8.5 AI模型、算法与工具链
工具链问题建议优先使用最新版本。相关下载资源请参考:下载资源汇总
本节主要解答与地瓜机器人RDK平台上AI模型部署、算法开发、以及算法工具链使用相关的常见疑问。
Q1: 使用算法工具链遇到问题,在提问时需要提供哪些信息?
A: 当您在使用地瓜机器人算法工具链遇到问题并寻求技术支持时,为了帮助快速定位问题,请尽量提供以下完整信息:
- 目标RDK硬件平台及处理器架构: 例如 RDK X3 (BPU Bernoulli2), RDK Ultra (BPU Bayes), RDK X5 (BPU Bayes-e), Super100 (BPU Nash-e), Super100P (BPU Nash-m)。
- 算法工具链转换环境信息:
horizon_nn包版本 (通过pip list | grep horizon查看)。- Python 版本 (例如 Py3.8, Py3.10)。
- 使用的工具链Docker镜像版本(如果使用Docker)。
- 原始模型文件: 提供您的ONNX模型文件(或其他原始格式模型文件)。
- 模型转换相关文件:
- 转换时使用的
yaml配置文件。 - 完整的
hb_mapper make_model_log或类似日志文件 (例如hb_mapper_makertbin_log_*.log)。 - 用于PTQ量化的校准数据集(或其生成方法和少量样本)。
- 转换时使用的
- 板端部署相关文件:
- 板端部署的代码片段或完整项目。
- 板端运行时的具体报错信息和日志。
- RDK板卡的系统版本信息(通过
rdkos_info命令获取)。
- 详细的问题复现步骤: 清晰地描述如何一步步操作才能重现您遇到的问题。
- 预期行为与实际行为: 描述您期望得到的结果以及实际观察到的现象。
注意: 很多常见问题可能在工具链的旧版本中存在,而已在新版本中修复。建议优先使用官方最新发布的Docker镜像和工具链版本。
- Docker镜像下载与挂载参考:
- 如果问题复杂,建议将完整的开发机转换项目、板端部署项目以及详细的错误复现方式,通过网盘等形式分享给技术支持人员。
Q2: 进行AI算法开发有哪些推荐的官方资源?
A:
- RDK用户手册 - 算法工具链章节: 这是最基础也是最重要的参考资料,详细介绍了工具链的安装、使用流程、各项工具的功能和参数等。
- 通用入口:https://developer.d-robotics.cc/rdk_doc/04_toolchain_development (请以官方最新文档为准)
- RDK Model Zoo (模型仓库): 官方提供的模型示例库,包含了多种常见AI模型在RDK平台上的移植、优化、量化和部署示例代码及教程。
- 地瓜开发者社区 - 资源中心: 社区的资源中心板块通常会汇总各类开发资源,包括工具链、SDK、示例代码、技术文档、教程视频等。
Q3: RDK X3(旭日X3派)平台有哪些社区算法资源和工具链手册?
A: 针对RDK X3平台的算法开发,可以参考以下OpenExplorer社区资源:
- RDK X3 算法工具链社区手册 (OpenExplorer): https://developer.d-robotics.cc/api/v1/fileData/horizon_xj3_open_explorer_cn_doc/index.html
- RDK X3 OpenExplore 产品发布及相关资源帖: https://developer.d-robotics.cc/forumDetail/136488103547258769
Q4: RDK Ultra平台有哪些社区算法资源和工具链手册?
A: 针对RDK Ultra平台的算法开发,可以参考以下OpenExplorer社区资源:
- RDK Ultra 算法工具链社区手册 (OpenExplorer): https://developer.d-robotics.cc/api/v1/fileData/horizon_j5_open_explorer_cn_doc/index.html
- RDK Ultra OpenExplore 产品发布及相关资源帖: https://developer.d-robotics.cc/forumDetail/118363912788935318
Q5: RDK X5平台有哪些社区算法资源和工具链手册?
A: 针对RDK X5平台的算法开发,可以参考以下OpenExplorer社区资源:
- RDK X5 算法工具链社区手册 (OpenExplorer): https://developer.d-robotics.cc/api/v1/fileData/x5_doc-v126cn/index.html (请注意文档版本号,以最新为准)
- RDK X5 OpenExplore 产品发布及相关资源帖: https://developer.d-robotics.cc/forumDetail/251934919646096384
Q6: 算法工具链的Docker镜像是基于Ubuntu 20.04制作的,这会影响转换产物(如.bin或.hbm模型文件)在RDK板端Ubuntu 22.04系统上运行吗?
A: 通常不会影响。
地瓜机器人OpenExplorer提供的算法工具链Docker镜像虽然可能基于Ubuntu 20.04制作,但其主要作用是提供一个隔离的、包含所有必要转换工具和依赖库的模型转换环境。
它生成的模型文件(如.bin用于PTQ,.hbm用于QAT)是针对RDK板卡上特定BPU架构的二进制指令和权重数据。这些模型文件本身与运行它们的RDK板卡操作系统的Ubuntu版本(无论是20.04还是22.04)是解耦的,只要板卡上的Runtime库(如libdnn.so等BPU驱动和推理库�)与模型转换时使用的工具链版本兼容即可。
Q7: 如何在RDK平台上部署YOLO系列模型(如YOLOv5, YOLOv8, YOLOv10)?
A: 地瓜机器人官方和社区提供了丰富的YOLO系列模型在RDK平台上的部署教程和示例。
-
YOLOv5 在RDK X3平台的部署:
- 全流程部署教程: YOLOv5在RDK X3上的全流程部署
- YOLOv5s 2.0版本训练与转化: 如果您使用的是YOLOv5s的tag 2.0版本,可以参考官方工具链入门手册配置开发环境,并参考此博客进行训练和转化:YOLOv5s v2.0训练与转化博客
- 较高版本YOLOv5输出层修改: 如果您使用的是较高版本的YOLOv5(如v5.0, v6.0, v7.0等,其输出层结构与v2.0不同),可能需要修改模型的输出层以适配RDK BPU的后处理要求。参考博客:高版本YOLOv5输出层修改指南
- 板端示例后处理注意: RDK系统
/app/pydev_demo/07_yolov5_sample中的后处理部分可能直接摘自某个特定版本的训练代码,存在较多冗余计算,主要用于算法验证。对于追求性能的实际部署,建议参考RDK Model Zoo中的优化后处理实现。 - 实时视频流检测 (TROS部署,刷满30fps): 使用TROS快速部署YOLOv5刷满30fps
-
YOLOv8 在RDK X3平台的部署:
- Python多进程刷满30fps参考: CSDN博客 - YOLOv8 RDK X3部署
-
YOLOv10 在Bayes架构平台(如RDK X5/Ultra)的部署:
- Python多线程刷满30fps参考: CSDN博客 - YOLOv10 Bayes平台部署
-
通用资源: 强烈建议查阅 RDK Model Zoo (https://github.com/D-Robotics/rdk_model_zoo),其中包含了多种YOLO版本(及其他主流模型)的官方部署示例、预处理/后处理代码、以及性能优化技巧。
Q8: YOLOv5部署时遇到 can't reshape xxx in (84,84,3,85) 类似的错误,如何解决?
A: 这个错误通常是由于后处理代码中预设的类别数量 (num_classes) 与您�实际模型训练和导出的类别数量不匹配导致的。
例如,85 通常代表 (x, y, w, h, confidence + num_classes),如果您的模型是基于COCO数据集(80类)训练的,那么 num_classes 就是80,总共是 5 + 80 = 85 个输出通道。如果您训练的是自定义类别数量的模型(例如10类),那么这里应该是 5 + 10 = 15。
- 解决方法: 找到您使用的YOLOv5后处理代码文件(通常是一个Python脚本),修改其中定义的类别数量参数,使其与您模型的实际类别数一致。
- 参考: 上述 YOLOv5s v2.0训练与转化博客 中可能也包含了相关类别数修改的说明。
Q9: YOLOv5部署时,检测结果出现数量非常多且不规则的检测框,是什么原因?
A: 这通常是由于ONNX模型的输出头结构与板端后处理代码的预期不匹配。
- 可能原因1:输出头未按BPU要求修改。
- 较高版本的YOLOv5(例如tag 2.0以上)官方导出的ONNX模型,其输出层可能包含了特征解码部分(例如直接输出检测框坐标和类别得分),或者没有将大、中、小三个特征图的输出分开。
- 地瓜机器人RDK BPU部署通常要求ONNX模型的输出是原始的特征图,并且这三个特征图是作为独立的输出节点。
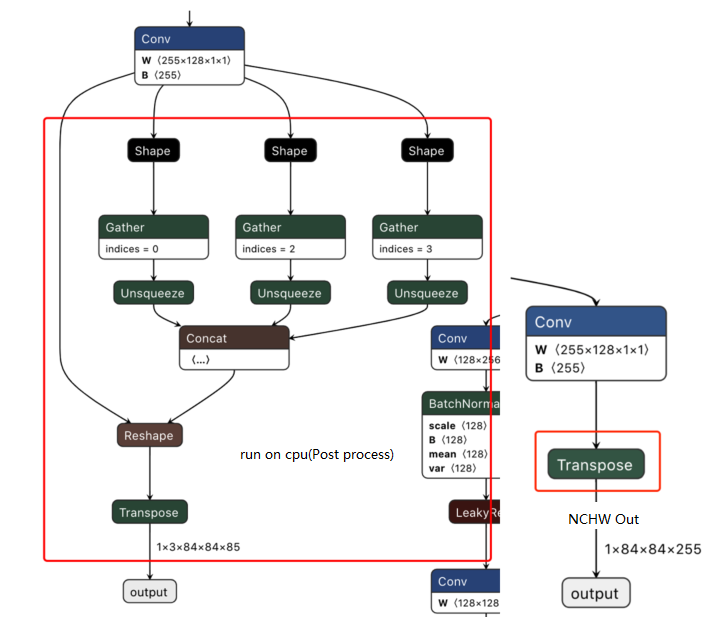
- 示例图(上为错误,下为部分正确但仍需调整):
上图:未分离特征图,包含解码。下图:分离了特征图,但可能错误添加了Sigmoid或未转NHWC。
- 解决方法:
- 您需要修改YOLOv5的导出脚本(通常是
models/yolo.py或类似文件),确保在导出ONNX模型时:- 移除模型末尾的检测头(解码层、NMS等)。
- 将三个不同尺度的特征图(P3, P4, P5或对应层)作为独立的输出节点。
- 确保输出的维度顺序符合工具链要求(例如,有时需要从NCHW转换为NHWC)。
- 不要在最终输出层后错误地添加不必要的激活函数(如Sigmoid),除非后处理代码明确需要。
- 参考教程: 高版本YOLOv5输出层修改指南 详细介绍了如何修改。
- 您需要修改YOLOv5的导出脚本(通常是
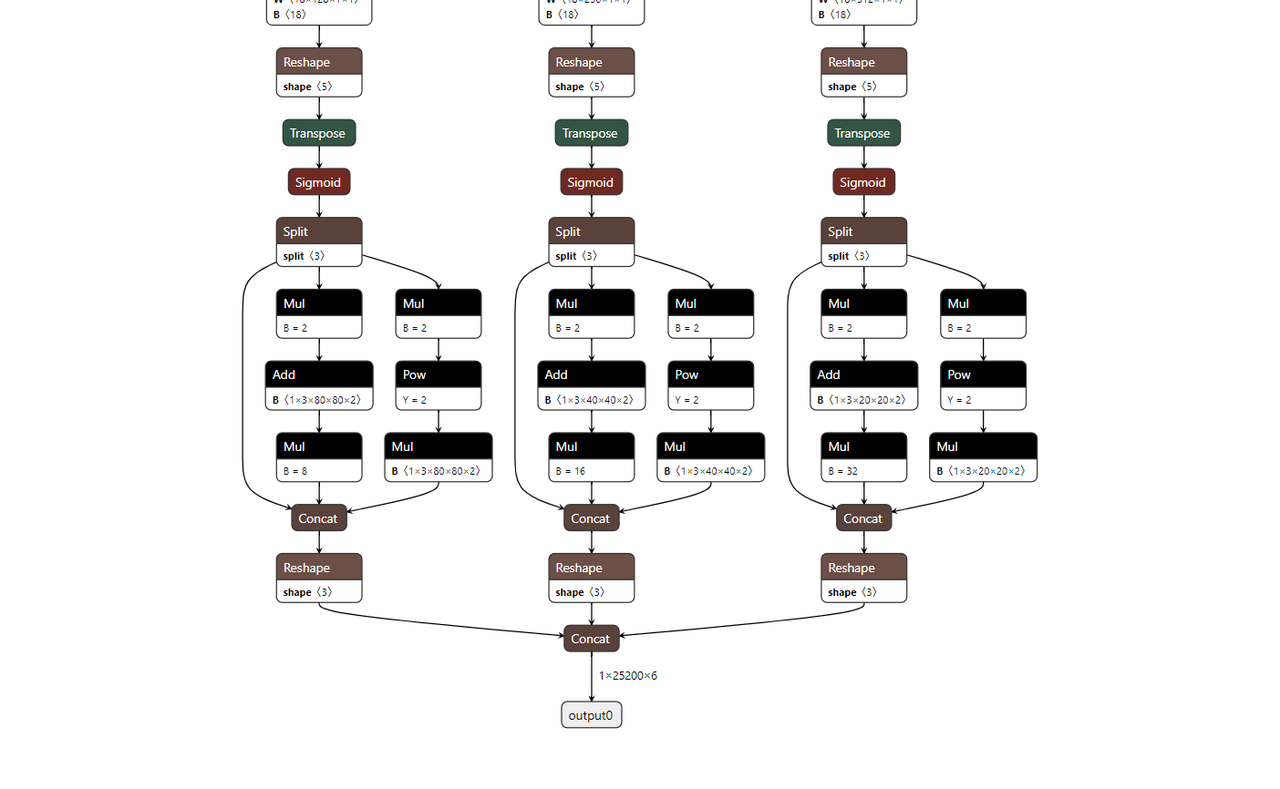
Q10: YOLOv5部署时,检测结果出现有周期性排列规律的异常检测框,是什么原因?
