow_accuracy.json 默认的配置路径吻合。如果需要更改前处理数据集的存放位置,则需要确保对应的 lst 文件可以被 workflow_accuracy.json 读取到。其次需要确保程序根据 lst 中的路径信息,能读取到对应的前处理文件。
数据挂载
由于数据集相对较大,不适合直接放在开发板上,可以采用nfs挂载的方式供开发板读取。
开发机PC端(需要root权限):
- 编辑 /etc/exports, 增加一行:
/nfs *(insecure,rw,sync,all_squash,anonuid=1000,anongid=1000,no_subtree_check)。/nfs表示本机挂载路径,可替换为用户指定目录 - 执行命令
exportfs -a -r,使/etc/exports 生效。
开发板端:
- 创建需要挂载的目录:
mkdir -p /mnt。 mount -t nfs {PC端IP}:/nfs /mnt -o nolock。
完成将PC端的/nfs文件夹挂载至板端/mnt文件夹。按照此方式,将包含预处理数据的文件夹挂载至板端,并将/data目录软链接至板端/ptq目录下,与/script同级目录。
模型推理
挂载完数据后,请登录开发板,开发板登录方法,请阅读开发板登录 章节内容,登录成功后,执行 centernet_resnet101/ 目录下的accuracy.sh脚本,如下所示:
/userdata/ptq/script/detection/centernet_resnet101# sh accuracy.sh
../../aarch64/bin/example --config_file=workflow_accuracy.json --log_level=2
...
I0419 03:14:51.158655 39555 infer_method.cc:107] Predict DoProcess finished.
I0419 03:14:51.187361 39556 ptq_centernet_post_process_method.cc:558] PTQCenternetPostProcessMethod DoProcess finished, predict result: [{"bbox":[-1.518860,71.691170,574.934631,638.294922],"prob":0.750647,"label":21,"class_name":"
I0118 14:02:43.636204 24782 ptq_centernet_post_process_method.cc:558] PTQCenternetPostProcessMethod DoProcess finished, predict result: [{"bbox":[3.432283,164.936249,157.480042,264.276825],"prob":0.544454,"label":62,"class_name":"
...
开发板端程序会在当前目录生成 eval.log 文件,该文件就是预测结果文件。
精度计算
注意:
精度计算部分请在 开发机 模型转换的环境下操作
PTQ模型精度计算:
PTQ模型精度计算的脚本在 ptq/tools/python_tools/accuracy_tools 目录下,其中:
-
cls_eval.py用于计算分类模型的精度。
-
coco_det_eval.py用于计算使用COCO数据集评测的检测模型的精度。
-
parsing_eval.py用于计算使用Cityscapes数据集评测的分割模型的精度。
-
voc_det_eval.py用于计算使用VOC数据集评测的检测模型的精度。
以下为您说明不同类型的PTQ模型精度计算方式:
- 分类模型
使用CIFAR-10数据集和ImageNet数据集的分类模型计算方式如下:
#!/bin/sh
python3 cls_eval.py --log_file=eval.log --gt_file=val.txt
备注:
-
log_file:分类模型的预测结果文件。 -
gt_file:CIFAR-10和ImageNet数据集的标注文件。 -
检测模型
使用COCO数据集的检测模型精度计算方式如下:
#!/bin/sh
python3 coco_det_eval.py --eval_result_path=eval.log --annotation_path=instances_val2017.json
备注:
eval_result_path:检测模型的预测结果文件。annotation_path:COCO数据集的标注文件。
使用VOC数据集的检测模型精度计算方式如下:
#!/bin/sh
python3 voc_det_eval.py --eval_result_path=eval.log --annotation_path=../Annotations --val_txt_path=../val.txt
备注:
-
eval_result_path:检测模型的预测结果文件。 -
annotation_path:VOC数据集的标注文件。 -
val_txt_path:VOC数据集中ImageSets/Main文件夹下的val.txt文件。 -
分割模型
使用Cityscapes数据集的分割模型精度计算方式如下:
#!/bin/sh
python3 parsing_eval.py --log_file=eval.log --gt_path=cityscapes/gtFine/val
备注:
log_file:分割模型的预测结果文件。gt_path:Cityscapes数据集的标注文件。
QAT模型精度计算:
QAT模型的精度计算脚本在 qat/tools/python_tools/accuracy_tools 目录下,其中:
-
bev_eval.py用于计算bev模型的精��度。
-
centerpoint_eval.py用于计算雷达3D模型centerpoint_pointpillar_nuscenes的精度。
-
cls_eval.py用于计算分类模型的精度。
-
densetnt_eval.py用于计算densetnt轨迹预测模型densetnt_vectornet_argoverse1的精度。
-
detr_eval.py用于计算detr检测模型的精度。
-
fcos3d_eval.py用于计算检测模型fcos3d_efficientnetb0_nuscenes的精度。
-
fcos_eval.py用于计算fcos检测模型的精度。
-
ganet_eval.py用于计算检测模型ganet_mixvargenet_culane的精度。
-
keypoints_eval.py用于计算检测模型keypoint_efficientnetb0_carfusion的精度。
-
lidar_multitask_eval.py用于计算lidar多任务模型centerpoint_mixvargnet_multitask_nuscenes的精度。
-
motr_eval.py用于计算motr检测模型motr_efficientnetb3_mot17的精度。
-
parsing_eval.py用于计算使用Cityscapes数据集评测的分割模型的精度。
-
pointpillars_eval.py用于计算检测模型pointpillars_kitti_car的精度。
-
pwcnet_eval.py用于计算使用FlyingChairs数据集评测的光流模型pwcnet_pwcnetneck_flyingchairs的精度。
-
retinanet_eval.py用于计算检测模型retinanet_vargnetv2_fpn_mscoco的精度。
-
yolov3_eval.py用于计算yolov3检测模型的精度。
-
stereonet_eval.py用于计算深度估计模型stereonetplus_mixvargenet_sceneflow的精度。
以下为您说明不同类型的QAT模型精度计算方式:
- Bev模型
使用nuscenes数据集的bev模型精度计算方式如下:
#!/bin/sh
python3 bev_eval.py --det_eval_path=bev_det_eval.log --seg_eval_path=bev_seg_eval.log --gt_files_path=./nuscenes_bev_val/val_gt_infos.pkl --meta_dir=./Nuscenes/meta/
# detr3d_efficientnetb3_nuscenes为bev检测模型,不需要指定 --seg_eval_path
python3 bev_eval.py --det_eval_path=eval.log --gt_files_path=./nuscenes_bev_val/val_gt_infos.pkl --meta_dir=./Nuscenes/meta/
备注:
-
det_eval_path:bev模型检测任务的预测结果文件。 -
seg_eval_path:bev模型分割任务的预测结果文件。 -
gt_files_path:对nuscenes数据集进行预处理生成的gt文件。 -
meta_dir:nuscenes数据集的meta信息路径。 -
分类模型
使用CIFAR-10数据集和ImageNet数据集的分类模型计算方式如下:
#!/bin/sh
python3 cls_eval.py --log_file=eval.log --gt_file=val.txt
备注:
-
log_file:分类模型的预测结果文件。 -
gt_file:CIFAR-10和ImageNet数据集的标注文件。 -
检测模型
-
1.使用COCO数据集的检测模型精度计算方式示例如下:
#!/bin/sh
python3 fcos_eval.py --eval_result_path=eval.log --annotation_path=instances_val2017.json --image_path=./mscoco/images/val2017/
# qat fcos模型需要增加--is_qat=True
python3 fcos_eval.py --eval_result_path=eval.log --annotation_path=instances_val2017.json --image_path=./mscoco/images/val2017/ --is_qat=True
备注:
eval_result_path:fcos检测模型的预测结果文件。annotation_path:COCO数据集的标注文件。image_path:COCO原始数据集。is_qat:是否是qat fcos模型结果评测。
#!/bin/sh
python3 retinanet_eval.py --eval_result_path=eval.log --annotation_path=instances_val2017.json --image_path=./mscoco/images/val2017/
备注:
eval_result_path:retinanet检测模型的预测结果文件。annotation_path:COCO数据集的标注文件。image_path:COCO原始数据集。
#!/bin/sh
python3 detr_eval.py --eval_result_path=eval.log --annotation_path=instances_val2017.json --image_path=./mscoco/images/val2017/
备注:
-
eval_result_path:retinanet检测模型的预测结果文件。 -
annotation_path:COCO数据集的标注文件。 -
image_path:COCO原始数据集。 -
2.使用VOC数据集的检测模型精度计算方式示例如下:
#!/bin/sh
python3 yolov3_eval.py --eval_result_path=eval.log --annotation_path=../Annotations --val_txt_path=../val.txt --image_height=416 --image_width=416
备注:
-
eval_result_path:检测模型的预测结果文件。 -
annotation_path:VOC数据集的标注文件。 -
val_txt_path:VOC数据集中ImageSets/Main文件夹下的val.txt文��件。 -
image_height: 图像的高度。 -
image_width: 图像的宽度。 -
3.使用Kitti数据集的检测模型精度计算方式如下:
#!/bin/sh
python3 pointpillars_eval.py --eval_result_path=eval.log --annotation_path=./val_gt_infos.pkl
备注:
-
eval_result_path:检测模型的预测结果文件。 -
annotation_path:预处理过程中生成的kitti3d数据集的标注文件val_gt_infos.pkl。 -
4.使用Culane数据集的检测模型精度计算方式如下:
#!/bin/sh
python3 ganet_eval.py --eval_path=eval.log --image_path=./culane
备注:
-
eval_result_path:检测模型的预测结果文件。 -
image_path:culane数据集。 -
5.使用Nuscenes数据集的检测模型精度计算方式如下:
#!/bin/sh
python3 fcos3d_eval.py --eval_result_path=eval.log --image_path=./Nuscenes
备注:
eval_result_path:检测模型的预测结果文件。image_path:nuscenes数据集。
#!/bin/sh
python3 centerpoint_eval.py --predict_result_path=eval.log --gt_files_path=./nuscenes_lidar_val/val_gt_infos.pkl --meta_dir=./Nuscenes/meta/
备注:
-
predict_result_path:检测模型的预测结果文件。 -
gt_files_path: 对nuscenes数据集进行预处理生成的gt文件。 -
meta_dir: nuscenes数据集的meta信息路径。 -
6.使用Carfusion数据集的检测模型精度计算方式如下:
#!/bin/sh
python3 keypoints_eval.py --anno_path=./processed_carfusion/processed_anno.json --eval_result_path=eval.log
备注:
-
anno_path:预处理生成的processed_anno.json文件。 -
eval_result_path:检测模型的预测结果文件。 -
分割模型
使用Cityscapes数据集的分割模型精度计算方式如下:
#!/bin/sh
python3 parsing_eval.py --log_file=eval.log --gt_path=cityscapes/gtFine/val
备注:
-
log_file:分割模型的预测结果文件。 -
gt_path:Cityscapes数据集的标注文件。 -
光流模型
使用FlyingChairs数据集的光流模型精度计算方式如下:
#!/bin/sh
python3 pwcnet_eval.py --log_file=eval.log --gt_path=./flyingchairs/FlyingChairs_release/data/ --val_file=./flyingchairs/FlyingChairs_train_val.txt
备注:
-
log_file:光流模型的预测结果文件。 -
val_file:FlyingChairs数据集标签文件。 -
gt_path:FlyingChairs数据集原始文件。 -
追踪模型
使用mot17数据集的追踪模型计算方式如下:
#!/bin/sh
python3 motr_eval.py --eval_result_path=eval_log --gt_val_path=valdata/gt_val
备注:
-
eval_result_path:追踪模型的预测结果文件夹。 -
gt_val_path:mot17数据集的标注文件。 -
多任务模型
使用nuscenes数据集的lidar多任务模型精度计算方式如下:
#!/bin/sh
python3 lidar_multitask_eval.py --det_eval_path=det_eval.log --seg_eval_path=seg_eval.log --gt_files_path=./nuscenes_lidar_val/val_gt_infos.pkl --data_dir=./Nuscenes
备注:
-
det_eval_path: 检测任务的预测结果文件。 -
seg_eval_path: 分割任务的预测结果文件。 -
gt_files_path: 对nuscenes数据集进行预处理生成的gt文件。 -
data_dir: nuscenes数据集路径。 -
轨迹预测模型
使用argoverse1数据集的追踪模型计算方式如下:
#!/bin/sh
python3 densetnt_eval.py --eval_result_path=eval.log --meta_path=argoverse1/meta
备注:
-
eval_result_path:轨迹预测的预测结果文件。 -
meta_path:argoverse1数据集生成的的标注文件,使用预处理脚本后,生成在原数据集目录meta中。 -
深度估计模型
使用Sceneflow数据集的深度估计模型精度计算方式如下:
#!/bin/sh
python3 stereonet_eval.py --log_file=eval.log --gt_files=val_gt_infos.pkl
备注:
log_file:深度估计模型的预测结果文件。gt_files:对Sceneflow数据集进行预处理生成的gt文件。
模型集成
前处理
您可根据需要自行添加模型前处理,将其部署到 CPU 上,以centerpoint_pointpillar_nuscenes为例:
1.增加前处理文件qat_centerpoint_preprocess_method.cc,以及头文件qat_centerpoint_preprocess_method.h。
2.增加模型前处理配置文件。
前处理文件及头文件添加
前处理文件 qat_centerpoint_preprocess_method.cc 放置于 ai_benchmark/code/src/method/ 路径下,
头文件 qat_centerpoint_preprocess_method.h 放置于 ai_benchmark/code/include/method/ 路径下:
|── ai_benchmark
| |── code # 示例源码
| | |── include
| | | |── method # 在此文件夹中添加头文件
| | | | |── qat_centerpoint_preprocess_method.h
| | | | |── ...
| | |── src
| | | |── method # 在此文件夹中添加前处理.cc文件
| | | | |── qat_centerpoint_preprocess_method.cc
| | | | |── ...
模型前处理配置文件添加
|── ai_benchmark
| |── x5/qat/script # 示例脚本文件夹
| | |── config
| | | |── preprocess
| | | | |── centerpoint_preprocess_5dim.json # 前处理配置脚本
前处理单帧延时评测
执行 sh latency.sh 脚本可对前处理的单帧延迟情况进行测试。如下所示:
I0615 13:30:40.772293 3670 output_plugin.cc:91] Pre process latency: [avg: 20.295ms, max: 28.690ms, min: 18.512ms], Infer latency: [avg: 25.053ms, max: 31.943ms, min: 24.702ms], Post process latency: [avg: 52.760ms, max: 54.099ms, min: 51.992ms].
其中:
-
Pre process表示前处理耗时。 -
Infer表示模型推理耗时。 -
Post process表示后处理耗时。
后处理
后处理集成主要有2个步骤,以CenterNet模型集成为例:
- 增加后处理文件
ptq_centernet_post_process_method.cc,以及头文件ptq_centernet_post_process_method.h。 - 增加模型运行脚本及配置文件。
后处理文件及头文件添加
后处理代码文件可直接复用src/method目录下任意后处理文件,主要修改 InitFromJsonString 函数,以及 PostProcess 函数即可。
InitFromJsonString 函数主要是读取workflow.json中的后处理相关的参数配置,用户可自定义设置相应的输入参数。
PostProcess 函数主要完��成后处理的逻辑。
后处理.cc文件放置于 ai_benchmark/code/src/method/ 路径下,
.h头文件放置于 ai_benchmark/code/include/method/ 路径下:
|── ai_benchmark
| |── code # 示例源码
| | |── include
| | | |── method # 在此文件夹中添加头文件
| | | | |── ptq_centernet_post_process_method.h
| | | | |── ...
| | |── src
| | | |── method # 在此文件夹中添加后处理.cc文件
| | | | |── ptq_centernet_post_process_method.cc
| | | | |── ...
