8.5 Algorithm toolchain class
For toolchain issues, we recommend using the latest version first. For related download resources, please refer to: Download Resources Summary
This section addresses frequently asked questions related to AI model deployment, algorithm development, and toolchain usage on the Horizon RDK platform.
Q1: What information should I provide when seeking technical support for toolchain issues?
A: To help technical support quickly identify and resolve your issue with the Horizon algorithm toolchain, please provide as much of the following information as possible:
- Target RDK hardware platform and processor architecture: For example, RDK X3 (BPU Bernoulli2), RDK Ultra (BPU Bayes), RDK X5 (BPU Bayes-e), Super100 (BPU Nash-e), Super100P (BPU Nash-m).
- Algorithm toolchain conversion environment information:
horizon_nnpackage version (check withpip list | grep horizon).- Python version (e.g., Py3.8, Py3.10).
- Toolchain Docker image version (if using Docker).
- Original model file: Provide your ONNX model file (or other original format model files).
- Model conversion related files:
- The
yamlconfiguration file used for conversion. - Complete
hb_mapper make_model_logor similar log files (e.g.,hb_mapper_makertbin_log_*.log). - The calibration dataset used for PTQ quantization (or its generation method and a few sample images).
- Board deployment related files:
- Code snippets or the complete project used for deployment on the board.
- Specific error messages and logs from runtime on the board.
- RDK board system version information (obtain via the
rdkos_infocommand).
- Detailed steps to reproduce the issue: Clearly describe the step-by-step process to reproduce your problem.
- Expected vs. actual behavior: Describe what you expected to happen and what actually occurred.
Note: Many common issues may exist in older toolchain versions and have been fixed in newer releases. It is recommended to always use the latest official Docker image and toolchain version.
- Docker image download and mounting references:
- For complex issues, it is recommended to share the complete conversion project, board deployment project, and detailed reproduction steps with technical support via cloud storage or similar means.
Q2: What official resources are recommended for AI algorithm development?
A:
- RDK User Manual - Algorithm Toolchain Section: The most fundamental and important reference, detailing toolchain installation, usage, features, and parameters.
- General entry: https://developer.d-robotics.cc/rdk_doc/04_toolchain_development (refer to the latest official documentation)
- RDK Model Zoo: Official model example repository, including various AI models ported, optimized, quantized, and deployed on the RDK platform, with code and tutorials.
- Horizon Developer Community - Resource Center: Aggregates various development resources, including toolchains, SDKs, sample code, technical documents, and tutorial videos.
- Community Resource Center: https://developer.d-robotics.cc/resource
Q3: What community algorithm resources and toolchain manuals are available for the RDK X3 platform?
A: For algorithm development on the RDK X3 platform, refer to the following OpenExplorer community resources:
- RDK X3 Algorithm Toolchain Community Manual (OpenExplorer): https://developer.d-robotics.cc/api/v1/fileData/horizon_xj3_open_explorer_cn_doc/index.html
- RDK X3 OpenExplore Product Release and Resources: https://developer.d-robotics.cc/forumDetail/136488103547258769
Q4: What community algorithm resources and toolchain manuals are available for the RDK Ultra platform?
A: For algorithm development on the RDK Ultra platform, refer to the following OpenExplorer community resources:
- RDK Ultra Algorithm Toolchain Community Manual (OpenExplorer): https://developer.d-robotics.cc/api/v1/fileData/horizon_j5_open_explorer_cn_doc/index.html
- RDK Ultra OpenExplore Product Release and Resources: https://developer.d-robotics.cc/forumDetail/118363912788935318
Q5: What community algorithm resources and toolchain manuals are available for the RDK X5 platform?
A: For algorithm development on the RDK X5 platform, refer to the following OpenExplorer community resources:
- RDK X5 Algorithm Toolchain Community Manual (OpenExplorer): https://developer.d-robotics.cc/api/v1/fileData/x5_doc-v126cn/index.html (check for the latest version)
- RDK X5 OpenExplore Product Release and Resources: https://developer.d-robotics.cc/forumDetail/251934919646096384
Q6: The algorithm toolchain Docker image is based on Ubuntu 20.04. Will this affect running the generated models (.bin or .hbm) on RDK boards with Ubuntu 22.04?
A: No, it will not affect it.
The Horizon OpenExplorer algorithm toolchain Docker image is mainly for providing an isolated environment with all necessary conversion tools and dependencies. The generated model files (e.g., .bin for PTQ, .hbm for QAT) are binary instructions and weights for the specific BPU architecture on the RDK board. These files are decoupled from the Ubuntu version on the board, as long as the runtime libraries (e.g., libdnn.so) on the board are compatible with the toolchain version used for conversion.
Q7: How do I deploy YOLO series models (e.g., YOLOv5, YOLOv8, YOLOv10) on the RDK platform?
A: Horizon provides comprehensive tutorials and examples for deploying YOLO series models on the RDK platform.
-
YOLOv5 on RDK X3:
- Full deployment tutorial: YOLOv5 Full Deployment on RDK X3
- YOLOv5s v2.0 training and conversion: For YOLOv5s tag 2.0, refer to the official toolchain getting started guide and this blog for training and conversion: YOLOv5s v2.0 Training and Conversion Blog
- Higher version YOLOv5 output layer modification: For higher versions (v5.0, v6.0, v7.0, etc.), you may need to modify the output layer to fit RDK BPU post-processing requirements. See: YOLOv5 Output Layer Modification Guide
- Board-side post-processing note: The post-processing in
/app/pydev_demo/07_yolov5_samplemay be directly copied from a specific training code version and is mainly for algorithm verification. For optimized deployment, refer to the RDK Model Zoo. - Real-time video detection (TROS deployment, 30fps): Deploy YOLOv5 with TROS at 30fps
-
YOLOv8 on RDK X3:
- Python multi-process 30fps reference: CSDN Blog - YOLOv8 RDK X3 Deployment
-
YOLOv10 on Bayes architecture platforms (RDK X5/Ultra):
- Python multi-thread 30fps reference: CSDN Blog - YOLOv10 Bayes Platform Deployment
-
General resource: Strongly recommended to check the RDK Model Zoo (https://github.com/D-Robotics/rdk_model_zoo), which contains official deployment examples, preprocessing/post-processing code, and optimization tips for various YOLO versions and other mainstream models.
Q8: When deploying YOLOv5, I get an error like can't reshape xxx in (84,84,3,85). How do I fix this?
A: This error is usually caused by a mismatch between the number of classes (num_classes) preset in the post-processing code and the actual number of classes in your trained/exported model.
For example, 85 typically means (x, y, w, h, confidence + num_classes). For COCO (80 classes), num_classes is 80, so 5 + 80 = 85. If your model is trained for 10 classes, it should be 5 + 10 = 15.
- Solution: Locate the YOLOv5 post-processing code (usually a Python script) and modify the class number parameter to match your model.
- Reference: The YOLOv5s v2.0 Training and Conversion Blog may also contain relevant instructions.
Q9: When deploying YOLOv5, I get a large number of irregular detection boxes. Why?
A: This is usually due to a mismatch between the ONNX model's output head structure and the board-side post-processing code.
- Possible cause 1: Output head not modified as required by BPU.
- Higher versions of YOLOv5 may export ONNX models with decoded detection heads or without separating the three feature maps.
- RDK BPU deployment usually requires the ONNX model to output raw feature maps, with the three feature maps as separate output nodes.