A:
- 可能原因:输出维度与后处理不匹配。
- 如果您使用的YOLOv5模型(例如公版的tag 2.0以下版本)在导出ONNX时,每个输出头的维度是5维的(例如
[batch, num_anchors, grid_h, grid_w, (x,y,w,h,conf+classes)]或者是[batch, num_anchors* (5+num_classes), grid_h, grid_w]展平的形式)。 - 而地瓜机器人BPU工具链在编译这类模型时,如果直接使用,可能会因为维度处理或后处理代码的预期,导致将某个维度截断或错误解析,从而出现周期性排列的异常检测框。
- 示例图:
 * 解决方法:
* 解决方法: - 推荐的做法是在导出ONNX模型时,将输出转换为明确的四维张量(例如NHWC格式:
[batch, grid_h, grid_w, num_anchors*(5+num_classes)]),并且在板端的后处理代码中,再根据这个NHWC的输出格式进行正确的解析和解码(例如,将其reshape回5维或进行相应的anchors计算)。 - 确保您的后处理逻辑与ONNX模型的最终输出维度和排列方式完全匹配。
- 如果您使用的YOLOv5模型(例如公版的tag 2.0以下版本)在导出ONNX时,每个输出头的维度是5维的(例如
Q11: YOLOv5部署时,检测框的位置出现整体偏移,是什么原因?
A:
- 渲染尺寸与图像原始尺寸不匹配:
- 后处理代码计算出的检测框坐标通常是相对于模型输入图像的尺寸(例如640x640)。如果您在显示结果时,将这些坐标直接绘制在一个不同尺寸的原始图像或显示画布上,而没有进行相应的缩放和平移变换,就会导致检测框位置偏移。
- 解决方法: 确保在渲染检测框之前,将模型输出的坐标按比例(
原始图像宽/模型输入宽,原始图像高/模型输入高)映射回原始图像的坐标系。如果模型输入前有padding操作,反向映射时也需要考虑去除padding的影响。
- Anchors不匹配:
- YOLOv5的检测框解码依赖于预设的锚框(anchors)。如果在模型训练时使用了一组anchors,但在后处理代码中使用了另一组不同的anchors(或者anchors的顺序、缩放方式不一致),会导致解码出的检测框位置和大小不正确。
- 解决方法: 确保后处理代码中使用的anchors参数(通常是18个数字,代表3个特征图上每层3个anchors的宽高)与模型训练时使用的anchors完全一致。
Q12: YOLOv5部署时,检测框都异常地聚集在图像的左上角,可能是什么原因?
A:
- 可能原因�:后处理库参数传递问题 (特指某些系统版本中的示例)。
- 在RDK OS 3.0.0及以上版本系统中,
/app/pydev_demo/07_yolov5_sample等示例中可能使用了CPython封装的后处理库。如果模型训练的类别数量等关键参数没有正确地传递给这个后处理库的初始化或调用接口,可能会导致解码逻辑错误,出现检测框聚集在左上角的现象。 - 示例图:
 * 解决方法:
* 解决方法: - 推荐使用RDK Model Zoo中的后处理: 对于YOLOv5等模型的验证和部署,强烈建议参考或直接使用 RDK Model Zoo (https://github.com/D-Robotics/rdk_model_zoo) 中提供的后处理代码。Model Zoo中的实现通常更健壮、更优化,并且与工具链的配合更紧密。
- 检查参数传递: 如果您坚持使用板载示例的后处理,请仔细检查示例代码,确保所有必要的参数(如类别数、输入分辨率、anchors、置信度阈值、NMS阈值等)都已正确配置并传递给了后处理函数或类。
- 在RDK OS 3.0.0及以上版本系统中,
Q13: 运行RDK板载的 /app/pydev_demo/07_yolov5_sample 示例时,如果使用自己的模型,报 Segmentation fault (段错误),怎么办?
A:
- 原因: 板载的官方示例程序(如
07_yolov5_sample)通常是针对其自带的预转换好的.bin模型进行适配和测试的。这个示例的预处理、模型加载、BPU推理调用以及后处理逻辑,都是围绕那个特定的自带模型设计的。 - 如果您用自己的(可能结构、输入输出、后处理逻辑都不同的)YOLOv5模型替换了示例中的
.bin文件,而没有相应地修改示例代码中的预处理、后处理或模型参数部分,就非常容易因为数据格式不匹配、内存访问越界等原因导致Segmentation fault。 - 解决方法:
- 不要直接替换bin文件就期望能运行: 原则上,对于自己训练和转换的模型,您需要编写或修改与之配套的完整推理程序(包括预处理、BPU推理接口调用、后处理)。
- 参考RDK Model Zoo: 对于YOLOv5这类常见模型,强烈建议参考 RDK Model Zoo (https://github.com/D-Robotics/rdk_model_zoo) 中对应模型的部署示例。Model Zoo通常会提供更通用、更清晰的预处理和后处理代码实现,您可以基于这些代码来适配您自己的模型。
- 理解后处理: 仔细学习YOLOv5的后处理原理(包括anchors解码、置信度过滤、NMS等),并确保您的后处理代码与您模型输出特征图的格式、维度、内容完全对应。
Q14: 模型推理检测不出任何结果,或者结果远差于预期,应该从哪些方面进行排查(Pipeline检查流程)?
A: 当模型部署后效果不佳或无输出时,需要系统性地检查整个推理流程(Pipeline):
-
数据预处理 (Preprocessing) 检查:
- 与训练时是否一致: 这是最关键的一点。确保部署时的预处理操作(如resize方式、归一化参数、均值方差、颜色空间转换如RGB/BGR、letterbox的padding方式和颜色等)与模型训练时所用的预处理完全一致。任何细微的差异都可能导致模型性能急剧下降。
- 可视化预处理结果: 将预处理后的图像数据保存下来(例如,如果输入是图片,就保存处理后的图片;如果是numpy数组,就将其可视化),与训练时送入模型的数据进行对比,看是否一致。
- 工具链
yaml配置: 在使用地瓜机器人工具链进行模型转换(PTQ)时,yaml配置文件中会有预处理相关的参数(如norm_type,mean_value,std_value等)。确保这些参数的设置能够正确地“抵消”掉您在将校准数据送入工具链之前所做的预处理,使得工具链看到的校准数据与模型训练时第一�层卷积前的输入分布一致。
-
模型转换过程检查:
- 工具链版本: 使用官方推荐的最新稳定版算法工具链。
yaml配置: 仔细检查模型转换时的yaml配置文件,确保所有参数(如输入节点名、输出节点名、输入数据类型、输入布局、模型类型、BPU架构等)都设置正确。- 校准数据集 (PTQ):
- 校准数据集的质量和代表性对PTQ量化后的模型精度至关重要。数据集应与实际应用场景的数据分布相似。
- 校准数据的预处理方式如前所述,必须与部署时一致(或者说,送入工具链的校准数据应是“逆预处理”后的,以便工具链内部进行正确的量化校准)。
- 量化敏感层分析: 如果PTQ后精度下降较多,可以使用工具链提供的精度分析工具(如层与层比对,dump各层数据)来定位哪些层对量化比较敏感,然后尝试混合精度量化(部分层使用更高精度或浮点)或QAT(量化感知训练)。
- 转换日志: 仔细阅读模型转换过程中工具链输出的完整日志,查找是否有任何错误、警告或提示信息。
-
BPU推理与板端Runtime检查:
- 输入数据准备: 确保送入板端BPU推理接口的数据与模型转换时定义的输入格式(layout, data type, shape)完全一致。
- 内存管理: 检查输入输出Buffer的分配、拷贝是否正确,有无内存踩踏或越界。
- Runtime版本: 确保板端使用的BPU驱动和Runtime库 (
libdnn.so等) 版本与模型转换时使用的工具链版本兼容。 - API调用: 检查BPU推理API的调用顺序、参数设置是否正确。
-
后处理 (Postprocessing) 检查:
- 与模型输出匹配: 确保后处理代码的逻辑(如解析输出特征图、解码检测框、应用NMS、阈值处理等)与模型转换后实际输出节点的格式、维度、含义完全匹配。
- 参数一致性: 后处理中使用的各种参数(如anchors, 类别数, 置信度阈值, NMS阈值, score_threshold等)必须与模型设计和训练时一致。
- 坐标映射: 如果有必要,确保将模型输出的坐标正确映射回原始图像尺寸。
- 逻辑错误: 仔细检查后处理代码是否存在逻辑bug。
-
端到端验证:
- 使用已知输入和输出: 最好能有一组训练集或验证集中的样本,您知道其对应的正确检测结果(Ground Truth)。用这些样本通过您的整个部署Pipeline,对比实际输出与期望输出。
- 逐模块验证: 如果可能,将整个Pipeline拆分成预处理、模型推理、后处理等模块,对每个模块的输入输出进行单独验证。
Q15: 板端hrt_*系列性能分析工具(如hrt_model_exec, hrt_bpu_monitor等)如何获取?