增加模型运行脚本及配置文件
模型运行脚本及配置文件完成添加后的目录结构参考如下:
- centerpoint_pointpillar_nuscenes模型:
|── ai_benchmark
| |── x5/qat/script # 示例脚本文件夹
| | |── detection
| | | |── centerpoint_pointpillar_nuscenes
| | | | |── accuracy.sh # 精度测试脚本
| | | | |── fps.sh # 性能测试脚本
| | | | |── latency.sh # 单帧延时示例脚本
| | | | |── workflow_accuracy # 精度配置文件夹
| | | | |── workflow_fps.json # 性能配置文件
| | | | |── workflow_latency.json # 单帧延时配置文件
- motr_efficientnetb3_mot17模型:
|── ai_benchmark
| |── x5/qat/script # 示例脚本文件夹
| | |── tracking
| | | |── motr
| | | | |── accuracy.sh # 精度测试脚本
| | | | |── fps.sh # 性能测试脚本
| | | | |── generate_acc_lst.sh # 生成精度lst脚本
| | | | |── latency.sh # 单帧延时示例脚本
| | | | |── workflow_accuracy # 精度配置文件夹
| | | | |── workflow_fps.json # 性能配置文件
| | | | |── workflow_latency.json # 单帧延时配置文件
- 除centerpoint_pointpillar_nuscenes模型及motr_efficientnetb3_mot17外其他模型:
|── ai_benchmark
| |── x5/ptq/script # 示例脚本文件夹
| | |── detection
| | | |── centernet_resnet101
| | | | |── accuracy.sh # 精度测试脚本
| | | | |── fps.sh # 性能测试脚本
| | | | |── latency.sh # 单帧延时示例脚本
| | | | |── workflow_accuracy.json # 精度配置文件
| | | | |── workflow_fps.json # 性能配置文件
| | | | |── workflow_latency.json # 单帧延时配置文件
辅助工具和常用操作
日志系统使用说明
日志系统主要包括 示例日志 和 模型推理API DNN日志 两部分。
其中示例日志是指交付包示例代码中的应用日志;DNN日志是指lib dnn库中的日志。
用户根据不同的需求可以获取不同的日志。
示例日志
- 日志等级。示例日志主要采用glog中的vlog,主要分为四个自定义等级:
0(SYSTEM),该等级主要用来输出报错信息;1(REPORT),该等级在示例代码中主要用来输出性能数据;2(DETAIL),该等级在示例代码中主要用来输出系统当前状态信息;3(DEBUG),该等级在示例代码中主要用来输出调试信息。 日志等级设置规则:假设设置了级别为P,如果发生了一个级别Q比P低, 则可以启动,否则屏蔽掉;默认DEBUG>DETAIL>REPORT>SYSTEM。
- 日志等级设置。通过
log_level参数来设置日志等级,在运行示例的时候,指定log_level参数来设置等级, 比如指定log_level=0,即输出SYSTEM日志;如果指定log_level=3, 则输出DEBUG、DETAIL、REPORT和SYSTEM日志。
模型推理API DNN日志
关于模型推理 DNN API日志的配置,请阅读《算法工具链产品手册》。
算子耗时说明
对模型算子(OP)性能的统计是通过设置 HB_DNN_PROFILER_LOG_PATH 环境变量实现的,本节介绍模型的推理性能分析,有助于开发者了解模型的真实推理性能情况。
对该变量的类型和取值说明如下:
备注:
export HB_DNN_PROFILER_LOG_PATH=${path}:表示OP节点dump的输出路径,程序正常运行完退出后,产生profiler.log文件。
- 示例说明
以下代码块以mobilenetv1模型为例,开启单个线程同时RunModel,设置 export HB_DNN_PROFILER_LOG_PATH=./,则统计输出的信息如下:
{
"perf_result": {
"FPS": 677.6192525182025,
"average_latency": 11.506142616271973
},
"running_condition": {
"core_id": 0,
"frame_count": 200,
"model_name": "mobilenetv1_224x224_nv12",
"run_time": 295.151,
"thread_num": 1
}
}
***
{
"chip_latency": {
"BPU_inference_time_cost": {
"avg_time": 11.09122,
"max_time": 11.54,
"min_time": 3.439
},
"CPU_inference_time_cost": {
"avg_time": 0.18836999999999998,
"max_time": 0.4630000000000001,
"min_time": 0.127
}
},
"model_latency": {
"BPU_MOBILENET_subgraph_0": {
"avg_time": 11.09122,
"max_time": 11.54,
"min_time": 3.439
},
"Dequantize_fc7_1_HzDequantize": {
"avg_time": 0.07884999999999999,
"max_time": 0.158,
"min_time": 0.068
},
"MOBILENET_subgraph_0_output_layout_convert": {
"avg_time": 0.018765,
"max_time": 0.08,
"min_time": 0.01
},
"Preprocess": {
"avg_time": 0.0065,
"max_time": 0.058,
"min_time": 0.003
},
"Softmax_prob": {
"avg_time": 0.084255,
"max_time": 0.167,
"min_time": 0.046
}
},
"task_latency": {
"TaskPendingTime": {
"avg_time": 0.029375,
"max_time": 0.059,
"min_time": 0.009
},
"TaskRunningTime": {
"avg_time": 11.40324,
"max_time": 11.801,
"min_time": 4.008
}
}
}
以上输出了 model_latency 和 task_latency。其中model_latency中输出了模型每个OP运行所需要的耗时情况,task_latency中输出了模型运行中各个task模块的耗时情况。
备注:
程序只有正常退出才会输出profiler.log文件。
dump工具
本节主要介绍dump工具的开启方法,一般不需要关注,只有在模型精度异常情况时开启使用。
通过设置 export HB_DNN_DUMP_PATH=${path} 这个环境变量,可以dump出模型推理过程中每个节点的输入和输出, 根据dump的输出结果,可以排查模型推理在开发机模拟器和开发板是否存在一致性问题:即相同模型,相同输入,开发板和开发机模拟器的输出结果是否完全相同。
模型上板分析工具说明
概述
本章节介绍X5算法工具链中模型上板推理的快速验证工具,方便开发者可以快速获取到 ***.bin 模型的信息、模型推理的性能、模型debug等内容。
hrt_model_exec 工具使用说明
hrt_model_exec 工具,可以快速在开发板上评测模型的推理性能、获取模型信息等。
目前工具提供了三类功能,如下表所示:
| 编号 | 子命令 | 说明 |
|---|---|---|
| 1 | model_info | 获取模型信息,如:模型的输入输出信息等。 |
| 2 | infer | 执行模型推理,获取模型推理结果。 |
| 3 | perf | 执行模型性能分析,获取性能分析结果。 |
小技巧:
工具也可以通过 -v 或者 --version �命令,查看工具的 dnn 预测库版本号。
例如: hrt_model_exec -v 或 hrt_model_exec --version
输入参数描述
在开发板上运行 hrt_model_exec 、 hrt_model_exec -h 或 hrt_model_exec --help 获取工具的使用参数详情。
如下图中所示:
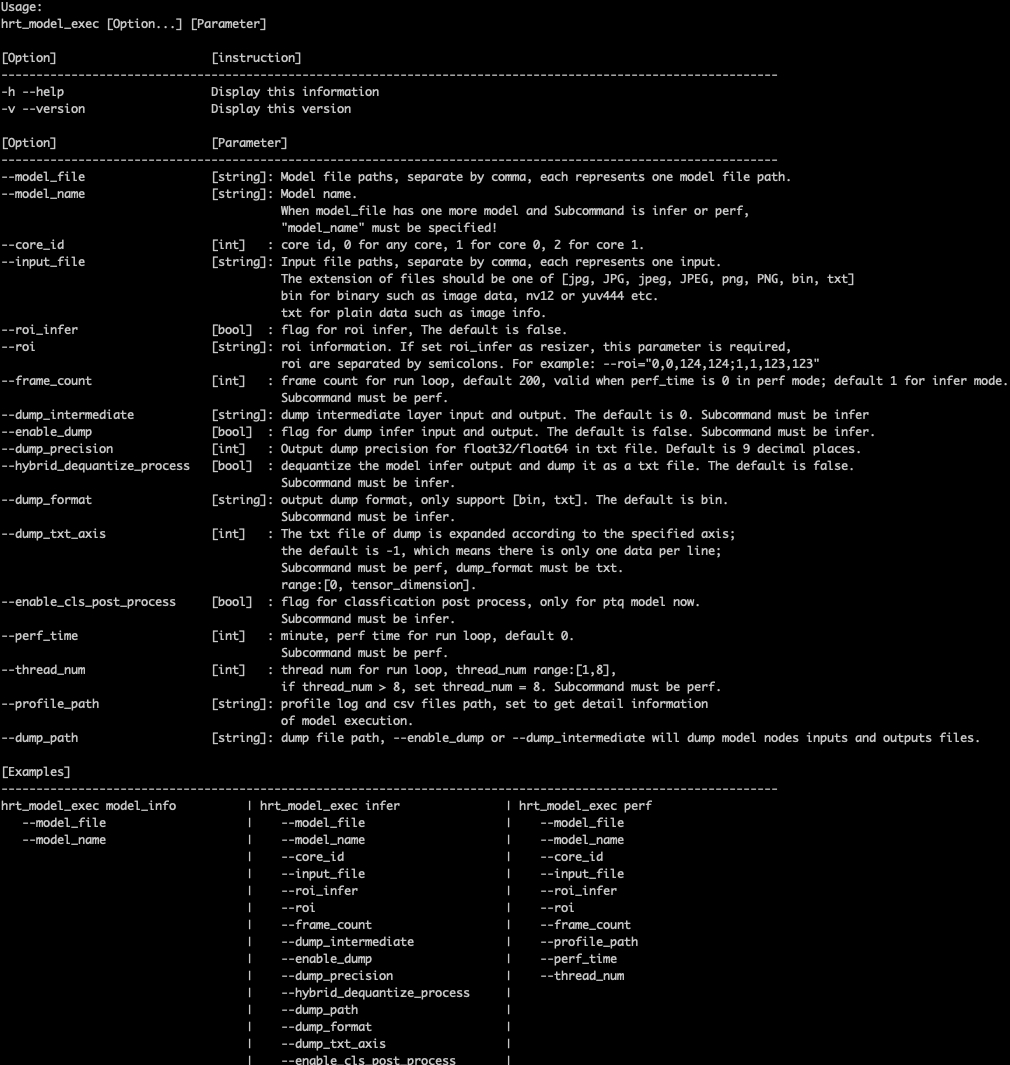
| 编号 | 参数 | 类型 | 说明 |
|---|---|---|---|
| 1 | model_file | string | 模型文件路径,多个路径可通过逗号分隔。 |
| 2 | model_name | string | 指定模型中某个模型的名称。 |
| 3 | core_id | int | 指定运行核。0:任意核,1:core0,2:core1;默认为 0。 |
| 4 | input_file | string | 模型输入信息。图片输入后缀必须为 bin / JPG / JPEG / jpg / jpeg / png / PNG中的一种。feature输入后缀名必须为 bin / txt 中的一种。 每个输入之间需要用英文字符的逗号隔开 ,,如: xxx.jpg,input.txt。当模型中含有对输入数据有要求的算子时,推荐使用指定数据进行perf,如:Gather算子的index输入需要满足一定范围。 |
| 5 | roi_infer | bool | 使能resizer模型推理。 若模型存在resizer输入源的输入,需设置为 true, 并且配置与输入源一一对应的 input_file 和 roi 参数。 |
| 6 | roi | string | 指定推理resizer模型时所需的roi区域。 多个roi之间通过英文分号间隔。如:--roi="2,4,123,125;6,8,111,113" |
| 7 | frame_count | int | 执行模型运行帧数。 |
| 8 | dump_intermediate | string | dump模型每一层输入和输出。 - dump_intermediate=0 时,默认dump功能关闭。 - dump_intermediate=1 时,模型中每一层节点输入数据输出数据以 bin 方式保存,其中 BPU 节点输出为 aligned 数据。- dump_intermediate=2 时,模型中每一层节点输入数据和输出数据以 bin和 txt 两种方式保存,其中 BPU 节点输出为 aligned 数据。 - dump_intermediate=3 时,模型中每一层节点输入数据和输出数据以 bin 和 txt 两种方式保存,其中 BPU 节点输出为 valid 数据。 |
| 9 | enable_dump | bool | 使能dump模型输入和输出,默认为 false。 |
| 10 | dump_precision | int | 控制txt格式输出float型数据的小数点位数,默认为 9。 |
| 11 | hybrid_dequantize_process | bool | 对原始输出进行后处理后保存。在 enable_dump=true 时生效,且只支持四维模型。后处理包括对定点输出进行反量化操作、去除 padding 操作。 |
| 12 | dump_format | string | dump模型输入和输出的格式。 |
| 13 | dump_txt_axis | int | 控制txt格式输入输出的换行规则。 |
| 14 | enable_cls_post_process | bool | 使能分类后处理,默认为 false。子命令为 infer 时配合使用,目前只支持ptq分类模型的后处理,打印分类结果。 |
| 15 | perf_time | int | 执行模型运行时间。 |
| 16 | thread_num | int | 线程数(并行度),数值可以表示最多有多少个任务在并行处理。测试延时,数值需要设置为1,没有资源抢占发生,延时测试更准确。测试吞吐,建议设置>2 (BPU核心个数),调整线程数使BPU利用率尽量高,吞吐测试更准确。 |
| 17 | profile_path | string | 统计工具日志产生路径,运行产生profiler.log和profiler.csv,分析op耗时和调度耗时。一般设置 --profile_path="." 即可,代表在当前目录下生成日志文件。 |
| 18 | dump_path | string | 工具dump输出文件路径,enable_dump或dump_intermediate都会产生输出文件,指定路径后,文件将输出在指定路径下,若路径不存在,则工具会自动创建。 |
使用说明
本节介绍 hrt_model_exec 工具的三个子功能的具体使用方法
model_info
- 概述
该参数用于获取模型信息,模型��支持范围:QAT模型,PTQ模型。
该参数与 model_file 一起使用,用于获取模型的详细信息;
模型的信息包括:模型输入输出信息 hbDNNTensorProperties 和模型的分段信息 stage ;模型的分段信息是:一张图片可以分多个阶段进行推理,stage信息为[x1, y1, x2, y2],分别为图片推理的左上角和右下角坐标,目前X5的bayes架构支持这类分段模型的推理,X3上模型均为1个stage。
小技巧:
不指定 model_name ,则会输出模型中所有模型信息,指定 model_name ,则只输出对应模型的信息。
- 示例说明
- 单模型
hrt_model_exec model_info --model_file=xxx.bin
- 多模型(输出所有模型信息)
hrt_model_exec model_info --model_file=xxx.bin,xxx.bin
- 多模型--pack模型(输出指定模型信息)
hrt_model_exec model_info --model_file=xxx.bin --model_name=xx