- Example images (top: incorrect, bottom: partially correct but still needs adjustment):
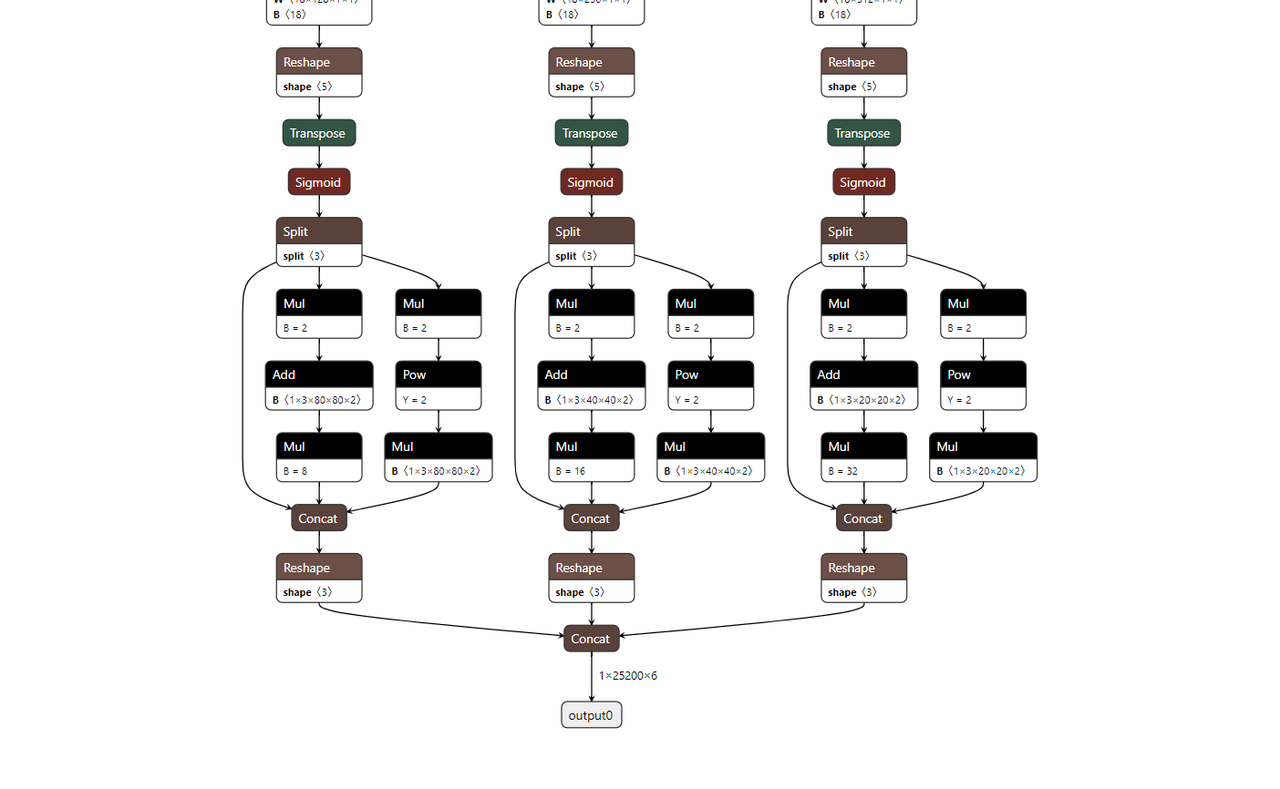
Top: feature maps not separated, includes decoding. Bottom: feature maps separated, but may have unnecessary Sigmoid or missing NHWC conversion.
- Solution:
- Modify the YOLOv5 export script (usually
models/yolo.py) to:- Remove detection heads (decoding layers, NMS, etc.).
- Output the three feature maps (P3, P4, P5 or equivalent) as separate output nodes.
- Ensure output dimension order matches toolchain requirements (e.g., sometimes convert NCHW to NHWC).
- Do not add unnecessary activation functions (e.g., Sigmoid) unless required by post-processing.
- Reference: YOLOv5 Output Layer Modification Guide
- Modify the YOLOv5 export script (usually
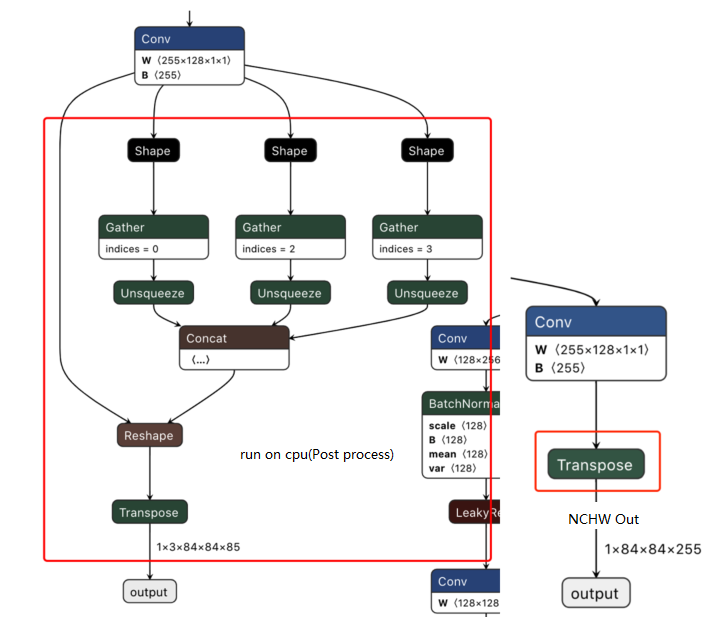
Q10: When deploying YOLOv5, detection boxes appear in a periodic pattern. Why?
A:
- Possible cause: Output dimensions do not match post-processing.
- If your YOLOv5 model outputs 5D tensors (e.g.,
[batch, num_anchors, grid_h, grid_w, (x,y,w,h,conf+classes)]or[batch, num_anchors*(5+num_classes), grid_h, grid_w]), the BPU toolchain may misinterpret dimensions, resulting in periodic detection boxes. - Example image:

- If your YOLOv5 model outputs 5D tensors (e.g.,
- Solution:
- When exporting the ONNX model, convert outputs to explicit 4D tensors (e.g., NHWC:
[batch, grid_h, grid_w, num_anchors*(5+num_classes)]), and ensure post-processing matches this format.
- When exporting the ONNX model, convert outputs to explicit 4D tensors (e.g., NHWC:
Q11: When deploying YOLOv5, detection boxes are offset from their correct positions. Why?
A:
- Mismatch between rendering size and original image size:
- Detection box coordinates are relative to the model input size (e.g., 640x640). If you render these coordinates on an image of a different size without scaling, boxes will be offset.
- Solution: Scale coordinates back to the original image size before rendering. If padding was used, remove its effect.
- Anchors mismatch:
- YOLOv5 decoding depends on preset anchors. If anchors used in post-processing differ from those used in training, box positions and sizes will be incorrect.
- Solution: Ensure anchors in post-processing exactly match those used during training.
Q12: When deploying YOLOv5, all detection boxes cluster in the top-left corner. Why?
A:
- Possible cause: Parameter passing issue in post-processing library (in some system versions).
- In RDK OS 3.0.0 and above,
/app/pydev_demo/07_yolov5_samplemay use a CPython-wrapped post-processing library. If key parameters (e.g., class number) are not correctly passed, decoding fails and boxes cluster in the top-left. - Example image:

- In RDK OS 3.0.0 and above,
- Solution:
- Recommended: Use post-processing from the RDK Model Zoo (https://github.com/D-Robotics/rdk_model_zoo), which is robust and optimized.
- If using onboard samples: Carefully check that all necessary parameters (class number, input resolution, anchors, thresholds, etc.) are correctly configured and passed.
Q13: When running /app/pydev_demo/07_yolov5_sample with my own model, I get a Segmentation fault. What should I do?
A:
- Reason: The onboard sample programs (like
07_yolov5_sample) are designed for the included.binmodel, with preprocessing, inference, and post-processing tailored for it. - If you replace the
.binfile with your own model without updating the code accordingly, data format mismatches or memory errors can cause segmentation faults. - Solution:
- Do not expect to run by simply replacing the bin file: For your own model, you must write or adapt the full inference pipeline (preprocessing, inference, post-processing).