A: 地瓜机器人RDK的系统镜像中,或者随算法工具链/SDK发布的包中,通常会包含一些用于板端模型执行��、性能分析和调试的命令行工具,它们一般以 hrt_ (Horizon Robotics Tool) 开头。
- 查找位置:
- 这些工具可能预装在RDK系统镜像的
/usr/bin或/opt/hobot/bin等路径下。 - 也可能包含在您下载的算法工具链包(解压后)的某个子目录中(例如
ddk/package/board/<target_os>/bin/或类似路径),您需要将这些工具手动拷贝到板卡的某个可执行路径下(如/usr/local/bin)或直接在板卡上指定其完整路径运行。
- 这些工具可能预装在RDK系统镜像的
- 官方资源帖: 地瓜开发者社区通常会有专门的帖子或文档说明这些板端工具的获取方式和使用方法。例如,此帖曾提供相关信息: 板端hrt_*工具下载及使用说明 (请确认链接及内容的最新有效性)
- 常用工具:
hrt_model_exec: 用于在板端执行转换好的.bin模型,进行推理验证和性能测试。hrt_bpu_monitor(或hrut_somstatus,bpu_predict_xN_sample中的性能打印部分): 用于监控BPU的实时使用率、频率、温度等状态。- 其他特定调试工具。
请查阅最新的RDK文档或社区资源,以获取这些工具的准确信息和下载方式。
模型量化错误及解决方法
hb_mapper checker (01_check.sh) 模型验证错误
【问题】 ERROR The shape of model input:input is [xxx] which has dimensions of 0. Please specify input-shape parameter.
- 发生此错误的原因可能是模型输入为动态shape。针对此错误,您可使用参数
--input-shape input_name input_shape来指定输入节点的shape信息。
ERROR HorizonRT not support these cpu operators: {op_type}
- 发生此错误的原因可能是使用的CPU算子为D-Robotics 不支持的CPU算子。 针对此错误,您可以根据我们提供的算子支持列表中的内容对算子进行替换;若不被支持的CPU算子为模型核心算子,请您联系D-Robotics 对此进行开发评估。
Unsupported op {op_type}
- 发生此错误的原因可能是使用的BPU算子为D-Robotics 不支持的BPU算子。针对此错误,若模型整体性能可满足需要,您可以忽略该日志;若模型整体性能不能达到您的预期,您可以根据我们提供的算子支持列表中的内容对算子进行替换。
ERROR nodes:['{op_type}'] are specified as domain:xxx, which are not supported by official onnx. Please check whether these ops are official onnx ops or defined by yourself
- 发生此错误的原因可能是使用的自定义算子为D-Robotics 不支持的自定义算子。针对此错误,您可以根据我们提供的算子支持列表中的内容对算子进行替换或参考自定义算子开发完成自定义CPU算子注册。
hb_mapper makertbin (03_build.sh) 模型转换错误
【问题】Layer `{op_name}`
xxx expect data shape range:[[xxx][xxx]], but the data shape is [xxx]
Layer `{op_name}`
Tensor xxx expects be n dimensions, but m provided
- 发生此错误的原因可能是,
{op_name}算子超过支持限制被回退到CPU计算。针对此错误,若CPU算子带来的性能损耗您可接受,则无需关注该信息;若性能不能达到您的要求,您可以根据我们提供的算子支持列表中的内容将该op修改至BPU可支持的范围。
INFO: Layer `{op_name}` will be executed on CPU
- 发生此错误的原因可能是,
{op_name}算子由于shape(CxHxW)超过8192被回退到CPU计算。针对此错误,若仅少数算子被回退CPU计算且模型整体性能满足要求,则无需关注该信息;若性能不满足要求,建议查看算子支持列表,替换为其他无shape限制的BPU算子。
ERROR There is an error in pass: `{op_name}`. Error message:xxx
- 发生此错误的原因可能是,
{op_name}算子优化失败。针对此错误,请您将模型以及.log文件收集好后提供给D-Robotics 技术人员进行分析处理。
Error There is an error in pass:constant_folding. Error message: Could not find an implementation for the node `{op_name}`
- 发生此错误的原因可能是该算子onnxruntime暂未支持。针对此错误,您可以根据我们提供的算子支持列表中的内容对算子进行替换,如不被支持的算子为核心算子,��请您联系D-Robotics 对此进行开发评估。
WARNING input shape [xxx] has length: n ERROR list index out of range
- 发生此错误的原因可能是目前模型输入暂不支持非四维输入。针对此错误,建议您将模型输入修改至四维(例如HxW -> 1x1xHxW)。
Start to parse the onnx model
core dump
- 发生此错误的原因可能是模型解析失败(可能是导出模型时只为一个output/input节点指定了name)。针对此错误,建议您重新导出onnx并确认其有效性(导出onnx模型时不指定output/input name,或者依次为每个output/input节点指定名称)。
Start to calibrate/quantize the model
core dump
Start to compile the model
core dump
- 发生此错误的原因可能是模型量化/编译失败。针对此错误,请您将模型以及.log文件收集好后提供给D-Robotics 技术人员进行分析处理。
ERROR model conversion faild: Inferred shape and existing shape differ in dimension x: (n) vs (m)
- 发生此错误的原因可能是onnx模型的输入shape非法,或者是工具优化pass有误。针对此错误,请您确保onnx模型的有效性,若onnx模型可正常推理,请将模型提供给D-Robotics 技术人员进行分析处理。
WARNING got unexpected input/output/sumin threshold on conv `{op_name}`! value: xxx
- 发生此错误的原因可能是数据预处理有误,或该节点weight值太小/太大。针对此错误,1.请您检查数据预处理是否有误;2.我们建议您使用BN算子优化数据分布。
ERROR hbdk-cc compile hbir model failed with returncode -n
- 发生此错误的原因可能是模型编译失败。针对此错误,请您将模型以及.log文件收集好后提供给D-Robotics 技术人员进行分析处理。
ERROR {op_type} only support 4 dim input
- 发生此错误的原因可能是工具链�暂不支持该op输入维度为非四维。针对此错误,我们建议您将该op输入维度调整为四维输入。
ERROR {op_type} Not support this attribute/mode=xxx
- 发生此错误的原因可能是工具链暂不支持op的该属性。针对此错误,您可以根据我们提供的算子支持列表中的内容进行替换或联系D-Robotics 对此进行开发评估。
ERROR There is no node can execute on BPU in this model, please make sure the model has at least one conv node which is supported by BPU.
- 发生此错误的原因可能是模型中没有可量化的BPU节点。针对此错误,请您确保onnx模型的有效性,且模型中至少使用了一个conv;若前述条件均已满足,请您将模型以及.log文件收集好后提供给D-Robotics 技术人员进行分析处理。
ERROR [ONNXRuntimeError] : 9 : NOT_IMPLEMENTED : could not find a implementation for the node of `{op_name}`:{op_type}(opset)
- 发生此错误的原因可能是模型opset版本超出工具链支持限制。 针对此错误,请您重新导出模型,确保
opset_version=10或者11。
ERROR The opset version of the onnx model is n, only model with opset_version 10/11 is supported
- 发生此错误的原因可能是模型opset版本超出工具链支持限制。针对此错误,请您重新导出模型,确保
opset_version=10 或者 11。
使用run_on_bpu后转换报错。
- 发生此错误的原因可能是目前暂不支持将该算子run_on_bpu。
run_on_bpu暂仅支持指定模型尾部的Relu/Softmax/pooling(maxpool、avgpool等)算子以及CPU*+Transpose组合(可通过声明Transpose节点名称,将CPU*+Transpose都运行在BPU上,CPU*特指BPU支持的op),若满足前述条件但仍run_on_bpu失败,请您联系D-Robotics 技术人员对此进行分析处理;若不满足前述条件,可联系D-Robotics 技术人员对此进行开发评估。
ERROR tool limits for max output num is 32
- 发生此错误的原因可能是工具链仅支持模型输出节点数量不超过32。针对此错误,建议您将模型输出节点数量控制在32个以内。
ERROR xxx file parse failed.
ERROR xxx does not exist in xxx.
- 发生此错误的原因可能是,环境配置不正确。请使用D-Robotics 提供的docker环境进行量化。
ERROR exception in command: makertbin.
ERROR cannot reshape array of size xxx into shape xxx.
- 发生此错误的原因可能是,数据预处理异常导致,请参考我们的文档中预处理相关信息。
ERROR load cal data for input xxx error
ERROR cannot reshape array of size xxx into shape xxx
- 发生此错误的原因可能是工具链版本不匹配,请使用我们提供的SDK中对应的工具链版本。
ERROR [ONNXRuntimeError] : 1 : FAIL : Non-zero status code returned while running HzCalibration node.Name:'xxx'Status Message :CUDA error cudaErrorNoKernelImageForDevice:no kernel image is available for execution on the device
- 发生此错误的原因可能是docker加载错误。 建议您加载Docker时换用nvidia docker加载命令
[ONNXRuntimeError] : 10 : INVALID_GRAPH : Load model from xxx.onnx failed:This is an invalid model. In Node, ("xxx", HzSQuantizedPreprocess, "", -1) : ("images": tensor(int8),"xxx": tensor(int8),"xxx": tensor(int32),"xxx": tensor(int8),) -> ("xxx": tensor(int8),) , Error No Op registered for HzSQuantizedPreprocess with domain_version of 11
- 发生此错误的原因可能onnx版本不匹配,重新导出onnx opset10版本并采用opencv方法做预处理
[E:onnxruntime:, sequential_executor.cc:183 Execute] Non-zero status code returned while running Resize node. Name:'xxx' Status Message: upsample.h:299 void onnxruntime::UpsampleBase::ScalesValidation(const std::vector<float>&, onnxruntime::UpsampleMode) const scales.size() == 2 || (scales.size() == 4 && scales[0] == 1 && scales[1] == 1) was false. 'Linear' mode and 'Cubic' mode only support 2-D inputs ('Bilinear', 'Bicubic') or 4-D inputs with the corresponding outermost 2 scale values being 1 in the Resize operator
- 发生此错误的原因可能是onnxruntime自己的问题,不能batch校准,只能1张张校准,因为模型里边有reshape, batch 后维度对不上了,对结果不影响。
ERROR No guantifiable nodes were found, and the model is not supported
- 发生此错误的原因可能是模型结构中没有包含输出节点导致的原因。
算法模型上板错误及解决方法
【问题】(common.h:79): HR:ERROR: op_name:xxx invalid attr key xxx
- 发生此错误的原因可能是libDNN暂不支持该op的某个属性。针对此错误,您可以根据我们提供的算子支持列表中的内容进行替换或联系D-Robotics 对此进行开发评估。
(hb_dnn_ndarray.cpp:xxx): data type of ndarray do not match specified type. NDArray dtype_: n, given:m
- 发生此错误的原因可能是libDNN暂不支持该输入类型(后续我们将逐步把算子约束前移至模型转换阶段提醒)。针对此错误,您可以根据我们提供的算子支持列表中的内容进行替换或联系D-Robotics 对此进行开发评估。
(validate_util.cpp:xxx):tensor aligned shape size is xxx , but tensor hbSysMem memSize is xxx, tensor hbSysMem memSize should >= tensor aligned shape size!