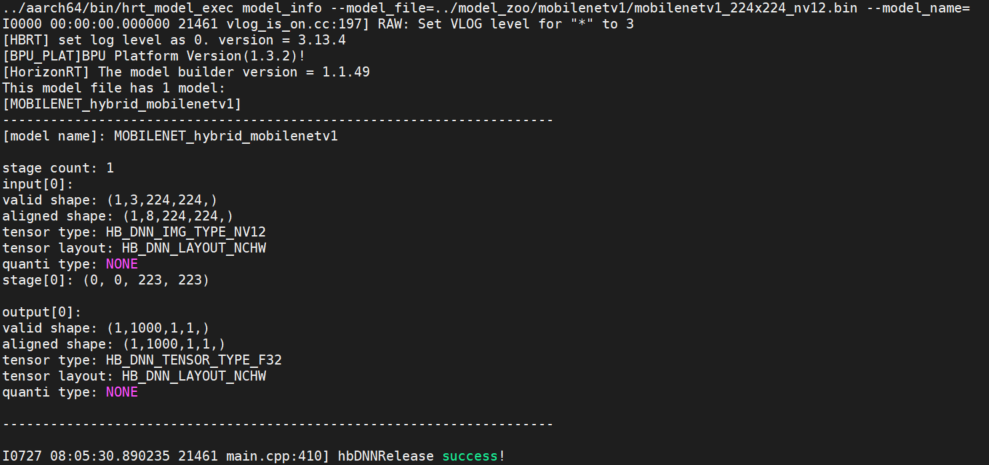
输入参数补充说明
- 重复输入
若重复指定参数输入,则会发生参数覆盖的情况,例如:获取模型信息时重复指定了两个模型文件,则会取后面指定的参数输入 yyy.bin:
hrt_model_exec model_info --model_file=xxx.bin --model_file=yyy.bin
若重复指定输入时,未加命令行参--model_file,则会取命令行参数后面的值,未加参数的不识别,
例如:下例会忽略 yyy.bin,参数值为 xxx.bin:
hrt_model_exec model_info --model_file=xxx.bin yyy.bin
infer
- 概述
该参数用于输入自定义图片后,模型推理一帧,并给出模型推理结果。
该参数需要与 input_file 一起使用,指定输入图片路径,工具根据模型信息resize图片,整理模型输入信息。
小技巧:
程序单线程运行单帧数据,输出模型运行的时间。
- 示例说明
- 单模型
hrt_model_exec infer --model_file=xxx.bin --input_file=xxx.jpg
- 多模型
hrt_model_exec infer --model_file=xxx.bin,xxx.bin --model_name=xx --input_file=xxx.jpg
- resizer模型
模型有三个输入,输入源顺序分别为[ddr, resizer, resizer]。
推理两帧数据,假设第一帧输入为[xx0.bin,xx1.jpg,xx2.jpg],roi为[2,4,123,125;6,8,111,113],第二帧输入为[xx3.bin,xx4.jpg,xx5.jpg],roi为[27,46,143,195;16,28,131,183],则推理命令如下:
hrt_model_exec infer --roi_infer=true --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
注意: 多帧输入之间用英文逗号隔离,roi之间使用分号隔离。
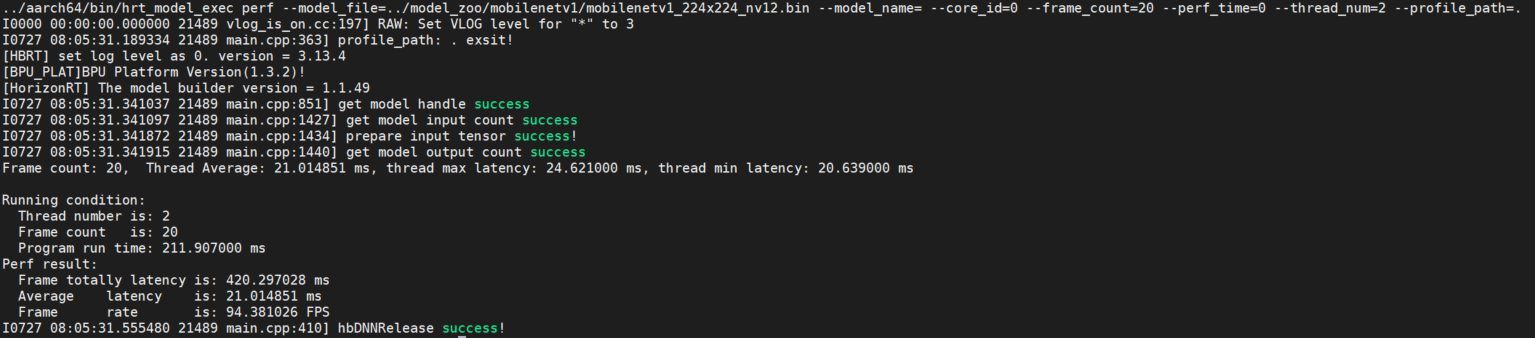
-
可选参数
参数 说明 core_id指定模型推理的核id,0:任意核,1:core0,2:core1;默认为 0,X5上因为只有一个BPU核,配置0或1。roi_infer使能resizer模型推理;若模型输入包含resizer源,设置为 true,默认为false。roiroi_infer为true时生效,��设置推理resizer模型时所需的roi区域以分号间隔。frame_count设置 infer运行帧数,单帧重复推理,可与enable_dump并用,验证输出一致性,默认为1。dump_intermediatedump模型每一层输入数据和输出数据,默认值 0,不dump数据。1:输出文件类型为bin;2:输出类型为bin和txt,其中BPU节点输出为aligned数据;3:输出类型为bin和txt,其中BPU节点输出为valid数据。enable_dumpdump模型输出数据,默认为 false。dump_precision控制txt格式输出float型数据的小数点位数,默认为 9。hybrid_dequantize_process控制txt格式输出float类型数据,若输出为定点数据将其进行反量化处理,目前只支持四维模型。 dump_formatdump模型输出文件的类型,可选参数为 bin或txt,默认为bin。dump_txt_axisdump模型txt格式输出的换行规则;若输出维度为n,则参数范围为[0, n], 默认为 -1,一行一个数据。enable_cls_post_process使能分类后处理,目前只支持ptq分类模型,默认 false。dump_path指定dump输出路径,默认当前路径。
多输入模型说明
工具 infer 推理功能支持多输入模型的推理,支持图片输入、二进制文件输入以及文本文件输入,输入数据用逗号隔开。
模型的输入信息可以通过 model_info 进行查看。
- 示例说明
hrt_model_exec infer --model_file=xxx.bin --input_file=xxx.jpg,input.txt
输入参数补充说明
input_file
图片类型的输入,其文件名后缀必须为 bin / JPG / JPEG / jpg / jpeg / png 中的一种,feature输入后缀名必须为 bin / txt 中的一种。
每个输入之间需要用英文字符的逗号隔开 ,,例如: xxx.jpg,input.txt。
enable_cls_post_process
使能分类后处理。子命令为 infer 时配合使用,目前只支持在PTQ分类模型的后处理时使用,变量为 true 时打印分类结果。
参见下图:
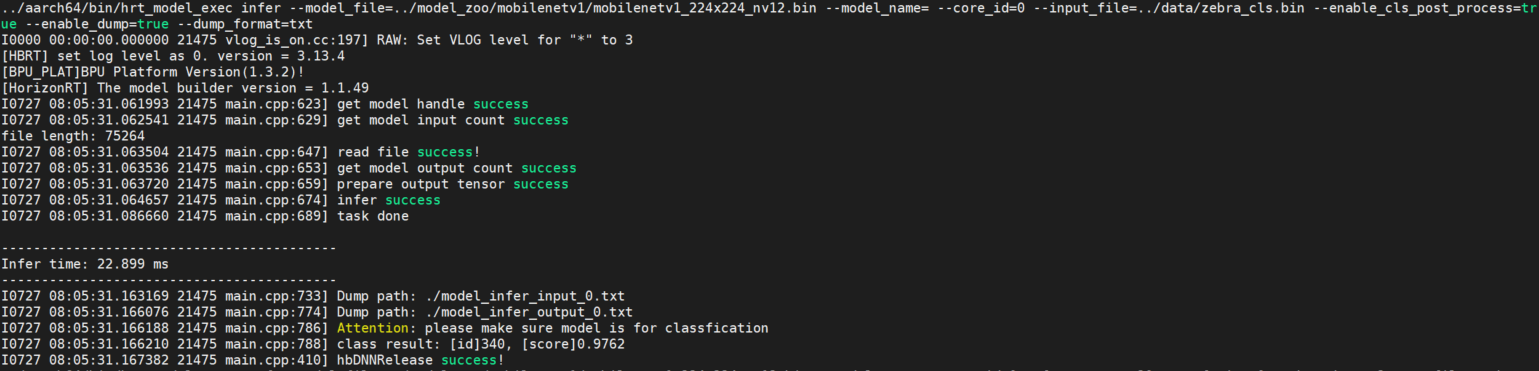
roi_infer
若模型包含resizer输入源, infer 和 perf 功能都需要设置 roi_infer 为true,并且配置与输入源一一对应的 input_file 和 roi 参数。
如:模型有三个输入,输入源顺序分别为[ddr, resizer, resizer],则推理两组输入数据的命令行如下:
// infer
hrt_model_exec infer --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
// perf
hrt_model_exec perf --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
每个 roi 输入之间需要用英文字符的分号隔开。
dump_intermediate
dump模型每一层节点的输入数据和输出数据。 dump_intermediate=0 时,默认dump功能关闭;
dump_intermediate=1 时,模型中每一层节点输入数据和输出数据以 bin 方式保存,其中 BPU 节点输出为 aligned 数据;
dump_intermediate=2 时,模型中每一层节点输入数据和输出数据以 bin 和 txt 两种方式保存,其中 BPU 节点输出为 aligned 数据;
dump_intermediate=3 时,模型中每一层节点输入数据和输出数据以 bin 和 txt 两种方式保存,其中 BPU 节点输出为 valid 数据。
如: 模型有两个输入,输入源顺序分别为[pyramid, ddr],将模型每一层节点的输入和输出保存为 bin 文件,其中 BPU 节点输出按 aligned 类型保存,则推理命令行如下:
hrt_model_exec infer --model_file=xxx.bin --input_file="xx0.jpg,xx1.bin" --dump_intermediate=1
dump_intermediate 参数支持 infer 和 perf 两种模式。
hybrid_dequantize_process
控制txt格式输出float类型数据。 hybrid_dequantize_process 参数在 enable_dump=true 时生效。
当 enable_dump=true 时,若设置 hybrid_dequantize_process=true ,反量化整型输出数据,将所有输出按float类型保存为 txt 文件,其中模型输出为 valid 数据,支持配置 dump_txt_axis 和 dump_precision;
若设置 hybrid_dequantize_process=false ,直接保存模型输出的 aligned 数据,不做任何处理。
如: 模型有3个输�出,输出Tensor数据类型顺序分别为[float,int32,int16], 输出txt格式float类型的 valid 数据, 则推理命令行如下:
// 输出float类型数据
hrt_model_exec infer --model_file=xxx.bin --input_file="xx.bin" --enable_dump=true --hybrid_dequantize_process=true
hybrid_dequantize_process 参数目前只支持四维模型。
perf
- 概述
该参数用于测试模型的推理性能。 使用此工具命令,用户无需输入数据,程序会根据模型信息自动构造模型的输入tensor,tensor数据为随机数。 程序默认单线程运行200帧数据,当指定perf_time参数时,frame_count参数失效,程序会执行指定时间后退出。 程序运行完成后,会输出模型运行的程序线程数、帧数、模型推理总时间,模型推理平均latency,帧率信息等。
小技巧:
程序每200帧打印一次性能信息:latnecy的最大、最小、平均值,不足200帧程序运行结束打印一次。
- 示例说明
- 单模型
hrt_model_exec perf --model_file=xxx.bin
- 多模型
hrt_model_exec perf --model_file=xxx.bin,xxx.bin --model_name=xx
- resizer模型
模型有三个输入,输入源顺序分别为[ddr, resizer, resizer]。
推理两帧数据,假设第一帧输入为[xx0.bin,xx1.jpg,xx2.jpg],roi为[2,4,123,125;6,8,111,113],第二帧输入为[xx3.bin,xx4.jpg,xx5.jpg],roi为[27,46,143,195;16,28,131,183],则推理命令如下:
hrt_model_exec perf --roi_infer=true --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
注意: 多帧输入之间用英文逗号隔离,roi之间使用分号隔离。
-
可选参数
参数 说明 core_id指定模型推理的核id,0:任意核,1:core0,2:core1;默认为 0,X5上因为只有一个BPU核,配置0或1。input_file模型输入信息,多个可通过逗号分隔。 roi_infer使能resizer模型推理;若模型输入包含resizer源,设置为 true,默认为false。roiroi_infer为true时生效,设置推理resizer模型时所需的roi区域以英文分号间隔。frame_count设置 perf运行帧数,当perf_time为0时生效,默认为200。perf_time设置 perf运行时间,单位:分钟,默认为0。thread_num设置程序运行线程数,范围[1, 8], 默认为 1, 设置大于8时按照8个线程处理。profile_path统计工具日志产生路径,运行产生profiler.log和profiler.csv,分析op耗时和调度耗时。
多线程Latency数据说明
多线程的目的是为了充分利用BPU�资源,多线程共同处理 frame_count 帧数据或执行perf_time时间,直至数据处理完成/执行时间结束程序结束。
在多线程 perf 过程中可以执行以下命令,实时获取BPU资源占用率情况。
hrut_somstatus -n 10000 –d 1
X3 输出内容如下:
=====================1=====================
temperature-->
CPU : 37.5 (C)
cpu frequency-->
min cur max
cpu0: 240000 1200000 1200000
cpu1: 240000 1200000 1200000
cpu2: 240000 1200000 1200000
cpu3: 240000 1200000 1200000
bpu status information---->
min cur max ratio
bpu0: 400000000 1000000000 1000000000 0
bpu1: 400000000 1000000000 1000000000 0
X5 输出内容如下:
=====================1=====================
temperature-->
DDR : 57.0 (C)
cat: /sys/class/hwmon/hwmon0/temp2_input: Connection timed out
BPU : 0.0 (C)
CPU : 56.6 (C)
cpu frequency-->
min(M) cur(M) max(M)
cpu0: 300 1500 1500
cpu1: 300 1500 1500
cpu2: 300 1500 1500
cpu3: 300 1500 1500
cpu4: 300 1500 1500
cpu5: 300 1500 1500
cpu6: 300 1500 1500
cpu7: 300 1500 1500
bpu status information---->
min(M) cur(M) max(M) ratio
bpu0: 500 1000 1000 0
ddr frequency information---->
min(M) cur(M) max(M)
ddr: 266 3200 3200
备注:
在 perf 模式下,单线程的latency时间表示模型的实测上板性能,
而多线程的latency数据表示的是每个线程的模型单帧处理时间,其相对于单线程的时间要长,但是多线程的总体处理时间减少,其帧率是提升的。
输入参数补充说明
profile_path
profile日志文件产生目录。
该参数通过设置环境变量 export HB_DNN_PROFILER_LOG_PATH=${path} 查看模型运行过程中OP以及任务调度耗时。
一般设置 --profile_path="." 即可,代表在当前目录下生成日志文件,日志文件为profiler.log。
thread_num
线程数(并行度),数值表示最多有多少个任务在并行处理。
测试延时时,数值需要设置为1,没有资源抢占发生,延时测试更准确。
测试吞吐时,建议设置>2 (BPU核心个数),调整线程数使BPU利用率尽量高,吞吐测试更准确。
注意: X5只有一个BPU核,core_id 只能设置为 0 或 1
// 多线程FPS
hrt_model_exec perf --model_file xxx.bin --thread_num 8 --core_id 0
// Latency
hrt_model_exec perf --model_file xxx.bin --thread_num 1 --core_id 1
常见问题
Latency、FPS数据是如何统计的?