- Refer to the RDK Model Zoo: For YOLOv5 and similar models, use the deployment examples in the RDK Model Zoo (https://github.com/D-Robotics/rdk_model_zoo).
- Understand post-processing: Study YOLOv5 post-processing (anchors decoding, confidence filtering, NMS, etc.) and ensure your code matches your model's output format.
Q14: If the model inference produces no results or results are far from expected, how should I troubleshoot (pipeline checklist)?
A: When model deployment yields poor or no results, systematically check the entire inference pipeline:
- Preprocessing check:
- Consistency with training: Ensure deployment preprocessing (resize, normalization, mean/std, color space, padding, etc.) matches training exactly.
- Visualize preprocessed data: Save and compare preprocessed images or arrays with training data.
- Toolchain
yamlconfig: Ensure preprocessing parameters in the toolchain'syamlfile correctly "cancel out" any preprocessing done before calibration data is fed in, so the toolchain sees data matching the model's first layer input distribution.
- Model conversion check:
- Toolchain version: Use the latest recommended toolchain.
yamlconfig: Double-check all parameters (input/output node names, data types, layouts, model type, BPU architecture, etc.).- Calibration dataset (PTQ):
- Calibration data quality and representativeness are critical for PTQ accuracy.
- Preprocessing for calibration data must match deployment (or be "inverse-preprocessed" as needed).
- Quantization-sensitive layer analysis: If PTQ accuracy drops, use toolchain analysis tools to identify sensitive layers and try mixed-precision or QAT.
- Conversion logs: Carefully review all logs for errors, warnings, or hints.
- BPU inference and board runtime check:
- Input data preparation: Ensure input data matches the model's expected format (layout, type, shape).
- Memory management: Check buffer allocation and copying for correctness.
- Runtime version: Ensure board-side runtime libraries match the toolchain version.
- API calls: Verify correct API usage and parameter settings.
- Post-processing check:
- Match model output: Ensure post-processing logic matches the output node format, dimensions, and meaning.
- Parameter consistency: All parameters (anchors, class number, thresholds, etc.) must match training.
- Coordinate mapping: Map output coordinates back to the original image as needed.
- Logic errors: Check for bugs in post-processing code.
- End-to-end validation:
- Use known inputs/outputs: Test with samples where you know the correct results.
- Module-by-module validation: If possible, validate each pipeline module separately.
Q15: How can I obtain board-side hrt_* performance analysis tools (e.g., hrt_model_exec, hrt_bpu_monitor)?
A: The Horizon RDK system image or toolchain/SDK packages usually include command-line tools for model execution, performance analysis, and debugging, typically prefixed with hrt_ (Horizon Robotics Tool).
- Where to find:
- These tools may be pre-installed in
/usr/binor/opt/hobot/binon the RDK system. - They may also be included in the toolchain package (e.g.,
ddk/package/board/<target_os>/bin/), and you may need to copy them to the board or run them with their full path.
- These tools may be pre-installed in
- Official resource post: The developer community often provides posts or docs on obtaining and using these tools, e.g.: Board-side hrt_* Tool Download and Usage Guide (check for latest validity)
- Common tools:
hrt_model_exec: For running.binmodels on the board for inference and performance testing.hrt_bpu_monitor(orhrut_somstatus, or performance printouts inbpu_predict_xN_sample): For monitoring BPU usage, frequency, temperature, etc.- Other specific debugging tools.
Refer to the latest RDK documentation or community resources for accurate information and download links.
Model quantization errors and solutions \
hb_mapper checker (01_check.sh) Model Validation Error
【Issue】ERROR The shape of model input:input is [xxx] which has dimensions of 0. Please specify input-shape parameter.
- This error occurs when the model input has a dynamic shape. To resolve it, you can specify the input shape using the
--input-shape input_name input_shapeparameter.
ERROR HorizonRT does not support these CPU operators: {op_type}
- This error happens when the CPU operator being used is unsupported by HorizonRT. To address this, check the list of supported operators provided and replace the unsupported one. If the unsupported operator is crucial to your model, contact HorizonRT for development evaluation.
Unsupported op {op_type}
- This error results from using an unsupported BPU operator in your model. If the model's overall performance meets your requirements, you can ignore this log. However, if performance expectations are not met, consider replacing the unsupported operator with a supported one from the provided operator list.
ERROR nodes:['{op_type}'] are specified as domain:xxx, which are not supported by official ONNX. Please check whether these ops are official ONNX ops or defined by yourself
- The reason for this error could be that the custom operator used is not supported by D-Robotics. To resolve it, you can either replace the operator with one listed in our supported operator list or develop and register a custom CPU operator.
Error in hb_mapper makertbin (03_build.sh) Model Conversion
【Question】Layer {op_name}
expects data shape within [[xxx][xxx]], but received [xxx]
Layer {op_name}
Expected tensor xxx to have n dimensions, but found m
- This error might occur if the
{op_name}operator is falling back to CPU computation due to unsupported dimensions. If the performance loss from using CPU is acceptable, you can ignore this message. However, if performance is a concern, review the operator support list and modify the op to a BPU-supported configuration.
INFO: Layer {op_name} will be executed on CPU
- This error indicates that
{op_name}operator is being computed on CPU because its shape (CxHxW) exceeds the limit of 8192. If only a few operators are affected and the overall model performance meets expectations, there's no need to worry. However, if performance is unsatisfactory, consider examining the operator support list for alternatives without shape limitations on BPU.
ERROR There is an error in pass: {op_name}. Error message:xxx
- This error might stem from an optimization failure of the
{op_name}operator. To address this issue, please gather your model and .log files and provide them to D-Robotics technical support for analysis and resolution.
Error There is an error in pass:constant_folding. Error message: Could not find an implementation for the node {op_name}
This error typically occurs when ONNX Runtime encounters an operator (op_name) that it does not have a built-in implementation for. It might be a custom or unsupported operator in the current version of ORT. To resolve this issue, you should verify if the specific operator is supported by checking the ORT operator list. If it's a core operator, consider contacting D-Robotics for development assessment or seeking an alternative implementation.
WARNING input shape [xxx] has length: n ERROR list index out of range
This warning indicates that the input shape provided to the model is not compatible with its requirements, as it expects a four-dimensional shape (e.g., HxW for a 2D image), but received a shape with length n which is not recognized as a standard format. To fix this, ensure your input data is reshaped into a 4D tensor (e.g., change xxx to 1x1xHxW).
Start to parse the onnx model
core dump
This error suggests that there was a failure during the parsing of the ONNX model. It could be due to missing or invalid information, such as naming issues with output or input nodes. Ensure that the exported ONNX model is properly formatted and that all necessary nodes have unique names. If the problem persists, check the model file for any syntax errors and consult the ONNX documentation.
【Question】Start to calibrate/quantize the model
core dump
Start to compile the model
core dump
- This error may occur because of a model quantization/compilation failure. In response to this error, please collect the model and.log file and provide it to D-Robotics technicians for analysis.
ERROR model conversion faild: Inferred shape and existing shape differ in dimension x: (n) vs (m)
- This error may occur because the input shape of the onnx model is illegal, or because the tool optimization pass is incorrect. In response to this error, please ensure that the onnx model is valid, and if the onnx model can be reasoned, please provide the model to D-Robotics technicians for analysis and processing.
WARNING got unexpected input/output/sumin threshold on conv {op_name}! value: xxx
- This error may occur because of incorrect data preprocessing, or because the weight value of the node is too small/too large. In response to this error, 1. Please check whether the data preprocessing is incorrect; 2. We recommend that you use BN operator to optimize data distribution.