- 发生此错误的原因可能是输入数据申请内存不足。针对此错误,请使用hbDNNTensorProperties.alignedByteSize来申请内存空间。
(bpu_model_info.cpp:xxx): HR:ERROR: hbm model input feature names must be equal to graph node input names
- 针对此错误,请您完整更新最新版本的工具链SDK开发包。
模型量化及上板使用技巧
Transformer使用说明
本章节将对各个transformer的概念及参数进行说明,并为您提供参考使用示例,方便您进行tranformer操�作。
在文档内容开始阅读前,以下内容请您注意:
- 图片数据为
三维数据,但D-Robotics 提供的transformer都是以四维数据的方式来进行获取和处理的,transformer只会对输入数据中的第0张图片做该操作。
AddTransformer
说明:
对输入图片中的所有像素值做增加value的操作。该transformer会在输出时, 将数据格式转为float32。
参数:
- value: 对每个像素做增加的数值, 注意value的取值可以为负数, 如 -128。
使用举例:
# 对图像数据做减去128的操作
AddTransformer(-128)
# 对图像数据做增加127的操作
AddTransformer(127)
MeanTransformer
说明:
对输入图片中的所有像素值做减去 mean_value 的操作。
参数:
-
means: 对每个像素做增加的数值, 注意value的取值可以为负数, 如 -128。
-
data_format: 输入的layout类型,取值范围为["CHW","HWC"], 默认 "CHW"。
使用举例:
# 每个像素减去128.0 输入的类型为CHW
MeanTransformer(np.array([128.0, 128.0, 128.0]))
# 每个像素减去不同的数值,103.94, 116.78, 123.68,输入的类型为 HWC
MeanTransformer(np.array([103.94, 116.78, 123.68]), data_format="HWC")
ScaleTransformer
说明:
对输入图片中的所有像素值做乘以data_scale系数的操作。
参数:
- scale_value: 需要乘以的系数,如0.0078125 或者1/128。
使用举例:
# 将取值范围-128~127,所有的像素的调整到-1~1之间
ScaleTransformer(0.0078125)
# 或者
ScaleTransformer(1/128)
NormalizeTransformer
说明:
用于对输入图片进行归一化的操作。该transformer会在输出时, 将数据格式转为float32。
参数:
- std:输入的第一张图片,需要除以的数值。
使用举例:
# 将取值范围[-128, 127] 所有的像素的调整到-1~1之间
NormalizeTransformer(128)
TransposeTransformer
说明:
用于做layout转换的操作。
参数:
- order: 对输入图片做layout转换后的顺序(顺序与原有的layout顺序有关)。如:HWC的顺序为0,1,2,需要转为CHW时,order为(2,0,1)。
使用举例:
# HWC转到CHW
TransposeTransformer((2, 0, 1))
# CHW转到HWC
TransposeTransformer((1, 2, 0))
HWC2CHWTransformer
说明:
用于将NHWC转换为NCHW的操作。
参数:不涉及。
使用举例:
# NHWC转到NCHW
HWC2CHWTransformer()
CHW2HWCTransformer
说明:
用于将NCHW转换为NHWC的操作。
参数:不涉及。
使用举例:
# NCHW转到 NHWC
CHW2HWCTransformer()
CenterCropTransformer
说明:
以直接截断取值的方式从图片中心裁剪出一个正方形的图片的操作。该transformer会在输出时, 将数据格式转为float32。当data_type的值为uint8时,输出为uint8。
参数:
-
crop_size: 中心裁剪的正方形的边长size。
-
data_type: 输出结果的类型,取值范围为["float", "uint8"]。
使用举例:
# 以224*224的方式,做中心裁剪,默认输出类型为float32
CenterCropTransformer(crop_size=224)
# 以224*224的方式,做中心裁剪,输出类型为uint8
CenterCropTransformer(crop_size=224, data_type="uint8")
PILCenterCropTransformer
说明:
使用PIL的方式从图片中心裁剪出一个正方形的图片的操作。该transformer会在输出时, 将数据格式转为float32。
参数:
- size: 中心裁剪的正方形的边长size。
使用举例:
# 以224*224的方式,使用PIL的方式做中心裁剪
PILCenterCropTransformer(size=224)
LongSideCropTransformer
说明:
用于做长边裁剪的操作。该 transformer 会在输出时, 将数据格式转为float32。
当宽度比高度的数值大时,会裁剪出一个中心以高度大小为准的正方形,如宽100,高70,裁剪之后大小为70*70。
当高度比宽度的数值大时,会裁剪出一个中心以宽度大小不变,高度为差值的一半+宽度 的长方形,如宽70,高100,裁剪之后大小为 70*(100-70)/2+70 ,即70* 85大小的长方形。
参数:不涉及。
使用举例:
LongSideCropTransformer()
PadResizeTransformer
说明:
使用填充的方式做图像放大的操作。该 transformer 会在输出时, 将数据格式转为float32。
参数:
-
target_size:目标大小,值为元组,如(240,240)。
-
pad_value:填充到数组中的值,默认值为127。
-
pad_position:填充的位置,取值范围为["boundary", "bottom_right"],默认值为 "boundary"。
使用举例:
# 裁剪一个大小为512*512,填充到右下角,填充值为0
PadResizeTransformer((512, 512), pad_position='bottom_right', pad_value=0)
# 裁剪一个大小为608*608,填充到边框,填充值为 127
PadResizeTransformer(target_size=(608, 608))
ResizeTransformer
说明:
用于调整图像大小的操作。
参数:
-
target_size:目标大小,值为元组,如(240,240)。
-
mode:图片处理模式,取值范围为("skimage","opencv"),默认值为 "skimage"。
-
method:插值的方法,此参数仅在mode为skimage时生效。取值范围为0-5,默认值为1,其中:
-
0代表Nearest-neighbor;
-
1代表Bi-linear(default);
-
2代表Bi-quadratic;
-
3代表Bi-cubic;
-
4代表Bi-quartic;
-
5代表Bi-quintic。
-
-
data_type:输出的类型,取值范围为(uint8,float),默认为float类型。当被设置为uint8时,输出类型为uint8 ,其他情况为float32。
-
interpolation:插值的方法,此参数仅在mode为opencv时生效。默认为空,取值范围为(opencv的插值方式), 目前interpolation仅支持为空或opencv中的INTER_CUBIC两种插值方法,当interpolation为空时,默认使用INTER_LINEAR方式。
以下为opencv中支持的插值方式及说明(目前未支持的插值方式将在后续迭代中逐步支持):
-
INTER_NEAREST,最近邻插值;
-
INTER_LINEAR,双线性插值,当interpolation为空时,默认使用这种方法。
-
INTER_CUBIC,双三次插值4x4像素邻域内的双立方插值。
-
INTER_AREA,使用像素面积关系重采样。它可能是图像抽取的首选方法,因为它可以提供无莫尔条纹的结果。但是当图像被缩放时,它类似于INTER_NEAREST方法。
-
INTER_LANCZOS4,8x8邻域的Lanczos插值。
-
INTER_LINEAR_EXACT,位精确双线性插值。
-
INTER_NEAREST_EXACT,位精确最近邻插值。这将产生与PIL、scikit-image或Matlab中的最近邻方法相同的结果。
-
INTER_MAX,插值代码的掩码。
-
WARP_FILL_OUTLIERS,标志,填充所有目标图像像素。如果其中一些对应于源图像中的异常值,则将它们设置为零。
-
WARP_INVERSE_MAP,标志,逆变换。
-
使用举例:
# 将输入图片大小调整为224*224,采用 opencv 的方式处理图片,插值的方式为双线性,输出为float32
ResizeTransformer(target_size=(224, 224), mode='opencv', method=1)
# 将输入图片大小调整为256*256,采用skimage的方式处理图片,插值的方式为双线性,输出为float32
ResizeTransformer(target_size=(256, 256))
# 将输入图片大小调整为256*256,采用skimage的方式处理图片,插值的方式为双线性,输出为uint8
ResizeTransformer(target_size=(256, 256), data_type="uint8")
PILResizeTransformer
说明:
使用PIL库做调整图像大小的操作。
参数:
-
size:目标大小,值为元组,如(240,240)。
-
interpolation:指定插值的方式,取值范围:(Image.NEAREST,Image.BILINEAR,Image.BICUBIC,Image.LANCZOS), 默认值为Image.BILINEAR。
-
Image.NEAREST:最近邻采样;
-
Image.BILINEAR:线性插值;
-
Image.BICUBIC:三次样条插值;
-
Image.LANCZOS:高质量下采样滤波器。
-
使用举例:
# 将输入图片大小调整为256*256 插值的方式为线性插值
PILResizeTransformer(size=256)
# 将输入图片大小调整为256*256 插值的方式为高质量下采样滤波器
PILResizeTransformer(size=256, interpolation=Image.LANCZOS)
ShortLongResizeTransformer
说明:
按照原比例对输入图片进行缩放的操作,新图片的大小与设置的参数有关。操作方式如下:
-
先以short_size的大小除以原图片的宽和高里最小值,以这个值为缩放比例系数。
-
当缩放比例系数乘以原图片的宽和高中的最大值,得到的结果大于long_size的数值时,缩放比例系数将变更为long_size除以原图片的宽和高中的最大值。
-
使用opencv中的resize方法,根据上方得到的缩放比例系数重新裁剪图片。
参数:
-
short_size:预期裁剪后的短边的长度。
-
long_size:预期裁剪后的长边的长度。
-
include_im:默认值为True,设置为True时, 会在返回时除了返回处理后的图片, 还会返回原图片。
使用举例:
# 短边长度为20,长边长度为100,返回处理后的图片及原图片
ShortLongResizeTransformer(short_size=20, long_size=100)
PadTransformer
说明:
通过用目标大小的size值除以输入图片宽或者高里的最大值为系数,然后使用这个系数乘以原有的宽高,resize图片。 然后根据新图片的大小,除以size_divisor后向上取整后,再乘以size_divisor,为新的宽高,生成新的图片的操作。
参数:
-
size_divisor:大小除数 ,默认值为128。
-
target_size:目标大小,默认值为512。
使用举例:
# pad大小为1024*1024
PadTransformer(size_divisor=1024, target_size=1024)
ShortSideResizeTransformer
说明:
根据期望的短边的长度,使用现在的长短边的比例,中心裁剪出新的图片大小的操作。
参数:
-
short_size:预期的短边的长度。
-
data_type:输出结果的类型,取值范围为("float","uint8"),默认取值"float32", 以 float32 类型输出,设置为uint8时,输出类型将为uint8。
-
interpolation:指定插值的方式,取值范围为 opencv 中采用的插值方式,默认为空。
目前interpolation仅支持为空或opencv中��的INTER_CUBIC两种插值方法,当interpolation为空时,默认使用INTER_LINEAR方式。
以下为opencv中支持的插值方式及说明(目前未支持的插值方式将在后续迭代中逐步支持):
-
INTER_NEAREST,最近邻插值;
-
INTER_LINEAR,双线性插值,当interpolation为空时,默认使用这种方法。
-
INTER_CUBIC,双三次插值4x4像素邻域内的双立方插值。
-
INTER_AREA,使用像素面积关系重采样。它可能是图像抽取的首选方法,因为它可以提供无莫尔条纹的结果。但是当图像被缩放时,它类似于INTER_NEAREST方法。
-
INTER_LANCZOS4,8x8邻域的Lanczos插值。
-
INTER_LINEAR_EXACT,位精确双线性插值。
-
INTER_NEAREST_EXACT,位精确最近邻插值。这将产生与PIL、scikit-image或Matlab中的最近邻方法相同的结果。
-
INTER_MAX,插值代码的掩码。
-
WARP_FILL_OUTLIERS,标志,填充所有目标图像像素。如果其中一些对应于源图像中的异常值,则将它们设置为零。
-
WARP_INVERSE_MAP,标志,逆变换。
-
使用举例:
# 将短边大小调整为256,插值方式为双线性插值
ShortSideResizeTransformer(short_size=256)
# 将短边大小调整为256,插值方式为8x8像素邻域内的Lanczos插值
ShortSideResizeTransformer(short_size=256, interpolation=Image.LANCZOS4)
PaddedCenterCropTransformer
说明:
使用填充的方式对图片中心进行裁剪的操作。
.. attention::
仅适用于EfficientNet-lite相关实例模型。
计算方式为:
-
计算系数,int((float( image_size ) / ( image_size + crop_pad ))。
-
计算中心size的大小, 系数 * np.minimum( 原始图片的高度, 原始图片的宽度 ))。
-
根据计算出来的size大小,做中心裁剪。
参数:
-
image_size:图片的大小,默认值为224。
-
crop_pad:中心填充的大小,默认值为32。
使用举例:
# 裁剪大小为240*240,填充值为32
PaddedCenterCropTransformer(image_size=240, crop_pad=32)
# 裁剪大小为224*224,填充值为32
PaddedCenterCropTransformer()
BGR2RGBTransformer
说明:
将输入格式由BGR转成RGB的操作。
参数:
- data_format:数据格式,取值范围为(CHW,HWC),默认值为CHW。
使用举例:
# layout为NCHW时,做BGR转为RGB
BGR2RGBTransformer()
# layout为NHWC时,做BGR转为RGB
BGR2RGBTransformer(data_format="HWC")
RGB2BGRTransformer
说明:
将输入格式由RGB转成BGR的操作。
参数:
- data_format:数据格式,取值范围为(CHW,HWC),默认值为CHW。
使用举例:
# layout为NCHW时,做RGB转成BGR
RGB2BGRTransformer()
# layout为NHWC时,做RGB转成BGR
RGB2BGRTransformer(data_format="HWC")
RGB2GRAYTransformer
说明:
将输入格式由RGB转成GRAY的操作。
参数:
- data_format:输入的layout类型,取值范围("CHW","HWC"),默认为"CHW"。
使用举例:
# layout为NCHW时,做RGB转成GRAY
RGB2GRAYTransformer(data_format='CHW')
# layout为NHWC时,做RGB转成GRAY
RGB2GRAYTransformer(data_format='HWC')
BGR2GRAYTransformer
说明:
将输入格式由 BGR 转成 GRAY 的操作。
参数:
- data_format:输入的layout类型,取值范围 ["CHW","HWC"],默认值为"CHW"。
使用举例:
# layout为NCHW时,做BGR转成GRAY
BGR2GRAYTransformer(data_format='CHW')
# layout为NHWC时,做BGR转成GRAY
BGR2GRAYTransformer(data_format='HWC')
RGB2GRAY_128Transformer
说明:
输入格式由RGB转成GRAY_128的操作。GRAY_128取值范围为(-128,127)。
参数:
- data_format:输入的layout类型,取值范围为["CHW","HWC"],默认值为"CHW",此项为必填项。
使用举例:
# layout为NCHW时,做RGB转成GRAY_128
RGB2GRAY_128Transformer(data_format='CHW')
# layout为NHWC时,做RGB转成GRAY_128
RGB2GRAY_128Transformer(data_format='HWC')
RGB2YUV444Transformer
说明:
将输入格式由RGB转成YUV444的操作。
参数:
- data_format:输入的layout类型,取值范围为["CHW", "HWC"],默认值为"CHW",此项为必填项。
使用举例:
# layout为NCHW时,做BGR转成YUV444
BGR2YUV444Transformer(data_format='CHW')
# layout为NHWC时,做BGR转成YUV444
BGR2YUV444Transformer(data_format='HWC')
BGR2YUV444Transformer
说明:
将输入格式由BGR转成YUV444的操作。
参数:
- data_format:输入的layout类型,取值范围为["CHW","HWC"],默认值为 "CHW",此项为必填项。
使用举例:
# layout为NCHW时,做BGR转成YUV444
BGR2YUV444Transformer(data_format='CHW')
# layout为NHWC时,做BGR转成YUV444
BGR2YUV444Transformer(data_format='HWC')
BGR2YUV444_128Transformer
说明:
将输入格式由BGR转成YUV444_128的操作。YUV444_128取值范围为(-128,127)。
参数:
- data_format:输入的layout类型,取值范围为["CHW","HWC"],默认值为 "CHW",此项为必填项。
使用举例:
# layout为NCHW时,做BGR转成YUV444_128
BGR2YUV444_128Transformer(data_format='CHW')
# layout为NHWC时,做BGR转成YUV444_128
BGR2YUV444_128Transformer(data_format='HWC')
RGB2YUV444_128Transformer
说明:
将输入格式由RGB转成YUV444_128的操作。YUV444_128取值范围为(-128,127)。
参数:
- data_format:输入的layout类型,取值范围为["CHW","HWC"],默认值为"CHW",此项为必填项。
使用举例:
# layout为NCHW时,做RGB转成 YUV444_128
RGB2YUV444_128Transformer(data_format='CHW')
# layout为NHWC时,做RGB转成 YUV444_128
RGB2YUV444_128Transformer(data_format='HWC')
BGR2YUVBT601VIDEOTransformer
说明:
将输入格式由BGR转成YUV_BT601_Video_Range的操作。
YUV_BT601_Video_Range,某些摄像头输入数据都是YUV BT601(Video Range)格式的,取值范围为16~235,该transformer就是适配这种格式的数据产生的。
参数:
- data_format:输入的layout类型,取值范围为["CHW","HWC"],默认值为"CHW",此项为必填项。
使用举例:
# layout为 NCHW时,做BGR转成YUV_BT601_Video_Range
BGR2YUVBT601VIDEOTransformer(data_format='CHW')
# layout为NHWC时,做BGR转成YUV_BT601_Video_Range
BGR2YUVBT601VIDEOTransformer(data_format='HWC')
RGB2YUVBT601VIDEOTransformer
说明:
将输入格式由RGB转成YUV_BT601_Video_Range的操作。
YUV_BT601_Video_Range,某些摄像头输入数据都是YUV BT601(Video Range)格式的,取值范围为16~235,该transformer就是适配这种格式的数据产生的。
参数:
- data_format:输入的layout类型,取值范围为["CHW","HWC"],默认值为"CHW",此项为必填项。
使用举例:
# layout为NCHW时,做RGB转成YUV_BT601_Video_Range
RGB2YUVBT601VIDEOTransformer(data_format='CHW')
# layout为NHWC时,做RGB转成YUV_BT601_Video_Range
RGB2YUVBT601VIDEOTransformer(data_format='HWC')
YUVTransformer
说明:
将输入格式转成YUV444的操作。
参数:
- color_sequence:颜色序列,此项为必填项。
使用举例:
# 将BGR读入的图片转为YUV444
YUVTransformer(color_sequence="BGR")
# 将RGB读入的图片转为YUV444
YUVTransformer(color_sequence="RGB")
ReduceChannelTransformer
说明:
将C通道缩减为单通道的操作。该transformer主要是针对于C通道,如shape为13224224 改为11224224。 使用时layout一定要和data_format值对齐,避免造成删错通道。
参数:
- data_format:输入的layout类型,取值范围为["CHW", "HWC"],默认值为"CHW"。
使用举例:
# 删除layout为NCHW的C通道
ReduceChannelTransformer()
# 或者
ReduceChannelTransformer(data_format="CHW")
# 删除layout为NHWC的C通道
ReduceChannelTransformer(data_format="HWC")
BGR2NV12Transformer
说明:
将输入格式由BGR转成NV12的操作。
参数:
-
data_format:输入的layout类型,取值范围为["CHW","HWC"],默认值为"CHW"。
-
cvt_mode:cvt模式,取值范围为(rgb_calc,opencv),默认值为rgb_calc。
-
rgb_calc��,采用mergeUV的方式处理图片;
-
opencv,采用opencv的方式处理图片。
-
使用举例:
# layout为NCHW时,由BGR转为NV12,采用rgb_calc模式处理图片
BGR2NV12Transformer()