Latency是指单流程推理模型所耗费的平均时间,重在表示在资源充足的情况下推理一帧的平均耗时,体现在上板运行是单核单线程统计;统计方法伪代码如下:
// Load model and prepare input and output tensor
...
// Loop run inference and get latency
{
int32_t const loop_num{1000};
start = std::chrono::steady_clock::now();
for(int32_t i = 0; i < loop_num; i++){
hbDNNInferCtrlParam infer_ctrl_param;
HB_DNN_INITIALIZE_INFER_CTRL_PARAM(&infer_ctrl_param);
hbDNNInfer(&task_handle,
&output,
input_tensors.data(),
dnn_handle,
&infer_ctrl_param);
// wait task done
hbDNNWaitTaskDone(task_handle, 0);
// release task handle
hbDNNReleaseTask(task_handle);
task_handle = nullptr;
}
end = std::chrono::steady_clock::now();
latency = (end - start) / loop_num;
}
// release tensor and model
FPS是指多流程同时进行模型推理平均一秒推理的帧数,重在表示充分使用资源情况下模型的吞吐,体现在上板运行为单核多线程;统计方法是同时起多个线程进行模型推理,计算平均1s推理的总帧数。
通过Latency推算FPS与工具测出的FPS为什么不一致?
Latency与FPS的统计情景不同,Latency为单流程(单核单线程)推理,FPS为多流程(单核多线程)推理,因此推算不一致;若统计FPS时将流程(线程)数量设置为 1 ,则通过Latency推算FPS和测出的一致。
工具如何评测自定义算子模型?
参考horizon_runtime_sample/code/02_advanced_samples/custom_identity示例开发自定义算子,将自定义算子编译成动态库,在工具使用之前指定该动态库路径即可。 例如动态库路径为:/userdata/plugins/libplugin.so,工具运行含该自定义算子的模型,仅需指定该动态库所在路径即可。
export HB_DNN_PLUGIN_PATH=/userdata/plugins/
hrt_bin_dump 工具使用说明
hrt_bin_dump 是模型的layer dump工具,工具的输出文件为二进制文件。
输入参数描述
| 编号 | 参数 | 类型 | 描述 | 说明 |
|---|---|---|---|---|
| 1 | model_file | string | 模型文件路径。 | 指定模型文件路径,可dump模型所有节点的输入和输出文件 |
| 2 | input_file | string | 输入文件路径。 | 模型的输入文件,支持 hbDNNDataType 所有类型的输入; IMG类型文件需为二进制文件(后缀必须为.bin),二进制文件的大小应与模型的输入信息相匹配,如:YUV444文件大小为 :math:height * width * 3; TENSOR类型文件需为二进制文件或文本文件(后缀必须为.bin/.txt),二进制文件的大小应与模型的输入信息相匹配,文本文件的读入数据个数必须大于等于模型要求的输入数据个数,多余的数据会被丢弃;每个输入之间通过逗号分隔,如:模型有两个输入,则: --input_file=kite.bin,input.txt。 |
| 3 | dump_path | string | 工具输出路径。 | 工具的输出路径,该路径应为合法路径。 |
使用说明
工具提供模型节点输入输出dump卷积层输出功能,输出文件为二进制文件。
直接运行 hrt_bin_dump 获取工具使用详情。
参见下图:
小技巧:
工具也可以通过 -v 或者 --version 命令,查看工具的 dnn 预测库版本号。
例如: hrt_bin_dump -v 或 hrt_bin_dump --version
示例说明
以mobilenetv1的模型为例,创建outputs文件夹,执行以下命令:
./hrt_bin_dump --model_file=./mobilenetv1.bin --dump_path=./outputs --input_file=./input.bin
运行日志参见以下截图:

在路径 outputs/ 文件夹下可以查看输出,参见以下截图:

RDK Ultra
模型推理DNN API使用示例说明
概述
本章节介绍模型上板运行 horizon_runtime_sample 示例包的具体用法,开发者可以体验并基于这些示例进行应用开发,降低开发门槛。
示例包提供三个方面的示例:
- 模型推理 dnn API使用示例。
- 自定义算子(custom OP)等特殊功能示例。
- 非NV12输入模型的杂项示例。
详细内容请阅读下文。
horizon_runtime_sample 示例包获取请参考 交付物说明。
示例代码包结构介绍
+---horizon_runtime_sample
|── README.md
├── code # 示例源码
│ ├── 00_quick_start # 快速入门示例,用mobilenetv1读取单张图片进行推理的示例代码
│ │ ├── CMakeLists.txt
│ │ ├── CMakeLists_x86.txt
│ │ └── src
│ ├── 01_api_tutorial # BPU SDK DNN API使用示例代码
│ │ ├── CMakeLists.txt
│ │ ├── mem
│ │ ├── model
│ │ ├── resize
│ │ ├── roi_infer
│ │ └── tensor
│ ├── 02_advanced_samples # 特殊功能示例
│ │ ├── CMakeLists.txt
│ │ ├── custom_identity
│ │ ├── multi_input
│ │ ├── multi_model_batch
│ │ └── nv12_batch
│ ├── 03_misc # 杂项示例
│ │ ├── CMakeLists.txt
│ │ ├── lenet_gray
│ │ └── resnet_feature
│ ├── CMakeLists.txt
│ ├── build_ultra.sh # aarch64编译脚本 RDK Ultra 使用
│ ├── build_xj3.sh # aarch64编译脚本 RDK X3 使用
│ └── deps_gcc9.3 # 编译依赖库
│ └── aarch64
├── ultra
│ ├── data # 预置数据文件
│ │ ├── cls_images
│ │ ├── custom_identity_data
│ │ ├── det_images
│ │ └── misc_data
│ ├── model
│ │ ├── README.md
| | └── runtime -> ../../../model_zoo/runtime/horizon_runtime_sample # 软链接指向OE包中的模型,板端运行环境需要自行指定模型路径
│ ├── script # aarch64示例运行脚本
│ │ ├── 00_quick_start
│ │ ├── 01_api_tutorial
│ │ ├── 02_advanced_samples
│ │ ├── 03_misc
│ │ └── README.md
│ └── script_x86 # x86示例运行脚本
│ ├── 00_quick_start
│ └── README.md
└── xj3
├── data # 预置数据文件
│ ├── cls_images
│ ├── custom_identity_data
│ ├── det_images
│ └── misc_data
├── model
│ ├── README.md
| └── runtime -> ../../../model_zoo/runtime/horizon_runtime_sample # 软链接指向OE包中的模型,板端运行环境需要自行指定模型路径
├── script # aarch64示例运行脚本
│ ├── 00_quick_start
│ ├── 01_api_tutorial
│ ├── 02_advanced_samples
│ ├── 03_misc
│ └── README.md
└── script_x86 # x86示例运行脚本
├── 00_quick_start
└── README.md
- 00_quick_start:快速入门示例,基于
dnnAPI,用mobilenetv1进行单张图片模型推理和结果解析。 - 01_api_tutorial:
dnnAPI使用教学代码, 包括 mem, model, resize, roi_infer 和 tensor 五部分。 - 02_advanced_samples:特殊功能示例,包括 custom_identity, multi_input, multi_model_batch 和 nv12_batch 功能。。
- 03_misc:非NV12输入模型的杂项示例。
- xj3:RDK X3开发板示例运行脚本,预置了数据和相关模型。
- ultra: RDK Ultra开发板示例运行脚本,预置了数据和相关模型。
- build_xj3.sh:RDK X3程序一键编译脚本。
- build_ultra.sh:RDK Ultra程序一键编译脚本。
- deps/deps_gcc9.3:示例代码所需要的三方依赖, 用户在开发自己代码程序的时候可以根据实际情况替换或者裁剪。
私有模型上板运行,请参考 00_quick_start/src/run_mobileNetV1_224x224.cc 示例代码流程进行代码重写,编译成功后可以在开发板上测试验证!
环境构建
开发板准备
-
拿到开发板后,请将开发版镜像更新到最新版本,升级方法请参考系统更新 章节内容。
-
确保本地开发机和开发板可以远程连接。
�编译
编译需要当前环境安装好交叉编译工具: aarch64-linux-gnu-g++ , aarch64-linux-gnu-gcc。 请使用D-Robotics 提供的开发机Docker镜像,直接进行编译使用。开发机Docker环境的获取及使用方法,请阅读环境安装 章节内容;
根据自身使用的开发板情况,请使用horizon_runtime_sample/code目录下的 build_xj3.sh 或 build_ultra.sh 脚本,即可一键编译开发板环境下的可执行程序,可执行程序和对应依赖会自动复制到 xj3/script 目录下的 aarch64 目录下 或 ultra/script 目录下的 aarch64 目录下。
工程通过获取环境变量 LINARO_GCC_ROOT 来指定交叉编译工具的路径,用户使用之前可以检查本地的环境变量是否为目标交叉编译工具。
如果需要指定交叉编译工具路径,可以设置环境变量 LINARO_GCC_ROOT , 或者直接修改脚本 build_xj3.sh 或 build_ultra.sh,指定变量 CC 和 CXX。
export CC=${GCC_ROOT}/bin/aarch64-linux-gnu-gcc
export CXX=${GCC_ROOT}/bin/aarch64-linux-gnu-g++
示例使用
basic_samples 示例
模型推理示例脚本主要在 xj3/script 和 xj3/script_x86 目录下,编译程序后目录结构如下:
# RDK X3 使用脚本信息
├─script
├── 00_quick_start
│ ├── README.md
│ └── run_mobilenetV1.sh
├── 01_api_tutorial
│ ├── model.sh
│ ├── README.md
│ ├── resize_bgr.sh
│ ├── resize_y.sh
│ ├── roi_infer.sh
│ ├── sys_mem.sh
│ └── tensor.sh
├── 02_advanced_samples
│ ├── custom_arm_op_custom_identity.sh
│ ├── README.md
│ └── run_multi_model_batch.sh
├── 03_misc
│ ├── README.md
│ ├── run_lenet.sh
│ └── run_resnet50_feature.sh
├── aarch64 # 编译产生可执行程序及依赖库
│ ├── bin
│ │ ├── model_example
│ │ ├── resize_bgr_example
│ │ ├── resize_y_example
│ │ ├── roi_infer
│ │ ├── run_custom_op
│ │ ├── run_lenet_gray
│ │ ├── run_mobileNetV1_224x224
│ │ ├── run_multi_model_batch
│ │ ├── run_resnet_feature
│ │ ├── sys_mem_example
│ │ └── tensor_example
│ └── lib
│ ├── libdnn.so
│ ├── libhbrt_bernoulli_aarch64.so
│ └── libopencv_world.so.3.4
└── README.md
# RDK Ultra 使用脚本信息
├─script
├── 00_quick_start
│ ├── README.md
│ └── run_mobilenetV1.sh
├── 01_api_tutorial
│ ├── model.sh
│ ├── README.md
│ ├── roi_infer.sh
│ ├── sys_mem.sh
│ └── tensor.sh
├── 02_advanced_samples
│ ├── plugin
│ │ └── custom_arm_op_custom_identity.sh
│ ├── README.md
│ ├── run_multi_input.sh
│ ├── run_multi_model_batch.sh
│ └── run_nv12_batch.sh
├── 03_misc
│ ├── README.md
│ ├── run_lenet.sh
│ └── run_resnet50_feature.sh
├── aarch64 # 编译产生可执行程序及依赖库
│ ├── bin
│ │ ├── model_example
│ │ ├── roi_infer
│ │ ├── run_custom_op
│ │ ├── run_lenet_gray
│ │ ├── run_mobileNetV1_224x224
│ │ ├── run_multi_input
│ │ ├── run_multi_model_batch
│ │ ├── run_nv12_batch
│ │ ├── run_resnet_feature
│ │ ├── sys_mem_example
│ │ └── tensor_example
│ └── lib
│ ├── libdnn.so
│ ├── libhbrt_bayes_aarch64.so
│ └── libopencv_world.so.3.4
└── README.md
- model文件夹下包含模型的路径,其中
runtime文件夹为软链接,链接路径为../../../model_zoo/runtime/horizon_runtime_sample,可直接找到交付包中的模型路径 - 板端运行环境需要将模型放至
model文件夹下
quick_start
00_quick_start 目录下的是模型推理的快速开始示例:
00_quick_start/
├── README.md
└── run_mobilenetV1.sh
run_mobilenetV1.sh:该脚本实现使用mobilenetv1模型读取单张图片进行推理的示例功能。
api_tutorial
01_api_tutorial 目录下的示例,用于介绍如何使用嵌入式API。其目录包含以下脚本:
├── model.sh
├── resize_bgr.sh
├── resize_y.sh
├── roi_infer.sh
├── sys_mem.sh
└── tensor.sh
model.sh:该脚本主要实现读取模型信息的功能。 使用的时候,直接进入 01_api_tutorial 目录,然后直接执行sh model.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
#!/bin/sh
/userdata/ruxin.song/xj3/script/01_api_tutorial# sh model.sh
../aarch64/bin/model_example --model_file_list=../../model/runtime/mobilenetv1/mobilenetv1_nv12_hybrid_horizonrt.bin
I0000 00:00:00.000000 24638 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[HBRT] set log level as 0. version = 3.12.1
[BPU_PLAT]BPU Platform Version(1.2.2)!
[HorizonRT] The model builder version = 1.3.3
I0108 04:19:27.245879 24638 model_example.cc:104] model count:1, model[0]: mobilenetv1_nv12
I0108 04:19:27.246064 24638 model_example.cc:112] hbDNNGetModelHandle [mobilenetv1_nv12] success!
I0108 04:19:27.246139 24638 model_example.cc:189] [mobilenetv1_nv12] Model Info: input num: 1, input[0] validShape: ( 1, 3, 224, 224 ), alignedShape: ( 1, 4, 224, 224 ), tensorLayout: 2, tensorType: 1, output num: 1, output[0] validShape: ( 1, 1000, 1, 1 ), alignedShape: ( 1, 1000, 1, 1 ), tensorLayout: 2, tensorType: 13
resize_bgr.sh:该脚本主要引导如何使用hbDNNResize这个API, 示例实现的代码功能是将一张1352x900大小的图片,截取图片中坐标为[5,19,340,343]的部分,然后resize到402x416并保存下来。 使用的时候,直接进入 01_api_tutorial 目录,然后直接执行sh resize_bgr.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
#!/bin/sh
/userdata/ruxin.song/xj3/script/01_api_tutorial# sh resize_bgr.sh
../aarch64/bin/resize_bgr_example --image_file=../../data/det_images/kite.jpg --resize_height=416 --resize_width=402 --resized_image=./resize_bgr.jpg --crop_x1=5 --crop_x2=340 --crop_y1=19 --crop_y2=343
I0000 00:00:00.000000 24975 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
I0108 06:58:03.327212 24975 resize_bgr_example.cc:116] Original shape: 1352x900 ,dest shape:402x416 ,aligned shape:402x416
[HBRT] set log level as 0. version = 3.12.1
[BPU_PLAT]BPU Platform Version(1.2.2)!