ERROR hbdk-cc compile hbir model failed with returncode -n
- This error may occur because the model failed to compile. In response to this error, please collect the model and.log file and provide it to D-Robotics technicians for analysis.
ERROR {op_type} only support 4 dim input
- This error may occur because the toolchain does not yet support the op input dimension as non-four-dimensional. In response to this error, we recommend that you adjust the op input dimension to four dimensions.
ERROR {op_type} Not support this attribute/mode=xxx
- This error may occur because the tool chain does not yet support this property of the op. For this error, you can replace it based on the operator support list we provide or contact D-Robotics for a development evaluation.
ERROR There is no node can execute on BPU in this model, please make sure the model has at least one conv node which is supported by BPU.
- This error may occur because there are no quantifiable BPU nodes in the model. In response to this error, ensure that the onnx model is valid and that at least one conv is used in the model. If the preceding conditions are met, collect the model and.log files and provide them to D-Robotics technicians for analysis and processing.
ERROR [ONNXRuntimeError] : 9 : NOT_IMPLEMENTED : unable to find an implementation for the node with name: {op_name}, type: {op_type}, opset version.
- This error arises when the model's opset version exceeds what the toolchain supports. To resolve this, re-export the model, ensuring that
opset_versionis set to10or11.
ERROR The opset version of the onnx model is n, only model with opset_version 10/11 is supported
- This error occurs due to an unsupported opset version in the model. To rectify the issue, re-export the model with a compatible version, specifically setting
opset_versionto10or11.
After using run_on_bpu, the conversion fails.
- This error might occur due to the unsupported usage of the
run_on_bpuoperator at the moment.run_on_bpucurrently only supports operators likeRelu,Softmax, and pooling (e.g.,maxpool,avgpool) at the end of the model, as well as CPU*+Transpose combinations (where you can specify a Transpose node name to run CPU* operations on BPU). If your model meets these conditions but still encounters issues, please contact D-Robotics technical support for further analysis. If it doesn't meet the criteria, you can request a development evaluation.
ERROR: tool limits for max output num is 32
- The error is likely due to a limitation in the toolchain that allows a maximum of 32 model output nodes. To resolve this, ensure your model has no more than 32 output nodes.
ERROR: xxx file parse failed.
ERROR: xxx does not exist in xxx.
- This error may stem from incorrect environment setup. Please use the provided Docker environment for quantization.
ERROR: exception in command: makertbin.
ERROR: cannot reshape array of size xxx into shape xxx.
- The error is likely related to a preprocessing issue. Please refer to our documentation for relevant information on data preprocessing.
ERROR: load cal data for input xxx error
ERROR: cannot reshape array of size xxx into shape xxx
- This error could be due to an incompatible toolchain version. Ensure you are using the corresponding SDK toolchain version provided.
ERROR [ONNXRuntimeError] : 1 : FAIL : Non-zero status code returned while running HzCalibration node.Name:'xxx'Status Message :CUDA error cudaErrorNoKernelImageForDevice:no kernel image is available for execution on the device
- The error might indicate a Docker loading issue. Try using the nvidia-docker loading command when loading Docker.
[ONNXRuntimeError] : 10 : INVALID_GRAPH : Load model from xxx.onnx failed:This is an invalid model. In Node, ("xxx", HzSQuantizedPreprocess, "", -1) : ("images": tensor(int8),"xxx": tensor(int8),"xxx": tensor(int32),"xxx": tensor(int8),) -> ("xxx": tensor(int8),) , Error No Op registered for HzSQuantizedPreprocess with domain_version of 11
- This error suggests a mismatch between ONNX versions. Re-export your ONNX model with the opset version 10 and use OpenCV for preprocessing.
[E:onnxruntime:, sequential_executor.cc:183 Execute] Non-zero status code returned while running Resize node. Name:'xxx' Status Message: upsample.h:299 void onnxruntime::UpsampleBase::ScalesValidation(const std::vector<float>&, onnxruntime::UpsampleMode) const scales.size() == 2 || (scales.size() == 4 && scales[0] == 1 && scales[1] == 1) was false. 'Linear' mode and 'Cubic' mode only support 2-D inputs ('Bilinear', 'Bicubic') or 4-D inputs with the corresponding outermost 2 scale values being 1 in the Resize operator
- The error is possibly related to ONNXRuntime's internal logic. Since the model contains reshape operations, batch calibration is not possible, and it can only handle images individually. This should not affect the final results.
ERROR: No guantifiable nodes were found, and the model is not supported
- This error occurs when no quantifiable nodes are found in the model structure, indicating that the model is not compatible for quantization.
Algorithm Model Boarding Errors and Solutions
【Problem】(common.h:79): HR:ERROR: op_name:xxx invalid attr key xxx
This error might occur because the specified attribute key for the op is not supported by libDNN. To resolve it, you can either replace the unsupported op with a compatible one from our operator support list or contact D-Robotics for further development evaluation.
【Problem】(hb_dnn_ndarray.cpp:xxx): data type of ndarray do not match specified type. NDArray dtype_: n, given:m
The error arises when the input data type does not match the required type for the operator. libDNN currently lacks support for this input type; we will gradually enforce operator constraints during the model conversion phase. To fix, check our operator support list and consider replacing or contacting D-Robotics for development assessment.
【Problem】(validate_util.cpp:xxx): tensor aligned shape size is xxx , but tensor hbSysMem memSize is xxx, tensor hbSysMem memSize should >= tensor aligned shape size!
This error happens when the allocated memory for the input data is insufficient. To address this, ensure that you allocate memory usinghbDNNTensorProperties.alignedByteSize function to accommodate the required size.
【Problem】(bpu_model_info.cpp:xxx): HR:ERROR: hbm model input feature names must be equal to graph node input names
An error occurred because the input feature names for the HBM model must match the node input names in the graph. Make sure to verify and align the input names accordingly.
Model Quantization and Board Usage Tips
Transformer Usage Guide
This section will provide explanations of various transformers and their parameters, along with usage examples to assist you in working with transformers.
Before diving into the content, please note:
- The image data is in three-dimensional format; however, D-Robotics's transformers operate on four-dimensional data. Transformers only apply operations to the first channel of input images.
AddTransformer
Explanation: Performs an addition operation on all pixel values in the input image. This transformer converts the output data format to float32.
Parameters:
- value: The value to add to each pixel, which can be negative, like -128.
Usage Example:
# Subtract 128 from image data
AddTransformer(-128)
# Add 127 to image data
AddTransformer(127)
MeanTransformer
Explanation: Subtracts the mean_value from all pixel values in the input image.
Parameters:
- means: The value to subtract from each pixel, which can be negative, like -128.
- data_format: Input layout type, can be either "CHW" or "HWC", default is "CHW".
Usage Example:
# Subtract 128.0 from each pixel (CHW format)
MeanTransformer(np.array([128.0, 128.0, 128.0]))
# Subtract different values for each channel (HWC format)
MeanTransformer(np.array([103.94, 116.78, 123.68]), data_format="HWC")
ScaleTransformer
Explanation: Multiplies all pixel values in the input image by the scale_value.
Parameters:
- scale_value: The coefficient to multiply by, such as 0.0078125 or 1/128.
Usage Example:
# Adjust pixel range from -128 to 127 to -1 to 1
ScaleTransformer(0.0078125)
# Or
ScaleTransformer(1/128)
NormalizeTransformer
Explanation: Normalizes the input image by performing a scaling operation. The transformer converts the output data format to float32.
Parameters:
- std: The value to divide each pixel by, typically the standard deviation of the first image.
Usage Example:
# Normalize pixel range [-128, 127] to -1 to 1
NormalizeTransformer(128)
TransposeTransformer
Explanation: Performs a layout transformation on the input image.