# 或者
BGR2NV12Transformer(data_format="CHW")
# layout为NHWC时,由BGR转为NV12,采用opencv模式处理图片
BGR2NV12Transformer(data_format="HWC", cvt_mode="opencv")
RGB2NV12Transformer
说明:
将输入格式由RGB转成NV12的操作。
参数:
-
data_format:输入的 layout 类型,取值范围 ["CHW", "HWC"], 默认值为"CHW"。
-
cvt_mode:cvt模式,��取值范围为(rgb_calc,opencv),默认值为rgb_calc。
-
rgb_calc,采用mergeUV的方式处理图片;
-
opencv,采用opencv的方式处理图片。
-
使用举例:
# layout为NCHW时,有RGB转为NV12,采用rgb_calc模式处理图片
RGB2NV12Transformer()
# 或者
RGB2NV12Transformer(data_format="CHW")
# layout为NHWC时,有RGB转为NV12,采用opencv模式处理图片
RGB2NV12Transformer(data_format="HWC", cvt_mode="opencv")
NV12ToYUV444Transformer
说明:
将输入格式由NV12转成YUV444的操作。
参数:
- target_size:目标大小,值为元组,如(240,240)。
- yuv444_output_layout:yuv444输出的layout,取值范围为(HWC,CHW),默认值为"HWC"。
使用举例:
# layout为NCHW ,大小为768*768, nv12转yuv444
NV12ToYUV444Transformer(target_size=(768, 768))
# layout为NHWC ,大小为224*224, nv12转yuv444
NV12ToYUV444Transformer((224, 224), yuv444_output_layout="HWC")
WarpAffineTransformer
说明:
用于做图像仿射变换的操作。
参数:
-
input_shape:输入的shape值。
-
scale:乘以的系数。
使用举例:
# 大小为512*512,长边长度为1.0
WarpAffineTransformer((512, 512), 1.0)
F32ToS8Transformer
说明:
用于做输入格式从float32转换为int8的操作。
参数:不涉及。
使用举例:
# 输入格式从 float32转为 int8
F32ToS8Transformer()
F32ToU8Transformer
说明:
用于做输入格式从float32转换为uint8的操作。
参数:不涉及。
使用举例:
# 输入格式从 float32 转为 uint8
F32ToU8Transformer()
示例YOLOv5x模型使用说明
- YOLOv5x模型:
-
可以从URL:yolov5-2.0 中下载相应的pt文件。
在clone代码时,请确认您使用的Tags是
v2.0,否则将导致转换失败。 -
md5sum码:
| md5sum | File |
|---|---|
| 2e296b5e31bf1e1b6b8ea4bf36153ea5 | yolov5l.pt |
| 16150e35f707a2f07e7528b89c032308 | yolov5m.pt |
| 42c681cf466c549ff5ecfe86bcc491a0 | yolov5s.pt |
| 069a6baa2a741dec8a2d44a9083b6d6e | yolov5x.pt |
- 为了更好地适配后处理代码,我们在ONNX模型导出前对Github代码做了如下修改 (代码参见:https://github.com/ultralytics/yolov5/blob/v2.0/models/yolo.py ):
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
x[i] = x[i].permute(0, 2, 3, 1).contiguous()
-
说明: 去除了每个输出分支尾部从4维到5维的reshape(即不将channel从255拆分成3x85),然后将layout从NHWC转换成NCHW再输出。
以下左图为修改前的模型某一输出节点的可视化图,右图则为修改后的对应输出节点可视化图。
-
下载完成后通过脚本 https://github.com/ultralytics/yolov5/blob/v2.0/models/export.py 进行pt文件到ONNX文件的转换。
-
注意事项
在使用export.py脚本时,请注意:
- 由于D-Robotics AI工具链支持的ONNX opset版本为
10和11,请将torch.onnx.export的opset_version参数根据您要使用的版本进行修改。 - 将
torch.onnx.export部分的默认输入名称参数由'images'改为'data',与模型转换示例包的YOLOv5x示例脚本保持一致。 - 将
parser.add_argument部分中默认的数据输入尺寸640x640改为模型转换示例包YOLOv5x示例中的672x672。
- 由于D-Robotics AI工具链支持的ONNX opset版本为
模型精度调优checklist
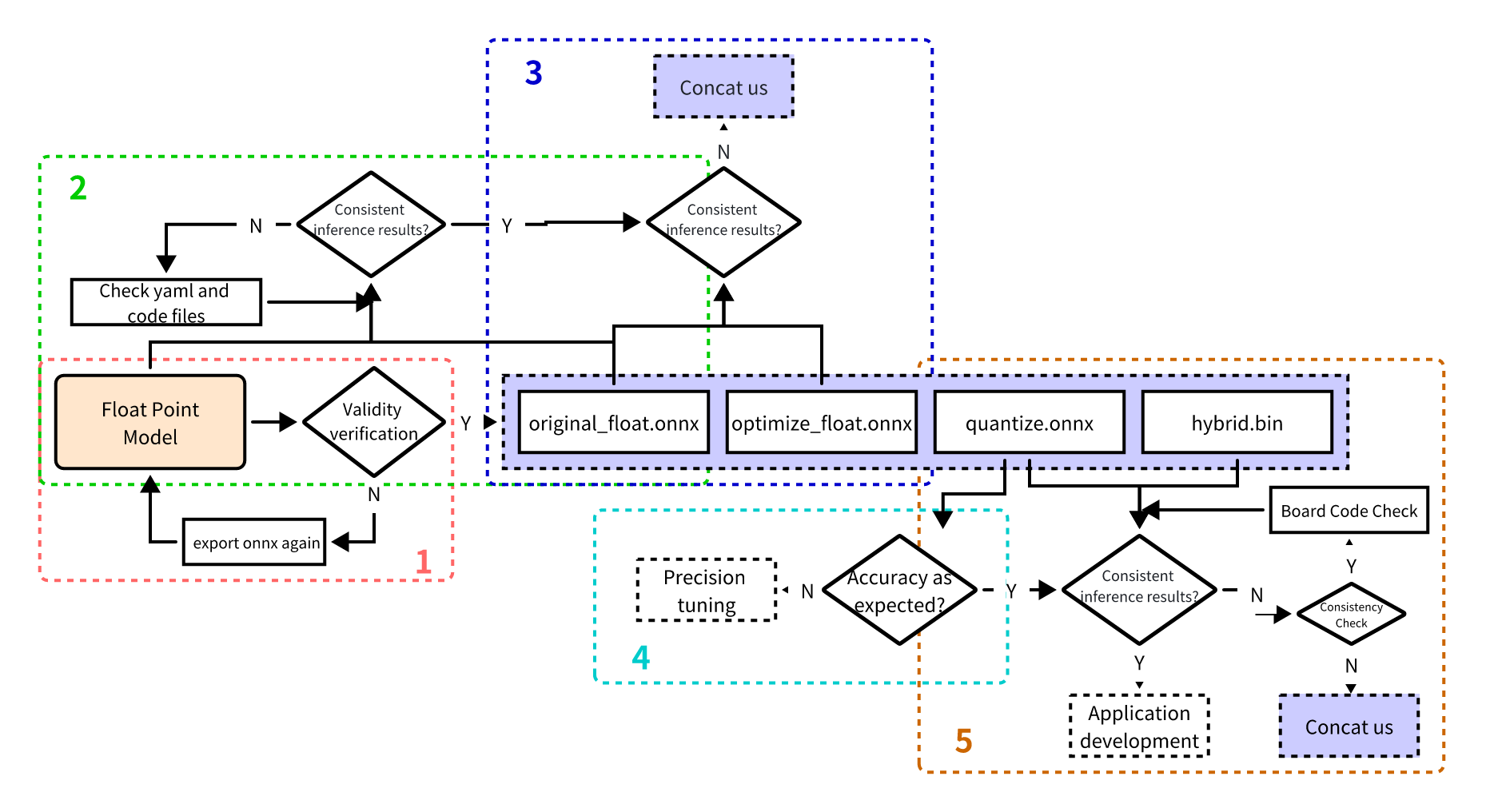
请严格按照��下图中步骤1-5来进行模型精度验证并保留每个步骤的代码和结果:
在进行排查前,请确认当前模型转换所用的Docker镜像或转换环境版本,并保留版本信息
1. 验证浮点onnx模型的推理结果
进入模型转换环境,来测试浮点onnx模型(特指从DL框架导出的onnx模型)的单张结果,此步骤结果应与训练后的模型推理结果完全一致(nv12格式除外,可能会引入少许差异)
可参考如下示例代码步骤,来确认浮点onnx模型的推理的步骤、数据预处理、后处理代码是否正确!
from horizon_tc_ui import HB_ONNXRuntime
import numpy as np
import cv2
def preprocess(input_name):
# BGR->RGB、Resize、CenterCrop···
# HWC->CHW
# normalization
return data
def main():
# 加载模型文件
sess = HB_ONNXRuntime(model_file=MODEL_PATH)
# 获取输入&输出节点名称
input_names = [input.name for input in sess.get_inputs()]
output_names = [output.name for output in sess.get_outputs()]
# 准备模型输入数据
feed_dict = dict()
for input_name in input_names:
feed_dict[input_name] = preprocess(input_name)
# 原始浮点onnx,数据dtype=float32
outputs = sess.run_feature(output_names, feed_dict, input_offset=0)
# 后处理
postprocess(outputs)
if __name__ == '__main__':
main()
2. 验证yaml配置文件以及前、后处理代码的正确性
测试 original_float.onnx 模型的单张结果,应与浮点onnx模型推理结果完全一致(nv12格式除外,由于nv12数据本身有损,可能会引入少许差异)
使用开源工具 Netron 打开 original_float.onnx 模型,并查看预处理节点 HzPreprocess 算子的详细属性,获取我们 数据预处理 需要的参数:data_format 和 input_type。
由于HzPreprocess节点的存在,会使得转换后的模型其预处理操作可能会和原始模型有所不同,该算子是在进行模型转换时,根据yaml配置文件中的配置参数(input_type_rt、input_type_train以及norm_type、mean_value、scale_value)来决定是否为模型加入HzPreprocess节点,预处理节点的生成细节,请参考PTQ原理及步骤详解章节的 norm_type 配置参数说明 内容,另外预处理节点会出现在转换过程产生的所有产物中。
理想状态下,这个HzPreprocess节点应该完成 input_type_rt 到 input_type_train 的完整转换, 但实际情况是整个type转换过程需要使用D-Robotics AI芯片硬件完成,但ONNX模型里面并没有包含硬件转换的部分,因此ONNX的真实输入类型会使用一种中间类型,这种中间类型就是硬件对 input_type_rt 的处理结果类型, 故针对图像输入数据类型为:RGB/BGR/NV12/YUV444/GRAY,并且数据dtype= uint8的模型时,在预处理代码中需要做 -128 的操作,featuremap 数据类型因为使用的是float32,因此预处理代码中 不需要-128 的操作; original_float.onnx的数据layout(NCHW/NHWC)会保持和原始浮点模型的输入layout一致。
可参考如下示例代码步骤,来确认 original_float.onnx 模型的推理的步骤、数据预处理、后处理代码是否正确!
数据预处理部分建议参考使用D-Robotics 模型转换 horizon_model_convert_sample 示例包中的caffe、onnx等示例模型的预处理步骤方法
from horizon_tc_ui import HB_ONNXRuntime
import numpy as np
import cv2
def preprocess(input_name):
# BGR->RGB、Resize、CenterCrop···
# HWC->CHW(通过onnx模型输入节点的具体shape来判断是否需要做layout转换)
# normalization(若已通过yaml文件将norm操作放入了模型中,则不要在预处理中做重复操作)
#-128(图像输入模型,仅在使用hb_session.run接口时需要自行在预处理完成-128,其他接口通过input_offset控制即可)
return data
def main():
# 加载模型文件
sess = HB_ONNXRuntime(model_file=MODEL_PATH)
# 获取输入&输出节点名称
input_names = [input.name for input in sess.get_inputs()]
output_names = [output.name for output in sess.get_outputs()]
# 准备模型输入数据
feed_dict = dict()
for input_name in input_names:
feed_dict[input_name] = preprocess(input_name)
#图像输入的模型(RGB/BGR/NV12/YUV444/GRAY),数据dtype= uint8
outputs = sess.run(output_names, feed_dict, input_offset=128)
# featuremap模型,数据dtype=float32, 若模型输入非featuremap,请注释掉下行代码!
outputs = sess.run_feature(output_names, feed_dict, input_offset=0)
# 后处理
postprocess(outputs)
if __name__ == '__main__':
main()
3. 验证模型的图优化阶段未引入精度误差
测试 optimize_float.onnx 模型的单张结果,应与original_float.onnx推理结果完全一致
使用开源工具 Netron 打开 optimize_float.onnx 模型,并查看预处理节点 HzPreprocess 算子的详细属性,获取我们数据预处理需要的参数:data_format和 input_type;
optimize_float.onnx模型的推理可参考如下示例代码步骤,来确认 optimize_float.onnx 模型的推理的步骤、数据预处理、后处理代码是否正确!