I0108 06:58:03.328739 24975 resize_bgr_example.cc:139] resize success!
I0108 06:58:03.335835 24975 resize_bgr_example.cc:143] wait task done finished!
执行成功后,当前目录会成功保存名称为resize_bgr.jpg的图片。
resize_y.sh:该脚本主要引导如何使用hbDNNResize这个API,示例代码实现的功能是将一张图片resize到416x402。 使用的时候,直接进入 01_api_tutorial 目录,然后直接执行sh resize_y.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
#!/bin/sh
/userdata/ruxin.song/xj3/script/01_api_tutorial# sh resize_y.sh
../aarch64/bin/resize_y_example --image_file=../../data/det_images/kite.jpg --resize_height=416 --resize_width=402 --resized_image=./resize_y.jpg
I0000 00:00:00.000000 24992 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
I0108 06:59:36.887241 24992 resize_y_example.cc:101] Original shape: 1352x900 ,dest shape:402x416 ,aligned shape:402x416
[HBRT] set log level as 0. version = 3.12.1
[BPU_PLAT]BPU Platform Version(1.2.2)!
I0108 06:59:36.888770 24992 resize_y_example.cc:119] resize success
I0108 06:59:36.891711 24992 resize_y_example.cc:123] wait resize success
I0108 06:59:36.891798 24992 resize_y_example.cc:129] spent time: 0.003463
执行成功后,当前目录会成功保存名称为resize_y.jpg的图片。
-
roi_infer.sh: 该脚本主要引导如何使用hbDNNRoiInfer这个API,示例代码实现的功能是将一张图片resize到模型输入大小,转为nv12数据,并给定roi框进行模型推理(infer)。 使用的时候,直接进入 01_api_tutorial 目录,然后直接执行sh roi_infer.sh即可。 -
sys_mem.sh:该脚本主要引导如何使用hbSysAllocMem、hbSysFlushMem和hbSysFreeMem这几个API。使用的时候,直接进入 01_api_tutorial 目录,执行sh sys_mem.sh即可。 -
tensor.sh:该脚本主要引导如何准备模型输入和输出的tensor。 使用的时候,直接进入 01_api_tutorial 目录,执行sh tensor.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
/userdata/ruxin.song/xj3/script/01_api_tutorial# sh tensor.sh
Tensor data type:0, Tensor layout: 2, shape:1x1x721x1836, aligned shape:1x1x721x1840
Tensor data type:1, Tensor layout: 2, shape:1x3x773x329, aligned shape:1x3x773x336
Tensor data type:2, Tensor layout: 2, shape:1x3x108x1297, aligned shape:1x3x108x1312
Tensor data type:5, Tensor layout: 2, shape:1x3x858x477, aligned shape:1x3x858x477
Tensor data type:5, Tensor layout: 0, shape:1x920x102x3, aligned shape:1x920x102x3
Tensor data type:4, Tensor layout: 2, shape:1x3x723x1486, aligned shape:1x3x723x1486
Tensor data type:4, Tensor layout: 0, shape:1x372x366x3, aligned shape:1x372x366x3
Tensor data type:3, Tensor layout: 2, shape:1x3x886x291, aligned shape:1x3x886x291
Tensor data type:3, Tensor layout: 0, shape:1x613x507x3, aligned shape:1x613x507x3
advanced_samples
02_advanced_samples 目录下的示例,用于介绍自定义算子特殊功能的使用。其目录包含以下脚本:
├── custom_arm_op_custom_identity.sh
└── run_multi_model_batch.sh
custom_arm_op_custom_identity.sh:该脚本主要实现自定义算子模型推理功能, 使用的时候,进入 02_advanced_samples 目录, 然后直接执行sh custom_arm_op_custom_identity.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
/userdata/ruxin.song/xj3/script/02_advanced_samples# sh custom_arm_op_custom_identity.sh
../aarch64/bin/run_custom_op --model_file=../../model/runtime/custom_op/custom_op_featuremap.bin --input_file=../../data/custom_identity_data/input0.bin,../../data/custom_identity_data/input1.bin
I0000 00:00:00.000000 30421 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
I0723 15:06:12.172068 30421 main.cpp:212] hbDNNRegisterLayerCreator success
I0723 15:06:12.172335 30421 main.cpp:217] hbDNNRegisterLayerCreator success
[BPU_PLAT]BPU Platform Version(1.3.1)!
[HBRT] set log level as 0. version = 3.15.3.0
[DNN] Runtime version = 1.15.2_(3.15.3 HBRT)
[A][DNN][packed_model.cpp:217](1563865572232) [HorizonRT] The model builder version = 1.13.5
I0723 15:06:12.240696 30421 main.cpp:232] hbDNNGetModelNameList success
I0723 15:06:12.240784 30421 main.cpp:239] hbDNNGetModelHandle success
I0723 15:06:12.240819 30421 main.cpp:245] hbDNNGetInputCount success
file length: 602112
file length: 602112
I0723 15:06:12.243616 30421 main.cpp:268] hbDNNGetOutputCount success
I0723 15:06:12.244102 30421 main.cpp:297] hbDNNInfer success
I0723 15:06:12.257903 30421 main.cpp:302] task done
I0723 15:06:14.277941 30421 main.cpp:306] write output tensor
模型的第一个输出数据保存至 ``output0.txt`` 文件。
run_multi_model_batch.sh:该脚本主要实现多个小模型批量推理功能, 使用的时候,进入 02_advanced_samples 目录, 然后直接执行sh run_multi_model_batch.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
root@x3sdbx3-hynix2G-3200:/userdata/chaoliang/xj3/script/02_advanced_samples# sh run_multi_model_batch.sh
../aarch64/bin/run_multi_model_batch --model_file=../../model/runtime/googlenet/googlenet_224x224_nv12.bin,../../model/runtime/mobilenetv2/mobilenetv2_224x224_nv12.bin --input_file=../../data/cls_images/zebra_cls.jpg,../../data/cls_images/zebra_cls.jpg
I0000 00:00:00.000000 17060 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[HBRT] set log level as 0. version = 3.13.4
[BPU_PLAT]BPU Platform Version(1.1.1)!
[HorizonRT] The model builder version = 1.3.18
[HorizonRT] The model builder version = 1.3.18
I0317 12:37:18.249785 17060 main.cpp:119] hbDNNInitializeFromFiles success
I0317 12:37:18.250029 17060 main.cpp:127] hbDNNGetModelNameList success
I0317 12:37:18.250071 17060 main.cpp:141] hbDNNGetModelHandle success
I0317 12:37:18.283633 17060 main.cpp:155] read image to nv12 success
I0317 12:37:18.284270 17060 main.cpp:172] prepare input tensor success
I0317 12:37:18.284456 17060 main.cpp:184] prepare output tensor success
I0317 12:37:18.285344 17060 main.cpp:218] infer success
I0317 12:37:18.296559 17060 main.cpp:223] task done
I0317 12:37:18.296701 17060 main.cpp:228] googlenet class result id: 340
I0317 12:37:18.296805 17060 main.cpp:232] mobilenetv2 class result id: 340
I0317 12:37:18.296887 17060 main.cpp:236] release task success
misc
03_misc 目录下的示例,用于介绍非nv12输入模型的使用。其目录包含以下脚本:
├── run_lenet.sh
└── run_resnet50_feature.sh
run_lenet.sh:该脚本主要实现Y数据输入的lenet模型推理功能, 使用的时候,进入 03_misc 目录, 然后直接执行sh run_lenet.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
/userdata/ruxin.song/xj3/script/03_misc# sh run_lenet.sh
../aarch64/bin/run_lenet_gray --model_file=../../model/runtime/lenet_gray/lenet_gray_hybrid_horizonrt.bin --data_file=../../data/misc_data/7.bin --image_height=28 --image_width=28 --top_k=5
I0000 00:00:00.000000 25139 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[HBRT] set log level as 0. version = 3.12.1
[BPU_PLAT]BPU Platform Version(1.2.2)!
[HorizonRT] The model builder version = 1.3.3
I0108 07:23:35.507514 25139 run_lenet_gray.cc:145] hbDNNInitializeFromFiles success
I0108 07:23:35.507737 25139 run_lenet_gray.cc:153] hbDNNGetModelNameList success
I0108 07:23:35.507771 25139 run_lenet_gray.cc:160] hbDNNGetModelHandle success
I0108 07:23:35.508070 25139 run_lenet_gray.cc:176] prepare y tensor success
I0108 07:23:35.508178 25139 run_lenet_gray.cc:189] prepare tensor success
I0108 07:23:35.509909 25139 run_lenet_gray.cc:200] infer success
I0108 07:23:35.510721 25139 run_lenet_gray.cc:205] task done
I0108 07:23:35.510790 25139 run_lenet_gray.cc:210] task post process finished
I0108 07:23:35.510832 25139 run_lenet_gray.cc:217] TOP 0 result id: 7
I0108 07:23:35.510857 25139 run_lenet_gray.cc:217] TOP 1 result id: 9
I0108 07:23:35.510879 25139 run_lenet_gray.cc:217] TOP 2 result id: 3
I0108 07:23:35.510903 25139 run_lenet_gray.cc:217] TOP 3 result id: 4
I0108 07:23:35.510927 25139 run_lenet_gray.cc:217] TOP 4 result id: 2
run_resnet50_feature.sh:该脚本主要实现feature数据输入的resnet50模型推理功能,示例代码对feature数据做了quantize和padding以满足模型的输入条件,然后输入到模型进行infer。 使用的时候,进入 03_misc 目录, 然后直接执行sh run_resnet50_feature.sh即可,如下所示:
以下示例日志都是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板日志信息会有所差异,以具体实测为准!
/userdata/ruxin.song/xj3/script/03_misc# sh run_resnet50_feature.sh
../aarch64/bin/run_resnet_feature --model_file=../../model/runtime/resnet50_feature/resnet50_feature_hybrid_horizonrt.bin --data_file=../../data/misc_data/np_0 --top_k=5
I0000 00:00:00.000000 25155 vlog_is_on.cc:197] RAW: Set VLOG level for "*" to 3
[HBRT] set log level as 0. version = 3.12.1
[BPU_PLAT]BPU Platform Version(1.2.2)!
[HorizonRT] The model builder version = 1.3.3
I0108 07:25:41.300466 25155 run_resnet_feature.cc:136] hbDNNInitializeFromFiles success
I0108 07:25:41.300708 25155 run_resnet_feature.cc:144] hbDNNGetModelNameList success
I0108 07:25:41.300741 25155 run_resnet_feature.cc:151] hbDNNGetModelHandle success
I0108 07:25:41.302760 25155 run_resnet_feature.cc:166] prepare feature tensor success
I0108 07:25:41.302919 25155 run_resnet_feature.cc:176] prepare tensor success
I0108 07:25:41.304678 25155 run_resnet_feature.cc:187] infer success
I0108 07:25:41.373052 25155 run_resnet_feature.cc:192] task done
I0108 07:25:41.373328 25155 run_resnet_feature.cc:197] task post process finished
I0108 07:25:41.373374 25155 run_resnet_feature.cc:204] TOP 0 result id: 74
I0108 07:25:41.373399 25155 run_resnet_feature.cc:204] TOP 1 result id: 815
I0108 07:25:41.373422 25155 run_resnet_feature.cc:204] TOP 2 result id: 73
I0108 07:25:41.373445 25155 run_resnet_feature.cc:204] TOP 3 result id: 78
I0108 07:25:41.373468 25155 run_resnet_feature.cc:204] TOP 4 result id: 72
辅助工具和常用操作
日志
本章节主要包括 示例日志 和 模型推理 DNN API日志 两部分。
其中示例日志是指交付包示例代码中的应用日志;模型推理 dnn API日志是指嵌入式dnn库中的日志。用户根据不同的需求可以获取不同的日志信息。
示例日志
示例日志主要采用glog中的vlog,basic_samples参考示例中,日志内容会全部输出。
模型推理 DNN API日志
关于模型推理 DNN API日志的配置,请阅读《算法工具链产品手册》。
公版模型性能精度测评说明
�评测方法说明
简介
本章节介绍公版模型精度性能评测 ai_benchmark 示例包的具体用法, 示例包中预置了源码、可执行程序和评测脚本,开发者可以直接在D-Robotics 开发板上体验并基于这些示例进行嵌入式应用开发,降低开发门槛。
示例包提供常见的分类、检测和分割模型的性能评测和精度评测示例,详细内容请阅读下文。
公版模型精度性能评测 ai_benchmark 示例包获取,请参考《交付物说明》。
示例代码包结构
ai_benchmark/code # 示例源码文件夹
├── build_ptq_xj3.sh # RDK X3 使用
├── build_ptq_ultra.sh # RDK Ultra 使用
├── CMakeLists.txt
├── deps/deps_gcc9.3 # 第三方依赖库,gcc9.3为deps_gcc9.3
│ ├── aarch64
│ └── vdsp
├── include # 源码头文件
│ ├── base
│ ├── input
│ ├── method
│ ├── output
│ ├── plugin
│ └── utils
├── README.md
└── src # 示例源码
├── input
├── method
├── output
├── plugin
├── simple_example.cc # 示例主程序
└── utils
ai_benchmark/xj3 # 示例包运行环境
└── ptq # PTQ方案模型示例
├── data # 模型精度评测数据集
├── mini_data # 模型性能评测数据集
│ ├── cifar10
│ ├── cityscapes
│ ├── coco
│ ├── culane
│ ├── flyingchairs
│ ├── imagenet
│ ├── kitti3d
│ ├── mot17
│ ├── nuscenes
│ ├── nuscenes_lidar
│ └── voc
├── model # PTQ方案nv12模型
│ ├── README.md
│ └── runtime -> ../../../../model_zoo/runtime/ai_benchmark/ptq # 软链接指向OE包中的模型,板端运行环境需要自行指定模型路径
├── README.md
├── script # 执行脚本
│ ├── aarch64 # 编译产生可执行文件及依赖库
│ ├── classification # 分类模型示例
│ │ ├── efficientnet_lite0
│ │ ├── efficientnet_lite1
│ │ ├── efficientnet_lite2
│ │ ├── efficientnet_lite3
│ │ ├── efficientnet_lite4
│ │ ├── googlenet
│ │ ├── mobilenetv1
│ │ ├── mobilenetv2
│ │ └── resnet18
│ ├── config # 模型推理配置文件
│ │ └── data_name_list
│ ├── detection # 检测模型示例
│ │ ├── centernet_resnet50
│ │ ├── efficientdetd0
│ │ ├── fcos_efficientnetb0
│ │ ├── preq_qat_fcos_efficientnetb0