Parameters:
- order: The new order of dimensions after the transformation (related to the original layout). For example, for HWC, the order would be (2, 0, 1) to convert to CHW.
Usage Example:
# Convert HWC to CHW
TransposeTransformer((2, 0, 1))
# Convert CHW to HWC
TransposeTransformer((1, 2, 0))
HWC2CHWTransformer
Explanation: Transforms input from NHWC to NCHW layout.
Parameters:
- None.
Usage Example:
# Convert NHWC to NCHW
HWC2CHWTransformer()
CHW2HWCTransformer
Explanation: Transforms input from NCHW to NHWC layout.
Parameters:
- None.
Usage Example:
# Convert NCHW to NHWC
CHW2HWCTransformer()
CenterCropTransformer
Explanation:
Crops a square image from the center of the input image. The transformer converts the output data format to float32, and uint8 if data_type is set to uint8.
Parameters:
- crop_size: The side length of the square to crop.
- data_type: Output data type, can be "float" or "uint8".
Usage Example:
# Crop a 224x224 center, default float32 output
CenterCropTransformer(crop_size=224)
# Crop a 224x224 center, output as uint8
CenterCropTransformer(crop_size=224, data_type="uint8")
PILCenterCropTransformer
Explanation: Uses PIL to crop a square image from the center of the input.
Parameters:
- size: The side length of the square to crop.
Usage Example:
# Crop a 224x224 center using PIL
PILCenterCropTransformer(size=224)
LongSideCropTransformer
Explanation: Crops the longest edge of the input image while maintaining aspect ratio. The transformer converts the output data format to float32.
Parameters:
- None.
Usage Example:
LongSideCropTransformer()
PadResizeTransformer
Explanation: Enlarges the image by padding and resizing. The transformer converts the output data format to float32.
Parameters:
- target_size: Target size as a tuple, e.g., (240, 240).
- pad_value: Value to pad the array with, default is 127.
- pad_position: Padding position, can be "boundary" or "bottom_right", default is "boundary".
Usage Example:
# Resize to 512x512, pad to bottom-right corner, pad value is 0
PadResizeTransformer((512, 512), pad_position='bottom_right', pad_value=0)
# Resize to 608x608, pad to edges, pad value is 127
PadResizeTransformer(target_size=(608, 608))
ResizeTransformer
Explanation: Resizes the image to the specified target size.
Parameters:
- target_size: Target size as a tuple, e.g., (240, 240).
- mode: Image processing mode, can be "skimage" or "opencv", default is "skimage".
- method: Interpolation method, only used when mode is "skimage". Range is 0-5, default is 1 (bicubic).
- data_type: Output data type, can be uint8 or float, default is float.
- interpolation: Interpolation method, only used when mode is "opencv". Can be empty (default INTER_LINEAR) or one of OpenCV's interpolation methods.
Usage Example:
# Resize to 224x224, using opencv with bilinear interpolation, float32 output
ResizeTransformer(target_size=(224, 224), mode='opencv', method=1)
# Resize to 256x256, using skimage with bilinear interpolation, float32 output
ResizeTransformer(target_size=(256, 256))
# Resize to 256x256, using skimage with bilinear interpolation, uint8 output
ResizeTransformer(target_size=(256, 256), data_type="uint8")
PILResizeTransformer
Explanation: Resizes the image using the PIL library.
Parameters:
- size: Target size as a tuple, e.g., (240, 240).
- interpolation: PIL interpolation method, options include Image.NEAREST, Image.BILINEAR, Image.BICUBIC, Image.LANCZOS, default is Image.BILINEAR.
Usage Example:
# Resize the input image to the specified size using PIL
LinearResizeTransformer
Description:
Resize the input image to a size of 256x256 using linear interpolation.
PILResizeTransformer(size=256)
ShortLongResizeTransformer
Explanation:
Performs resizing based on the original aspect ratio, with output dimensions determined by provided parameters. The process involves:
- Scaling by a factor calculated as
short_sizedivided by the smaller dimension of the original image. - If the scaled maximum dimension exceeds
long_size, the scaling factor adjusts tolong_sizedivided by the larger original dimension. - Uses OpenCV's
resizemethod with the calculated scale factor to crop the image.
Parameters:
- short_size: Target length for the shorter side.
- long_size: Target length for the longer side.
- include_im: Default True, if True, returns both processed image and the original.
Usage Example:
ShortLongResizeTransformer(short_size=20, long_size=100)
PadTransformer
Description:
Resize the image by padding to the desired target size using a scaling factor based on the original dimensions and a divisor.
Parameters:
- size_divisor: Division factor, default 128.
- target_size: Desired target size, default 512.
Usage Example:
PadTransformer(size_divisor=1024, target_size=1024)
ShortSideResizeTransformer
Explanation:
Crops the image to the specified short side size while maintaining the aspect ratio, using either float32 or uint8 output type and a specified interpolation method.
Parameters:
- short_size: Expected length of the shorter side.
- data_type: Output data type, can be "float" or "uint8", default "float32".
- interpolation: Interpolation method, accepts OpenCV interpolation types, defaults to None (uses INTER_LINEAR).
Usage Examples:
# Resize to 256 with bilinear interpolation
ShortSideResizeTransformer(short_size=256)
# Resize to 256 with Lanczos4 interpolation
ShortSideResizeTransformer(short_size=256, interpolation=Image.LANCZOS)
PaddedCenterCropTransformer
Description:
Performs center cropping with padding, specifically designed for EfficientNet-lite models.
Note:
Works only for EfficientNet-lite instances.
Calculation Process:
- Calculate the coefficient as
int((float(image_size) / (image_size + crop_pad))). - Compute the center size as the coefficient times the smaller of the original height and width.
- Crop the image centered around the calculated size.
Parameters:
- image_size: Image size, default 224.
- crop_pad: Padding amount, default 32.
Usage Example:
PaddedCenterCropTransformer(image_size=240, crop_pad=32)
BGR2RGBTransformer
Description:
Converts the input format from BGR to RGB.
Parameter:
- data_format: Data layout, can be "CHW" or "HWC", default "CHW".
Usage Example:
# For NCHW layout, convert BGR to RGB
BGR2RGBTransformer()
# For NHWC layout, convert BGR to RGB
BGR2RGBTransformer(data_format="HWC")
RGB2BGRTransformer
Description:
Converts the input format from RGB to BGR.
Parameter:
- data_format: Data layout, can be "CHW" or "HWC", default "CHW".
Usage Example:
# For NCHW layout, convert RGB to BGR
RGB2BGRTransformer()
# For NHWC layout, convert RGB to BGR
RGB2BGRTransformer(data_format="HWC")
RGB2GRAYTransformer
Description:
Converts the input format from RGB to grayscale.
Parameter:
- data_format: Input layout, can be "CHW" or "HWC", default "CHW".
Usage Example:
# For NCHW layout, convert RGB to grayscale
RGB2GRAYTransformer(data_format='CHW')
# For NHWC layout, convert RGB to grayscale
RGB2GRAYTransformer(data_format='HWC')
BGR2GRAYTransformer
Description:
Converts the input format from BGR to grayscale.
Parameter:
- data_format: Input layout, can be "CHW" or "HWC", default "CHW".
Usage Example:
# For NCHW layout, convert BGR to grayscale
BGR2GRAYTransformer(data_format='CHW')
# For NHWC layout, convert BGR to grayscale
BGR2GRAYTransformer(data_format='HWC')
RGB2GRAY_128Transformer
Description:
Converts the input format from RGB to grayscale with values ranging from -128 to 127.
Parameter:
- data_format: Input layout, must be "CHW" or "HWC".
Usage Example:
# For NCHW layout, convert RGB to 128-bit grayscale
RGB2GRAY_128Transformer(data_format='CHW')
# For NHWC layout, convert RGB to 128-bit grayscale
RGB2GRAY_128Transformer(data_format='HWC')
RGB2YUV444Transformer
Description:
Converts the input format from RGB to YUV444.