数据预处理部分建议参考使用D-Robotics 模型转换 horizon_model_convert_sample 示例包中的caffe、onnx等示例模型的预处理步骤方法
from horizon_tc_ui import HB_ONNXRuntime
import numpy as np
import cv2
def preprocess(input_name):
# BGR->RGB、Resize、CenterCrop···
# HWC->CHW(通过onnx模型输入节点的具体shape来判断是否需要做layout转换)
# normalization(若已通过yaml文件将norm操作放入了模型中,则不要在预处理中做重复操作)
#-128(图像输入模型,仅在使用hb_session.run接口时需要自行在预处理完成-128,其他接口通过input_offset控制即可)
return data
def main():
# 加载模型文件
sess = HB_ONNXRuntime(model_file=MODEL_PATH)
# 获取输入&输出节点名称
input_names = [input.name for input in sess.get_inputs()]
output_names = [output.name for output in sess.get_outputs()]
# 准备模型输入数据
feed_dict = dict()
for input_name in input_names:
feed_dict[input_name] = preprocess(input_name)
#图像输入的模型(RGB/BGR/NV12/YUV444/GRAY),数据dtype= uint8
outputs = sess.run(output_names, feed_dict, input_offset=128)
# featuremap模型,数据dtype=float32, 若模型输入非featuremap,请注释掉下行代码!
outputs = sess.run_feature(output_names, feed_dict, input_offset=0)
# 后处理
postprocess(outputs)
if __name__ == '__main__':
main()
4. 验证量化精度是否满足预期
测试quantized.onnx的精度指标。
使用开源工具 Netron 打开 quantized.onnx 模型,并查看预处理节点 HzPreprocess 算子的详细属性,获取我们数据预处理需要的参数:data_format和 input_type;
quantized.onnx模型的推理可参考如下示例代码步骤,来确认 quantized.onnx 模型的推理的步骤、数据预处理、后处理代码是否正确!
数据预处理部分建议参考使用D-Robotics 模��型转换 horizon_model_convert_sample 示例包中的caffe、onnx等示例模型的预处理步骤方法
from horizon_tc_ui import HB_ONNXRuntime
import numpy as np
import cv2
def preprocess(input_name):
# BGR->RGB、Resize、CenterCrop···
# HWC->CHW(通过onnx模型输入节点的具体shape来判断是否需要做layout转换)
# normalization(若已通过yaml文件将norm操作放入了模型中,则不要在预处理中做重复操作)
#-128(图像输入模型,仅在使用hb_session.run接口时需要自行在预处理完成-128,其他接口通过input_offset控制即可)
return data
def main():
# 加载模型文件
sess = HB_ONNXRuntime(model_file=MODEL_PATH)
# 获取输入&输出节点名称
input_names = [input.name for input in sess.get_inputs()]
output_names = [output.name for output in sess.get_outputs()]
# 准备模型输入数据
feed_dict = dict()
for input_name in input_names:
feed_dict[input_name] = preprocess(input_name)
#图像输入的模型(RGB/BGR/NV12/YUV444/GRAY),数据dtype= uint8
outputs = sess.run(output_names, feed_dict, input_offset=128)
# featuremap模型,数据dtype=float32, 若模型输入非featuremap,请注释掉下行代码!
outputs = sess.run_feature(output_names, feed_dict, input_offset=0)
# 后处理
postprocess(outputs)
if __name__ == '__main__':
main()
5. 确保模型编译过程无误且板端推理代码正确
使用 hb_model_verifier 工具验证quantized.onnx和.bin的一致性,模型输出应至少满足小数点后2-3位对齐
hb_model_verifier工具(详细介绍可参考)的使用方法,请参考PTQ原理及步骤详解章节的 hb_model_verifier 工具 内容。
若模型一致性校验通过,则请仔细检查开发板端的前、后处理代码!
若quantized.onnx与.bin模型一致性校验失败,请联系D-Robotics 技术人员
模型量化yaml配置文件模板
RDK X3 Caffe模型量化yaml文件模板
请新建 caffe_config.yaml 文件,并直接拷贝以下内容,然后只需填写标记为 必选参数 的参数即可进行模型转换,若需了解更多参数的使用说明,可参考 yaml配置文件详解 章节内容。
# Copyright (c) 2020 D-Robotics.All Rights Reserved.
# 模型转化相关的参数
model_parameters:
# 必选参数
# Caffe浮点网络数据模型文件, 例如:caffe_model: './horizon_x3_caffe.caffemodel'
caffe_model: ''
# 必选参数
# Caffe网络描述文件, 例如:prototxt: './horizon_x3_caffe.prototxt'
prototxt: ''
march: "bernoulli2"
layer_out_dump: False
working_dir: 'model_output'
output_model_file_prefix: 'horizon_x3'
# 模型输入相关参数
input_parameters:
input_name: ""
input_shape: ''
input_type_rt: 'nv12'
input_layout_rt: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据类型,可选的值为rgb/bgr/gray/featuremap/yuv444, 例如:input_type_train: 'bgr'
input_type_train: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据排布, 可选值为 NHWC/NCHW, 例如:input_layout_train: 'NHWC'
input_layout_train: ''
#input_batch: 1
# 必选参数
# 原始浮点模型训练框架中所使用数据预处理方法,可配置:no_preprocess/data_mean/data_scale/data_mean_and_scale
# no_preprocess 不做任何操作,对应的 mean_value 或者 scale_value 均无需配置
# data_mean 减去通道均值mean_value,对应的 mean_value 需要配置,并注释掉scale_value
# data_scale 对图像像素乘以data_scale系数,对应的 scale_value需要配置,并注释掉mean_value
# data_mean_and_scale 减去通道均值后再乘以scale系数,标识下方对应的 mean_value 和 scale_value 均需配置
norm_type: ''
# 必选参数
# 图像减去的均值, 如果是通道均值,value之间必须用空格分隔
# 例如:mean_value: 128.0 或者 mean_value: 111.0 109.0 118.0
mean_value:
# 必选参数
# 图像预处理缩放比例,如果是通道缩放比例,value之间必须用空格分隔,计算公式:scale = 1/std
# 例如:scale_value: 0.0078125 或者 scale_value: 0.0078125 0.001215 0.003680
scale_value:
# 模型量化相关参数
calibration_parameters:
# 必选参数
# 模型量化的参考图像的存放目录,图片格式支持Jpeg、Bmp等格式,图片来源一般是从测试集中选择100张图片,并要覆盖典型场景,不要是偏僻场景,如过曝光、饱和、模糊、纯黑、纯白等图片
# 请根据 02_preprocess.sh 脚本中的文件夹路径来配置,例如:cal_data_dir: './calibration_data_yuv_f32'
cal_data_dir: ''
cal_data_type: 'float32'
calibration_type: 'default'
# max_percentile: 0.99996
# 编译器相关参数
compiler_parameters:
compile_mode: 'latency'
debug: False
# core_num: 2
optimize_level: 'O3'
RDK X3 ONNX模型量化yaml文件模板
请新建 onnx_config.yaml 文件,并直接拷贝以下内容,然后只需填写标记为 必选参数 的参数即可进行模型转换,若需了解更多参数的使用说明,可参考 yaml配置文件详解章节内容。
# Copyright (c) 2020 D-Robotics.All Rights Reserved.
# 模型转化相关的参数
model_parameters:
# 必选参数
# Onnx浮点网络数据模型文件, 例如:onnx_model: './horizon_x3_onnx.onnx'
onnx_model: ''
march: "bernoulli2"
layer_out_dump: False
working_dir: 'model_output'
output_model_file_prefix: 'horizon_x3'
# 模型输入相关参数
input_parameters:
input_name: ""
input_shape: ''
input_type_rt: 'nv12'
input_layout_rt: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据类型,可选的值为rgb/bgr/gray/featuremap/yuv444, 例如:input_type_train: 'bgr'
input_type_train: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据排布, 可选值为 NHWC/NCHW, 例如:input_layout_train: 'NHWC'
input_layout_train: ''
#input_batch: 1
# 必选参数
# 原始浮点模型训练框架中所使用数据预处理方法,可配置:no_preprocess/data_mean/data_scale/data_mean_and_scale
# no_preprocess 不做任何操作,对应的 mean_value 或者 scale_value 均无需配置
# data_mean 减去通道均值mean_value,对应的 mean_value 需要配置,并注释掉scale_value
# data_scale 对图像像素乘以data_scale系数,对应的 scale_value需要配置,并注释掉mean_value
# data_mean_and_scale 减去通道均值后再乘以scale系数,标识下方对应的 mean_value 和 scale_value 均需配置
norm_type: ''
# 必选参数
# 图像减去的均值, 如果是通道均值,value之间必须用空格分隔
# 例如:mean_value: 128.0 或者 mean_value: 111.0 109.0 118.0
mean_value:
# 必选参数
# 图像预处理缩放比例,如果是通道缩放比例,value之间必须用空格分隔,计算公式:scale = 1/std
# 例如:scale_value: 0.0078125 或者 scale_value: 0.0078125 0.001215 0.003680
scale_value:
# 模型量化相关参数
calibration_parameters:
# 必选参数
# 模型量化的参考图像的存放目录,图片格式支持Jpeg、Bmp等格式,图片来源一般是从测试集中选择100张图片,并要覆盖典型场景,不要是偏僻场景,如过曝光、饱和、模糊、纯黑、纯白等图片
# 请根据 02_preprocess.sh 脚本中的文件夹路径来配置,例如:cal_data_dir: './calibration_data_yuv_f32'
cal_data_dir: ''
cal_data_type: 'float32'
calibration_type: 'default'
# max_percentile: 0.99996
# 编译器相关参数
compiler_parameters:
compile_mode: 'latency'
debug: False
# core_num: 2
optimize_level: 'O3'
RDK Ultra Caffe模型量化yaml文件模板
请新建 caffe_config.yaml 文件,并直接拷贝以下内容,然后只需填写标记为 必选参数 的参数即可进行模型转换,若需了解更多参数的使用说明,可参考 yaml配置文件详解 章节内容。