│ │ ├── preq_qat_fcos_efficientnetb1
│ │ ├── preq_qat_fcos_efficientnetb2
│ │ ├── ssd_mobilenetv1
│ │ ├── yolov2_darknet19
│ │ ├── yolov3_darknet53
│ │ └── yolov5s
│ ├── segmentation # 分割模型示例
│ │ ├── deeplabv3plus_efficientnetb0
│ │ ├── fastscnn_efficientnetb0
│ │ └── unet_mobilenet
│ ├── base_config.sh # 基础配置
│ └── README.md
└── tools # 精度评测工具
├── python_tools
└── README.md
ai_benchmark/ultra # 示例包运行环境
└── ptq # PTQ方案模型示例
├── data # 模型精度评测数据集
├── mini_data # 模型性能评测数据集
│ ├── cifar10
│ ├── cityscapes
│ ├── coco
│ ├── culane
│ ├── flyingchairs
│ ├── imagenet
│ ├── kitti3d
│ ├── mot17
│ ├── nuscenes
│ ├── nuscenes_lidar
│ └── voc
├── model # PTQ方案nv12模型
│ │ ├── README.md
│ │ └── runtime -> ../../../../model_zoo/runtime/ai_benchmark/ptq # 软链接指向OE包中的模型,板端运行环境需要自行指定模型路径
├── README.md
├── script # 执行脚本
│ ├── aarch64 # 编译产生可执行文件及依赖库
│ ├── classification # 分类模型示例
│ │ ├── efficientnasnet_m
│ │ ├── efficientnasnet_s
│ │ ├── efficientnet_lite0
│ │ ├── efficientnet_lite1
│ │ ├── efficientnet_lite2
│ │ ├── efficientnet_lite3
│ │ ├── efficientnet_lite4
│ │ ├── googlenet
│ │ ├── mobilenetv1
│ │ ├── mobilenetv2
│ │ ├── resnet18
│ │ └── vargconvnet
│ ├── config # 模型推理配置文件
│ │ └── model
│ ├── detection # 检测模型示例
│ │ ├── centernet_resnet101
│ │ ├── preq_qat_fcos_efficientnetb0
│ │ ├── preq_qat_fcos_efficientnetb2
│ │ ├── preq_qat_fcos_efficientnetb3
│ │ ├── ssd_mobilenetv1
│ │ ├── yolov2_darknet19
│ │ ├── yolov3_darknet53
│ │ ├── yolov3_vargdarknet
│ │ └── yolov5x
│ ├── segmentation # 分割模型示例
│ │ ├── deeplabv3plus_efficientnetb0
│ │ ├── deeplabv3plus_efficientnetm1
│ │ ├── deeplabv3plus_efficientnetm2
│ │ └── fastscnn_efficientnetb0
│ ├── env.sh # 基础环境脚本
│ └── README.md
└── tools # 精度评测工具
├── python_tools
└── README.md
- code:该目录内是评测程序的源码,用来进行模型性能和精度评测。
- xj3: 提供了已经编译好的应用程序,以及各种评测脚本,用来测试多种模型在D-Robotics BPU上运行的性能,精度等(RDK X3 使用)。
- ultra: 提供了已经编译好的应用程序,以及各种评测脚本,用来测试多种模型在D-Robotics BPU上运行的性能,精度等(RDK Ultra 使用)。
- build_ptq_xj3.sh:开发板程序一键编译脚本(RDK X3 使用)。
- build_ptq_ultra.sh:开发板程序一键编译脚本(RDK Ultra 使用)。
- deps/deps_gcc9.3:示例代码所需要的依赖,主要如下所示:
gflags glog hobotlog nlohmann opencv rapidjson
示例模型
我们提供了开源的模型库,里面包含常用的分类、检测和分割�模型,模型的命名规则为:{model_name}_{backbone}_{input_size}_{input_type},开发者可以直接使用。
以下表格中的bin模型都是通过 horizon_model_convert_sample 模型转换示例包转换编译出来的,请阅读《交付物说明》 章节内容进行获取。
| MODEL | MODEL NAME |
|---|---|
| centernet_resnet101 | centernet_resnet101_512x512_nv12.bin |
| deeplabv3plus_efficientnetb0 | deeplabv3plus_efficientnetb0_1024x2048_nv12.bin |
| deeplabv3plus_efficientnetm1 | deeplabv3plus_efficientnetm1_1024x2048_nv12.bin |
| efficientnasnet_m | efficientnasnet_m_300x300_nv12.bin |
| efficientnet_lite4 | efficientnet_lite4_300x300_nv12.bin |
| fastscnn_efficientnetb0 | fastscnn_efficientnetb0_1024x2048_nv12.bin |
| googlenet | googlenet_224x224_nv12.bin |
| mobilenetv1 | mobilenetv1_224x224_nv12.bin |
| mobilenetv2 | mobilenetv2_224x224_nv12.bin |
| preq_qat_fcos_efficientnetb0 | fcos_efficientnetb0_512x512_nv12.bin |
| preq_qat_fcos_efficientnetb2 | fcos_efficientnetb2_768x768_nv12.bin |
| resnet18 | resnet18_224x224_nv12.bin |
| ssd_mobilenetv1 | ssd_mobilenetv1_300x300_nv12.bin |
| vargconvnet | vargconvnet_224x224_nv12.bin |
| yolov3_darknet53 | yolov3_darknet53_416x416_nv12.bin |
| yolov5s | yolov5s_672x672_nv12.bin |
| yolov5x | yolov5x_672x672_nv12.bin |
公共数据集
测评示例中用到的数据集主要有VOC数据集、COCO数据集、ImageNet、Cityscapes数据集、FlyingChairs数据集、KITTI数据集、Culane数据集、Nuscenes数据集和Mot17数据集。
请在linux环境下进行下载,获取方式如下:
VOC:http://host.robots.ox.ac.uk/pascal/VOC/ (使用VOC2012版本)
COCO:https://cocodataset.org/#download
ImageNet:https://www.image-net.org/download.php
Cityscapes:https://github.com/mcordts/cityscapesScripts
FlyingChairs:https://lmb.informatik.uni-freiburg.de/resources/datasets/FlyingChairs.en.html
KITTI3D:https://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
CULane:https://xingangpan.github.io/projects/CULane.html
nuScenes:https://www.nuscenes.org/nuscenes#download
mot17:https://opendatalab.com/MOT17
环境构建
开发板准备
-
拿到开发板后,请将开发版镜像更新到最新版本,升级方法请参考安装系统 章节内容。
-
确保本地开发机和开发板可以远程连接。
编译环境准备
编译需要当前环境安装好交叉编译工具 gcc-ubuntu-9.3.0-2020.03-x86_64-aarch64-linux-gnu。请使用D-Robotics 提供的开发机Docker镜像,直接进行编译使用。开发机Docker环境的获取及使用方法,请阅读环境安装 章节内容;
请使用code目录下的 build_ptq_xj3.sh 或 build_ptq_ultra.sh 脚本,即可一键编译开发板环境下的可执行程序,可执行程序和对应依赖会自动复制到 xj3/ptq/script 目录下的 aarch64 目录下 或 ultra/ptq/script 目录下的 aarch64 目录下。
需要注意 build_ptq_xj3.sh 和 build_ptq_ultra.sh 脚本里指定的交叉编译工具链的位置是 /opt 目录下,用户如果安装在其他位置,可以手动修改下脚本。
export CC=/opt/gcc-ubuntu-9.3.0-2020.03-x86_64-aarch64-linux-gnu/bin/aarch64-linux-gnu-gcc
export CXX=/opt/gcc-ubuntu-9.3.0-2020.03-x86_64-aarch64-linux-gnu/bin/aarch64-linux-gnu-g++
测评示例使用说明
评测示例脚本主要在 script 和 tools 目录下。 script是开发板上运行的评测脚本,包括常见分类,检测和分割模型。每个模型下面有三个脚本,分别表示:
- fps.sh:利用多线程调度实现fps统计,用户可以根据需求自由设置线程数。
- latency.sh:实现单帧延迟统计(一个线程,单帧)。
- accuracy.sh:用于精度评测。
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
script:
├── aarch64 # 编译产生的可执行文件及依赖库
│ ├── bin
│ └── lib
├── base_config.sh # 基础配置
├── config # image_name配置文件
│ ├── data_name_list
| | ├── coco_detlist.list
│ | ├── imagenet.list
│ | └── voc_detlist.list
├── classification # 分类模型评测
│ ├── efficientnet_lite0
│ │ ├── accuracy.sh
│ │ ├── fps.sh
│ │ ├── latency.sh
│ │ ├── workflow_accuracy.json
│ │ ├── workflow_fps.json
│ │ └── workflow_latency.json
│ ├── mobilenetv1
│ ├── .....
│ └── resnet18
├── detection # 检测模型
| ├── centernet_resnet50
│ │ ├── accuracy.sh
│ │ ├── fps.sh
│ │ ├── latency.sh
│ │ ├── workflow_accuracy.json
│ │ ├── workflow_fps.json
│ │ └── workflow_latency.json
│ ├── yolov2_darknet19
│ ├── yolov3_darknet53
│ ├── ...
│ └── efficientdetd0
└── segmentation # 分割模型
├── deeplabv3plus_efficientnetb0
│ ├── accuracy.sh
│ ├── fps.sh
│ ├── latency.sh
│ ├── workflow_accuracy.json
│ ├── workflow_fps.json
│ └── workflow_latency.json
├── fastscnn_efficientnetb0
└── unet_mobilenet
tools目录下是精度评测需要的脚本。主要包括 python_tools 下的精度计算脚本。
tools:
python_tools
└── accuracy_tools
├── cityscapes_metric.py
├── cls_eval.py
├── coco_metric.py
├── coco_det_eval.py
├── config.py
├── parsing_eval.py
├── voc_det_eval.py
└── voc_metric.py
评测前需要执行以下命令,将 ptq 目录拷贝到开发板上,然后将 model_zoo/runtime 拷贝到 ptq/model 目录下。
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
scp -r ai_toolchain_package/Ai_Toolchain_Package-release-vX.X.X-OE-vX.X.X/ai_benchmark/xj3/ptq root@192.168.1.10:/userdata/ptq/
scp -r model_zoo/runtime root@192.168.1.10:/userdata/ptq/model/
性能评测
性能评测分为latency和fps两方面。
- 测评脚本使用说明
进入到需要评测的模型目录下,执行 sh latency.sh 即可测试出单帧延迟。如下图所示:
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
I0419 02:35:07.041095 39124 output_plugin.cc:80] Infer latency: [avg: 13.124ms, max: 13.946ms, min: 13.048ms], Post process latency: [avg: 3.584ms, max: 3.650ms, min: 3.498ms].
infer表示模型推理耗时。Post process表示后处理耗时。
进入到需要评测的模型目录下执行 sh fps.sh 即可测试出帧率。如下图所示:
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
I0419 02:35:00.044417 39094 output_plugin.cc:109] Throughput: 176.39fps # 模型帧率
该功能采用多线程并发方式,旨在让模型可以在BPU上达到极致的性能。由于多线程并发及数据采样的原因,在程序启动阶段帧率值会较低,之后帧率会上升并逐渐趋于稳定,帧率的浮动范围控制在0.5%之内。
- 命令行参数说明
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
fps.sh 脚本内容如下:
#!/bin/sh
source ../../base_config.sh
export SHOW_FPS_LOG=1
export STAT_CYCLE=10 # 设置环境变量,FPS 统计周期
${app} \
--config_file=workflow_fps.json \
--log_level=1
latency.sh 脚本内容如下:
#!/bin/sh
source ../../base_config.sh
export SHOW_LATENCY_LOG=1 # 设置环境�变量,打印 LATENCY 级别log
export STAT_CYCLE=5 # 设置环境变量,LATENCY 统计周期
${app} \
--config_file=workflow_latency.json \
--log_level=1
- 配置文件说明
注意:max_cache参数生效时会预处理图片并读取到内存中,为保障您的程序稳定运行,请不要设置过大的值,建议您的数值设置不超过30。
以fcos_efficientnetb0模型为例,workflow_fps.json 配置文件内容如下:
{
"input_config": {
"input_type": "image", # 输入数据格式,支持图像或者bin文件
"height": 512, # 输入数据高度
"width": 512, # 输入数据宽度
"data_type": 1, # 输入数据类型:HB_DNN_IMG_TYPE_NV12
"image_list_file": "../../../mini_data/coco/coco.lst", # 预处理数据集lst文件所在路径
"need_pre_load": true, # 是否使用预加载方式读取数据集
"limit": 10,
"need_loop": true, # 是否循环读取数据进行评测
"max_cache": 10
},
"output_config": {
"output_type": "image", # 可视化输出数据类型
"image_list_enable": true,
"in_order": false # 是否按顺序输出
},
"workflow": [
{
"method_type": "InferMethod", # Infer推理方式
"unique_name": "InferMethod",
"method_config": {
"core": 0, # 推理core id
"model_file": "../../../model/runtime/fcos_efficientnetb0/fcos_efficientnetb0_512x512_nv12.bin" # 模型文件
}
},
{
"thread_count": 4, # 后处理线程数
"method_type": "PTQFcosPostProcessMethod", # 后处理方法
"unique_name": "PTQFcosPostProcessMethod",
"method_config": { # 后处理参数
"strides": [
8,
16,
32,
64,
128
],
"class_num": 80,
"score_threshold": 0.5,
"topk": 1000,
"det_name_list": "../../config/data_name_list/coco_detlist.list"
}
}
]
}
workflow_latency.json 如下:
{
"input_config": {
"input_type": "image",
"height": 512,
"width": 512,
"data_type": 1,
"image_list_file": "../../../mini_data/coco/coco.lst",
"need_pre_load": true,
"limit": 1,
"need_loop": true,
"max_cache": 10
},
"output_config": {
"output_type": "image",
"image_list_enable": true
},
"workflow": [
{
"method_type": "InferMethod",
"unique_name": "InferMethod",
"method_config": {
"core": 0,
"model_file": "../../../model/runtime/fcos_efficientnetb0/fcos_efficientnetb0_512x512_nv12.bin"
}
},
{
"thread_count": 1,
"method_type": "PTQFcosPostProcessMethod",
"unique_name": "PTQFcosPostProcessMethod",
"method_config": {
"strides": [
8,
16,
32,
64,
128
],
"class_num": 80,
"score_threshold": 0.5,
"topk": 1000,
"det_name_list": "../../config/data_name_list/coco_detlist.list"
}
}
]
}
精度评测
模型精度评测分为四步:
- 数据预处理。
- 数据挂载。
- 模型推理。
- 精度计算。
-
数据预处理
对于PTQ模型:数据预处理需要在x86开发机环境下运行 hb_eval_preprocess 工具,对数据集进行预处理。
所谓预处理是指图片数据在送入模型之前的特定处理操作,例如:图片resize、crop和padding等。
该工具集成于开发机模型转换编译的环境中,原始数据集经过工具预处理之后,会生成模型对应的前处理二进制文件.bin文件集.
直接运行 hb_eval_preprocess --help 可查看工具使用规则。
- 关于
hb_eval_preprocess工具命令行参数,可键入hb_eval_preprocess -h, 或查看 PTQ量化原理及步骤说明的 hb_eval_preprocess工具 一节内容。
下面将详细介绍示例包中每一个模型对应的数据集,以及对应数据集的预处理操作:
VOC数据集:该数据集主要用于ssd_mobilenetv1模型的评测, 其目录结构如下,示例中主要用到Main文件下的val.txt文件,JPEGImages中的源图片和Annotations中的标注数据:
.
└── VOCdevkit # 根目录
└── VOC2012 # 不同年份的数据集,这里只下载了2012的,还有2007等其它年份的
├── Annotations # 存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等
├── ImageSets # 该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本
�│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages # 存放源图片
├── SegmentationClass # 存放的是图片,语义分割相关
└── SegmentationObject # 存放的是图片,实例分割相关
对数据集进行预处理:
hb_eval_preprocess -m ssd_mobilenetv1 -i VOCdevkit/VOC2012/JPEGImages -v VOCdevkit/VOC2012/ImageSets/Main/val.txt -o ./pre_ssd_mobilenetv1
COCO数据集:该数据集主要用于yolov2_darknet19、yolov3_darknet53、yolov5s、efficientdetd0、fcos_efficientnetb0和centernet_resnet50等检测模型的评测, 其目录如下,示例中主要用到annotations文件夹下的instances_val2017.json标注文件和images中的图片:
.