Parameter:
- data_format: Input layout, can be "CHW" or "HWC", required.
Usage Example:
# For NCHW layout, convert RGB to YUV444
BGR2YUV444Transformer(data_format='CHW')
# For NHWC layout, convert RGB to YUV444
BGR2YUV444Transformer(data_format='HWC')
BGR2YUV444Transformer
Description:
Converts the input format from BGR to YUV444.
Parameter:
- data_format: Input layout, can be "CHW" or "HWC", required.
Usage Example:
# For NCHW layout, convert BGR to YUV444
BGR2YUV444Transformer(data_format='CHW')
# For NHWC layout, convert BGR to YUV444
BGR2YUV444Transformer(data_format='HWC')
BGR2YUV444_128Transformer
Description:
Converts the input format from BGR to YUV444 with values ranging from -128 to 127.
Parameter:
- data_format: Input layout, must be "CHW" or "HWC".
Usage Example:
# For NCHW layout, convert BGR to 128-bit YUV444
BGR2YUV444_128Transformer(data_format='CHW')
# For NHWC layout, convert BGR to 128-bit YUV444
BGR2YUV444_128Transformer(data_format='HWC')
RGB2YUV444_128Transformer
Description:
Converts the input format from RGB to YUV444 with values ranging from -128 to 127.
Parameter:
- data_format: Input layout, can be "CHW" or "HWC".
Usage Example:
# For NCHW layout, convert RGB to 128-bit YUV444
RGB2YUV444_128Transformer(data_format='CHW')
# For NHWC layout, convert RGB to 128-bit YUV444
RGB2YUV444_128Transformer(data_format='HWC')
BGR2YUVBT601VIDEOTransformer
Description: Transforms the input format from BGR to YUV_BT601_Video_Range.
YUV_BT601_Video_Range: Some camera inputs are in YUV BT601 (Video Range) format with values ranging from 16 to 235. This transformer is designed for such data.
Parameters:
- data_format: The input layout type, can be either "CHW" or "HWC", default is "CHW". This is a required field.
Usage Example:
# For NCHW layout, convert BGR to YUV_BT601_Video_Range
BGR2YUVBT601VIDEOTransformer(data_format='CHW')
# For NHWC layout, convert BGR to YUV_BT601_Video_Range
BGR2YUVBT601VIDEOTransformer(data_format='HWC')
RGB2YUVBT601VIDEOTransformer
Description: Similar to BGR2YUVBT601VIDEOTransformer but for RGB input.
Parameters:
- data_format: The input layout type, can be either "CHW" or "HWC", default is "CHW". This is a required field.
Usage Example:
# For NCHW layout, convert RGB to YUV_BT601_Video_Range
RGB2YUVBT601VIDEOTransformer(data_format='CHW')
# For NHWC layout, convert RGB to YUV_BT601_Video_Range
RGB2YUVBT601VIDEOTransformer(data_format='HWC')
YUVTransformer
Description: Converts the input format to YUV444.
Parameters:
- color_sequence: The color sequence, a required field.
Usage Example:
# Convert an image read as BGR to YUV444
YUVTransformer(color_sequence="BGR")
# Convert an image read as RGB to YUV444
YUVTransformer(color_sequence="RGB")
ReduceChannelTransformer
Description: Reduces the C channel to a single channel. This transformer is mainly for handling channels like converting a shape of 13224224 to 11224224. Ensure the layout matches the data_format to avoid removing the wrong channel.
Parameters:
- data_format: The input layout type, can be either "CHW" or "HWC", default is "CHW".
Usage Example:
# Remove the C channel for NCHW layout
ReduceChannelTransformer()
# Remove the C channel for NHWC layout
ReduceChannelTransformer(data_format="HWC")
BGR2NV12Transformer
Description: Translates input format from BGR to NV12.
Parameters:
- data_format: Input layout type, can be "CHW" or "HWC", default is "CHW".
- cvt_mode: Conversion mode, can be "rgb_calc" or "opencv", default is "rgb_calc".
- rgb_calc: Merges UV using a custom method.
- opencv: Uses OpenCV's method.
Usage Example:
# For NCHW layout, convert BGR to NV12 with rgb_calc mode
BGR2NV12Transformer()
# For NHWC layout, convert BGR to NV12 with opencv mode
BGR2NV12Transformer(data_format="HWC", cvt_mode="opencv")
RGB2NV12Transformer
Description: Similar to BGR2NV12Transformer but for RGB input.
Parameters:
- data_format: Input layout type, can be "CHW" or "HWC", default is "CHW".
- cvt_mode: Conversion mode, can be "rgb_calc" or "opencv", default is "rgb_calc".
Usage Example:
# For NCHW layout, convert RGB to NV12 with rgb_calc mode
RGB2NV12Transformer()
# For NHWC layout, convert RGB to NV12 with opencv mode
RGB2NV12Transformer(data_format="HWC", cvt_mode="opencv")
NV12ToYUV444Transformer
Description: Transforms input format from NV12 to YUV444.
Parameters:
- target_size: The desired size as a tuple, e.g., (240, 240).
- yuv444_output_layout: The layout for the YUV444 output, can be "HWC" or "CHW", default is "HWC".
Usage Example:
# For NCHW layout and input size of 768*768, convert NV12 to YUV444
NV12ToYUV444Transformer(target_size=(768, 768))
# For NHWC layout and input size of 224*224, convert NV12 to YUV444
NV12ToYUV444Transformer((224, 224), yuv444_output_layout="HWC")
WarpAffineTransformer
Description: Performs image affine transformation.
Parameters:
-
input_shape: The input shape value.
-
scale: The scaling factor.
Usage Example:
# For an image of size 512*512, scale the longer side by 1.0
WarpAffineTransformer((512, 512), 1.0)
F32ToS8Transformer
Description: Converts input format from float32 to int8.
Parameters: No parameters.
Usage Example:
# Convert input from float32 to int8
F32ToS8Transformer()
F32ToU8Transformer
Description: Converts input format from float32 to uint8.
Parameters: No parameters.
Usage Example:
# Convert input from float32 to uint8
F32ToU8Transformer()
Example usage guide for YOLOv5x model
-
YOLOv5x Model:
-
Download the corresponding .pt file from the URL: yolov5-2.0. Make sure you use the tag
v2.0to ensure successful conversion.MD5SUMs:
MD5SUM File 2e296b5e31bf1e1b6b8ea4bf36153ea5 yolov5l.pt 16150e35f707a2f07e7528b89c032308 yolov5m.pt 42c681cf466c549ff5ecfe86bcc491a0 yolov5s.pt 069a6baa2a741dec8a2d44a9083b6d6e yolov5x.pt
-
-
Modify the YOLOv5 code from GitHub (version v2.0) for better compatibility with post-processing:
- In models/yolo.py, remove the reshape and layout change at the end of each output branch.(https://github.com/ultralytics/yolov5/blob/v2.0/models/yolo.py)
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
x[i] = x[i].permute(0, 2, 3, 1).contiguous()
-
After cloning the code, run the script at https://github.com/ultralytics/yolov5/blob/v2.0/models/export.py to convert the .pt files to ONNX.
-
Note: When using the export.py script, consider the following:
- Set the
opset_versionparameter intorch.onnx.exportaccording to the ONNX opset version you intend to use. - Adjust the default input name parameters in the
torch.onnx.exportsection as needed.
- Set the
Please note that I have translated the text into English while maintaining the original format and code blocks. I have also made the requested changes to the image file name and data input size.