# Copyright (c) 2020 D-Robotics.All Rights Reserved.
# 模型转化相关的参数
model_parameters:
# 必选参数
# Caffe浮点网络数据模型文件, 例如:caffe_model: './horizon_ultra_caffe.caffemodel'
caffe_model: ''
# 必选参数
# Caffe网络描述文件, 例如:prototxt: './horizon_ultra_caffe.prototxt'
prototxt: ''
march: "bayes"
layer_out_dump: False
working_dir: 'model_output'
output_model_file_prefix: 'horizon_ultra'
# 模型输入相关参数
input_parameters:
input_name: ""
input_shape: ''
input_type_rt: 'nv12'
input_layout_rt: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据类型,可选的值为rgb/bgr/gray/featuremap/yuv444, 例如:input_type_train: 'bgr'
input_type_train: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据排布, 可选值为 NHWC/NCHW, 例如:input_layout_train: 'NHWC'
input_layout_train: ''
#input_batch: 1
# 必选参数
# 原始浮点模型训练框架中所使用数据预处理方法,可配置:no_preprocess/data_mean/data_scale/data_mean_and_scale
# no_preprocess 不做任何操作,对应的 mean_value 或者 scale_value 均无需配置
# data_mean 减去通道均值mean_value,对应的 mean_value 需要配置,并注释掉scale_value
# data_scale 对图像像素乘以data_scale系数,对应的 scale_value需要配置,并注释掉mean_value
# data_mean_and_scale 减去通道均值后再乘以scale系数,标识下方对应的 mean_value 和 scale_value 均需配置
norm_type: ''
# 必选参数
# 图像减去的均值, 如果是通道均值,value之间必须用空格分隔
# 例如:mean_value: 128.0 或者 mean_value: 111.0 109.0 118.0
mean_value:
# 必选参数
# 图像预处理缩放比例,如果是通道缩放比例,value之间必须用空格分隔,计算公式:scale = 1/std
# 例如:scale_value: 0.0078125 或者 scale_value: 0.0078125 0.001215 0.003680
scale_value:
# 模型量化相关参数
calibration_parameters:
# 必选参数
# 模型量化的参考图像的存放目录,图片格式支持Jpeg、Bmp等格式,图片来源一般是从测试集中选择100张图片,并要覆盖典型场景,不要是偏僻场景,如过曝光、饱和、模糊、纯黑、纯白等图片
# 请根据 02_preprocess.sh 脚本中的文件夹路径来配置,例如:cal_data_dir: './calibration_data_yuv_f32'
cal_data_dir: ''
cal_data_type: 'float32'
calibration_type: 'default'
# max_percentile: 0.99996
# 编译器相关参数
compiler_parameters:
compile_mode: 'latency'
debug: False
# core_num: 2
optimize_level: 'O3'
RDK Ultra ONNX模型量化yaml文件模板
请新建 onnx_config.yaml 文件,并直接拷贝以下内容,然后只需填写标记为 必选参数 的参数即可进行模型转换,若需了解更多�参数的使用说明,可参考 yaml配置文件详解 章节内容。
# Copyright (c) 2020 D-Robotics.All Rights Reserved.
# 模型转化相关的参数
model_parameters:
# 必选参数
# Onnx浮点网络数据模型文件, 例如�:onnx_model: './horizon_ultra_onnx.onnx'
onnx_model: ''
march: "bayes"
layer_out_dump: False
working_dir: 'model_output'
output_model_file_prefix: 'horizon_ultra'
# 模型输入相关参数
input_parameters:
input_name: ""
input_shape: ''
input_type_rt: 'nv12'
input_layout_rt: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据类型,可选的值为rgb/bgr/gray/featuremap/yuv444, 例如:input_type_train: 'bgr'
input_type_train: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据排布, 可选值为 NHWC/NCHW, 例如:input_layout_train: 'NHWC'
input_layout_train: ''
#input_batch: 1
# 必选参数
# 原始浮点模型训练框架中所使用数据预处理方法,可配置:no_preprocess/data_mean/data_scale/data_mean_and_scale
# no_preprocess 不做任何操作,对应的 mean_value 或者 scale_value 均无需配置
# data_mean 减去通道均值mean_value,对应的 mean_value 需要配置,并注释掉scale_value
# data_scale 对图像像素乘以data_scale系数,对应的 scale_value需要配置,并注释掉mean_value
# data_mean_and_scale 减去通道均值后再乘以scale系数,标识下方对应的 mean_value 和 scale_value 均需配置
norm_type: ''
# 必选参数
# 图像减去的均值, 如果是通道均值,value之间必须用空格分隔
# 例如:mean_value: 128.0 或者 mean_value: 111.0 109.0 118.0
mean_value:
# 必选参数
# 图像预处理缩放比例,如果是通道缩放比例,value之间必须用空格分隔,计算公式:scale = 1/std
# 例如:scale_value: 0.0078125 或者 scale_value: 0.0078125 0.001215 0.003680
scale_value:
# 模型量化相关参数
calibration_parameters:
# 必选参数
# 模型量化的参考图像的存放目录,图片格式支持Jpeg、Bmp等格式,图片来源一般是从测试集中选择100张图片,并要覆盖典型场景,不要是偏僻场景,如过曝光、饱和、模糊、纯黑、纯白等图片
# 请根据 02_preprocess.sh 脚本中的文件夹路径来配置,例如:cal_data_dir: './calibration_data_yuv_f32'
cal_data_dir: ''
cal_data_type: 'float32'
calibration_type: 'default'
# max_percentile: 0.99996
# 编译器相关参数
compiler_parameters:
compile_mode: 'latency'
debug: False
# core_num: 2
optimize_level: 'O3'
RDK X5 Caffe模型量化yaml文件模板
请新建 caffe_config.yaml 文件,并直接拷贝以下内容,然后只需填写标记为 必选参数 的参数即可进行模型转换,若需了解更多参数的使用说明,可参考 yaml配置文件详解章节内容。
# Copyright (c) 2020 D-Robotics.All Rights Reserved.
# 模型转化相关的参数
model_parameters:
# 必选参数
# Caffe浮点网络数据模型文件, 例如:caffe_model: './horizon_ultra_caffe.caffemodel'
caffe_model: ''
# 必选参数
# Caffe网络描述文件, 例如:prototxt: './horizon_ultra_caffe.prototxt'
prototxt: ''
march: "bayes-e"
layer_out_dump: False
working_dir: 'model_output'
output_model_file_prefix: 'horizon_x5'
# 模型输入相关参数
input_parameters:
input_name: ""
input_shape: ''
input_type_rt: 'nv12'
input_layout_rt: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据类型,可选的值为rgb/bgr/gray/featuremap/yuv444, 例如:input_type_train: 'bgr'
input_type_train: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据排布, 可选值为 NHWC/NCHW, 例如:input_layout_train: 'NHWC'
input_layout_train: ''
#input_batch: 1
# 必选参数
# 原始浮点模型训练框架中所使用数据预处理方法,可配置:no_preprocess/data_mean/data_scale/data_mean_and_scale
# no_preprocess 不做任何操作,对应的 mean_value 或者 scale_value 均无需配置
# data_mean 减去通道均值mean_value,对应的 mean_value 需要配置,并注释掉scale_value
# data_scale 对图像像素乘以data_scale系数,对应的 scale_value需要配置,并注释掉mean_value
# data_mean_and_scale 减去通道均值后再乘以scale系数,标识下方对应的 mean_value 和 scale_value 均需配置
norm_type: ''
# 必选参数
# 图像减去的均值, 如果是通道均值,value之间必须用空格分隔
# 例如:mean_value: 128.0 或者 mean_value: 111.0 109.0 118.0
mean_value:
# 必选参数
# 图像预处理缩放比例,如果是通道缩放比例,value之间必须用空格分隔,计算公式:scale = 1/std
# 例如:scale_value: 0.0078125 或者 scale_value: 0.0078125 0.001215 0.003680
scale_value:
# 模型量化相关参数
calibration_parameters:
# 必选参数
# 模型量化的参考图像的存放目录,图片格式支持Jpeg、Bmp等格式,图片来源一般是从测试集中选择100张图片,并要覆盖典型场景,不要是偏僻场景,如过曝光、饱和、模糊、纯黑、纯白等图片
# 请根据 02_preprocess.sh 脚本中的文件夹路径来配置,例如:cal_data_dir: './calibration_data_yuv_f32'
cal_data_dir: ''
cal_data_type: 'float32'
calibration_type: 'default'
# max_percentile: 0.99996
# 编译器相关参数
compiler_parameters:
compile_mode: 'latency'
debug: False
# core_num: 2
optimize_level: 'O3'
RDK X5 ONNX模型量化yaml文件模板
请新建 onnx_config.yaml 文件,并直接拷贝以下内容,然后只需填写标记为 必选参数 的参数即可进行模型转换,若需了解更多参数的使用说明,可参考 yaml配置文件详解 章节内容。
# Copyright (c) 2020 D-Robotics.All Rights Reserved.
# 模型转化相关的参数
model_parameters:
# 必选参数
# Onnx浮点网络数据模型文件, 例如:onnx_model: './horizon_ultra_onnx.onnx'
onnx_model: ''
march: "bayes-e"
layer_out_dump: False
working_dir: 'model_output'
output_model_file_prefix: 'horizon_x5'
# 模型输入相关参数
input_parameters:
input_name: ""
input_shape: ''
input_type_rt: 'nv12'
input_layout_rt: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据类型,可选的值为rgb/bgr/gray/featuremap/yuv444, 例如:input_type_train: 'bgr'
input_type_train: ''
# 必选参数
# 原始浮点模型训练框架中所使用训练的数据排布, 可选值为 NHWC/NCHW, 例如:input_layout_train: 'NHWC'
input_layout_train: ''
#input_batch: 1
# 必选参数
# 原始浮点模型训练框架中所使用数据预处理方法,可配置:no_preprocess/data_mean/data_scale/data_mean_and_scale
# no_preprocess 不做任何操作,对应的 mean_value 或者 scale_value 均无需配置
# data_mean 减去通道均值mean_value,对应的 mean_value 需要配置,并注释掉scale_value
# data_scale 对图像像素乘以data_scale系数,对应的 scale_value需要配置,并注释掉mean_value
# data_mean_and_scale 减去通道均值后再乘以scale系数,标识下方对应的 mean_value 和 scale_value 均需配置
norm_type: ''
# 必选参数
# 图像减去的均值, 如果是通道均值,value之间必须用空格分隔
# 例如:mean_value: 128.0 或者 mean_value: 111.0 109.0 118.0
mean_value:
# 必选参数
# 图像预处理缩放比例,如果是通道缩放比例,value之间必须用空格分隔,计算公式:scale = 1/std
# 例如:scale_value: 0.0078125 或者 scale_value: 0.0078125 0.001215 0.003680
scale_value:
# 模型量化相关参数
calibration_parameters:
# 必选参数
# 模型量化的参考图像的存放目录,图片格式支持Jpeg、Bmp等格式,图片来源一般是从测试集中选择100张图片,并要覆盖典型场景,不要是偏僻场景,如过曝光、饱和、模糊、纯黑、纯白等图片
# 请根据 02_preprocess.sh 脚本中的文件夹路径来配置,例如:cal_data_dir: './calibration_data_yuv_f32'
cal_data_dir: ''
cal_data_type: 'float32'
calibration_type: 'default'
# max_percentile: 0.99996
# 编译器相关参数
compiler_parameters:
compile_mode: 'latency'
debug: False
# core_num: 2
optimize_level: 'O3'
X3多核BPU使用说明
因X3中有2颗BPU核,所以在BPU使用中存在单核模型和双核模型的情况,多核BPU的使用注意事项参考文档:X3多核BPU的合理使用技巧与建议
定点.bin模型上板多batch使用说明
-
1.模型转换时,在yaml配置文件里通过input_batch配置batch_size;
-
2.上板bin模型输入时,以原始模型维度1×3×224×224,修改input_batch为10,也就是10×3×224×224这个维度举例:
-
准备数据:
Image图像数据:设置
aligned_shape = valid_shape,��然后按单张数据准备的方式,把10张图片依次按顺序写入申请的内存空间;FeatureMap数据:按aligned_shape把数据padding好,然后按单batch数据准备的方式,把10份数据依次按顺序写入申请的内存空间,模型推理流程和单batch模型推理流程一致;