├── annotations # 存放标注数据
└── images # 存放源图片
对数据集进行预处理:
hb_eval_preprocess -m model_name -i coco/coco_val2017/images -o ./pre_model_name
ImageNet数据集:该数据集主要用于EfficientNet_lite0、EfficientNet_Lite1、EfficientNet_Lite2、EfficientNet_Lite3、EfficientNet_Lite4、MobileNet、GoogleNet、ResNet等分类模型的评测, 示例中主要用到了标注文件val.txt 和val目录中的源图片:
.
├── val.txt
└── val
对数据集进行预处理:
hb_eval_preprocess -m model_name -i imagenet/val -o ./pre_model_name
Cityscapes数据集:该数据集用于deeplabv3plus_efficientnetb0、deeplabv3plus_efficientnetm1、deeplabv3plus_efficientnetm2和fastscnn_efficientnetb0等分割模型的评测。 示例中主要用到了./gtFine/val中的标注文件和./leftImg8bit/val中的源图片。
.
├── gtFine
│ └── val
│ ├── frankfurt
│ ├── lindau
│ └── munster
└── leftImg8bit
└── val
├── frankfurt
├── lindau
└── munster
对数据集进行预处理:
hb_eval_preprocess -m unet_mobilenet -i cityscapes/leftImg8bit/val -o ./pre_unet_mobilenet
示例中精度计算脚本的运行流程是:
1、根据 workflow_accurary.json 中的 image_list_file 参数值,去寻找对应数据集的 lst 文件;
2、根据 lst 文件存储的前处理文件路径信息,去加载每一个前处理文件,然后进行推理
所以,生成预处理文件之后,需要生成对应的lst文件,将每一张前处理文件的路径写入到lst文件中,而这个路径与数据集在开发板端的存放位置有关。
这里我们推荐其存放位置与 script 文件夹同级目录,如下:
# RDK X3 使用如下格式:
|-- ptq
| |-- data
| | |-- cityscapes
| | | -- xxxx.bin # 前处理好的二进制文件
| | | -- ....
| | | -- cityscapes.lst # lst文件:记录每一个前处理文件的路径
| | |-- coco
| | | -- xxxx.bin
| | | -- ....
| | | -- coco.lst
| | |-- imagenet
| | | -- xxxx.bin
| | | -- ....
| | | -- imagenet.lst
| | `-- voc
| | | -- xxxx.bin
| | | -- ....
| | `-- voc.lst
| |-- model
| | |-- ...
| |-- script
| | |-- ...
# RDK Ultra 使用如下格式:
|-- ptq
| |-- data
| | |-- cityscapes
| | | |-- pre_deeplabv3plus_efficientnetb0
| | | | |-- xxxx.bin # 前处理好的二进制文件
| | | | |-- ....
| | | |-- pre_deeplabv3plus_efficientnetb0.lst # lst文件:记录每一个��前处理文件的路径
| | | |-- pre_deeplabv3plus_efficientnetm1
| | | |-- pre_deeplabv3plus_efficientnetm1.lst
| | | |-- pre_deeplabv3plus_efficientnetm2
| | | |-- pre_deeplabv3plus_efficientnetm2.lst
| | | |-- pre_fastscnn_efficientnetb0
| | | |-- pre_fastscnn_efficientnetb0.lst
| | |-- coco
| | | |-- pre_centernet_resnet101
| | | | |-- xxxx.bin
| | | | |-- ....
| | | |-- pre_centernet_resnet101.lst
| | | |-- pre_yolov3_darknet53
| | | |-- pre_yolov3_darknet53.lst
| | | |-- pre_yolov3_vargdarknet
| | | |-- pre_yolov3_vargdarknet.lst
| | | |-- pre_yolov5x
| | | |-- pre_yolov5x.lst
| | | |-- pre_preq_qat_fcos_efficientnetb0
| | | |-- pre_preq_qat_fcos_efficientnetb0.lst
| | | |-- pre_preq_qat_fcos_efficientnetb2
| | | |-- pre_preq_qat_fcos_efficientnetb2.lst
| | | |-- pre_preq_qat_fcos_efficientnetb3
| | | |-- pre_preq_qat_fcos_efficientnetb3.lst
| | |-- imagenet
| | | |-- pre_efficientnasnet_m
| | | | |-- xxxx.bin
| | | | |-- ....
| | | |-- pre_efficientnasnet_m.lst
| | | |-- pre_efficientnasnet_s
| | | |-- pre_efficientnasnet_s.lst
| | | |-- pre_efficientnet_lite4
| | | |-- pre_efficientnet_lite4.lst
| | | |-- pre_googlenet
| | | |-- pre_googlenet.lst
| | | |-- pre_mobilenetv1
| | | |-- pre_mobilenetv1.lst
| | | |-- pre_mobilenetv2
| | | |-- pre_mobilenetv2.lst
| | | |-- pre_resnet18
| | | |-- pre_resnet18.lst
| | | |-- pre_vargconvnet
| | | |-- pre_vargconvnet.lst
| | |-- voc
| | | |-- pre_ssd_mobilenetv1
| | | | |-- xxxx.bin
| | | | |-- ....
| | | |-- pre_ssd_mobilenetv1.lst
| |-- model
| | |-- ...
| |-- script
| | |-- ...
与之对应的lst文件,参考生成方式如下:
# RDK X3 请使用如下命令:
find ../../../data/coco/fcos -name "*bin*" > ../../../data/coco/coco.lst
# RDK Ultra 请使用如下命令:
find ../../../data/coco/pre_centernet_resnet101 -name "*bin*" > ../../../data/coco/pre_centernet_resnet101.lst
这样生成的lst文件中存储的路径为一个相对路径: ../../../data/ 或 ../../../data/coco/pre_centernet_resnet101/ ,可以与 workflow_accuracy.json 默认的配置路径吻合。
如果需要更改前处理数据集的存放位置,则需要确保对应的 lst 文件可以被 workflow_accuracy.json 读取到;其次需要确保程序根据 lst 中的路径信息,能读取到对应的前处理文件。
-
数据挂载
由于数据集相对较大,不适合直接放在开发板上,可以采用nfs挂载的方式供开发板读取。
开发机PC端(需要root权限):
- 编辑 /etc/exports, 增加一行:
/nfs *(insecure,rw,sync,all_squash,anonuid=1000,anongid=1000,no_subtree_check)。/nfs表示本机挂载路径,可替换为用户指定目录 - 执行命令
exportfs -a -r,使/etc/exports 生效。
开发板端:
- 创建需要挂载的目录:
mkdir -p /mnt。 mount -t nfs {PC端IP}:/nfs /mnt -o nolock。
完成将PC端的/nfs文件夹挂载至板端/mnt文件夹。按照此方式,将包含预处理数据的文件夹挂载至板端,并将/data目录软链接至板端/ptq目录下,与/script同级目录。
-
模型推理
以下示例是使用 RDK X3 开发板的实测结果,若使用 RDK Ultra 开发板信息会有所差异,以具体实测为准!
挂载完数据后,请登录开发板,开发板登录方法,请阅读开发板登录 章节内容,登录成功后,执行 fcos_efficientnetb0/ 目录下的accuracy.sh脚本,如下所示:
/userdata/ptq/script/detection/fcos# sh accuracy.sh
../../aarch64/bin/example --config_file=workflow_accuracy.json --log_level=2
...
I0419 03:14:51.158655 39555 infer_method.cc:107] Predict DoProcess finished.
I0419 03:14:51.187361 39556 ptq_fcos_post_process_method.cc:123] PTQFcosPostProcessMethod DoProcess finished, predict result: [{"bbox":[-1.518860,71.691170,574.934631,638.294922],"prob":0.750647,"label":21,"class_name":"
I0118 14:02:43.636204 24782 ptq_fcos_post_process_method.cc:123] PTQFcosPostProcessMethod DoProcess finished, predict result: [{"bbox":[3.432283,164.936249,157.480042,264.276825],"prob":0.544454,"label":62,"class_name":"
...
开发板端程序会在当前目录生成 eval.log 文件,该文件就是预测结果文件。
-
精度计算
精度计算部分请在 开发机 模型转换的环境下操作
精度计算的脚本在 python_tools 目录下,其中 accuracy_tools 中的:
cls_eval.py是用来计算分类模型的精度;
coco_det_eval.py是用来计算使用COCO数据集评测的检测模型的精度;
parsing_eval.py是用来计算使用Cityscapes数据集评测的分割模型的精度。
voc_det_eval.py是用来计算使用VOC数据集评测的检测模型的精度。
- 分类模型
使用CIFAR-10数据集和ImageNet数据集的分类模型计算方式如下:
#!/bin/sh
python3 cls_eval.py --log_file=eval.log --gt_file=val.txt
log_file:分类模型的预测结果文件。gt_file:CIFAR-10和ImageNet数据集的标注文件。
- 检测模型
使用COCO数据集的检测模型精度计算方式如下:
#!/bin/sh
python3 coco_det_eval.py --eval_result_path=eval.log --annotation_path=instances_val2017.json
eval_result_path:检测模型的预测结果文件。annotation_path:COCO数据集的标注文件。
使用VOC数据集的检测模型精度计算方式如下:
#!/bin/sh
python3 voc_det_eval.py --eval_result_path=eval.log --annotation_path=../Annotations --val_txt_path=../val.txt
eval_result_path:检测模型的预测结果文件。annotation_path:VOC数据集的标注文件。val_txt_path:VOC数据集中ImageSets/Main文件夹下的val.txt文件。
- 分割模型
使用Cityscapes数据集的分割模型精度计算方式如下:
:linenos:
#!/bin/sh
python3 parsing_eval.py --width=output_width --height=output_height --log_file=eval.log --gt_path=cityscapes/gtFine/val
width: 分割模型的输出宽度height: 分割模型的输出高度log_file:分割模型的预测结果文件。gt_path:Cityscapes数据集的标注文件。
模型集成
模型后处理集成主要有2个步骤,以centernet_resnet50模型集成为例:
- 增加后处理文件
ptq_centernet_post_process_method.cc,以及头文件ptq_centernet_post_process_method.h。 - 增加模型运行脚本及配置文件。
后处理文件添加
以下示例是使用 RDK X3 开发板举例,若使用 RDK Ultra 开发板信息会有所差异,以具体为准!
后处理代码文件可直接复用src/method目录下任意后处理文件,主要修改 InitFromJsonString 函数,以及 PostProcess 函数即可。
InitFromJsonString 函数主要是读取workflow.json中的后处理相关的参数配置,用户可自定义设置相应的输入参数。
PostProcess 函数主要完成后处理的逻辑。
后处理.cc文件放置于 ai_benchmark/code/src/method/ 路径下,
.h头文件放置于 ai_benchmark/code/include/method/ 路径下:
|--ai_benchmark
| |--code # 示例源码
| | |--include
| | | |--method # 在此文件夹中添加头文件
| | | | |--ptq_centernet_post_process_method.h
| | | | |--......
| | | | |--ptq_yolo5_post_process_method.h
| | |--src
| | | |--method # 在此文件夹中添加后处理.cc文件
| | | | |--ptq_centernet_post_process_method.cc
| | | | |--......
| | | | |--ptq_yolo5_post_process_method.cc
增加模型运行脚本及配置文件
脚本目录结构如下:
|--ai_benchmark
| |--xj3/ptq/script # 示例脚本文件夹
| | |--detection
| | | |--centernet_resnet50
| | | | |--accuracy.sh # 精度测试脚本
| | | | |--fps.sh # 性能测试脚本
| | | | |--latency.sh # 单帧延时示例脚本
| | | | |--workflow_accuracy.json # 精度配置文件
| | | | |--workflow_fps.json # 性能配置文件
| | | | |--workflow_latency.json # 单帧延时配置文件
辅助工具和常用操作
日志系统使用说明
日志系统主要包括 示例日志 和 模型推理API DNN日志 两部分。
其中示例日志是指交付包示例代码中的应用日志;DNN日志是指lib dnn库中的日志。
用户根据不同的需求可以获取不同的日志。
- 示例日志
- 日志等级。示例日志主要采用glog中的vlog,主要分为四个自定义等级:
0(SYSTEM),该等级主要用来输出报错信息;1(REPORT),该等级在示例代码中主要用来输出性能数据;2(DETAIL),该等级在示例代码中主要用来输出系统当前状态信息;3(DEBUG),该等级在示例代码中主要用来输出调试信息。 日志等级设置规则:假设设置了级别为P,如果发生了一个级别Q比P低, 则可以启动,否则屏蔽掉;默认DEBUG>DETAIL>REPORT>SYSTEM。
- 日志等级设置。通过
log_level参数来设置日志等级,在运行示例的时候,指定log_level参数来设置等�级, 比如指定log_level=0,即输出SYSTEM日志;如果指定log_level=3, 则输出DEBUG、DETAIL、REPORT和SYSTEM日志。
- 模型推理API DNN日志
关于模型推理 DNN API日志的配置,请阅读《算法工具链产品手册》。
算子耗时说明
对模型算子(OP)性能的统计是通过设置 HB_DNN_PROFILER_LOG_PATH 环境变量实现的,本节介绍模型的推理性能分析,有助于开发者了解模型的真实推理性能情况。
对该变量的类型和取值说明如下:
export HB_DNN_PROFILER_LOG_PATH=${path}:表示OP节点dump的输出路径,程序正常运行完退出后,产生profiler.log文件。
- 示例说明
以下示例是使用 RDK X3 开发板举例,若使用 RDK Ultra 开发板信息会有所差异,以具体为准!