"data" # Changed "images" to "data" to match the YOLOv5x example script in the model conversion package
Model Accuracy Optimization Checklist
Follow the steps 1-5 strictly to verify the model's accuracy, and keep the code and results for each step:
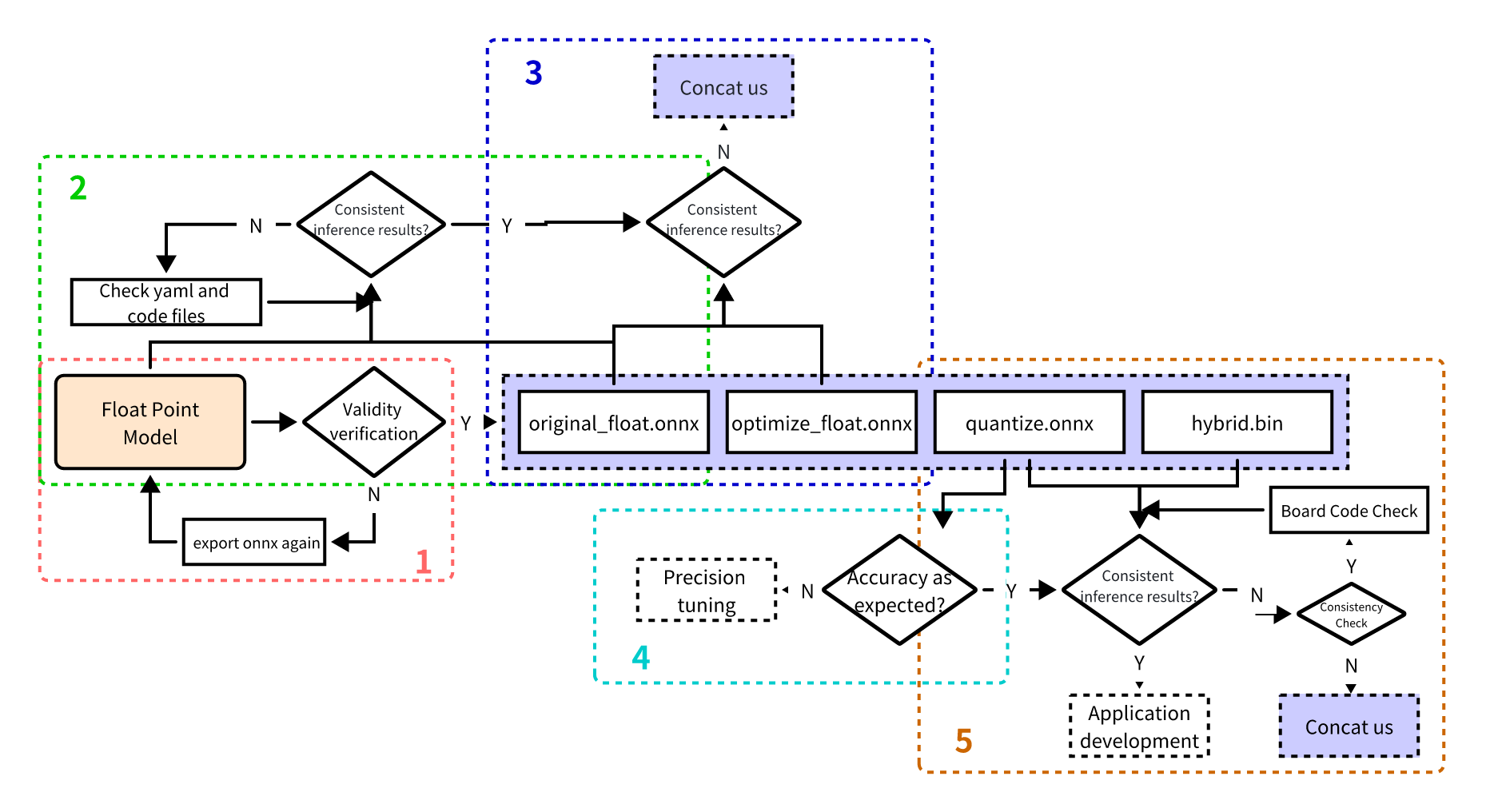
Before starting, ensure you have the correct Docker image or conversion environment version, and record the version information.
1. Validate the inference results of the float ONNX model
Enter the model conversion environment to test the single-image result of the float ONNX model (specifically, the ONNX model exported from the DL framework). This step's result should be identical to the inference result of the trained model (except for possible minor differences due to NV12 format).
from horizon_tc_ui import HB_ONNXRuntime
import numpy as np
import cv2
def preprocess(input_name):
# RGB conversion, Resize, CenterCrop...
# HWC to CHW
# normalization
return data
def main():
# Load the model file
sess = HB_ONNXRuntime(model_file=MODEL_PATH)
# Get input and output node names
input_names = [input.name for input in sess.get_inputs()]
output_names = [output.name for output in sess.get_outputs()]
# Prepare model input data
feed_dict = {input_name: preprocess(input_name) for input_name in input_names}
# Original float ONNX, data dtype=float32
outputs = sess.run(output_names, feed_dict, input_offset=0)
# Postprocessing
postprocess(outputs)
if __name__ == '__main__':
main()
2. Verify the correctness of the YAML configuration file and preprocessing/postprocessing code
Test the single-image result of the original_float.onnx model, which should be consistent with the float ONNX model's inference result (excluding possible minor differences due to NV12 data loss).
Use an open-source tool like Netron to inspect the original_float.onnx model, and examine the detailed properties of the "HzPreprocess" operator to obtain the required parameters for our preprocessing: data_format and input_type.
Since the HzPreprocess operator is present, the preprocessing in the converted model might differ from the original. This operator is added based on the configuration parameters in the YAML file (input_type_rt, input_type_train, norm_type, mean_value, scale_value). For more details, refer to the section on "norm_type configuration parameter explanation" in the PTQ principles and steps guide. The preprocessing node will appear in all conversion outputs.
Ideally, the HzPreprocess node should complete the full type conversion from input_type_rt to input_type_train, but this process is done on the D-Robotics AI chip hardware, which is not included in the ONNX model. Thus, the actual input type in the ONNX model uses a middle type representing the hardware's handling of input_type_rt. For image models with inputs like RGB/BGR/NV12/YUV444/GRAY and dtype=uint8, apply -128 in the preprocessing when using the hb_session.run interface; for featuremap models with dtype=float32, no -128 is needed, as the input layout (NCHW/NHWC) remains the same as the original float model.
from horizon_tc_ui import HB_ONNXRuntime
import numpy as np
import cv2
def preprocess(input_name):
# BGR to RGB, Resize, CenterCrop...
# HWC to CHW (determined by the specific shape of the input node in the ONNX model)
# normalization (skip if normalization operation is already included in the model's YAML file)
# -128 (apply to image inputs when using the hb_session.run interface; use input_offset for other interfaces)
return data
def main():
# Load the model file
sess = HB_ONNXRuntime(model_file=MODEL_PATH)
# Get input and output node names
input_names = [input.name for input in sess.get_inputs()]
output_names = [output.name for output in sess.get_outputs()]
# Prepare model input data
feed_dict = {}
for input_name in input_names:
feed_dict[input_name] = preprocess(input_name)
# Image input models (RGB/BGR/NV12/YUV444/GRAY), data type = uint8
outputs = sess.run(output_names, feed_dict, input_offset=128)
# Feature map models, data type = float32. Comment out this line if the model input is not a feature map!
# outputs = sess.run_feature(output_names, feed_dict, input_offset=0)
# Post-processing
postprocess(outputs)
if __name__ == '__main__':
main()
3. Validate that no accuracy loss was introduced during graph optimization
Test the single-image result of the optimize_float.onnx model, which should be identical to the original_float.onnx inference result.
Use Netron to inspect the optimize_float.onnx model and check the "HzPreprocess" operator's details for the required preprocessing parameters: data_format and input_type.
from horizon_tc_ui import HB_ONNXRuntime
import numpy as np
import cv2
def preprocess(input_name):
# BGR to RGB, Resize, CenterCrop...
# HWC to CHW (determined by the specific shape of the input node in the ONNX model)
# normalization (if normalization operation is already included in the model's YAML file, skip it here)
# -128 (apply -128 to image inputs when using the hb_session.run interface; other interfaces can control with input_offset)
return data
def main():
# Load the model file
sess = HB_ONNXRuntime(model_file=MODEL_PATH)
# Get input and output node names
input_names = [input.name for input in sess.get_inputs()]
output_names = [output.name for output in sess.get_outputs()]
# Prepare model input data
feed_dict = {input_name: preprocess(input_name) for input_name in input_names}
# Image input models (RGB/BGR/NV12/YUV444/GRAY), data dtype= uint8
outputs = sess.run(output_names, feed_dict, input_offset=128)
# Feature map models, data dtype=float32. Comment out this line if the model does not take feature maps as input!
# outputs = sess.run_feature(output_names, feed_dict, input_offset=0)
# Post-processing
postprocess(outputs)
if __name__ == '__main__':
main()
4. Verify the quantization accuracy meets expectations
Test the precision metrics of the quantized.onnx model.
Use Netron to open the quantized.onnx model and examine the "HzPreprocess" operator's details for the needed preprocessing parameters: data_format and input_type.
from horizon_tc_ui import HB_ONNXRuntime
import numpy as np
import cv2
def preprocess(input_name):
# BGR to RGB, Resize, CenterCrop...
# HWC to CHW (determine layout conversion based on the specific shape of the input node in the ONNX model)
# normalization (skip if normalization operation is already included in the model's YAML file)
# -128 (apply -128 to image inputs when using the hb_session.run interface; other interfaces use input_offset)
return data
def main():
# Load the model file
sess = HB_ONNXRuntime(model_file=MODEL_PATH)
# Get input and output node names
input_names = [input.name for input in sess.get_inputs()]
output_names = [output.name for output in sess.get_outputs()]
# Prepare model input data
feed_dict = {input_name: preprocess(input_name) for input_name in input_names}
# Image input models (RGB/BGR/NV12/YUV444/GRAY), data dtype= uint8
outputs = sess.run(output_names, feed_dict, input_offset=128)
# Feature map model, data dtype=float32. Comment out the following line if the model input is not a feature map!
# outputs = sess.run_feature(output_names, feed_dict, input_offset=0)
# Post-processing
postprocess(outputs)
if __name__ == '__main__':
main()
Verifying Model Compilation and Code Correctness
Use the hb_model_verifier tool to ensure ../07_Advanced_development between the quantized.onnx and .bin files, with model outputs aligned to at least two or three decimal places.
For detailed instructions on using hb_model_verifier, please refer to the section on PTQ principles and steps in the "hb_model_verifier tool" content.
If the model ../07_Advanced_development check passes, carefully examine the board-side preprocessing and post-processing code!
In case of a failure in the ../07_Advanced_development check between the quantized.onnx and .bin models, contact D-Robotics technical support.
Quantization YAML Configuration File Templates
RDK X3 Caffe Model Quantization YAML Template
Create a caffe_config.yaml file and copy the following content, then fill in the marked required parameters to proceed with model conversion. For more information on parameter usage, see the "YAML Configuration File Explanation" chapter.
# Copyright (c) 2020 D-Robotics.All Rights Reserved.
# Parameters related to model conversion
model_parameters:
# Required parameters
# Float-point Caffe network data model file, e.g., caffe_model: './horizon_x3_caffe.caffemodel'
caffe_model: ''
# Required parameters
# Caffe network description file, e.g., prototxt: './horizon_x3_caffe.prototxt'
prototxt: ''
march: "bernoulli2"
layer_out_dump: False
working_dir: 'model_output'
output_model_file_prefix: 'horizon_x3'
# Input parameters related to the model
input_parameters:
input_name: ""
input_shape: ''
input_type_rt: 'nv12'
input_layout_rt: ''
# Required parameters
# Data type used in the original float model training framework, options: rgb/bgr/gray/featuremap/yuv444, e.g., input_type_train: 'bgr'
input_type_train: ''
# Required parameters
# Data layout used in the original float model training framework, options: NHWC/NCHW, e.g., input_layout_train: 'NHWC'
input_layout_train: ''
#input_batch: 1
# Required parameter
# Preprocessing method used in the original float model training framework, options: no_preprocess/data_mean/data_scale/data_mean_and_scale
# no_preprocess: No operation; mean_value or scale_value do not need to be configured
# data_mean: Subtract channel mean (mean_value); comment out scale_value
# data_scale: Multiply image pixels by scale_value; comment out mean_value
# data_mean_and_scale: Subtract channel mean and then multiply by scale_value; both mean_value and scale_value must be configured
norm_type: ''
# Required parameter
# Image mean value to subtract, separated by spaces if channel-wise, e.g., mean_value: 128.0 or mean_value: 111.0 109.0 118.0
mean_value:
# Required parameter
# Image scaling factor; separate by spaces if channel-wise, e.g., scale_value: 0.0078125 or scale_value: 0.0078125 0.001215 0.003680
# Parameters related to model quantization
calibration_parameters:
# Required parameter
# Directory containing reference images for model calibration, supporting formats like JPEG, BMP. These images should be from a test set, covering diverse scenarios, not extreme conditions like overexposure, saturation, blur, pure black, or pure white.
# Configure according to the folder path in the 02_preprocess.sh script, e.g., cal_data_dir: './calibration_data_yuv_f32'
cal_data_dir: ''
cal_data_type: 'float32'
calibration_type: 'default'
# max_percentile: 0.99996
# Compiler-related parameters
compiler_parameters:
compile_mode: 'latency'
debug: False
# core_num: 2
optimize_level: 'O3'
RDK X3 ONNX Model Quantization YAML Template
Create a onnx_config.yaml file and copy the following content, then fill in the marked required parameters to proceed with model conversion. For more information on parameter usage, see the "YAML Configuration File Explanation" chapter.
# Copyright (c) 2020 D-Robotics.All Rights Reserved.
# Parameters related to model conversion
model_parameters:
# Required parameters
# Float-point ONNX network data model file, e.g., onnx_model: './horizon_x3_onnx.onnx'
onnx_model: ''
march: "bernoulli2"
layer_out_dump: False
working_dir: 'model_output'
output_model_file_prefix: 'horizon_x3'
# Input parameters related to the model
input_parameters:
input_name: ""
input_shape: ''
input_type_rt: 'nv12'
input_layout_rt: ''
# Required parameters
# Data type used in the original float model training framework, options: rgb/bgr/gray/featuremap/yuv444, e.g., input_type_train: 'bgr'
input_type_train: ''
# Required parameters
# Data layout used in the original float model training framework, options: NHWC/NCHW, e.g., input_layout_train: 'NHWC'
input_layout_train: ''
#input_batch: 1
# Required parameter
# Preprocessing method used in the original float model training framework, options: no_preprocess/data_mean/data_scale/data_mean_and_scale
# no_preprocess: No operation; mean_value or scale_value do not need to be configured
# data_mean: Subtract channel mean (mean_value); comment out scale_value
# data_scale: Multiply image pixels by scale_value; comment out mean_value
# data_mean_and_scale: Subtract channel mean and then multiply by scale_value; both mean_value and scale_value must be configured
norm_type: ''
# Required parameter
# Image mean value to subtract, separated by spaces if channel-wise, e.g., mean_value: 128.0 or mean_value: 111.0 109.0 118.0
mean_value:
# Required parameter
# Image scaling factor; separate by spaces if channel-wise, e.g., scale_value: 0.0078125 or scale_value: 0.0078125 0.001215 0.003680