以下代码块以mobilenetv1模型为例,开启单个线程同时RunModel,设置 export HB_DNN_PROFILER_LOG_PATH=./,则统计输出的信息如下:
{
"perf_result": {
"FPS": 677.6192525182025,
"average_latency": 11.506142616271973
},
"running_condition": {
"core_id": 0,
"frame_count": 200,
"model_name": "mobilenetv1_224x224_nv12",
"run_time": 295.151,
"thread_num": 1
}
}
***
{
"chip_latency": {
"BPU_inference_time_cost": {
"avg_time": 11.09122,
"max_time": 11.54,
"min_time": 3.439
},
"CPU_inference_time_cost": {
"avg_time": 0.18836999999999998,
"max_time": 0.4630000000000001,
"min_time": 0.127
}
},
"model_latency": {
"BPU_MOBILENET_subgraph_0": {
"avg_time": 11.09122,
"max_time": 11.54,
"min_time": 3.439
},
"Dequantize_fc7_1_HzDequantize": {
"avg_time": 0.07884999999999999,
"max_time": 0.158,
"min_time": 0.068
},
"MOBILENET_subgraph_0_output_layout_convert": {
"avg_time": 0.018765,
"max_time": 0.08,
"min_time": 0.01
},
"Preprocess": {
"avg_time": 0.0065,
"max_time": 0.058,
"min_time": 0.003
},
"Softmax_prob": {
"avg_time": 0.084255,
"max_time": 0.167,
"min_time": 0.046
}
},
"task_latency": {
"TaskPendingTime": {
"avg_time": 0.029375,
"max_time": 0.059,
"min_time": 0.009
},
"TaskRunningTime": {
"avg_time": 11.40324,
"max_time": 11.801,
"min_time": 4.008
}
}
}
以上输出了 model_latency 和 task_latency。其中model_latency中输出了模型每个OP运行所需要的耗时情况,task_latency中输出了模型运行中各个task模块的耗时情况。
程序只有正常退出才会输出profiler.log文件。
dump工具
本节主要介绍dump工具的开启方法,一般不需要关注,只有在模型精度异常情况时开启使用。
通过设置 export HB_DNN_DUMP_PATH=${path} 这个环境变量,可以dump出模型推理过程中每个节点的输入和输出, 根据dump的输出结果,可以排查模型推理在开发机模拟器和开发板是否存在一致性问题:即相同模型,相同输入,开发板和开发机模拟器的输出结果是否完全相同。
模型上板分析工具说明
概述
本章节介绍D-Robotics 算法工具链中模型上板推理的快速验证工具,方便开发者可以快速获取到 ***.bin 模型的信息、模型推理的性能、模型debug等内容。
hrt_model_exec 工具使用说明
hrt_model_exec 工具,可以快速在开发板上评测模型的推理性能、获取模型信息等。
目前工具提供了三类功能,如下表所示:
| 编号 | 子命令 | 说明 |
|---|---|---|
| 1 | model_info | 获取模型信息,如:模型的输入输出信息等。 |
| 2 | infer | 执行模型推理,获取模型推理结果。 |
| 3 | perf | 执行模型性能分析,获取性能分析结果。 |
工具也可以通过 -v 或者 --version 命令,查看工具的 dnn 预测库版本号。
例如: hrt_model_exec -v 或 hrt_model_exec --version
输入参数描述
在开发板上运行 hrt_model_exec 、 hrt_model_exec -h 或 hrt_model_exec --help 获取工具的使用参数详情。
如下图中所示:
| 编号 | 参数 | 类型 | 说明 |
|---|---|---|---|
| 1 | model_file | string | 模型文件路径,多个路径可通过逗号分隔。 |
| 2 | model_name | string | 指定模型中某个模型的名称。 |
| 3 | core_id | int | 指定运行核。 |
| 4 | input_file | string | 模型输入信息,多个可通过逗号分隔。 |
| 5 | roi_infer | bool | 使能resizer模型推理。 |
| 6 | roi | string | 指定推理resizer模型时所需的roi区域。 |
| 7 | frame_count | int | 执行模型运行帧数。 |
| 8 | dump_intermediate | string | dump模型每一层输入和输出。 |
| 9 | enable_dump | bool | 使能dump模型输入和输出。 |
| 10 | dump_precision | int | 控制txt格式输出float型数据的小数点位数。 |
| 11 | hybrid_dequantize_process | bool | 控制txt格式输出float类型数据。 |
| 12 | dump_format | string | dump模型输入和输出的格式。 |
| 13 | dump_txt_axis | int | 控制txt格式输入输出的换行规则。 |
| 14 | enable_cls_post_process | bool | 使能分类后处理。 |
| 15 | perf_time | int | 执行模型运行时间。 |
| 16 | thread_num | int | 指定程序运行线程数。 |
| 17 | profile_path | string | 模型性能/调度性能统计数据的保存路径。 |
使用说明
本节介绍 hrt_model_exec 工具的三个子功能的具体使用方法
model_info
- 概述
该参数用于获取模型信息,模型支持范围:QAT模型,PTQ模型。
该参数与 model_file 一起使用,用于获取模型的详细信息;
模型的信息包括:模型输入输出信息 hbDNNTensorProperties 和模型的分段信息 stage ;模型的分段信息是:一张图片可以分多个阶段进行推理,stage信息为[x1, y1, x2, y2],分别为图片推理的左上角和右下角坐标,目前D-Robotics RDK Ultra的bayes架构支持这类分段模型的推理,RDK X3上模型均为1个stage。
不指定 model_name ,则会输出模型中所有模型信息,指定 model_name ,则只输出对应模型的信息。
- 示例说明
- 单模型
hrt_model_exec model_info --model_file=xxx.bin
- 多模型(输出所有模型信息)
hrt_model_exec model_info --model_file=xxx.bin,xxx.bin
- 多模型--pack模型(输出指定模型信息)
hrt_model_exec model_info --model_file=xxx.bin --model_name=xx
输入参数补充说明
- 重复输入
若重复指定参数输入,则会发生参数覆盖的情况,例如:获取模型信息时重复指定了两个模型文件,则会取后面指定的参数输入 yyy.bin:
hrt_model_exec model_info --model_file=xxx.bin --model_file=yyy.bin
若重复指定输入时,未加命令行参--model_file,则会取命令行参数后面的值,未加参数的不识别,
例如:下例会忽略 yyy.bin,参数值为 xxx.bin:
hrt_model_exec model_info --model_file=xxx.bin yyy.bin
infer
- 概述
该参数用于输入自定义图片后,模型推理一帧,并给出模型推理结果。
该参数需要与 input_file 一起使用,指定输入图片路径,工具根据模型信息resize图片,整理模型输入信息。
程序单线程运行单帧数据,输出模型运行的时间。
- 示例说明
- 单模型
hrt_model_exec infer --model_file=xxx.bin --input_file=xxx.jpg
- 多模型
hrt_model_exec infer --model_file=xxx.bin,xxx.bin --model_name=xx --input_file=xxx.jpg
-
可选参数
参数 说明 core_id指定模型推理的核id,0:任意核,1:core0,2:core1;默认为 0。roi_infer使能resizer模型推理;若模型输入包含resizer源,设置为 true,默认为false。roiroi_infer为true时生效,设置推理resizer模型时所需的roi区域以分号间隔。frame_count设置 infer运行帧数,单帧重复推理,可与enable_dump并用,验证输出一致性,默认为1。dump_intermediatedump模型每一层输入数据和输出数据,默认值 0,不dump数据。1:输出文件类型为bin;2:输出类型为bin和txt,其中BPU节点输出为aligned数据;3:输出类型为bin和txt,其中BPU节点输出为valid数据。enable_dumpdump模型输出数据,默认为 false。dump_precision控制txt格式输出float型数据的小数点位数,默认为 9。hybrid_dequantize_process控制txt格式输出float类型数据,若输出为定点数据将其进行反量化处理,目前只支持四维模型。 dump_formatdump模型输出文件的类型,可选参数为 bin或txt,默认为bin。dump_txt_axisdump模型txt格式输出的换行规则;若输出维度为n,则参数范围为[0, n], 默认为 4。enable_cls_post_process使能分类后处理,目前只支持ptq分类模型,默认 false。
多输入模型说明
工具 infer 推理功能支持多输入模型的推理,支持图片输入、二进制文件输入以及文本文件输入,输入数据用逗号隔开。
模型的输入信息可以通过 model_info 进行查看。
- 示例说明
hrt_model_exec infer --model_file=xxx.bin --input_file=xxx.jpg,input.txt
输入参数补充说明
input_file
图片类型的输入,其文件名后缀必须为 bin / JPG / JPEG / jpg / jpeg 中的一种,feature输入后缀名必须为 bin / txt 中的一种。
每个输入之间需要用英文字符的逗号隔开 ,,例如: xxx.jpg,input.txt。
enable_cls_post_process
使能分类后处理。子命令为 infer 时配合使用,目前只支持在PTQ分类模型的后处理时使用,变量为 true 时打印分类结果。
参见下图:
roi_infer
若模型包含resizer输入源, infer 和 perf 功能都需要设置 roi_infer 为true,并且配置与输入源一一对应的 input_file 和 roi 参数。
如:模型有三个输入,输入源顺序分别为[ddr, resizer, resizer],则推理两组输入数据的命令行如下:
// infer
hrt_model_exec infer --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
// perf
hrt_model_exec perf --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
每个 roi 输入之间需要用英文字符的分号隔开。
dump_intermediate
dump模型每一层节点的输入数据和输出数据。 dump_intermediate=0 时,默认dump功能关闭;
dump_intermediate=1 时,模型中每一层节点输入数据和输出数据以 bin 方式保存,其中 BPU 节点输出为 aligned 数据;
dump_intermediate=2 时,模型中每一层节点输入数据和输出数据以 bin 和 txt 两种方式保存,其中 BPU 节点输出为 aligned 数据;
dump_intermediate=3 时,模型中每一层节点输入数据和输出数据以 bin 和 txt 两种方式保存,其中 BPU 节点输出为 valid 数据。
如: 模型有两个输入,输入源顺序分别为[pyramid, ddr],将模型每一层节点的输入和输出保存为 bin 文件,其中 BPU 节点输出按 aligned 类型保存,则推理命令行如下:
hrt_model_exec infer --model_file=xxx.bin --input_file="xx0.jpg,xx1.bin" --dump_intermediate=1
dump_intermediate 参数支持 infer 和 perf 两种模式。
hybrid_dequantize_process
控制txt格式输出float类型数据。 hybrid_dequantize_process 参数在 enable_dump=true 时生效。
当 enable_dump=true 时,若设置 hybrid_dequantize_process=true ,反量化整型输出数据,将所有输出按float类型保存为 txt 文件,其中模型输出为 valid 数据,支持配置 dump_txt_axis 和 dump_precision;
若设置 hybrid_dequantize_process=false ,直接保存模型输出的 aligned 数据,不做任何处理。
如: 模型有3个输出,输出Tensor数据类型顺序分别为[float,int32,int16], 输出txt格式float类型的 valid 数据, 则推理命令行如下:
// 输出float类型数据
hrt_model_exec infer --model_file=xxx.bin --input_file="xx.bin" --enable_dump=true --hybrid_dequantize_process=true
hybrid_dequantize_process 参数目前只支持四维模型。
perf
- 概述
该参数用于测试模型的推理性能。 使用此工具命令,用户无需输入数据,程序会根据模型信息自动构造模型的输入tensor,tensor数据为随机数。 程序默认单线程运行200帧数据,当指定perf_time参数时,frame_count参数失效,程序会执行指定时间后退出。 程序运行完成后,会输出模型运行的程序线程数、帧数、模型推理总时间,模型推理平均latency,帧率信息等。
程序每200帧打印一次性能信息:latnecy的最大、最小、平均值,不足200帧程序运行结束打印一次。
- 示例说明
- 单模型
hrt_model_exec perf --model_file=xxx.bin
- 多模型
hrt_model_exec perf --model_file=xxx.bin,xxx.bin --model_name=xx
-
可选参数
参数 说明 core_id指定模型推理的核id,0:任意核,1:core0,2:core1;默认为 0。input_file模型输入信息,多个可通过逗号分隔。 roi_infer使能resizer模型推理;若模型输入包含resizer源,设置为 true,默认为false。roiroi_infer为true时生效,设置推理resizer模型时所需的roi区域以分号间隔。frame_count设置 perf运行帧数,当perf_time为0时生效,默认为200。dump_intermediatedump模型每一层输入数据和输出数据,默认值 0,不dump数据。1:输出文件类型为bin;2:输出类型为bin和txt,其中BPU节点输出为aligned数据;3:输出类型为bin和txt,其中BPU节点输出为valid数据。perf_time设置 perf运行时间,单位:分钟,默认为0。thread_num设置程序运行线程数,范围[1, 8], 默认为 1, 设置大于8时按照8个线程处理。profile_path统计工具日志产生路径,运行产生profiler.log和profiler.csv,分析op耗时和调度耗时。时。
多线程Latency数据说明
多线程的目的是为了充分利用BPU资源,多线程共同处理 frame_count 帧数据或执行perf_time时间,直至数据处理完成/执行时间结束程序结束。
在多线程 perf 过程中可以执行以下命令,实时获取BPU资源占用率情况。
hrut_somstatus -n 10000 –d 1
输出内容如下:
=====================1=====================
temperature-->
CPU : 37.5 (C)
cpu frequency-->
min cur max
cpu0: 240000 1200000 1200000
cpu1: 240000 1200000 1200000
cpu2: 240000 1200000 1200000
cpu3: 240000 1200000 1200000
bpu status information---->
min cur max ratio
bpu0: 400000000 1000000000 1000000000 0
bpu1: 400000000 1000000000 1000000000 0
��以上示例展示的为 RDK X3 开发板的输出日志, 若使用 RDK Ultra 开发板,直接使用上述命令获取即可。
在 perf 模式下,单线程的latency时间表示模型的实测上板性能,
而多线程的latency数据表示的是每个线程的模型单帧处理时间,其相对于单线程的时间要长,但是多线程的总体处理时间减少,其帧率是提升的。
输入参数补充说明
profile_path
profile日志文件产生目录。
该参数通过设置环境变量 export HB_DNN_PROFILER_LOG_PATH=${path} 查看模型运行过程中OP以及任务调度耗时。
一般设置 --profile_path="." 即可,代表在当前目录下生成日志文件,日志文件为profiler.log。
thread_num
线程数(并行度),数值表示最多有多少个任务在并行处理。 测试延时时,数值需要设置为1,没有资源抢占发生,延时测试更准确。 测试吞吐时,建议设置>2 (BPU核心个数),调整线程数使BPU利用率尽量高,吞吐测试更准确。
// 双核FPS
hrt_model_exec perf --model_file xxx.bin --thread_num 8 --core_id 0
// Latency
hrt_model_exec perf --model_file xxx.bin --thread_num 1 --core_id 1
hrt_bin_dump 工具使用说明
hrt_bin_dump 是 PTQ debug模型的layer dump工具,工具的输出文件为二进制文件。
输入参数描述
| 编号 | 参数 | 类型 | 描述 | 说明 |
|---|---|---|---|---|
| 1 | model_file | string | 模型文件路径。 | 必须为debug model。即模型的编译参数 layer_out_dump 需要设置为 True,指定模型转换过程中输出各层的中间结果。 |
| 2 | input_file | string | 输入文件路径。 | 模型的输入文件,支持 hbDNNDataType 所有类型的输入; IMG类型文件需为二进制文件(后缀必须为.bin),二进制文件的大小应与模型的输入信息相匹配,如:YUV444文件大小为 :math:height * width * 3; TENSOR类型文件需为二进制文件或文本文件(后缀必须为.bin/.txt),二进制文件的大小应与模型的输入信息相匹配,文本文件的读入数据个数必须大于等于模型要求的输入数据个数,多余的数据会被丢弃;每个输入之间通过逗号分隔,如:模型有两个输入,则: --input_file=kite.bin,input.txt。 |
| 3 | conv_mapping_file | string | 模型卷积层配置文件。 | 模型layer配置文件,配置文件中标明了模型各层信息,在模型编译过程中生成。文件名称一般为: model_name_quantized_model_conv_output_map.json。 |
| 4 | conv_dump_path | string | 工具输出路径。 | 工具的输出路径,该路径应为合法路径。 |
使用说明
工具提供dump卷积层输出功能,输出文件为二进制文件。
直接运行 hrt_bin_dump 获取工具使用详情。
参见下图:
工具也可以通过 -v 或者 --version 命令,查看工具的 dnn 预�测库版本号。
例如: hrt_bin_dump -v 或 hrt_bin_dump --version
示例说明
以mobilenetv1的debug模型为例,创建outputs文件夹,执行以下命令:
./hrt_bin_dump --model_file=./mobilenetv1_hybrid_horizonrt.bin --conv_mapping_file=./mobilenetv1_quantized_model_conv_output_map.json --conv_dump_path=./outputs --input_file=./zebra_cls.bin
运行日志参见以下截图:
在路径 outputs/ 文件夹下可以查看输出,参见以下截图: