Development Guide
Requirements for Floating Point Model
symbolic_trace
Similar to PyTorch's quantization training, horizon_plugin_pytorch is designed and developed based on fx, so it requires that the floating-point model can correctly complete symbolic_trace.
Partial Operator Support Only
Since BPU only supports a limited number of operators, horizon_plugin_pytorch only supports the operators in the operator list and the special operators defined internally based on BPU restrictions.
Calibration Guide
In quantization, an important step is to determine the quantization parameters. Reasonable initial quantization parameters can significantly improve model accuracy and accelerate model convergence. Calibration is the process of inserting an Observer into a floating-point model and using a small amount of training data to statistically measure the data distribution at various points in the model's forward process to determine reasonable quantization parameters. Although quantization training can be done without calibration, it is generally beneficial to quantization training, so it is recommended that users consider this step as a mandatory option.
Process and Example
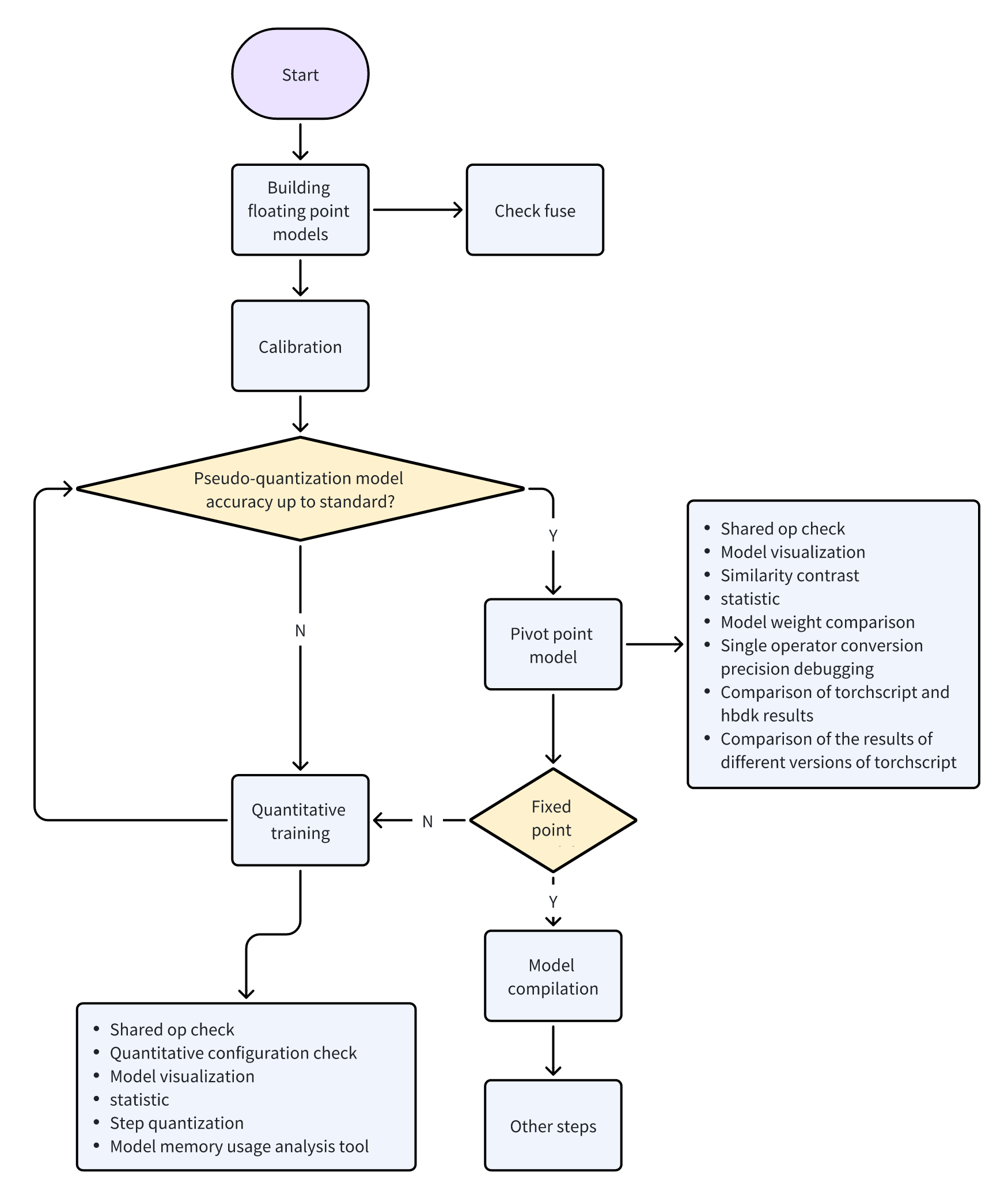
The overall process of Calibration and QAT is shown in the following figure:

The steps are described as follows:
-
Build and train a floating-point model. Refer to the Floating Point Model Acquisition section of the horizon_plugin_pytorch quick start chapter for more information.
-
Insert an Observer node into the floating-point model. Refer to the Calibration section of the horizon_plugin_pytorch quick start chapter for more information. Before converting the floating-point model using the
prepare_qat_fxmethod, the model needs to be set with aqconfig.model.qconfig = horizon.quantization.get_default_qconfig()get_default_qconfigcan set differentobserverforweightandactivation. Currently, calibration has optional observers including "min_max", "percentile", "mse", "kl", and "mix". If there are no special requirements, it is recommended to use the default "min_max" forweight_observerand "mse" foractivation_observer. Special usage and debugging techniques are described in the following common algorithm introduction.The
fake_quantparameter has no effect on the Calibration results, so it can be kept in the default state.def get_default_qconfig(
activation_fake_quant: Optional[str] = "fake_quant",
weight_fake_quant: Optional[str] = "fake_quant",
activation_observer: Optional[str] = "min_max",
weight_observer: Optional[str] = "min_max",
activation_qkwargs: Optional[Dict] = None,
weight_qkwargs: Optional[Dict] = None,
):- Set the
fake quantizestate toCALIBRATION.
horizon.quantization.set_fake_quantize(model, horizon.quantization.FakeQuantState.CALIBRATION)There are three states for
fake quantize, which need to be set to the corresponding state beforeQAT,calibration, andvalidation. In the calibration state, only the statistics of the inputs and outputs of each operator are observed. In the QAT state, besides observing the statistics, pseudo-quantization operations are also performed. And in the validation state, statistics are not observed, only pseudo-quantization operations are performed.class FakeQuantState(Enum):
QAT = "qat"
CALIBRATION = "calibration"
VALIDATION = "validation" - Set the
-
Calibration. Feed the prepared calibration data to the model, and observe the relevant statistics during the forward process by the observer.
-
Set the model state to
evaland set thefake quantizestate toVALIDATION.model.eval()
horizon.quantization.set_fake_quantize(model, horizon.quantization.FakeQuantState.VALIDATION) -
Validate the calibration effect. If the effect is satisfactory, the model can be directly converted to fixed point or quantization training can be performed based on it. If not satisfied, adjust the parameters in the
calibration qconfigto continue the calibration.
Introduction to Common Algorithms
For the parameter descriptions of each operator, please refer to the API documentation at the end of the document.
| Algorithm | Speed Ranking | Accuracy Ranking | Ease of Use Ranking |
|---|---|---|---|
| min_max | 1 | 5 | 1 |
| percentile | 2 | 4 | 4 |
| mse | 4 | 1 | 2 |
| kl | 5 | 2 | 3 |
| mix | 3 | 2 | 1 |
The table above shows the performance of several commonly used calibration methods, where smaller numbers indicate better performance. Speed represents the time consumed for calibrating the same data, accuracy represents the calibration effect of the method on most models, and ease of use represents the complexity of parameter tuning.
For the same model, different methods and parameters may have significant differences in accuracy/speed. Recent research also shows that there is no single method that can achieve the best accuracy on all models, and it is necessary to adjust the parameters accordingly. Therefore, it is recommended for users to try these calibration methods.
-
min_max. This method only calculates the sliding average of the maximum and minimum values, which is used to quickly determine common parameters such as Batch size and average_constant, without much technique involved.
-
percentile. This method has the highest upper limit of accuracy among all methods, but it is also the most difficult to tune. If the accuracy requirements can be met through other methods or the default parameters of this method, it is not recommended to spend too much time on parameter tuning. There are two adjustable parameters in percentile: bins and percentile. The more bins, the smaller the interval between candidate options for max, and the finer the granularity for adjustment, but it also means higher computational cost. It is recommended to determine the percentile first and then adjust the bins. Iterate between the two to narrow down the parameter range until satisfactory results are achieved. In most cases, taking 2048 as the bin provides sufficient adjustment granularity, and there is no need to separately adjust this parameter. The following is an example of the parameter tuning path for a model:
| Order | percentile | bins | accuracy |
|---|---|---|---|
| 1 | 99.99 | 2048 | 53.75 |
| 2 | 99.99 | 4096 | 54.38 |
| 3 | 99.995 | 4096 | 16.25 |
| 4 | 99.985 | 4096 | 32.67 |
| 5 | 99.9875 | 4096 | 57.06 |
| 6 | 99.9875 | 8192 | 62.84 |
| 7 | 99.98875 | 8192 | 57.62 |
| 8 | 99.988125 | 8192 | 63.15 |
In this example, it can be seen that after careful adjustment, the accuracy has improved by about 10%. There are significant differences between the inputs and outputs of different ops in the model. A set of global percentile parameters may be difficult to meet the requirements of all ops. When high accuracy is required, you can first find better global parameters using the method above, and then use debug tools to find the ops with large errors and individually set percentile parameters for these ops, following the setting method of qconfig. Here are several common data distributions that can cause significant errors:
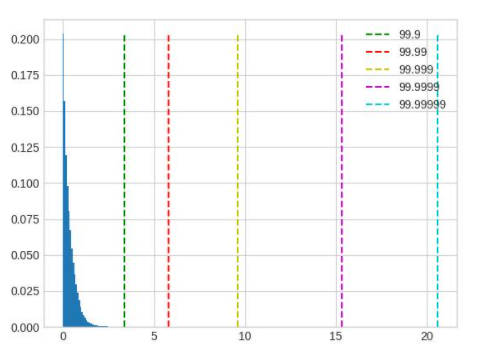
Long-tailed distribution, the value of percentile should be smaller. In the figure, 99.9 is a better value to choose.
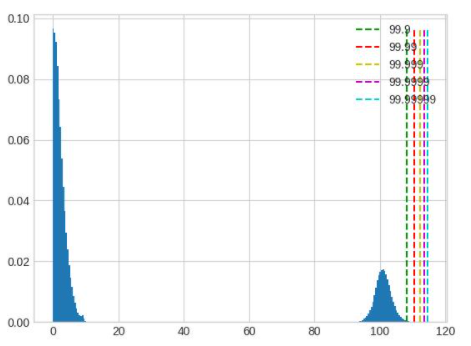
The value range is too large, and the distribution is not centralized. Whether to retain or ignore the tail will result in significant loss of accuracy. This situation should be avoided during training of floating-point models by adjusting parameters such as weight decay.
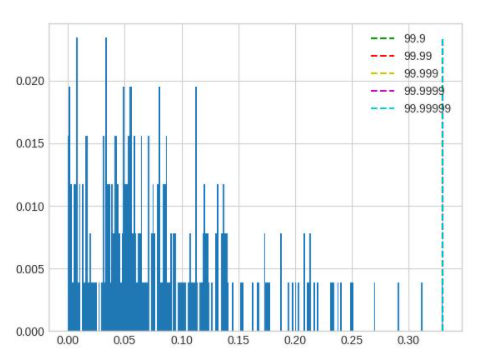
The output distribution of layernorm will show several highly concentrated areas. In this case, adjusting percentile according to the normal method will not have any impact on the quantization result. The adjustment range of percentile needs to be increased.
-
mse. The adjustable parameter is only the stride, with the default stride being 1. It will gradually try the 100th percentile of the maximum value and select the value corresponding to the percentile that minimizes the error (L2 distance) before and after quantization. This method is time-consuming for large models. Increasing the stride within a reasonable range can reduce the time consumption while ensuring accuracy. A too large stride can affect accuracy. Note that adjusting the parameters of this method can only optimize time consumption and cannot significantly improve accuracy.
-
kl. There are two adjustable parameters: bin and update_interval. Due to the long time consumption of this method, it is not recommended to adjust the default bin. The update_interval default is 1, increasing it can reduce time consumption, but it needs to ensure that update_interval is less than the total calibration step, otherwise it will not obtain normal quantization parameters.
-
mix. This method is mixed calibration. For each place that needs to be counted, different parameters of the percentile method will be attempted to select the method that minimizes the error (L2 distance) before and after quantization. It is highly automated and does not require adjustment of parameters.
Tuning techniques
-
The more calibration data, the better. However, due to the marginal effect, the improvement in accuracy will be very limited when the data volume becomes large. If the training set is small, all data can be used for calibration. If the training set is large, a suitable subset can be selected based on the time consumption of calibration. It is recommended to perform calibration for at least 10 - 100 steps.
-
Data augmentation such as horizontal flipping is recommended, but mosaic-like augmentation should be avoided. Calibration should be performed using pre-processing from the inference stage plus training data as much as possible.
-
The batch size should be as large as possible. If there is significant noise in the data or a large number of outliers in the model, it can be appropriately reduced. This parameter should be determined when trying the min max method.
-
average_constant indicates the influence of each step on the maximum and minimum values. The smaller the average_constant, the smaller the influence of the current step, and the greater the influence of the history sliding average. This parameter needs to be adjusted between 0.01 and 0.5 depending on the data volume. When the data volume is sufficient (step > 100), average_constant is set to 0.01. When the data volume is insufficient, average_constant can be increased appropriately. In extreme cases where there are only 2 steps of data, average_constant is set to 0.5. This parameter should be determined when trying the min max method and then used in other methods.
-
When the accuracy of the calibration model is good, fixing the quantization parameters of the feature map and performing QAT training can achieve better results. When the accuracy is poor, the fixed calibration quantization parameters should not be used. There is no clear standard for whether the accuracy is good or bad, and it needs to be tried. For example, if the accuracy of a certain model is 100, if the calibration accuracy is 50, then the accuracy is definitely not good. But if the calibration accuracy is 95, then whether this accuracy can reach the level of fixed feature map quantization parameters needs to be tried. The usual practice is to experiment with both fixed and unfixed quantization parameters for comparison.
-
It is recommended to try the min max method first, as it is the fastest. Use it to go through the calibration process, adjust and determine the batch size and average_constant parameters, and then try the percentile, kl, mse, and mix methods separately, selecting the method with the best performance.
Observer Parameters Documentation
class horizon_plugin_pytorch.quantization.observer_v2.KLObserver(bins: int = 512, update_interval: int = 1, averaging_constant: float = 0.01, ch_axis: int = - 1, dtype: Union[torch.dtype, horizon_plugin_pytorch.dtype.QuantDType] = 'qint8', qscheme: torch.qscheme = torch.per_tensor_symmetric, quant_min: int = None, quant_max: int = None, is_sync_quantize: bool = False, factory_kwargs: Dict = None)
KL observer. KL observer based on histogram. Histogram is calculated online and won’t be saved.
Parameters
-
bins - Number of histograms bins.
-
update_interval - Interval of computing KL entropy and update min/max. KLObserver will constantly collect histograms of activations, but only perform KL calculation when update_interval is satisfied. if it is set to 1, KL entropy will be computed every forward step. Larger interval guarantees less time and does no harm to calibration accuracy. Set it to the total calibration steps can achieve best performance. update_interval must be no greater than total calibration steps, otherwise no min/max will be computed.
-
averaging_constant - Averaging constant for min/max.
-
ch_axis - Channel axis.
-
dtype - Quantized data type.
-
qscheme - Quantization scheme to be used.
-
quant_min - Min quantization value. Will follow dtype if unspecified.
-
quant_max - Max quantization value. Will follow dtype if unspecified.
-
is_sync_quantize - If sync statistics when training with multiple devices.
-
factory_kwargs - kwargs which are passed to factory functions for min_val and max_val.
forward(x_orig)
Defines the computation performed at every call.
Should be overridden by all subclasses.
Although the recipe for forward pass needs to be defined within this function, one should call the Module instance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
class horizon_plugin_pytorch.quantization.observer_v2.MSEObserver(stride: int = 1, averaging_constant: float = 0.01, ch_axis: int = - 1, dtype: Union[torch.dtype, horizon_plugin_pytorch.dtype.QuantDType] = 'qint8', qscheme: torch.qscheme = torch.per_tensor_symmetric, quant_min: int = None, quant_max: int = None, is_sync_quantize: bool = False, factory_kwargs: Dict = None)
MSE observer.
Observer module for computing the quantization parameters based on the Mean Square Error (MSE) between the original tensor and the quantized one.
This observer linear searches the quantization scales that minimize MSE.
Parameters
-
stride – Searching stride. Larger value gives smaller search space, which means less computing time but possibly poorer accuracy. Default is 1. Suggests no greater than 20.
-
averaging_constant – Averaging constant for min/max.
-
ch_axis – Channel axis.
-
dtype – Quantized data type.
-
qscheme – Quantization scheme to be used.
-
quant_min – Min quantization value. Will follow dtype if unspecified.
-
quant_max – Max quantization value. Will follow dtype if unspecified.
-
is_sync_quantize – If sync statistics when training with multiple devices.
-
factory_kwargs – kwargs which are passed to factory functions for min_val and max_val.
forward(x_orig)
Defines the computation performed at every call.
Should be overridden by all subclasses.
Although the recipe for forward pass needs to be defined within this function, one should call the Module instance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
class horizon_plugin_pytorch.quantization.observer_v2.MinMaxObserver(averaging_constant: float = 0.01, ch_axis: int = - 1, dtype: Union[torch.dtype, horizon_plugin_pytorch.dtype.QuantDType] = 'qint8', qscheme: torch.qscheme = torch.per_tensor_symmetric, quant_min: int = None, quant_max: int = None, is_sync_quantize: bool = False, factory_kwargs: Dict = None)
Min max observer.
This observer computes the quantization parameters based on minimums and maximums of the incoming tensors. The module records the moving average minimum and maximum of incoming tensors, and uses this statistic to compute the quantization parameters.
Parameters- averaging_constant – Averaging constant for min/max.
- ch_axis – Channel axis.
- dtype – Quantized data type.
- qscheme – Quantization scheme to be used.
- quant_min – Min quantization value. Will follow dtype if unspecified.
- quant_max – Max quantization value. Will follow dtype if unspecified.
- is_sync_quantize – If sync statistics when training with multiple devices.
- factory_kwargs – kwargs which are passed to factory functions for min_val and max_val.
forward(x_orig)
Record the running minimum and maximum of x.
class horizon_plugin_pytorch.quantization.observer_v2.MixObserver(averaging_constant: float = 0.01, ch_axis: int = - 1, dtype: Union[torch.dtype, horizon_plugin_pytorch.dtype.QuantDType] = 'qint8', qscheme: torch.qscheme = torch.per_tensor_symmetric, quant_min: int = None, quant_max: int = None, is_sync_quantize: bool = False, factory_kwargs: Dict = None)
Mix observer.
This observer computes the quantization parameters based on multiple calibration methods and selects the quantization parameters with the smallest quantization error.
Parameters
-
averaging_constant – Averaging constant for min/max.
-
ch_axis – Channel axis.
-
dtype – Quantized data type.
-
qscheme – Quantization scheme to be used.
-
quant_min – Min quantization value. Will follow dtype if unspecified.
-
quant_max – Max quantization value. Will follow dtype if unspecified.
-
is_sync_quantize – If sync statistics when training with multiple devices.
-
factory_kwargs – kwargs which are passed to factory functions for min_val and max_val.
forward(x_orig)
Defines the computation performed at every call.
Should be overridden by all subclasses.
Although the recipe for forward pass needs to be defined within this function, one should call the Module instance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
class horizon_plugin_pytorch.quantization.observer_v2.PercentileObserver(percentile: float = 99.99, bins: int = 2048, averaging_constant: float = 0.01, ch_axis: int = - 1, dtype: Union[torch.dtype, horizon_plugin_pytorch.dtype.QuantDType] = 'qint8', qscheme: torch.qscheme = torch.per_tensor_symmetric, quant_min: int = None, quant_max: int = None, is_sync_quantize: bool = False, factory_kwargs: Dict = None)
Percentile observer.
Percentile observer based on histogram. Histogram is calculated online and won’t be saved. The minimum and maximum are moving averaged to compute the quantization parameters.
Parameters
-
percentile – Index percentile of histrogram
-
bins – Number of histograms bins.
-
averaging_constant – Averaging constant for min/max.
-
ch_axis – Channel axis.
-
dtype – Quantized data type.
-
qscheme – Quantization scheme to be used.
-
quant_min – Min quantization value. Will follow dtype if unspecified.
-
quant_max – Max quantization value. Will follow dtype if unspecified.
-
is_sync_quantize – If sync statistics when training with multiple devices.
-
factory_kwargs – kwargs which are passed to factory functions for min_val and max_val.
forward(x_orig)
Defines the computation performed at every call.
Should be overridden by all subclasses.
Although the recipe for forward pass needs to be defined within this function, one should call the Module instance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
class horizon_plugin_pytorch.quantization.MovingAverageMinMaxObserver(averaging_constant=0.01, dtype=torch.qint8, qscheme=torch.per_tensor_symmetric, quant_min=None, quant_max=None, is_sync_quantize=False, factory_kwargs=None)
MovingAverageMinMax Observer.
Observer module for computing the quantization parameters based on the moving average of the min and max values.
This observer computes the quantization parameters based on the moving averages of minimums and maximums of the incoming tensors. The module records the average minimum and maximum of incoming tensors, and uses this statistic to compute the quantization parameters.
Parameters
-
averaging_constant – Averaging constant for min/max.
-
dtype – Quantized data type
-
qscheme – Quantization scheme to be used, only support per_tensor_symmetric scheme
-
reduce_range – Reduces the range of the quantized data type by 1 bit
-
quant_min – Minimum quantization value.
-
quant_max – Maximum quantization value.
-
is_sync_quantize – Whether use sync quantize
-
factory_kwargs – Arguments for register data buffer
forward(x_orig)
Record the running minimum and maximum of x.
class horizon_plugin_pytorch.quantization.MovingAveragePerChannelMinMaxObserver(averaging_constant=0.01, ch_axis=0, dtype=torch.qint8, qscheme=torch.per_channel_symmetric, quant_min=None, quant_max=None, is_sync_quantize=False, factory_kwargs=None)
MovingAveragePerChannelMinMax Observer.
Observer module for computing the quantization parameters based on the running per channel min and max values.
This observer uses the tensor min/max statistics to compute the per channel quantization parameters. The module records the running minimum and maximum of incoming tensors, and uses this statistic to compute the quantization parameters.
Parameters
-
averaging_constant – Averaging constant for min/max.
-
ch_axis – Channel axis
-
dtype – Quantized data type
-
qscheme – Quantization scheme to be used, Only support per_channel_symmetric
-
quant_min – Minimum quantization value.
-
quant_max – Maximum quantization value.
-
is_sync_quantize – whether use sync quantize
-
factory_kwargs – Arguments for register data buffer
forward(x_orig)
Defines the computation performed at every call.
Should be overridden by all subclasses.
Although the recipe for forward pass needs to be defined within this function, one should call the Module instance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Quantization Training Guide
Quantization training involves inserting some fake quantization nodes into the model to minimize precision loss when converting the quantization-trained model into a fixed-point model. Quantization training is similar to traditional model training, where developers can start from scratch and build a pseudo-quantized model, and then train that pseudo-quantized model. Due to various limitations of the deployed hardware platforms, it is relatively difficult for developers to understand these limitations and build pseudo-quantized models accordingly. The quantization training tool automatically inserts pseudo-quantization operators based on the limitations of the deployment platform into the provided floating-point model, reducing the threshold for developers to develop quantized models.
Quantization training is generally more challenging than training pure floating-point models due to the various restrictions imposed. The goal of the quantization training tool is to reduce the difficulty of quantization training and the engineering complexity of deploying quantized models.
Process and Examples
Although the quantization training tool does not require users to start from a pre-trained floating-point model, experience has shown that starting quantization training from a pre-trained high-precision floating-point model can greatly reduce the difficulty of quantization training.
from horizon_plugin_pytorch.quantization import get_default_qconfig
# Convert the model to QAT state
default_qat_8bit_fake_quant_qconfig = get_default_qconfig(
activation_fake_quant="fake_quant",
weight_fake_quant="fake_quant",
activation_observer="min_max",
weight_observer="min_max",
activation_qkwargs=None,
weight_qkwargs={
"qscheme": torch.per_channel_symmetric,
"ch_axis": 0,
},
)
default_qat_out_8bit_fake_quant_qconfig = get_default_qconfig(
activation_fake_quant=None,
weight_fake_quant="fake_quant",
activation_observer=None,
weight_observer="min_max",
activation_qkwargs=None,
weight_qkwargs={
"qscheme": torch.per_channel_symmetric,
"ch_axis": 0,
},
)
qat_model = prepare_qat_fx(
float_model,
{
"": default_qat_8bit_fake_quant_qconfig,
"module_name": {
"classifier": default_qat_out_8bit_fake_quant_qconfig,
},
},
).to(device)
# Load the quantization parameters from the Calibration model
qat_model.load_state_dict(calib_model.state_dict())
# Perform quantization-aware training
# As a fine-tuning process, quantization-aware training generally requires a smaller learning rate
optimizer = torch.optim.SGD(
qat_model.parameters(), lr=0.0001, weight_decay=2e-4
)
for nepoch in range(epoch_num):
# Note the training state control method for QAT model here
qat_model.train()
set_fake_quantize(qat_model, FakeQuantState.QAT)
train_one_epoch(
qat_model,
nn.CrossEntropyLoss(),optimizer,
None,
train_data_loader,
device,
)
# Note the control method for QAT model eval state here
qat_model.eval()
set_fake_quantize(qat_model, FakeQuantState.VALIDATION)
# Test accuracy of qat model
top1, top5 = evaluate(
qat_model,
eval_data_loader,
device,
)
print(
"QAT model: evaluation Acc@1 {:.3f} Acc@5 {:.3f}".format(
top1.avg, top5.avg
)
)
# Test accuracy of quantized model
quantized_model = convert_fx(qat_model.eval()).to(device)
top1, top5 = evaluate(
quantized_model,
eval_data_loader,
device,
)
print(
"Quantized model: evaluation Acc@1 {:.3f} Acc@5 {:.3f}".format(
top1.avg, top5.avg
)
)
Due to limitations of the underlying platform, QAT models cannot fully represent the accuracy of the final deployed model. It is important to monitor the accuracy of the quantized model to ensure that it is performing as expected, otherwise there may be issues with the deployed model.
From the above example code, it can be seen that quantization-aware training has two additional steps compared to traditional pure floating-point model training:
- prepare_qat_fx
- Load calibration model parameters
prepare_qat_fx
The objective of this step is to transform the floating-point network by inserting quantization nodes.
Loading Calibration Model Parameters
By loading the pseudo quantization parameters obtained from Calibration, a better initialization can be achieved.
Training Iterations
At this point, the construction of the pseudo quantization model and the initialization of the parameters have been completed. Now, regular training iterations and model parameter updates can be performed, while monitoring the accuracy of the quantized model.
Pseudo Quantization Operator
The main difference between quantization training and traditional floating-point model training lies in the insertion of pseudo quantization operators. Different quantization training algorithms are also represented through pseudo quantization operators. Therefore, let's introduce the pseudo quantization operator here.
Since BPU only supports symmetric quantization, we will take symmetric quantization as an example here.
Pseudo Quantization Process
Taking int8 quantization training as an example, the calculation process of the pseudo quantization operator is generally as follows:
fake_quant_x = clip(round(x / scale), -128, 127) * scale
Like Conv2d, which optimizes weight and bias parameters through training, the pseudo quantization operator needs to optimize the scale parameter through training. However, due to the fact that round acts as a step function and its gradient is 0, the pseudo quantization operator cannot be directly trained through gradient backpropagation. To solve this problem, there are usually two solutions: statistical methods and "learning"-based methods.
Statistical Methods
The goal of quantization is to uniformly map floating-point numbers in the Tensor to the range [-128, 127] represented by int8 using the scale parameter. Since it is a uniform mapping, it is easy to calculate the scale:
def compute_scale(x: Tensor):
xmin, xmax = x.max(), maxv = x.min()
return max(xmin.abs(), xmax.abs()) / 256.0
Due to the non-uniform distribution of data in the Tensor and the out-of-range problem, different methods for computing xmin and xmax have emerged. You can refer to MovingAverageMinMaxObserver and other methods.
Please refer to default_qat_8bit_fake_quant_qconfig and related interfaces for usage in the tool.
"Learning"-Based Methods
Although the gradient of round is 0, researchers have found through experiments that setting its gradient to 1 can also make the model converge to the expected accuracy in this scenario.
def round_ste(x: Tensor):
return (x.round() - x).detach() + x
Please refer to default_qat_8bit_lsq_quant_qconfig and its related interfaces for instructions on how to use the tool.
Users who are interested in further understanding can refer to the following paper: Learned Step Size Quantization
Heterogeneous Model Guide
Introduction to Heterogeneous Models
A heterogeneous model is a model where part of it runs on the BPU and the other part runs on the CPU during deployment, as opposed to a homogeneous model which runs entirely on the BPU. Typically, the following two types of models become heterogeneous models during deployment:
-
Models that contain operators not supported by the BPU.
-
Models where certain operators are specified to run on the CPU due to large quantization error.
Workflow

By using 'prepare', the floating-point model is converted into a QAT model, which is then trained and exported as an ONNX format model, and finally converted into a binary model using the hb_mapper tool.
Users can obtain heterogeneous fixed-point models through the conversion process for model accuracy evaluation.
Operator Limitations
Since the heterogeneous model is integrated with horizon_nn, its operator support is the same as that of horizon_nn.
Main Interface Parameter Description
horizon_plugin_pytorch.quantization.prepare_qat_fx
- Set
hybrid=Trueto enable the heterogeneous model functionality. - Users can specify certain BPU-supported operators to run on the CPU by setting the
hybrid_dictparameter.
def prepare_qat_fx(
model: Union[torch.nn.Module, GraphModule],
qconfig_dict: Dict[str, Any] = None,
prepare_custom_config_dict: Dict[str, Any] = None,
optimize_graph: bool = False,
hybrid: bool = False,
hybrid_dict: Dict[str, List] = None,
) -> ObservedGraphModule:
"""Prepare QAT Model
`model`: torch.nn.Module or GraphModule (model after fuse_fx)
`qconfig_dict`: Define Qconfig. If eager mode within module is used in addition to qconfig_dict, the qconfig defined within the module takes priority. The configuration format of qconfig_dict is as follows:
qconfig_dict = {
# Optional, global configuration
"": qconfig,
# Optional, configure by module type
"module_type": [(torch.nn.Conv2d, qconfig), ...],
# Optional, configure by module name
"module_name": [("foo.bar", qconfig),...],
# Priority: global < module_type < module_name < module.qconfig
# The qconfig for non-module types of operators defaults to be consistent with the qconfig of their parent module.
# If you need to set it separately, please encapsulate this part into a separate module.
`prepare_custom_config_dict`: Custom configuration dictionary
prepare_custom_config_dict = {
# Currently only preserved_attributes is supported. Generally, all properties will be automatically preserved.
# This option is just in case, and is rarely used.
"preserved_attributes": ["preserved_attr"],
}
`optimize_graph`: Keep the input and output scale of "cat" consistent. Currently only effective in the Bernoulli architecture.
`hybrid`: Whether to use hybrid mode. Hybrid mode must be enabled in the following cases:
1. The model contains operators not supported by BPU, or the user wants to specify some BPU operators to fall back to CPU.
2. The user wants to quantize the QAT model with horizon_nn.
`hybrid_dict`: Define the user-specified CPU operator.
hybrid_dict = {
# Optional, configure by module type
"module_type": [torch.nn.Conv2d, ...],
# Optional, configure by module name
"module_name": ["foo.bar", ...],
# Priority: module_type < module_name
# Similar to qconfig_dict, if you want non-module types of operators to run on CPU, you need to encapsulate this part into a separate module.
}
"""
horizon_plugin_pytorch.utils.onnx_helper.export_to_onnx
Export the onnx model to integrate with hb_mapper.
This interface also supports non-hybrid models, and the exported ONNX format model is only used for visualization.
def export_to_onnx(
model,
args,
f,
export_params=True,
verbose=False,
training=TrainingMode.EVAL,
input_names=None,
output_names=None,
operator_export_type=OperatorExportTypes.ONNX_FALLTHROUGH,
opset_version=11,
do_constant_folding=True,
example_outputs=None,
strip_doc_string=True,
dynamic_axes=None,
keep_initializers_as_inputs=None,
custom_opsets=None,
enable_onnx_checker=False,
):
"""This interface is basically the same as torch.onnx.export, hiding the parameters that do not need modification. The parameters that need attention are:
`model`: The model to be exported
`args`: Model input for tracing the model
`f`: Filename or file descriptor for saving the onnx file
`operator_export_type`: Operator export type
1. For non-heterogeneous models, onnx is only used for visualization and does not need to be guaranteed to be actually available. The default value is OperatorExportTypes.ONNX_FALLTHROUGH.
2. For heterogeneous models, onnx needs to be guaranteed to be actually available, and None is used to ensure that the exported operator is a standard onnx operator.
`opset_version`: Can only be 11. horizon_plugin_pytorch has registered specific mapping rules in opset 11.
Note: If you use the public torch.onnx.export, make sure the above parameters are set correctly,
and import horizon_plugin_pytorch.utils._register_onnx_ops to register specific mapping rules in opset 11.
"""
horizon_plugin_pytorch.quantization.convert_fx
You can reuse convert_fx to convert the quantized fake quantization model into a heterogeneous quantization model for model accuracy evaluation.
Heterogeneous quantization models obtained through convert_fx cannot be deployed. They are currently only used for model accuracy evaluation.
def convert_fx(
graph_module: GraphModule,
convert_custom_config_dict: Dict[str, Any] = None,
_remove_qconfig: bool = True,
) -> QuantizedGraphModule:
"""Convert the QAT model, only used for evaluating the fixed-point model.
`graph_module`: The model after prepare->(calibration)->train
`convert_custom_config_dict`: Custom configuration dictionary
convert_custom_config_dict = {
# Only support preserved_attributes for now. Generally, all attributes will be automatically preserved, and this option is rarely used.
"preserved_attributes": ["preserved_attr"],
}
`_remove_qconfig`: Whether to remove qconfig after conversion, which is generally not used.
"""
Process and Example1. Transform floating-point model.
-
Insert
QuantStubandDeQuantStubto keep consistent usage with non-heterogeneous mode.-
If the first op is
cpu op, then there is no need to insertQuantStub. -
If the last op is
cpu op, thenDeQuantStubcan be omitted.
-
-
For non-
moduleoperations, if separateqconfigsettings or specifying running on CPU is required, they need to be encapsulated into amodule. Please refer to_SeluModulein the example for details.
-
Set
march. Setbernoulli2for RDK X3 and setbayesfor RDK Ultra. -
Set
qconfig. Retain the configuration method of settingqconfigwithinmodulein non-heterogeneous mode. In addition to this,qconfigcan also be passed through theqconfig_dictparameter of theprepare_qat_fxinterface. For detailed usage, please refer to the interface parameter description.-
For
BPU op, it is necessary to ensure that there is aqconfig. If its input op is notQuantStub, then the input op also needs to have anactivation qconfig. -
For
CPU op,qconfigwill not have any impact on it, but if it is followed by aBPU op, aqconfigmust be specified. -
Recommended setting method: first set the global
qconfigtohorizon.quantization.default_qat_8bit_fake_quant_qconfig(orhorizon.quantization.default_calib_8bit_fake_quant_qconfig, depending on calibration or qat stage), and then modify it according to the requirements. Generally, onlyqconfigforint16and high-precision output ops needs to be set separately.
-
Currently, only the RDK Ultra with the BPU architecture set to BAYES supports setting the int16 quantization.
-
Set
hybrid_dict. Optional, for detailed usage, please refer to the interface parameter description. If there are no explicitly specified CPU ops,hybrid_dictdoes not need to be set. -
Call
prepare_qat_fxand performcalibration. Refer to the Calibration section in the horizon_plugin_pytorch development guide. -
Call
prepare_qat_fx, load thecalibrationmodel, and perform QAT training. Refer to the Quantization Training section in the horizon_plugin_pytorch development guide. -
Call
convert_fx. Optional, can be skipped if there is no need to evaluate the precision of the fixed-point model. -
Call
export_to_onnx.torch.onnx.exportcan also be used, but the precautions in theexport_to_onnxinterface description must be followed. -
Use
hb_mapperto transform the onnx model. After transformation, check whether the operators are running on the expected device. In some cases,hb_mapperstill needs to set therun_on_cpuparameter. For example: althoughconvis not quantized in the QAT stage,hb_mapperwill still default to quantizing it because its input (output of the previous operator) goes through pseudo quantization.
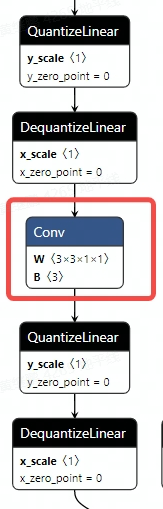
import copy
import numpy as np
import torch
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn import qat
from horizon_plugin_pytorch.quantization import (
prepare_qat_fx,
convert_fx,set_fake_quantize,
FakeQuantState,
load_observer_params,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_calib_8bit_fake_quant_qconfig,
default_calib_out_8bit_fake_quant_qconfig,
default_qat_8bit_fake_quant_qconfig,
default_qat_out_8bit_fake_quant_qconfig,
)
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
from horizon_plugin_pytorch.utils.onnx_helper import export_to_onnx
class _ConvBlock(nn.Module):
def __init__(self, channels=3):
super().__init__()
self.conv = nn.Conv2d(channels, channels, 1)
self.prelu = torch.nn.PReLU()
def forward(self, input):
x = self.conv(input)
x = self.prelu(x)
return torch.nn.functional.selu(x)
# Wrap functional selu into a module for separate setting
class _SeluModule(nn.Module):
def forward(self, input):
return torch.nn.functional.selu(input)
class HybridModel(nn.Module):
def __init__(self, channels=3):
super().__init__()
# Insert QuantStub
self.quant = QuantStub()
self.conv0 = nn.Conv2d(channels, channels, 1)
self.prelu = torch.nn.PReLU()
self.conv1 = _ConvBlock(channels)
self.conv2 = nn.Conv2d(channels, channels, 1)
self.conv3 = nn.Conv2d(channels, channels, 1)
self.conv4 = nn.Conv2d(channels, channels, 1)
self.selu = _SeluModule()
# Insert DequantStub
self.dequant = DeQuantStub()
self.identity = torch.nn.Identity()
def forward(self, input):
x = self.quant(input)
x = self.conv0(x)
x = self.identity(x)x = self.prelu(x)
x = torch.nn.functional.selu(x)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.identity(x)
x = self.conv4(x)
x = self.selu(x)
return self.dequant(x)
# Set march **RDK X3** to BERNOULLI2, and set **RDK Ultra** to BAYES.
set_march(March.BAYES)
data_shape = [1, 3, 224, 224]
data = torch.rand(size=data_shape)
model = HybridModel()
qat_model = copy.deepcopy(model)
# Do not perform inference on the float model after prepare_qat_fx, as prepare_qat_fx modifies the float model in-place.
float_res = model(data)
calibration_model = prepare_qat_fx(
model,
{
"": default_calib_8bit_fake_quant_qconfig,
# selu is a CPU operator, and conv4 is the output of the BPU model, set as high-precision output.
"module_name": [("conv4", default_calib_out_8bit_fake_quant_qconfig)]
},
hybrid=True,
hybrid_dict={
"module_name": ["conv1.conv", "conv3"],
"module_type": [_SeluModule],
},
)
# Ensure the original model does not change during the calibration phase.
calibration_model.eval()
set_fake_quantize(calibration_model, FakeQuantState.CALIBRATION)
for i in range(5):
calibration_model(torch.rand(size=data_shape))
qat_model = prepare_qat_fx(
qat_model,
{
"": default_qat_8bit_fake_quant_qconfig,
# selu is a CPU operator, and conv4 is the output of the BPU model, set as high-precision output.
"module_name": [("conv4", default_qat_out_8bit_fake_quant_qconfig)]
},
hybrid=True,
hybrid_dict={
"module_name": ["conv1.conv", "conv3"],
"module_type": [_SeluModule],
},
)
load_observer_params(calibration_model, qat_model)
set_fake_quantize(calibration_model, FakeQuantState.QAT)
# qat training start
# ......
# qat training end
# Export qat.onnx
export_to_onnx(
qat_model,
data,
"qat.onnx",
operator_export_type=None,
)
# Evaluate quantized model
quantize_model = convert_fx(qat_model)
quantize_res = quantize_model(data)
Print the results of the QAT model.
HybridModel(
(quant): QuantStub(
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_tensor_symmetric, ch_axis=-1, scale=tensor([0.0078]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=tensor([-0.9995]), max_val=tensor([0.9995]))
)
)
(conv0): Conv2d(
3, 3, kernel_size=(1, 1), stride=(1, 1)
(weight_fake_quant): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_channel_symmetric, ch_axis=0, scale=tensor([0.0038, 0.0041, 0.0016]), zero_point=tensor([0, 0, 0])
(activation_post_process): MovingAveragePerChannelMinMaxObserver(min_val=tensor([-0.4881, -0.4944, 0.0787]), max_val=tensor([-0.1213, 0.5284, 0.1981]))
)
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_tensor_symmetric, ch_axis=-1, scale=tensor([0.0064]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=tensor([-0.8159]), max_val=tensor([0.8159]))
)
)
(prelu): PReLU(num_parameters=1)
(conv1): _ConvBlock(
(conv): Conv2d(3, 3, kernel_size=(1, 1), stride=(1, 1))
(prelu): PReLU(num_parameters=1)
)
(conv2): Conv2d(3, 3, kernel_size=(1, 1), stride=(1, 1)
(weight_fake_quant): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_channel_symmetric, ch_axis=0, scale=tensor([0.0040, 0.0044, 0.0040]), zero_point=tensor([0, 0, 0])
(activation_post_process): MovingAveragePerChannelMinMaxObserver(
min_val=tensor([-0.5044, -0.4553, -0.5157]), max_val=tensor([0.1172, 0.5595, 0.4104])
)
)
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_tensor_symmetric, ch_axis=-1, scale=tensor([0.0059]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(
min_val=tensor([-0.7511]), max_val=tensor([0.7511])
)
)
(conv3): Conv2d(3, 3, kernel_size=(1, 1), stride=(1, 1))
(conv4): Conv2d(
3, 3, kernel_size=(1, 1), stride=(1, 1)
(weight_fake_quant): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_channel_symmetric, ch_axis=0, scale=tensor([0.0025, 0.0037, 0.0029]), zero_point=tensor([0, 0, 0])
(activation_post_process): MovingAveragePerChannelMinMaxObserver(
min_val=tensor([-0.2484, -0.4718, -0.3689]), max_val=tensor([0.3239, -0.0056, 0.3312])
)
)
(activation_post_process): None
)
(selu): _SeluModule()
(dequant): DeQuantStub()
(identity): Identity()
(prelu_input_dequant): DeQuantStub()
(selu_1_activation_post_process): _WrappedCalibFakeQuantize(
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_tensor_symmetric, ch_axis=-1, scale=tensor([0.0042]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(
min_val=tensor([-0.5301]), max_val=tensor([0.5301])
)
)
)
(conv3_activation_post_process): _WrappedCalibFakeQuantize(
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_tensor_symmetric, ch_axis=-1, scale=tensor([0.0072]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(
min_val=tensor([-0.9156]), max_val=tensor([0.9156])
)
)
)
(conv3_input_dequant): DeQuantStub()
(selu_2_input_dequant): DeQuantStub()
)
def forward(self, input):
input_1 = input
quant = self.quant(input_1); input_1 = None
conv0 = self.conv0(quant); quant = None
identity = self.identity(conv0); conv0 = None
prelu_input_dequant_0 = self.prelu_input_dequant(identity); identity = None
prelu = self.prelu(prelu_input_dequant_0); prelu_input_dequant_0 = None
selu = torch.nn.functional.selu(prelu, inplace = False); prelu = None
conv1_conv = self.conv1.conv(selu); selu = None
conv1_prelu = self.conv1.prelu(conv1_conv); conv1_conv = None
selu_1 = torch.nn.functional.selu(conv1_prelu, inplace = False); conv1_prelu = None
selu_1_activation_post_process = self.selu_1_activation_post_process(selu_1); selu_1 = None
conv2 = self.conv2(selu_1_activation_post_process); selu_1_activation_post_process = None
conv3_input_dequant_0 = self.conv3_input_dequant(conv2); conv2 = None
conv3 = self.conv3(conv3_input_dequant_0); conv3_input_dequant_0 = None
conv3_activation_post_process = self.conv3_activation_post_process(conv3); conv3 = None
identity_1 = self.identity(conv3_activation_post_process); conv3_activation_post_process = None
conv4 = self.conv4(identity_1); identity_1 = None
selu_2_input_dequant_0 = self.selu_2_input_dequant(conv4); conv4 = None
selu_2 = torch.nn.functional.selu(selu_2_input_dequant_0, inplace = False); selu_2_input_dequant_0 = None
dequant = self.dequant(selu_2); selu_2 = None
return dequant
The exported ONNX model shown in the image contains CPU operators highlighted in red circles.
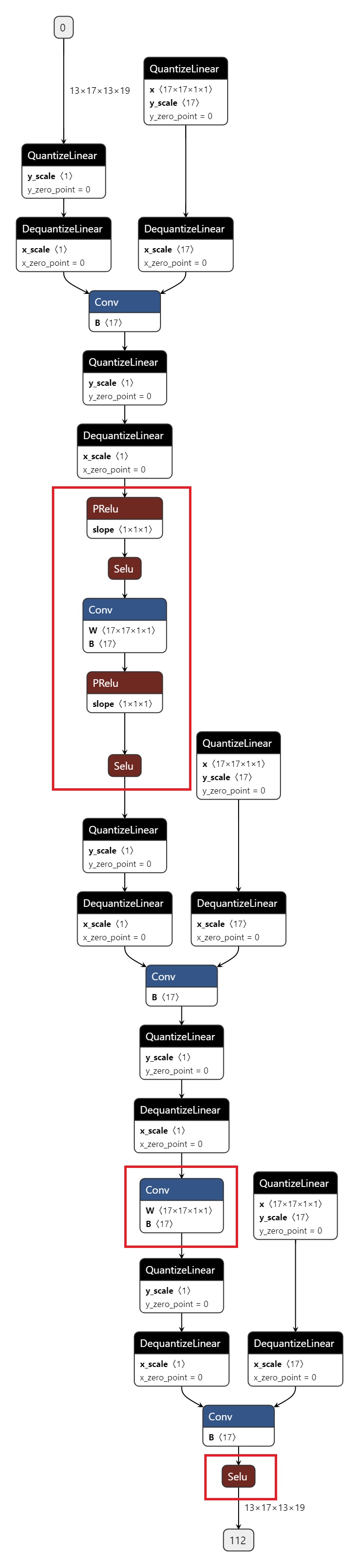
Guide to Analysis Tools
When encountering precision issues with QAT or quantized models, you can use various tools provided to analyze the models and identify precision drop points.
Overview
The following table summarizes the usage interfaces and scenarios of various tools. Except for the model visualization tool, all other tools are in the horizon_plugin_pytorch.utils.quant_profiler package.
| Tool | Usage Interface/Method | Scenario |
|---|---|---|
| Integration Interface | model_profiler | Call other debug tools and display the results centrally in an HTML page; Currently, it calls similarity, statistics, shared op check, fuse check, weight comparison, and quantization configuration check tools. |
| Fuse Check | check_unfused_operations | Check if there are op patterns in floating-point models that can be fused but are not fused. |
| Shared Op Check | get_module_called_count | Check if there are shared-used ops in the model. |
| Quantization Configuration Check | check_qconfig | Check if the quantization configuration in the QAT model meets expectations. |
| Model Visualization | export_to_onnx export_quantized_onnx | Export ONNX models to view the model structure. Does not support ONNX run. |
| Similarity Comparison | featuremap_similarity | Locate problematic ops when the precision of quantized models decreases. |
| Statistics | get_raw_features / profile_featuremap | Output numerical features of each layer's output in the model to evaluate whether the current data distribution and quantization precision are suitable for quantization. |
| Model Weight Comparison | compare_weights | Compare the similarity of weights in each layer of the model. |
| Step Quantization | qconfig=None | When training QAT models is difficult, identify the bottleneck of precision loss by setting a part of the model to floating point. |
| Single Operator Conversion Precision Debugging | set_preserve_qat_mode | When the precision of QAT model conversion to fixed point decreases, identify the bottleneck of precision loss by replacing some ops in the fixed-point model with QAT forms using this interface. |
| Heterogeneous Model Deployment Device Check | check_deploy_device | Check whether each op runs on BPU or CPU as expected during the deployment of heterogeneous models. |
| Comparison of TorchScript and HBDK Results | script_profile | Compare whether the results of each op in the fixed-point pt generated by horizon_plugin_pytorch and HBDK are consistent. |
| Comparison of Results of Different Versions of TorchScript | compare_script_models | Compare the results of each op in the fixed-point pt generated by horizon_plugin_pytorch using different versions. |
| Model CUDA Memory Consumption Analysis Tool | show_cuda_memory_consumption | Analyze the model's CUDA memory consumption to identify memory bottlenecks. |
Integrated Interface
For convenience in usage and visualization, horizon_plugin_pytorch provides an integrated interface model_profiler. This interface invokes other debug tools and consolidates the results into an HTML page, where the results of all other debug tools are also simultaneously saved. Currently, it invokes several tools including similarity analysis, statistics, shared operation check, fuse check, weight comparison, and quantization configuration check.
This interface involves the comparison between two models. In fx mode, the model conversion process is by default inplace. If you need to use this tool, please manually deepcopy the original model before conversion. Otherwise, after conversion, it will incorrectly compare two identical models.
# from horizon_plugin_pytorch.utils.quant_profiler import model_profiler
def model_profiler(
model1: torch.nn.Module,
model2: torch.nn.Module,
example_inputs: Any,
mode: str,
out_dir: Optional[str] = None,
kwargs_dict: Optional[dict] = None,
):
"""Run various inspection and analysis tools and display the results in one HTML page.
This function will compare:
1) The similarity and statistics of each op in two models, and the similarity of weights, while checking shared ops in the model.
2) Check if there are unfused patterns in the floating point model and the quantization configuration in the QAT model.
The results will be displayed in `profiler.html`.
Note:
1) This interface only supports comparing adjacent stages of the same model, in the order of conversion. For example, "floating point vs QAT" or "QAT vs fixed point". Comparing directly between floating point and fixed point models, or using the order of "QAT model vs floating point model" is not supported.
2) The ONNX visualization of the model structure as well as the histogram of feature maps of each layer are not displayed in the HTML page. You can manually call `export_to_onnx/export_quantized_onnx` and `profile_featuremap(with_tensorboard=True)`. In addition, this interface also supports passing custom arguments for calling each debug tool through the `kwargs_dict` parameter.
Parameters:
model1: Floating Point/Calibrated/QAT model
model2: Calibrated/QAT/Fixed Point model
example_inputs: Model input
mode: Indicates which two models to compare, only supports the following three modes
- `FvsQ`: Floating point model vs QAT/calibration model
- `QvsQ`: QAT model vs quantized model
- `CvsQ`: Calibration model vs QAT model
out_dir: Specify the result file `profiler.html` and the path for all debug tool invocation results. Default is `None`, which will generate a `profiler` directory in the `ckpt_dir` specified directory or the current directory, and store all results in that directory.
kwargs_dict: Parameters for calling other debug tools, provided as a `dict`. **You can refer to the specific introduction of each tool above for the specific parameters.** Support 7 key values
1) `featuremap_similarity`: similarity
2) `get_raw_features`: calculate the relevant features of each layer op input/output feature
3) `profile_featuremap`: statistics function, output the maximum, minimum, mean, and variance of each layer results in the model
4) `get_module_called_count`: check if there are shared ops in the model5) `check_unfused_operations`: Check if the model has unfused patterns
6) `compare_weights`: Compare the similarity of weights in two models
7) `check_qconfig`: Check the Qconfig configuration in the QAT model
Note:
1) The parameters `model` and `example_inputs` are defined in the `model_profiler` interface. The `kwargs_dict` must not have definitions for these two parameters.
2) The `out_dir` parameter in `kwargs_dict` will be replaced by the `out_dir` parameter in the `model_profiler` interface.
"""
Example usage:
from copy import deepcopy
import numpy as np
import pytest
import torch
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
import horizon_plugin_pytorch as horizon
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.qat_mode import QATMode, set_qat_mode
from horizon_plugin_pytorch.quantization import (
convert_fx,
prepare_qat_fx,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch.utils.quant_profiler import model_profiler
class Conv2dModule(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=1,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode="zeros",
):
super().__init__()
self.conv2d = nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
dilation,
groups,
bias,
padding_mode,
)
self.add = FloatFunctional()
self.bn_mod = nn.BatchNorm2d(out_channels)
self.relu_mod = nn.ReLU()
def forward(self, x, y):
x = self.conv2d(x)
x = self.bn_mod(x)
x = self.add.add(x, y)
x = self.relu_mod(x)
return x
class TestFuseNet(nn.Module):
def __init__(self, channels) -> None:
super().__init__()
self.quantx = QuantStub()
self.quanty = QuantStub()
self.convmod1 = Conv2dModule(channels, channels)
self.convmod2 = Conv2dModule(channels, channels)
self.convmod3 = Conv2dModule(channels, channels)
self.shared_conv = nn.Conv2d(channels, channels, 1)
self.bn1 = nn.BatchNorm2d(channels)
self.bn2 = nn.BatchNorm2d(channels)
self.sub = FloatFunctional()
self.relu = nn.ReLU()
self.dequant = DeQuantStub()
def forward(self, x, y):
x = self.quantx(x)
y = self.quanty(y)
x = self.convmod1(x, y)
x = self.convmod2(y, x)
x = self.convmod3(x, y)
x = self.shared_conv(x)
x = self.bn1(x)
y = self.shared_conv(y)
y = self.bn2(y)
x = self.sub.sub(x, y)
x = self.relu(x)
return self.dequant(x)
# **RDK X3** sets BERNOULLI2, **RDK Ultra** sets BAYES.
set_march(March.BAYES)
device = torch.device("cpu")
data = torch.arange(1 * 3 * 4 * 4) / 100 + 1
data = data.reshape((1, 3, 4, 4))
data = data.to(torch.float32).to(device)
float_net = TestFuseNet(3).to(device)
float_net(data, data)
qat_net = prepare_qat_fx(float_net, {"": default_qat_8bit_fake_quant_qconfig})
qat_net = qat_net.to(device)
qat_net(data, data)
# Need to deepcopy the model before conversion in fx mode
qat_net2 = deepcopy(qat_net)
quantized_net = convert_fx(qat_net2)
model_profiler(qat_net, quantized_net, (data, data), mode="QvsQ")
If the out_dir parameter is not specified, a horizon_quant_debug folder will be generated in the current directory, and profiler.html and the results of various debug tools will be saved in that folder. For a detailed explanation of the output of each debug tool, please refer to the specific introduction of each tool below.
Fuse Check
The correctness of the model fuse involves two aspects:
- Whether the fusable operators have been fused.
- Whether the fused operators are correct.
This interface can only check the first case. For the second case, please use a similarity comparison tool to compare the feature similarity of the model before and after fusion. If you find that the feature similarity is problematic for all features after a certain operator, the fusion of this operator may be incorrect (the fusion process combines several ops into one, and uses Identity to replace other locations, so it is normal for feature similarity to be low at these Identity positions).
This interface only accepts input of floating-point models.
# from horizon_plugin_pytorch.utils.quant_profiler import check_unfused_operations
def check_unfused_operations(
model: torch.nn.Module,
example_inputs,
print_tabulate=True,
):
"""Check if there are unfused ops in the model.
This interface can only check if there are unfused ops. It cannot check the correctness of the fusion. If you want to check if the fusion of ops is correct,
please use the `featuremap_similarity` interface to compare the similarity between the pre-fusion and post-fusion models.
Parameters:
model: input model
example_inputs: model input parameters
print_tabulate: whether to print the result. The default is True.
Output:
List[List[str]]: a list of fusionable op patterns
Example Usage:
This is an example in eager mode (manually define fuse pattern and call fuse function). If using fx for quantization, all fusionable patterns in the model will be fused automatically.
import horizon_plugin_pytorch as horizon
import numpy as np
import torch
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.utils.quant_profiler import check_unfused_operations
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
class Conv2dModule(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=1,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode="zeros",
):
super().__init__()
self.conv2d = nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
dilation,groups,
bias,
padding_mode,
)
self.add = FloatFunctional()
self.bn_mod = nn.BatchNorm2d(out_channels)
self.relu_mod = nn.ReLU()
def forward(self, x, y):
x = self.conv2d(x)
x = self.bn_mod(x)
x = self.add.add(x, y)
x = self.relu_mod(x)
return x
def fuse_model(self):
from horizon_plugin_pytorch.quantization import fuse_modules
fuse_list = ["conv2d", "bn_mod", "add", "relu_mod"]
fuse_modules(
self,
fuse_list,
inplace=True,
)
class TestFuseNet(nn.Module):
def __init__(self, channels) -> None:
super().__init__()
self.convmod1 = Conv2dModule(channels, channels)
self.convmod2 = Conv2dModule(channels, channels)
self.convmod3 = Conv2dModule(channels, channels)
self.shared_conv = nn.Conv2d(channels, channels, 1)
self.bn1 = nn.BatchNorm2d(channels)
self.bn2 = nn.BatchNorm2d(channels)
self.sub = FloatFunctional()
self.relu = nn.ReLU()
def forward(self, x, y):
x = self.convmod1(x, y)
x = self.convmod2(y, x)
x = self.convmod3(x, y)
x = self.shared_conv(x)
x = self.bn1(x)
y = self.shared_conv(y)
y = self.bn2(y)
x = self.sub.sub(x, y)
x = self.relu(x)
return x
def fuse_model(self):
self.convmod1.fuse_model()
self.convmod3.fuse_model()
shape = np.random.randint(10, 20, size=4).tolist()
data0 = torch.rand(size=shape)
data1 = torch.rand(size=shape)
float_net = TestFuseNet(shape[1])
float_net.fuse_model()
check_unfused_operations(float_net, (data0, data1))
The output result is as follows:
name type
------------------- ------------------------------------------------
shared_conv(shared) <class 'torch.nn.modules.conv.Conv2d'>
bn1 <class 'torch.nn.modules.batchnorm.BatchNorm2d'>
name type
------------------- ------------------------------------------------
shared_conv(shared) <class 'torch.nn.modules.conv.Conv2d'>
bn2 <class 'torch.nn.modules.batchnorm.BatchNorm2d'>
name type
----------------- --------------------------------------------------------------------------------
convmod2.conv2d <class 'torch.nn.modules.conv.Conv2d'>
convmod2.bn_mod <class 'torch.nn.modules.batchnorm.BatchNorm2d'>
convmod2.add <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.FloatFunctional'>
convmod2.relu_mod <class 'torch.nn.modules.activation.ReLU'>
Each group of patterns that can be fused but are not fused will be outputted in a tabular format, with the first column indicating the name of the module defined in the model, and the second column indicating the type of the module.
Shared Operation Check
This interface calculates and prints the number of times each operation is called in one forward pass of the model, thereby checking for shared operations in the model. If a module instance appears multiple times in the model with different names, the function will use the first name and record all calls under that name (you may see related warnings).
# from horizon_plugin_pytorch.utils.quant_profiler import get_module_called_count
def get_module_called_count(
model: torch.nn.Module,
example_inputs,
check_leaf_module: callable = None,
print_tabulate: bool = True,
) -> Dict[str, int]:
"""Calculate the number of calls to leaf nodes in the model.
Parameters:
model: The model.
example_inputs: Input to the model.
check_leaf_module: Check whether the module is a leaf node. Default is None,
using the predefined is_leaf_module, treating all defined operations in
horizon_plugin_pytorch as well as unsupported floating point operations
as leaf nodes.
print_tabulate: Whether to print the results. Default is True.
Output:
Dict[str, int]: The name of each layer in the model and the corresponding
number of calls.
"""
Example usage:
import numpy as np
import torch
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
import horizon_plugin_pytorch as horizon
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.utils.quant_profiler import get_module_called_count
class Net(nn.Module):
def __init__(self, quant=False, share_op=True):
super(Net, self).__init__()
self.quant_stubx = QuantStub()
self.quant_stuby = QuantStub()
self.mul_op = FloatFunctional()
self.cat_op = FloatFunctional()
self.quantized_ops = nn.Sequential(
nn.ReLU(),
nn.Sigmoid(),
nn.Softmax(),
nn.SiLU(),
horizon_nn.Interpolate(
scale_factor=2, recompute_scale_factor=True
),
horizon_nn.Interpolate(
scale_factor=2.3, recompute_scale_factor=True
),
nn.AvgPool2d(kernel_size=4),
nn.Upsample(scale_factor=1.3, mode="bilinear"),
nn.UpsamplingBilinear2d(scale_factor=0.7),
)
self.dequant_stub = DeQuantStub()
self.float_ops = nn.Sequential(
nn.Tanh(),
nn.LeakyReLU(),
nn.PReLU(),
nn.UpsamplingNearest2d(scale_factor=0.7),
)
self.quant = quant
self.share_op = share_op
def forward(self, x, y):
x = self.quant_stubx(x)
y = self.quant_stuby(y)
z = self.mul_op.mul(x, y)
x = self.cat_op.cat((x, y), dim=1)
if self.share_op:
x = self.cat_op.cat((x, y), dim=1)
x = self.quantized_ops(x)
x = self.dequant_stub(x)
if not self.quant:
x = self.float_ops(x)
return x
shape = np.random.randint(10, 20, size=4).tolist()
data0 = torch.rand(size=shape)
data1 = torch.rand(size=shape)
float_net = Net()
get_module_called_count(float_net, (data0, data1))
The output is a table that records the number of times each module in the model is called. Normally, each module is called once; if it is called 0 times, it means that the module is defined but not used; if it is called more than once, it means that the module is shared and used multiple times:
name called times
--------------- --------------
quant_stubx 1
quant_stuby 1
unused 0
mul_op 1
cat_op 2
quantized_ops.0 1
quantized_ops.1 1
quantized_ops.2 1
quantized_ops.3 1
quantized_ops.4 1
quantized_ops.5 1
quantized_ops.6 1
quantized_ops.7 1
quantized_ops.8 1
dequant_stub 1
float_ops.0 1
float_ops.1 1
float_ops.2 1
float_ops.3 1
Quantization Configuration Check
Check the quantization configurations for each op of the calibration/QAT model. The input must be a QAT or calibration model. The output will be saved in the qconfig_info.txt file.
# from horizon_plugin_pytorch.utils.quant_profiler import check_qconfig
def check_qconfig(
model: torch.nn.Module,
example_inputs: Any,
prefixes: Tuple = (),
types: Tuple = (),
custom_check_func: Optional[Callable] = None,
out_dir: Optional[str] = None,
):
"""Check the quantization configurations for the calibration/QAT model.
This function will
1) Check the quantization configurations for the output activations and weights
of each layer in the model. The configuration information will be saved in the
`qconfig_info.txt` file.
2) Check the input and output types for each layer in the model.
By default, the function will print a warning message for the following cases:
1) Output layer activation is not quantized.
2) Fixed scale.
3) Weight is quantized to a non-int8 type (currently only int8 quantization is supported).
4) Input and output types of the model are different.
If you want to check for more information, you can pass a custom check function
through `custom_check_func`.
Parameters:
model: The input model, must be a QAT model.
example_inputs: Model inputs.
prefixes: Specify the layer names (starting with prefixes) of the ops to check
the quantization configurations.
types: Specify the types of the ops to check the quantization configurations.
custom_check_func: Custom function for checking additional information. This
function will be called within a module's hook, so it needs to be defined in the
following format:
func(module, input, output) -> None
out_dir: The path to save the result file `qconfig_info.txt`. If None, it will
be saved in the current path.
"""
Example usage:
import numpy as np
import torch
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.dtype import qint16
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.quantization import get_default_qconfig
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch.quantization.quantize_fx import (
convert_fx,
prepare_qat_fx,
)
from horizon_plugin_pytorch.quantization.observer import FixedScaleObserver
from horizon_plugin_pytorch.utils.quant_profiler import check_qconfig
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
class Conv2dModule(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=1,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode="zeros",
):
super().__init__()
self.conv2d = nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
dilation,
groups,
bias,
padding_mode,
)self.add = FloatFunctional()
self.bn_mod = nn.BatchNorm2d(out_channels)
self.relu_mod = nn.ReLU()
def forward(self, x, y):
x = self.conv2d(x)
x = self.bn_mod(x)
x = self.add.add(x, y)
x = self.relu_mod(x)
return x
class TestFuseNet(nn.Module):
def __init__(self, channels) -> None:
super().__init__()
self.convmod1 = Conv2dModule(channels, channels)
self.convmod2 = Conv2dModule(channels, channels)
self.convmod3 = Conv2dModule(channels, channels)
self.shared_conv = nn.Conv2d(channels, channels, 1)
self.bn1 = nn.BatchNorm2d(channels)
self.bn2 = nn.BatchNorm2d(channels)
self.sub = FloatFunctional()
self.relu = nn.ReLU()
def forward(self, x, y):
x = self.convmod1(x, y)
x = self.convmod2(y, x)
x = self.convmod3(x, y)
x = self.shared_conv(x)
x = self.bn1(x)
y = self.shared_conv(y)
y = self.bn2(y)
x = self.sub.sub(x, y)
x = self.relu(x)
return x
float_net = TestFuseNet(3)
# **RDK X3** set BERNOULLI2, **RDK Ultra** set BAYES
set_march(March.BAYES)
# Manually construct unsupported or special cases
sub_qconfig = get_default_qconfig(
# Fixed sub's output scale
activation_qkwargs={
"observer": FixedScaleObserver,
"scale": 1 / 2 ** 15,"dtype": qint16,
}
)
qat_net = prepare_qat_fx(
float_net,
{
"": get_default_qconfig(
weight_qkwargs={
"qscheme": torch.per_channel_symmetric,
"ch_axis": 0,
# Does not support int16 quantization for weight
"dtype": qint16,
}
),
"module_name": [("sub", sub_qconfig)]
}
)
shape = np.random.randint(10, 20, size=4).tolist()
shape[1] = 3
data0 = torch.rand(size=shape)
data1 = torch.rand(size=shape)
check_qconfig(qat_net, (data0, data1))
Output:
-
qconfig_info.txt
Each layer out qconfig:
+-------------------+----------------------------------------------------------------------------+--------------------+-------------+----------------+
| Module Name | Module Type | Input dtype | out dtype | ch_axis |
|-------------------+----------------------------------------------------------------------------+--------------------+-------------+----------------|
| quantx | <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | torch.float32 | qint8 | -1 |
| quanty | <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | torch.float32 | qint8 | -1 |
| convmod1.add | <class 'horizon_plugin_pytorch.nn.qat.conv2d.ConvAddReLU2d'> | ['qint8', 'qint8'] | qint8 | -1 |
| convmod2.conv2d | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint8 | qint8 | -1 |
| convmod2.bn_mod | <class 'horizon_plugin_pytorch.nn.qat.batchnorm.BatchNorm2d'> | qint8 | qint8 | -1 |
| convmod2.add[add] | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | ['qint8', 'qint8'] | qint8 | -1 |
| convmod2.relu_mod | <class 'horizon_plugin_pytorch.nn.qat.relu.ReLU'> | qint8 | qint8 | qconfig = None |
| convmod3.add | <class 'horizon_plugin_pytorch.nn.qat.conv2d.ConvAddReLU2d'> | ['qint8', 'qint8'] | qint8 | -1 |
| shared_conv | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint8 | qint8 | -1 |
| bn1 | <class 'horizon_plugin_pytorch.nn.qat.batchnorm.BatchNorm2d'> | qint8 | qint8 | -1 |
| shared_conv(1) | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint8 | qint8 | -1 |
| bn2 | <class 'horizon_plugin_pytorch.nn.qat.batchnorm.BatchNorm2d'> | qint8 | qint8 | -1 |
| sub[sub] | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | ['qint8', 'qint8'] | qint16 | -1 |
| relu | <class 'horizon_plugin_pytorch.nn.qat.relu.ReLU'> | qint16 | qint16 | qconfig = None |
+-------------------+----------------------------------------------------------------------------+--------------------+-------------+----------------+
Weight qconfig:
+-----------------+--------------------------------------------------------------+----------------+-----------+
| Module Name | Module Type | weight dtype | ch_axis |
|-----------------+--------------------------------------------------------------+----------------+-----------|
| convmod1.add | <class 'horizon_plugin_pytorch.nn.qat.conv2d.ConvAddReLU2d'> | qint16 | 0 |
| convmod2.conv2d | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint16 | 0 |
| convmod3.add | <class 'horizon_plugin_pytorch.nn.qat.conv2d.ConvAddReLU2d'> | qint16 | 0 |
| shared_conv | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint16 | 0 |
| shared_conv(1) | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint16 | 0 |
+-----------------+--------------------------------------------------------------+----------------+-----------+
Please check if these OPs qconfigs are expected..
+-----------------+----------------------------------------------------------------------------+------------------------------------------------------------------+
| Module Name | Module Type | Msg |
|-----------------+----------------------------------------------------------------------------+------------------------------------------------------------------|
| convmod1.add | <class 'horizon_plugin_pytorch.nn.qat.conv2d.ConvAddReLU2d'> | qint16 weight!!! |
| convmod2.conv2d | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint16 weight!!! |
| convmod3.add | <class 'horizon_plugin_pytorch.nn.qat.conv2d.ConvAddReLU2d'> | qint16 weight!!! |
| shared_conv | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint16 weight!!! |
| shared_conv(1) | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint16 weight!!! |
| sub[sub] | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | input dtype ['qint8', 'qint8'] is not same with out dtype qint16 |
| sub[sub] | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | Fixed scale 3.0517578125e-05 |
+-----------------+----------------------------------------------------------------------------+------------------------------------------------------------------+
The output txt file contains three tables in the following order:
-
Quantization information for each layer, from left to right columns represent:
- Module Name: the name of each module defined in the model
- Module Type: the actual type of each module
- Input dtype: the input type of each module
- out dtype: the output type of each module
- ch_axis: the dimension on which the quantization is performed. -1 indicates per-tensor quantization; if qconfig=None is displayed, it means that the module does not have a qconfig and will not be quantized
-
Quantization information for the weights in each layer, from left to right columns represent:
- Module Name: the name of each module defined in the model
- Module Type: the actual type of each module
- weight dtype: the quantization precision used for the weights, currently only support qint8 quantization
- ch_axis: the dimension on which the quantization is performed. -1 indicates per-tensor quantization; by default, weights are quantized on the 0th dimension. If qconfig=None is displayed, it means that the weights of the module do not have a qconfig and will not be quantized
-
Modules in the model with special quantization configurations (does not indicate configuration errors, need to be checked one by one). This table will also be displayed on the screen.
- Module Name: the name of each module defined in the model
- Module Type: the actual type of each module
- Msg: special quantization configuration
-
Screen output
Please check if these OPs qconfigs are expected..
+---------------+----------------------------------------------------------------------------+------------------------------------------------------------------+
| Module Name | Module Type | Msg |
|---------------+----------------------------------------------------------------------------+------------------------------------------------------------------|
| convmod1.add | <class 'horizon_plugin_pytorch.nn.qat.conv2d.ConvAddReLU2d'> | qint16 weight!!! |
| convmod2.add | <class 'horizon_plugin_pytorch.nn.qat.conv2d.ConvAddReLU2d'> | qint16 weight!!! |
| convmod3.add | <class 'horizon_plugin_pytorch.nn.qat.conv2d.ConvAddReLU2d'> | qint16 weight!!! |
| bn1 | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint16 weight!!! |
| shared_conv | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint16 weight!!! |
| sub | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | input dtype ['qint8', 'qint8'] is not same with out dtype qint16 |
| sub | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | Fixed scale 3.0517578125e-05 |
+---------------+----------------------------------------------------------------------------+------------------------------------------------------------------+
Visualization: ONNX Model Visualization
Currently, horizon_plugin_pytorch supports visualizing models at any stage. Visualization here refers to visualizing the model structure, and the default export format is ONNX, which can be viewed using netron. The exported ONNX model currently does not support inference, only support visualizing the model structure.
# from horizon_plugin_pytorch.utils.onnx_helper import (
# export_to_onnx,
# export_quantized_onnx,
# )
export_to_onnx(
model,
args,
f,
export_params=True,
verbose=False,
training=TrainingMode.EVAL,
input_names=None,
output_names=None,
operator_export_type=OperatorExportTypes.ONNX_FALLTHROUGH,
do_constant_folding=True,
example_outputs=None,
dynamic_axes=None,
enable_onnx_checker=False,
)
export_quantized_onnx(
model,
args,
f,
export_params=True,
verbose=False,
training=TrainingMode.EVAL,
input_names=None,
output_names=None,operator_export_type=OperatorExportTypes.ONNX_FALLTHROUGH,
opset_version=None,
do_constant_folding=True,
example_outputs=None,
dynamic_axes=None,
keep_initializers_as_inputs=None,
custom_opsets=None,
)
The meanings of the parameters are consistent with torch.onnx.export, except for the parameter operator_export_type=OperatorExportTypes.ONNX_FALLTHROUGH .
Note when using:
-
For exporting ONNX of floating-point models and QAT models, please use
export_to_onnx. -
For exporting ONNX of fixed-point models, please use
export_quantized_onnx. -
The granularity of visualization is as follows:
-
Custom ops in horizon_plugin_pytorch, including floating-point ops and fixed-point ops, the implementation inside the op will not be visualized.
-
The granularity of visualization for community ops used in floating-point models is determined by the community.
-
Example usage:
from copy import deepcopy
import torch
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
import horizon_plugin_pytorch as horizon
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.quantization.quantize_fx import (
convert_fx,
prepare_qat_fx,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.utils.onnx_helper import (
export_to_onnx,
export_quantized_onnx,
)
class Net(nn.Module):
def __init__(self, quant=False, share_op=True):
super(Net, self).__init__()
self.quant_stubx = QuantStub()
self.quant_stuby = QuantStub()
self.mul_op = FloatFunctional()
self.cat_op = FloatFunctional()
self.quantized_ops = nn.Sequential(
nn.ReLU(),
nn.Sigmoid(),
nn.Softmax(),
nn.SiLU(),
horizon_nn.Interpolate(
scale_factor=2, recompute_scale_factor=True
),
horizon_nn.Interpolate(
scale_factor=2.3, recompute_scale_factor=True
),
nn.AvgPool2d(kernel_size=4),
nn.Upsample(scale_factor=1.3, mode="bilinear"),
nn.UpsamplingBilinear2d(scale_factor=0.7),
)
self.dequant_stub = DeQuantStub()
self.float_ops = nn.Sequential(
nn.Tanh(),
nn.LeakyReLU(),
nn.PReLU(),
nn.UpsamplingNearest2d(scale_factor=0.7),
)
self.quant = quant
self.share_op = share_op
def forward(self, x, y):
x = self.quant_stubx(x)
y = self.quant_stuby(y)
z = self.mul_op.mul(x, y)
x = self.cat_op.cat((x, y), dim=1)
if self.share_op:
x = self.cat_op.cat((x, y), dim=1)
x = self.quantized_ops(x)
x = self.dequant_stub(x)
if not self.quant:
x = self.float_ops(x)
return x
# **RDK X3** set BERNOULLI2, **RDK Ultra** set as BAYES。
set_march(March.BAYES)
device = torch.device("cuda")
float_net = Net(quant=True, share_op=True).to(device)
float_net2 = deepcopy(float_net)
qat_net = prepare_qat_fx(
float_net2, {"": default_qat_8bit_fake_quant_qconfig}
)
qat_net(data, data)
qat_net2 = deepcopy(qat_net)
quantized_net = convert_fx(qat_net2)
data = torch.arange(1 * 3 * 4 * 4) / 100 + 1
data = data.reshape((1, 3, 4, 4))
data = data.to(torch.float32).to(device)
export_to_onnx(float_net, (data, data), "float_test.onnx")
export_to_onnx(qat_net, (data, data), "qat_test.onnx")
export_quantized_onnx(quantized_net, (data, data), "quantized_test.onnx")
Similarity Comparison
When there is a significant decrease in accuracy of a fixed-point model compared to a QAT model, you can use the similarity comparison tool to compare the similarity of the output of each layer in the model, quickly identifying which op is causing the accuracy drop.
-
If the output of a certain layer is all zeros, the similarity result will also be 0 when using cosine similarity calculation. At this time, you can check if the output of this layer is all zeros, or confirm whether the output is the same based on indicators like printed atol. If the output of a certain layer is completely identical, the similarity result will be inf when using signal-to-noise ratio calculation;
-
If device=None, the tool will not move the model and input data, you need to manually ensure that the model and input data are on the same device;
-
Any two-stage model comparisons are supported in any input order, on any two devices. It is recommended to input in the order of float/qat/quantized, such as (float, qat) or (qat, quantized). If the order is (qat, float), there is no impact on similarity and per-op error, but the per-op error under the same input in the results may have bias, because it is impossible to generate inputs that correspond exactly to the float model for the QAT model. In addition, because the QAT model parameters change after training, directly comparing the similarity between the float model and the QAT model after training has little reference significance, so it is recommended to compare the similarity between the float model and the QAT model after calibration but before training;
-
In fx mode, the model conversion process is by default inplace. If you need to use the similarity tool, please manually deepcopy the original model before conversion. Otherwise, after conversion, the similarity of two identical models will be incorrectly compared.
# from horizon_plugin_pytorch.utils.quant_profiler import featuremap_similarity
def featuremap_similarity(
model1: torch.nn.Module,
model2: torch.nn.Module,
inputs: Any,
similarity_func: Union[str, Callable] = "Cosine",
threshold: Optional[Real] = None,
devices: Union[torch.device, tuple, None] = None,
out_dir: Optional[str] = None,
)
"""
Function for comparing the similarity of feature maps between two input models,
calculating and comparing the similarity of each layer's output features.
The input models can be floating-point models, models after operator fusion,
calibrated models, QAT models, or fixed-point models.
Parameters:
model1: Can be a floating-point model, a model after operator fusion,
a calibrated model, a QAT model, or a fixed-point model.
model2: Can be a floating-point model, a model after operator fusion,
a calibrated model, a QAT model, or a fixed-point model.
inputs: Model input.
similarity_func: The method for calculating similarity.
Defaults to Cosine similarity. Supports Cosine/MSE/L1/KL/SQNR/Custom similarity calculation function.
If it is a custom similarity function, it is best to return a constant or a tensor with only one value,
otherwise, the displayed results may not meet expectations.
threshold: Threshold. Defaults to None, will set to different default thresholds
according to different similarity calculation methods.
If you pass in a value, depending on the similarity comparison method,
values exceeding or below this threshold and corresponding op similarity information will be printed on the screen.
devices: Specifies the device on which the model is to forward during similarity calculation.
If None, forward on the device where the model input is located by default;
If there is only one parameter such as torch.device("cpu"),
both models will be moved to the specified device for forward;
If two values are specified such as (torch.device("cpu"), torch.device("cuda")),
the two models will be moved to the corresponding device for forward respectively.
Generally used to compare intermediate results of the same model and stage on CPU/GPU.
out_dir: Specify the path for output result files and images. Defaults to None,
saving to the current path.
Output:
Output is a list, each item in the list is a sublist representing the similarity information of each layer,
formatted as [index, module name, module type, similarity, output scale, maximum error,
per-op error (N scale), per-op error under the same input (N scale)]
"""
Example usage:
from copy import deepcopy
import torch
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
import horizon_plugin_pytorch as horizon
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.quantization.quantize_fx import (
convert_fx,
prepare_qat_fx,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.utils.quant_profiler import featuremap_similarity
class Net(nn.Module):
def __init__(self, quant=False, share_op=True):
super(Net, self).__init__()
self.quant_stubx = QuantStub()
self.quant_stuby = QuantStub()
self.mul_op = FloatFunctional()
self.cat_op = FloatFunctional()
self.quantized_ops = nn.Sequential(
nn.ReLU(),
nn.Sigmoid(),
nn.Softmax(),
nn.SiLU(),
horizon_nn.Interpolate(
scale_factor=2, recompute_scale_factor=True
),
horizon_nn.Interpolate(
scale_factor=2.3, recompute_scale_factor=True
),
nn.AvgPool2d(kernel_size=4),
nn.Upsample(scale_factor=1.3, mode="bilinear"),
nn.UpsamplingBilinear2d(scale_factor=0.7),
)
self.dequant_stub = DeQuantStub()
self.float_ops = nn.Sequential(
nn.Tanh(),
nn.LeakyReLU(),
nn.PReLU(),
nn.UpsamplingNearest2d(scale_factor=0.7),
)
self.quant = quant
self.share_op = share_op
def forward(self, x, y):
x = self.quant_stubx(x)
y = self.quant_stuby(y)
z = self.mul_op.mul(x, y)
x = self.cat_op.cat((x, y), dim=1)
if self.share_op:
x = self.cat_op.cat((x, y), dim=1)
x = self.quantized_ops(x)
x = self.dequant_stub(x)
if not self.quant:
x = self.float_ops(x)
return x
# **RDK X3** set BERNOULLI2, **RDK Ultra** set as BAYES。
set_march(March.BAYES)
device = torch.device("cuda")
float_net = Net(quant=True, share_op=True).to(device)
# fx transformations are all inplace modifications. If you need to compare similarity, you need to manually deepcopy the model before conversion.
float_net2 = deepcopy(float_net)
qat_net = prepare_qat_fx(
float_net2, {"": default_qat_8bit_fake_quant_qconfig}
)
qat_net(data, data)
qat_net2 = deepcopy(qat_net)
bpu_net = convert_fx(qat_net2)
data = torch.arange(1 * 3 * 4 * 4) / 100 + 1
data = data.reshape((1, 3, 4, 4))
data = data.to(torch.float32).to(device)
featuremap_similarity(qat_net, bpu_net, (data, data))
After running, the following files will be generated in the current directory or the directory specified by the out_dir parameter:
-
similarity.txt: Printed in table format, it displays the similarity and per-op error results of each layer in the order of model
forward. Each column in the table from left to right represents:-
Index: Index, starting from 0, it represents the numbering of each op in the model according to the forward order. It has no practical significance and is used for the horizontal axis numbering in the similarity image.
-
Module Name: The name used to define the op in the model, such as backbone.mod1.conv; Different formats of suffixes represent different meanings:
-
If the module name has the suffix '(I)', it indicates that the op is
Identityin one of the models. -
If the module name has the suffix '(I vs I)', it indicates that the op is
Identityin both of the compared models. -
If the module name has the suffix '(i)' (i >= 1), it indicates that the layer is a shared op, and it has been shared i times, currently it is the i+1th call. When a shared op is called for the first time, it is the same as other ops and does not have a suffix.
-
-
Module Type: The type of the op, such as torch.nn.Conv2d, horizon_plugin_pytorch.nn.qat.stubs.QuantStub, etc.
-
Similarity: The similarity of the corresponding op output in the two models. Generally, if the similarity of a certain layer suddenly decreases significantly and does not rise subsequently, it is likely that the decrease in model accuracy is caused by that layer. Further analysis of that layer can be done in conjunction with statistical tools.
-
qscale: The scale value of the op in the quantized model; if it is per-channel quantization, it will not be output.
-
Acc Error(float atol): The maximum difference between the corresponding op outputs in the two models,
Acc Error = N * qscale. -
Acc Error(N out_qscale): The maximum difference in scale of the corresponding op outputs in the two models.
-
Op Error with Same Input (N out_qscale): If the inputs of the corresponding op in the two models are completely the same (excluding the influence of cumulative errors), the maximum difference in scale of the outputs. Theoretically, the per-op error under the same input should all be within a few scales. If the difference is large, it indicates that there may be problems with the op transformation causing significant differences in results.
---------------------------------------------------------------
Note:
* Suffix '(I)' means this layer is Identity in one model
* Suffix '(I vs I)' means this layer is Identity in both models
* Suffix '(i)'(i >= 1) means this op is shared i times
---------------------------------------------------------------
+---------+----------------------------+----------------------------------------------------------------------------+--------------+-----------+----------------+------------------+------------------------+
| Index | Module Name | Module Type | Similarity | qscale | Acc Error | Acc Error | Op Error with Same |
| | | | | | (float atol) | (N out_qscale) | Input (N out_qscale) |
|---------+----------------------------+----------------------------------------------------------------------------+--------------+-----------+----------------+------------------+------------------------|
| 0 | quant_stubx | <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | 1.0000000 | 0.0115294 | 0.0000000 | 0 | 0 |
| 1 | quant_stuby | <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | 1.0000000 | 0.0115294 | 0.0000000 | 0 | 0 |
| 2 | mul_op | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 0.9999989 | 0.0168156 | 0.0168156 | 1 | 1 |
| 3 | cat_op | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 0.9999971 | 0.0167490 | 0.0334979 | 2 | 0 |
| 4 | cat_op(1) | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 0.9999980 | 0.0167490 | 0.0334979 | 2 | 0 |
| 5 | quantized_ops.0 | <class 'horizon_plugin_pytorch.nn.qat.relu.ReLU'> | 0.9999980 | 0.0167490 | 0.0334979 | 2 | 0 |
| 6 | quantized_ops.1 | <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> | 1.0000000 | 0.0070079 | 0.0000000 | 0 | 0 |
| 7 | quantized_ops.2.sub | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 0.9999999 | 0.0000041 | 0.0000041 | 1 | 1 |
| 8 | quantized_ops.2.exp | <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> | 1.0000000 | 0.0000305 | 0.0000305 | 1 | 1 |
| 9 | quantized_ops.2.sum | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 1.0000000 | 0.0002541 | 0.0005081 | 2 | 2 |
| 10 | quantized_ops.2.reciprocal | <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> | 1.0000001 | 0.0000037 | 0.0000186 | 5 | 5 |
| 11 | quantized_ops.2.mul | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 1.0000000 | 0.0009545 | 0.0000000 | 0 | 0 |
| 12 | quantized_ops.3 | <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> | 1.0000000 | 0.0005042 | 0.0000000 | 0 | 0 |
| 13 | quantized_ops.4 | <class 'horizon_plugin_pytorch.nn.qat.interpolate.Interpolate'> | 1.0000000 | 0.0005042 | 0.0005042 | 1 | 1 |
| 14 | quantized_ops.5 | <class 'horizon_plugin_pytorch.nn.qat.interpolate.Interpolate'> | 0.9999999 | 0.0005042 | 0.0005042 | 1 | 0 |
| 15 | quantized_ops.6 | <class 'horizon_plugin_pytorch.nn.qat.avg_pool2d.AvgPool2d'> | 0.9999995 | 0.0005022 | 0.0005022 | 1 | 1 |
| 16 | quantized_ops.7 | <class 'horizon_plugin_pytorch.nn.qat.upsampling.Upsample'> | 0.9999998 | 0.0005022 | 0.0005022 | 1 | 0 |
| 17 | quantized_ops.8 | <class 'horizon_plugin_pytorch.nn.qat.upsampling.UpsamplingBilinear2d'> | 1.0000000 | 0.0005022 | 0.0000000 | 0 | 0 |
| 18 | dequant_stub | <class 'horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub'> | 1.0000000 | | 0.0000000 | 0 | 0 |
+---------+----------------------------+----------------------------------------------------------------------------+--------------+-----------+----------------+------------------+------------------------+ -
-
ordered_op_error_similarity.txt: Similarly printed in table format, the results are sorted in descending order by per-op error under the same input, making it easier for you to quickly locate which op has a larger conversion error. The meaning of each column in the table is the same as similarity.txt.
---------------------------------------------------------------
Note:
* Suffix '(I)' means this layer is Identity in one model
* Suffix '(I vs I)' means this layer is Identity in both models
* Suffix '(i)'(i >= 1) means this op is shared i times
---------------------------------------------------------------
+---------+----------------------------+----------------------------------------------------------------------------+--------------+-----------+----------------+------------------+------------------------+
| Index | Module Name | Module Type | Similarity | qscale | Acc Error | Acc Error | Op Error with Same |
| | | | | | (float atol) | (N out_qscale) | Input (N out_qscale) |
|---------+----------------------------+----------------------------------------------------------------------------+--------------+-----------+----------------+------------------+------------------------|
| 10 | quantized_ops.2.reciprocal | <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> | 1.0000001 | 0.0000037 | 0.0000186 | 5 | 5 |
| 9 | quantized_ops.2.sum | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 1.0000000 | 0.0002541 | 0.0005081 | 2 | 2 |
| 2 | mul_op | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 0.9999989 | 0.0168156 | 0.0168156 | 1 | 1 |
| 7 | quantized_ops.2.sub | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 0.9999999 | 0.0000041 | 0.0000041 | 1 | 1 |
| 8 | quantized_ops.2.exp | <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> | 1.0000000 | 0.0000305 | 0.0000305 | 1 | 1 |
| 13 | quantized_ops.4 | <class 'horizon_plugin_pytorch.nn.qat.interpolate.Interpolate'> | 1.0000000 | 0.0005042 | 0.0005042 | 1 | 1 |
| 15 | quantized_ops.6 | <class 'horizon_plugin_pytorch.nn.qat.avg_pool2d.AvgPool2d'> | 0.9999995 | 0.0005022 | 0.0005022 | 1 | 1 |
| 0 | quant_stubx | <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | 1.0000000 | 0.0115294 | 0.0000000 | 0 | 0 |
| 1 | quant_stuby | <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | 1.0000000 | 0.0115294 | 0.0000000 | 0 | 0 |
| 3 | cat_op | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 0.9999971 | 0.0167490 | 0.0334979 | 2 | 0 |
| 4 | cat_op(1) | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 0.9999980 | 0.0167490 | 0.0334979 | 2 | 0 |
| 5 | quantized_ops.0 | <class 'horizon_plugin_pytorch.nn.qat.relu.ReLU'> | 0.9999980 | 0.0167490 | 0.0334979 | 2 | 0 |
| 6 | quantized_ops.1 | <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> | 1.0000000 | 0.0070079 | 0.0000000 | 0 | 0 |
| 11 | quantized_ops.2.mul | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 1.0000000 | 0.0009545 | 0.0000000 | 0 | 0 |
| 12 | quantized_ops.3 | <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> | 1.0000000 | 0.0005042 | 0.0000000 | 0 | 0 |
| 14 | quantized_ops.5 | <class 'horizon_plugin_pytorch.nn.qat.interpolate.Interpolate'> | 0.9999999 | 0.0005042 | 0.0005042 | 1 | 0 |
| 16 | quantized_ops.7 | <class 'horizon_plugin_pytorch.nn.qat.upsampling.Upsample'> | 0.9999998 | 0.0005022 | 0.0005022 | 1 | 0 |
| 17 | quantized_ops.8 | <class 'horizon_plugin_pytorch.nn.qat.upsampling.UpsamplingBilinear2d'> | 1.0000000 | 0.0005022 | 0.0000000 | 0 | 0 |
| 18 | dequant_stub | <class 'horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub'> | 1.0000000 | | 0.0000000 | 0 | 0 |
+---------+----------------------------+----------------------------------------------------------------------------+--------------+-----------+----------------+------------------+------------------------+ -
similarity.html: An interactive image displaying the similarity curve of each layer as the model forwards. It allows zooming in and out, and hovering over specific points reveals the exact similarity values. (This is a screenshot of an HTML webpage without interactive functionality).

Statistical Metrics
Calculate the numerical features min/max/mean/var/scale for each layer's input and output in the model. Statistical metrics can help you observe the data distribution in the current model and evaluate which quantization precision (int8/int16) should be used. This tool also checks for any numerical exceptional layers in the model, such as NaN or inf.
Currently, only the RDK Ultra with BPU architecture set to BAYES supports setting int16 quantization.
# from horizon_plugin_pytorch.utils.quant_profiler import get_raw_features, profile_featuremap
get_raw_features(
model: torch.nn.Module,
example_inputs: Any,
prefixes: Tuple = (),
types: Tuple = (),
device: torch.device = None,
preserve_int: bool = False,
use_class_name: bool = False,
skip_identity: bool = False,
)
"""
Parameters:
model: Model for which statistical metrics need to be outputted
example_inputs: The input of the model
prefixes: Specify the layer names in the model corresponding to the ops for which statistical metrics need to be outputted (starting with prefixes)
types: Specify the types of ops for which statistical metrics need to be outputted
device: Specify the device (CPU/GPU) on which the model should be forwarded
preserve_int: Whether to output in fixed-point numerical format. The default output is in float format. This parameter only takes effect for qat and quantized models, and only if the layer output has scale (e.g. if the output of the dequant layer is float, this parameter has no effect)
use_class_name: Whether to print the name of each layer op. The default is to print the op type
skip_identity: Whether to skip statistical metrics for Identity ops. By default, statistical metrics are outputted for all types of ops
Output:
list(dict): Returns a list, where each element is a dictionary representing the input/output values and some parameter values of each layer. The format is as follows:
- "module_name": (str) The name of the module in the original model
- "attr": (str) The attribute of the module. It can be input/output/weight/bias, etc. input/output represents the input/output of this layer, and others represent the parameters in the module
- "data": (Tensor) The numerical value corresponding to the attribute of this layer. If the data is a QTensor, it records the value after dequantization
- "scale": (Tensor | None) If the data is a QTensor, it represents the corresponding scale, which may be the scale of per-tensor quantization or per-channel quantization; otherwise, it is None
- "ch_axis": (int) If the data is per-channel quantized data, it represents the dimension of quantization. Otherwise, it is -1
- “ff_method”: (str) If the current module is FloatFunctional/QFunctional, it records the actual
The called method (`add/sub/mul/...`). Otherwise, it is `None`.
"""
profile_featuremap(
featuremap: List[Dict],
with_tensorboard: bool = False,
tensorboard_dir: Optional[str] = None,
print_per_channel_scale: bool = False,
show_per_channel: bool = False,
out_dir: Optional[str] = None,
file_name: Optional[str] = None,
)
"""
Input:
featuremap: output of `get_raw_features`
with_tensorboard: whether to use tensorboard to display data distribution. Default is False.
tensorboard_dir: tensorboard log file path. Default is None. Only valid when `with_tensorboard=True`.
print_per_channel_scale: whether to print per channel quantization scale. Default is False.
show_per_channel: whether to show the histogram of each channel in the feature in tensorboard. Default is False.
out_dir: specify the path of the output result file and image. If not specified, it will be save in the current path.
file_name: the name of the saved file and image. If not specified, it will be "statistic.txt" and an interactive "statistic.html" by default.
"""
-
Default usage of two interfaces together:
profile_featuremap(get_raw_features(model, example_inputs), with_tensorboard=True). -
By default, the statistical results are saved in
statistic.txt, and the results are plotted and saved in thestatistic.htmlfile, which can be opened and viewed in a browser. -
If you need to calculate other information, you can customize the featuremap statistical processing function to handle the return data of the
get_raw_featuresfunction. -
The function
get_raw_featuresrecords the input and output of each layer of the model by insertinghooks. However, the community'shookscurrently do not supportkwargs(see here), which leads to two issues:-
cat((x,y), 1): In this writing style, the parameterdim=1will be filtered out, only recording the two tensors x and y, which is also expected; -
cat(x=(x,y), dim=1): In this writing style, the two keyword arguments will not take effect during hook execution. There is currently no way to handle this situation, so you need to ensure that the tensor type data is not passed as keyword arguments when forwarding the model.
-
Usage Example:
import torch
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
import horizon_plugin_pytorch as horizon
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.quantization.quantize_fx import (
convert_fx,
prepare_qat_fx,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.utils.quant_profiler import (
get_raw_features,
profile_featuremap,
)
class Net(nn.Module):
def __init__(self, quant=False, share_op=True):
super(Net, self).__init__()
self.quant_stubx = QuantStub()
self.quant_stuby = QuantStub()
self.mul_op = FloatFunctional()
self.cat_op = FloatFunctional()
self.quantized_ops = nn.Sequential(
nn.ReLU(),
nn.Sigmoid(),
nn.Softmax(),
nn.SiLU(),
horizon_nn.Interpolate(
scale_factor=2, recompute_scale_factor=True
),
horizon_nn.Interpolate(
scale_factor=2.3, recompute_scale_factor=True
),
nn.AvgPool2d(kernel_size=4),
nn.Upsample(scale_factor=1.3, mode="bilinear"),
nn.UpsamplingBilinear2d(scale_factor=0.7),
)
self.dequant_stub = DeQuantStub()
self.float_ops = nn.Sequential(
nn.Tanh(),
nn.LeakyReLU(),
nn.PReLU(),
nn.UpsamplingNearest2d(scale_factor=0.7),
)
self.quant = quant
self.share_op = share_op
def forward(self, x, y):
x = self.quant_stubx(x)
y = self.quant_stuby(y)
z = self.mul_op.mul(x, y)
x = self.cat_op.cat((x, y), dim=1)
if self.share_op:
x = self.cat_op.cat((x, y), dim=1)
x = self.quantized_ops(x)
x = self.dequant_stub(x)
if not self.quant:
x = self.float_ops(x)
return x
# **RDK X3** set BERNOULLI2, **RDK Ultra** set BAYES.
set_march(March.BAYES)
device = torch.device("cuda")
float_net = Net(quant=True, share_op=True).to(device)
qat_net = prepare_qat_fx(
float_net, {"": default_qat_8bit_fake_quant_qconfig}
)
qat_net = qat_net.to(device)
data = torch.arange(1 * 3 * 4 * 4) / 100 + 1
data = data.reshape((1, 3, 4, 4))
data = data.to(torch.float32).to(device)
profile_featuremap(get_raw_features(qat_net, (data, data)), True)
After running, the following files will be generated in the current directory or the directory specified by the out_dir parameter:
-
statistic.txt: Outputs the statistical information of the input and output of each layer in tabular form. Each column in the table represents the following from left to right:
-
Module Index: An index that starts from 0 for each op in the model in the forward order. It has no actual meaning and is used for the horizontal axis numbering in similarity pictures.
-
Module Name: The name used to define and use the op in the model, such as backbone.mod1.conv. Different suffix formats represent different meanings:
- If the module name has a suffix '(i)' (i >= 1), it means that the layer is a shared op and has been shared i times. The first time the shared op is called is the same as other ops and does not have a suffix.
-
Module Type: The type of the op, such as torch.nn.Conv2d, horizon_plugin_pytorch.nn.qat.stubs.QuantStub, etc.
-
Attribute: Which attribute of the module is printed in the current row, such as input, output, weight, bias, etc.
-
Min: The minimum value of the data.
-
Max: The maximum value of the data. By using min and max, the current data range can be obtained. Combined with the scale value, it can be determined whether the current quantization precision (int8/int16) meets the accuracy requirements.
-
Currently, only the RDK Ultra with BPU architecture set to "BAYES" supports setting "int16" quantization.
- Mean: The mean value of the data.
- Var: Variance of the data. If the variance is NaN, and min=max=mean, it means there is only one value. If the variance is large, it indicates that the data distribution in the array is uneven and may not be suitable for quantization.
- Scale: The quantization scale of the data. If it is empty, it means that the data is quantized per-channel or not quantized.
- Dtype: The quantization dtype of the current layer, such as qint8/qint16. If the current layer is not quantized, it will directly print the floating-point data type.
Currently, only RDK Ultra with BPU architecture set to "BAYES" supports "int16" quantization.
Under normal circumstances, the statistic.txt file will contain two tables in the above format, one is the statistics of each layer printed in the order of the model forward; the other is the statistics of each layer printed in descending order of the quantization data range, which is convenient for you to quickly locate the layers with large value ranges. If there are NaN or inf in some layers of the model, the statistic.txt file will also include an additional table indicating which layers have NaN or inf, and this table will be printed on the screen to remind you to check these abnormal layers.
+----------------+----------------------------+-------------------------------------------------------------------------------+---------------------+------------+-----------+------------+-----------+-----------+---------------+
| Module Index | Module Name | Module Type | Input/Output/Attr | Min | Max | Mean | Var | Scale | Dtype |
|----------------+----------------------------+-------------------------------------------------------------------------------+---------------------+------------+-----------+------------+-----------+-----------+---------------|
| 0 | quant_stubx | <class 'horizon_plugin_pytorch.nn.quantized.quantize.Quantize'> | input | -2.9943717 | 2.9613159 | -0.0791836 | 2.7670853 | | torch.float32 |
| 0 | quant_stubx | <class 'horizon_plugin_pytorch.nn.quantized.quantize.Quantize'> | output | -2.9826291 | 2.9591436 | -0.0786467 | 2.7688842 | 0.0234853 | qint8 |
| 1 | quant_stuby | <class 'horizon_plugin_pytorch.nn.quantized.quantize.Quantize'> | input | 0.5011058 | 0.9995295 | 0.7525039 | 0.0210502 | | torch.float32 |
| 1 | quant_stuby | <class 'horizon_plugin_pytorch.nn.quantized.quantize.Quantize'> | output | 0.5017246 | 0.9956098 | 0.7525385 | 0.0210164 | 0.0078394 | qint8 |
| 2 | mul_op[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0 | -2.9826291 | 2.9591436 | -0.0786467 | 2.7688842 | 0.0234853 | qint8 |
| 2 | mul_op[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-1 | 0.5017246 | 0.9956098 | 0.7525385 | 0.0210164 | 0.0078394 | qint8 |
| 2 | mul_op[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | -2.9577060 | 2.5648856 | -0.0374420 | 1.5830494 | 0.0231071 | qint8 |
| 3 | cat_op[cat] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0-0 | -2.9826291 | 2.9591436 | -0.0786467 | 2.7688842 | 0.0234853 | qint8 |
| 3 | cat_op[cat] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0-1 | -2.9577060 | 2.5648856 | -0.0374420 | 1.5830494 | 0.0231071 | qint8 |
| 3 | cat_op[cat] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | -2.9942081 | 2.9474237 | -0.0580113 | 2.1627743 | 0.0233923 | qint8 |
| 4 | cat_op[cat](1) | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0 | -2.9942081 | 2.9474237 | -0.0580113 | 2.1627743 | 0.0233923 | qint8 |
| 4 | cat_op[cat](1) | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-1 | 0.5017246 | 0.9956098 | 0.7525385 | 0.0210164 | 0.0078394 | qint8 |
| 4 | cat_op[cat](1) | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | -2.9942081 | 2.9474237 | 0.2123352 | 1.5946714 | 0.0233923 | qint8 |
| 5 | quantized_ops.0 | <class 'horizon_plugin_pytorch.nn.quantized.relu.ReLU'> | input | -2.9942081 | 2.9474237 | 0.2123352 | 1.5946714 | 0.0233923 | qint8 |
| 5 | quantized_ops.0 | <class 'horizon_plugin_pytorch.nn.quantized.relu.ReLU'> | output | 0.0000000 | 2.9474237 | 0.6510122 | 0.4357365 | 0.0233923 | qint8 |
| 6 | quantized_ops.1 | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | input | 0.0000000 | 2.9474237 | 0.6510122 | 0.4357365 | 0.0233923 | qint8 |
| 6 | quantized_ops.1 | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | output | 0.4992901 | 0.9464155 | 0.6408262 | 0.0163976 | 0.0074521 | qint8 |
| 7 | quantized_ops.2.sub[sub] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0 | 0.4992901 | 0.9464155 | 0.6408262 | 0.0163976 | 0.0074521 | qint8 |
| 7 | quantized_ops.2.sub[sub] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-1 | 0.6334277 | 0.9464155 | 0.7888176 | 0.0090090 | 0.0074521 | qint8 |
| 7 | quantized_ops.2.sub[sub] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | -0.4471186 | 0.0000000 | -0.1479909 | 0.0140247 | 0.0000136 | qint16 |
| 8 | quantized_ops.2.exp | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | input | -0.4471186 | 0.0000000 | -0.1479909 | 0.0140247 | 0.0000136 | qint16 |
| 8 | quantized_ops.2.exp | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | output | 0.6394446 | 0.9999847 | 0.8683713 | 0.0100195 | 0.0000305 | qint16 |
| 9 | quantized_ops.2.sum[sum] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input | 0.6394446 | 0.9999847 | 0.8683713 | 0.0100195 | 0.0000305 | qint16 |
| 9 | quantized_ops.2.sum[sum] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | 4.6700654 | 5.9043884 | 5.2101822 | 0.0529649 | 0.0001802 | qint16 |
| 10 | quantized_ops.2.reciprocal | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | input | 4.6700654 | 5.9043884 | 5.2101822 | 0.0529649 | 0.0001802 | qint16 |
| 10 | quantized_ops.2.reciprocal | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | output | 0.1693695 | 0.2141069 | 0.1923085 | 0.0000730 | 0.0000065 | qint16 |
| 11 | quantized_ops.2.mul[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0 | 0.6394446 | 0.9999847 | 0.8683713 | 0.0100195 | 0.0000305 | qint16 |
| 11 | quantized_ops.2.mul[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-1 | 0.1693695 | 0.2141069 | 0.1923085 | 0.0000730 | 0.0000065 | qint16 |
| 11 | quantized_ops.2.mul[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | 0.1326724 | 0.2132835 | 0.1666716 | 0.0003308 | 0.0016794 | qint8 |
| 12 | quantized_ops.3 | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | input | 0.1326724 | 0.2132835 | 0.1666716 | 0.0003308 | 0.0016794 | qint8 |
| 12 | quantized_ops.3 | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | output | 0.0703202 | 0.1175087 | 0.0903590 | 0.0001112 | 0.0009253 | qint8 |
| 13 | quantized_ops.4 | <class 'horizon_plugin_pytorch.nn.quantized.interpolate.Interpolate'> | input | 0.0703202 | 0.1175087 | 0.0903590 | 0.0001112 | 0.0009253 | qint8 |
| 13 | quantized_ops.4 | <class 'horizon_plugin_pytorch.nn.quantized.interpolate.Interpolate'> | output | 0.0712454 | 0.1147329 | 0.0903947 | 0.0000526 | 0.0009253 | qint8 |
| 14 | quantized_ops.5 | <class 'horizon_plugin_pytorch.nn.quantized.interpolate.Interpolate'> | input | 0.0712454 | 0.1147329 | 0.0903947 | 0.0000526 | 0.0009253 | qint8 |
| 14 | quantized_ops.5 | <class 'horizon_plugin_pytorch.nn.quantized.interpolate.Interpolate'> | output | 0.0712454 | 0.1147329 | 0.0903947 | 0.0000461 | 0.0009253 | qint8 |
| 15 | quantized_ops.6 | <class 'horizon_plugin_pytorch.nn.quantized.avg_pool2d.AvgPool2d'> | input | 0.0712454 | 0.1147329 | 0.0903947 | 0.0000461 | 0.0009253 | qint8 |
| 15 | quantized_ops.6 | <class 'horizon_plugin_pytorch.nn.quantized.avg_pool2d.AvgPool2d'> | output | 0.0747764 | 0.1091563 | 0.0903856 | 0.0000372 | 0.0008595 | qint8 |
| 16 | quantized_ops.7 | <class 'horizon_plugin_pytorch.nn.quantized.upsampling.Upsample'> | input | 0.0747764 | 0.1091563 | 0.0903856 | 0.0000372 | 0.0008595 | qint8 |
| 16 | quantized_ops.7 | <class 'horizon_plugin_pytorch.nn.quantized.upsampling.Upsample'> | output | 0.0756359 | 0.1074373 | 0.0903877 | 0.0000286 | 0.0008595 | qint8 |
| 17 | quantized_ops.8 | <class 'horizon_plugin_pytorch.nn.quantized.upsampling.UpsamplingBilinear2d'> | input | 0.0756359 | 0.1074373 | 0.0903877 | 0.0000286 | 0.0008595 | qint8 |
| 17 | quantized_ops.8 | <class 'horizon_plugin_pytorch.nn.quantized.upsampling.UpsamplingBilinear2d'> | output | 0.0773549 | 0.1048589 | 0.0903853 | 0.0000251 | 0.0008595 | qint8 |
| 18 | dequant_stub | <class 'horizon_plugin_pytorch.nn.quantized.quantize.DeQuantize'> | input | 0.0773549 | 0.1048589 | 0.0903853 | 0.0000251 | 0.0008595 | qint8 |
| 18 | dequant_stub | <class 'horizon_plugin_pytorch.nn.quantized.quantize.DeQuantize'> | output | 0.0773549 | 0.1048589 | 0.0903853 | 0.0000251 | | torch.float32 |
+----------------+----------------------------+-------------------------------------------------------------------------------+---------------------+------------+-----------+------------+-----------+-----------+---------------+
Statistics with quant range in descending order...
+----------------+----------------------------+-------------------------------------------------------------------------------+---------------------+------------+-----------+------------+-----------+-----------+---------------+
| Module Index | Module Name | Module Type | Input/Output/Attr | Min | Max | Mean | Var | Scale | Dtype |
|----------------+----------------------------+-------------------------------------------------------------------------------+---------------------+------------+-----------+------------+-----------+-----------+---------------|
| 9 | quantized_ops.2.sum[sum] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | 4.6700654 | 5.9043884 | 5.2101822 | 0.0529649 | 0.0001802 | qint16 |
| 10 | quantized_ops.2.reciprocal | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | input | 4.6700654 | 5.9043884 | 5.2101822 | 0.0529649 | 0.0001802 | qint16 |
| 0 | quant_stubx | <class 'horizon_plugin_pytorch.nn.quantized.quantize.Quantize'> | input | -2.9943717 | 2.9613159 | -0.0791836 | 2.7670853 | | torch.float32 |
| 3 | cat_op[cat] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | -2.9942081 | 2.9474237 | -0.0580113 | 2.1627743 | 0.0233923 | qint8 |
| 4 | cat_op[cat](1) | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0 | -2.9942081 | 2.9474237 | -0.0580113 | 2.1627743 | 0.0233923 | qint8 |
| 4 | cat_op[cat](1) | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | -2.9942081 | 2.9474237 | 0.2123352 | 1.5946714 | 0.0233923 | qint8 |
| 5 | quantized_ops.0 | <class 'horizon_plugin_pytorch.nn.quantized.relu.ReLU'> | input | -2.9942081 | 2.9474237 | 0.2123352 | 1.5946714 | 0.0233923 | qint8 |
| 0 | quant_stubx | <class 'horizon_plugin_pytorch.nn.quantized.quantize.Quantize'> | output | -2.9826291 | 2.9591436 | -0.0786467 | 2.7688842 | 0.0234853 | qint8 |
| 2 | mul_op[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0 | -2.9826291 | 2.9591436 | -0.0786467 | 2.7688842 | 0.0234853 | qint8 |
| 3 | cat_op[cat] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0-0 | -2.9826291 | 2.9591436 | -0.0786467 | 2.7688842 | 0.0234853 | qint8 |
| 2 | mul_op[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | -2.9577060 | 2.5648856 | -0.0374420 | 1.5830494 | 0.0231071 | qint8 |
| 3 | cat_op[cat] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0-1 | -2.9577060 | 2.5648856 | -0.0374420 | 1.5830494 | 0.0231071 | qint8 |
| 5 | quantized_ops.0 | <class 'horizon_plugin_pytorch.nn.quantized.relu.ReLU'> | output | 0.0000000 | 2.9474237 | 0.6510122 | 0.4357365 | 0.0233923 | qint8 |
| 6 | quantized_ops.1 | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | input | 0.0000000 | 2.9474237 | 0.6510122 | 0.4357365 | 0.0233923 | qint8 |
| 8 | quantized_ops.2.exp | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | output | 0.6394446 | 0.9999847 | 0.8683713 | 0.0100195 | 0.0000305 | qint16 |
| 9 | quantized_ops.2.sum[sum] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input | 0.6394446 | 0.9999847 | 0.8683713 | 0.0100195 | 0.0000305 | qint16 |
| 11 | quantized_ops.2.mul[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0 | 0.6394446 | 0.9999847 | 0.8683713 | 0.0100195 | 0.0000305 | qint16 |
| 1 | quant_stuby | <class 'horizon_plugin_pytorch.nn.quantized.quantize.Quantize'> | input | 0.5011058 | 0.9995295 | 0.7525039 | 0.0210502 | | torch.float32 |
| 1 | quant_stuby | <class 'horizon_plugin_pytorch.nn.quantized.quantize.Quantize'> | output | 0.5017246 | 0.9956098 | 0.7525385 | 0.0210164 | 0.0078394 | qint8 |
| 2 | mul_op[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-1 | 0.5017246 | 0.9956098 | 0.7525385 | 0.0210164 | 0.0078394 | qint8 |
| 4 | cat_op[cat](1) | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-1 | 0.5017246 | 0.9956098 | 0.7525385 | 0.0210164 | 0.0078394 | qint8 |
| 6 | quantized_ops.1 | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | output | 0.4992901 | 0.9464155 | 0.6408262 | 0.0163976 | 0.0074521 | qint8 |
| 7 | quantized_ops.2.sub[sub] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-0 | 0.4992901 | 0.9464155 | 0.6408262 | 0.0163976 | 0.0074521 | qint8 |
| 7 | quantized_ops.2.sub[sub] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-1 | 0.6334277 | 0.9464155 | 0.7888176 | 0.0090090 | 0.0074521 | qint8 |
| 7 | quantized_ops.2.sub[sub] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | -0.4471186 | 0.0000000 | -0.1479909 | 0.0140247 | 0.0000136 | qint16 |
| 8 | quantized_ops.2.exp | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | input | -0.4471186 | 0.0000000 | -0.1479909 | 0.0140247 | 0.0000136 | qint16 |
| 10 | quantized_ops.2.reciprocal | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | output | 0.1693695 | 0.2141069 | 0.1923085 | 0.0000730 | 0.0000065 | qint16 |
| 11 | quantized_ops.2.mul[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | input-1 | 0.1693695 | 0.2141069 | 0.1923085 | 0.0000730 | 0.0000065 | qint16 |
| 11 | quantized_ops.2.mul[mul] | <class 'horizon_plugin_pytorch.nn.quantized.functional_modules.QFunctional'> | output | 0.1326724 | 0.2132835 | 0.1666716 | 0.0003308 | 0.0016794 | qint8 |
| 12 | quantized_ops.3 | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | input | 0.1326724 | 0.2132835 | 0.1666716 | 0.0003308 | 0.0016794 | qint8 |
| 12 | quantized_ops.3 | <class 'horizon_plugin_pytorch.nn.quantized.segment_lut.SegmentLUT'> | output | 0.0703202 | 0.1175087 | 0.0903590 | 0.0001112 | 0.0009253 | qint8 |
| 13 | quantized_ops.4 | <class 'horizon_plugin_pytorch.nn.quantized.interpolate.Interpolate'> | input | 0.0703202 | 0.1175087 | 0.0903590 | 0.0001112 | 0.0009253 | qint8 |
| 13 | quantized_ops.4 | <class 'horizon_plugin_pytorch.nn.quantized.interpolate.Interpolate'> | output | 0.0712454 | 0.1147329 | 0.0903947 | 0.0000526 | 0.0009253 | qint8 |
| 14 | quantized_ops.5 | <class 'horizon_plugin_pytorch.nn.quantized.interpolate.Interpolate'> | input | 0.0712454 | 0.1147329 | 0.0903947 | 0.0000526 | 0.0009253 | qint8 |
| 14 | quantized_ops.5 | <class 'horizon_plugin_pytorch.nn.quantized.interpolate.Interpolate'> | output | 0.0712454 | 0.1147329 | 0.0903947 | 0.0000461 | 0.0009253 | qint8 |
| 15 | quantized_ops.6 | <class 'horizon_plugin_pytorch.nn.quantized.avg_pool2d.AvgPool2d'> | input | 0.0712454 | 0.1147329 | 0.0903947 | 0.0000461 | 0.0009253 | qint8 |
| 15 | quantized_ops.6 | <class 'horizon_plugin_pytorch.nn.quantized.avg_pool2d.AvgPool2d'> | output | 0.0747764 | 0.1091563 | 0.0903856 | 0.0000372 | 0.0008595 | qint8 |
| 16 | quantized_ops.7 | <class 'horizon_plugin_pytorch.nn.quantized.upsampling.Upsample'> | input | 0.0747764 | 0.1091563 | 0.0903856 | 0.0000372 | 0.0008595 | qint8 |
| 16 | quantized_ops.7 | <class 'horizon_plugin_pytorch.nn.quantized.upsampling.Upsample'> | output | 0.0756359 | 0.1074373 | 0.0903877 | 0.0000286 | 0.0008595 | qint8 |
| 17 | quantized_ops.8 | <class 'horizon_plugin_pytorch.nn.quantized.upsampling.UpsamplingBilinear2d'> | input | 0.0756359 | 0.1074373 | 0.0903877 | 0.0000286 | 0.0008595 | qint8 |
| 17 | quantized_ops.8 | <class 'horizon_plugin_pytorch.nn.quantized.upsampling.UpsamplingBilinear2d'> | output | 0.0773549 | 0.1048589 | 0.0903853 | 0.0000251 | 0.0008595 | qint8 |
| 18 | dequant_stub | <class 'horizon_plugin_pytorch.nn.quantized.quantize.DeQuantize'> | input | 0.0773549 | 0.1048589 | 0.0903853 | 0.0000251 | 0.0008595 | qint8 |
| 18 | dequant_stub | <class 'horizon_plugin_pytorch.nn.quantized.quantize.DeQuantize'> | output | 0.0773549 | 0.1048589 | 0.0903853 | 0.0000251 | | torch.float32 |
+----------------+----------------------------+-------------------------------------------------------------------------------+---------------------+------------+-----------+------------+-----------+-----------+---------------+
-
statistic.html

If with_tensorboard=True is set, a TensorBoard log file will be generated in the specified directory, which can be opened and viewed using TensorBoard to see the distribution histograms of each group of data.
Model Weight Comparison
By default, this tool calculates the similarity of each layer's weight in the model (if any) and outputs it to the screen and saves it to a file. You can also plot the histograms of the weight by setting with_tensorboard=True for a more intuitive comparison.
If the fx mode is used for quantization, please note the following:
- The process of model transformation is inplace by default. Please manually deepcopy the original model before performing the transformation. Otherwise, after the transformation, two identical models will be incorrectly compared with their weights;
- If it involves the comparison of weights between float models, please manually call fuse_fx to fuse the original float model. Otherwise, the weights of the unfused float model will be incorrectly compared with those of the fused qat or fixed-point model.
# from horizon_plugin_pytorch.utils.quant_profiler import compare_weights
def compare_weights(
float_model: torch.nn.Module,
qat_quantized_model: torch.nn.Module,
similarity_func="Cosine",
with_tensorboard: bool = False,
tensorboard_dir: Optional[str] = None,
out_dir: Optional[str] = None,
) -> Dict[str, Dict[str, torch.Tensor]]:
"""Compare the weights of float/qat/quantized models.
This function uses torch.quantization._numeric_suite.compare_weights to compare the weights of each layer in the model. The weight similarity and atol will be printed to the screen and saved to "weight_comparison.txt". You can also set with_tensorboard=True to print the weight histograms through tensorboard.
Args:
float_model: Float model
qat_quantized_model: QAT/fixed-point model
similarity_func: Similarity calculation function. Supports Cosine/MSE/L1/KL/SQNR and any custom functions.
Similarity calculation function for weights. If it is a custom function, it should return a scalar or a tensor with only one number, otherwise the result may not be as expected. Default is Cosine.
with_tensorboard: Whether to use tensorboard, default is False.
tensorboard_dir: Tensorboard log file path. Default is None.
out_dir: Path to save the txt result. Default is None, saved to the current path.
Output:
A dictionary that records the weights of the two models, in the following format:
* KEY (str): Module name (such as layer1.0.conv.weight)
* VALUE (dict): The weights of the corresponding layers in the two models:
"float": The weights in the floating-point model
"quantized": The weights in the qat/fixed-point model
Example:
from copy import deepcopy
import horizon_plugin_pytorch as horizon
import numpy as np
import torch
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.quantization import (
convert,
get_default_qat_qconfig,
prepare_qat,
fuse_modules,
)
from horizon_plugin_pytorch.quantization.quantize_fx import (
convert_fx,
fuse_fx,
prepare_qat_fx,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch.utils.quant_profiler import compare_weights
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
# Resnet18 definition is omitted here
float_net = Resnet18().to(device)
# Set BERNOULLI2 for **RDK X3**, Set BAYES for **RDK Ultra**.
set_march(March.BAYES)
float_net.qconfig = get_default_qat_qconfig()
float_net2 = deepcopy(float_net)
qat_net = prepare_qat_fx(float_net2, {"": default_qat_8bit_fake_quant_qconfig})
qat_net(data)
# It is necessary!! Otherwise, comparing the unfused float model and the fused qat model, the weights in the model may not correspond.
float_net = fuse_fx(float_net)
compare_weights(float_net, qat_net)
The results will be displayed on the screen in table format and saved in weight_comparison.txt. Each column from left to right in the table represents:
- Weight Name: which layer's weight in the model
- Similarity: the similarity of the weights in the corresponding layers of the two models
- Atol: the difference in scale in the weights of the corresponding layers in the two models
+-------------------------------------+--------------+-----------+
| Weight Name | Similarity | Atol |
|-------------------------------------+--------------+-----------|
| conv1.conv.weight | 1.0000000 | 0.0000000 |
| layer1.0.conv_cell1.conv.weight | 1.0000000 | 0.0000000 |
| layer1.0.shortcut.conv.weight | 1.0000000 | 0.0000000 |
| layer1.0.conv_cell2.skip_add.weight | 1.0000000 | 0.0000000 |
| layer1.1.conv_cell1.conv.weight | 1.0000000 | 0.0000000 |
| layer1.1.conv_cell2.conv.weight | 1.0000000 | 0.0000000 |
| layer2.0.conv_cell1.conv.weight | 1.0000000 | 0.0000000 |
| layer2.0.shortcut.conv.weight | 1.0000000 | 0.0000000 |
| layer2.0.conv_cell2.skip_add.weight | 1.0000000 | 0.0000000 |
| layer2.1.conv_cell1.conv.weight | 1.0000000 | 0.0000001 |
| layer2.1.conv_cell2.conv.weight | 1.0000000 | 0.0000001 |
| layer3.0.conv_cell1.conv.weight | 1.0000000 | 0.0000001 |
| layer3.0.shortcut.conv.weight | 1.0000000 | 0.0000001 |
| layer3.0.conv_cell2.skip_add.weight | 1.0000000 | 0.0000002 |
| layer3.1.conv_cell1.conv.weight | 1.0000000 | 0.0000005 |
| layer3.1.conv_cell2.conv.weight | 1.0000001 | 0.0000008 |
| conv2.conv.weight | 1.0000001 | 0.0000010 |
| pool.conv.weight | 0.9999999 | 0.0000024 |
| fc.weight | 1.0000000 | 0.0000172 |
+-------------------------------------+--------------+-----------+
Step-wise Quantization
When encountering difficulties in training QAT models that lead to poor performance, you may need to use step-wise quantization to identify the accuracy bottleneck. At this time, you can set a part of the model as floating-point by using qconfig=None.
If you use fx for quantization, you can directly refer to the API documentation prepare_qat_fx and use the hybrid and hybrid_dict parameters to enable step-wise quantization.# from horizon_plugin_pytorch.quantization import prepare_qat
# from horizon_plugin_pytorch.quantization import prepare_qat
def prepare_qat(
model: torch.nn.Module,
mapping: Optional[Dict[torch.nn.Module, torch.nn.Module]] = None,
inplace: bool = False,
optimize_graph: bool = False,
hybrid: bool = False,
):
"""Enable step quantization through the hybrid parameter in the prepare_qat interface
Parameters:
hybrid: Generate a hybrid model with intermediate operations as floating-point calculations. There are some restrictions:
1. The hybrid model cannot be checked or compiled
2. Some quantization ops cannot directly accept floating-point input, and you need to manually insert QuantStub
"""
-
Quantized operator -> Floating-point operator: The output type of the quantized operator is
QTensor.QTensoris not allowed to be directly used as the input of the floating-point operator by default, which will cause aNotImplementedErrorerror during forward. To solve this problem, you can use the above interface to remove this restriction. -
Floating-point operator -> Quantized operator: In QAT, the implementation of the quantized operator is generally in the form of floating-point operator + FakeQuant. Therefore, in most cases, the quantized operator can directly use
Tensoras input. Due to the need for alignment with fixed-point numbers, a few operators require the scale information of the input during QAT, so the input must beQTensor. For this case, we added a check. If you encounter related errors, you need to manually insertQuantStubbetween the floating-point operator and the quantized operator.
Usage example:
import numpy as np
import pytest
import torch
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn import qat
from horizon_plugin_pytorch.quantization import (
get_default_qat_qconfig,
prepare_qat,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch.quantization.quantize_fx import prepare_qat_fx
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
class HyperQuantModel(nn.Module):
def __init__(self, channels=3) -> None:
super().__init__()
self.quant = QuantStub()
self.conv0 = nn.Conv2d(channels, channels, 1)
self.conv1 = nn.Conv2d(channels, channels, 1)
self.conv2 = nn.Conv2d(channels, channels, 1)
self.dequant = DeQuantStub()
def forward(self, input):
x = self.quant(input)
x = self.conv0(x)
x = self.conv1(x)
x = self.conv2(x)
return self.dequant(x)
def set_qconfig(self):
self.qconfig = default_qat_8bit_fake_quant_qconfig
self.conv1.qconfig = None
shape = np.random.randint(10, 20, size=4).tolist()
data = torch.rand(size=shape)
# Set BERNOULLI2 for **RDK X3** and BAYES for **RDK Ultra**.
set_march(March.BAYES)
model = HyperQuantModel(shape[1])
# If using eager mode, after setting qconfig, call prepare_qat(hybrid=True)
# model.set_qconfig()
# qat_model = prepare_qat(model, hybrid=True)
# In fx mode, directly set using the prepare_qat_fx interface
qat_model = prepare_qat_fx(
model,
qconfig_dict={"": default_qat_8bit_fake_quant_qconfig},
hybrid=True,
hybrid_dict={"module_name": ["conv1",]}
)
assert isinstance(qat_model.conv0, qat.Conv2d)
# conv1 still remains as a float conv in the qat model
assert isinstance(qat_model.conv1, nn.Conv2d)
assert isinstance(qat_model.conv2, qat.Conv2d)
qat_model(data)
Single Operator Conversion Precision Debugging
When the precision of the fixed-point model is reduced during QAT conversion, you may need to verify which operator specifically causes the loss of precision by replacing some key operators in the fixed-point model with QAT.
# from horizon_plugin_pytorch.utils.quant_profiler import set_preserve_qat_mode
def set_preserve_qat_mode(model: nn.Module, prefixes=(), types=(), value=True):
"""
By setting mod.preserve_qat_mode=True, the quantized model 'mod' will still remain in qat mode after conversion.
This function can be called when the model is in float or qat mode.
Please note the following:
1) For fused modules, the 'preserve_qat_mode=True' setting will only take effect if 'conv' has 'preserve_qat_mode=True' set.
Therefore, you can set 'conv.preserve_qat_mode=True' to set 'fused.preserve_qat_mode=True' as well. Here is an example:
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv = torch.nn.Conv2d()
self.bn = torch.nn.BatchNorm2d()
self.add = FloatFunctional()
self.relu = torch.nn.Relu()
float_model = Model()
# Set float conv, correct
set_preserve_qat_mode(float_model, types=(torch.nn.Conv2d,))
# Set float bn, incorrect
set_preserve_qat_mode(float_model, types=(torch.nn.BatchNorm2d,))
float_model.fuse_modules()
float_model.qconfig = get_default_qat_qconfig()
qat_model = prepare_qat(float_model)
# Set float conv after fusing and converting to qat model, correct.
# In this way, 'preserve_qat_mode=True' will be set for all convs and fused modules (convbn, convbnadd, ...)
set_preserve_qat_mode(qat_model, types=(torch.nn.Conv2d,))
# Use the 'prefixes' parameter to specify a specific fused module. convbnaddrelu will be fused to the position of 'add'
set_preserve_qat_mode(qat_model, prefixes=("add",))
2) If the float model uses torch functions (such as torch.add, torch.pow) and is converted using fx,
these functions will be automatically replaced with D-Robotics operators. To set 'preserve_qat_mode=True'
for these functions, you need to set 'preserve_qat_mode=True' for the corresponding D-Robotics operator in the qat model. Here is an example:
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add = torch.add
float_model = Model()
# Convert to qat model using fx
qat_model = prepare_qat_fx(float_model)# Set through the types, correct. All FloatFunctional in the qat model will be set
# preserve_qat_mode = True
set_preserve_qat_mode(qat_model, types=(FloatFunctional,))
# Use the prefixes parameter to specify a function (like add). "add_generated_add_0" is the name
# of the automatically generated add module
set_preserve_qat_mode(qat_model, prefixes=("add_generated_add_0",))
Parameters:
model: The model that requires output statistics
prefixes: Specify the layer names in the model corresponding to the op that needs output statistics
(layers starting with prefixes)
types: Specify the types of op that need output statistics. If the input is a floating-point model,
types must be floating-point op types;
if the input is a QAT model, types can be either floating-point or qat op types
value: Set preserve_qat_mode=value. Default value is True
"""
Usage example:
import horizon_plugin_pytorch as horizon
import numpy as np
import torch
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch.quantization.quantize_fx import (
convert_fx,
prepare_qat_fx,
)
from horizon_plugin_pytorch.utils.quant_profiler import set_preserve_qat_mode
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
class Conv2dModule(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=1,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode="zeros",
):
super().__init__()
self.conv2d = nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
dilation,
groups,
bias,
padding_mode,
)
self.add = FloatFunctional()
self.bn_mod = nn.BatchNorm2d(out_channels)
self.relu_mod = nn.ReLU()
def forward(self, x, y):
x = self.conv2d(x)
x = self.bn_mod(x)
x = self.add.add(x, y)
x = self.relu_mod(x)
return x
class TestFuseNet(nn.Module):
def __init__(self, channels) -> None:
super().__init__()
self.convmod1 = Conv2dModule(channels, channels)
self.convmod2 = Conv2dModule(channels, channels)
self.convmod3 = Conv2dModule(channels, channels)
self.shared_conv = nn.Conv2d(channels, channels, 1)
self.bn1 = nn.BatchNorm2d(channels)
self.bn2 = nn.BatchNorm2d(channels)
self.sub = FloatFunctional()
self.relu = nn.ReLU()
def forward(self, x, y):
x = self.convmod1(x, y)
x = self.convmod2(y, x)
x = self.convmod3(x, y)
x = self.shared_conv(x)
x = self.bn1(x)
y = self.shared_conv(y)
y = self.bn2(y)
x = self.sub.sub(x, y)
x = self.relu(x)return x
model = TestFuseNet(3)
# The interface can be called to set, or you can manually specify preserve_qat_mode=True
set_preserve_qat_mode(float_net, ("convmod1"), ())
model.convmod1.preserve_qat_mode = True
# Set BERNOULLI2 for **RDK X3** and BAYES for **RDK Ultra**.
set_march(March.BAYES)
qat_net = prepare_qat_fx(model, {"": default_qat_8bit_fake_quant_qconfig})
quant_model = horizon.quantization.convert_fx(qat_net)
# In the quantized model, convmod1.add is still qat.ConvAddReLU2d
assert isinstance(quant_model.convmod1.add, horizon_nn.qat.ConvAddReLU2d)
Device Check for Heterogeneous Model Deployment
horizon_plugin_pytorch supports deploying heterogeneous models using fx. The device check tool for heterogeneous model will check whether each operator in the model runs on BPU or CPU during deployment.
# from horizon_plugin_pytorch.utils.quant_profiler import check_deploy_device
def check_deploy_device(
model: torch.fx.GraphModule,
print_tabulate: bool = True,
out_dir: Optional[str] = None,
) -> Dict[str, Tuple[str, str]]:
"""Check whether each operator runs on CPU or BPU during the deployment of a heterogeneous model.
Args:
model: QAT model or quantized model. Must be obtained through the `prepare_qat_fx` interface.
print_tabulate: Whether to print the result. Default is True.
out_dir: The path to save deploy_device.txt. Default is None, saved to the current path.
Returns:
A dict that records the device (BPU/CPU) on which each op runs during deployment, in the following format:
* KEY (str): module name (e.g., layer1.0.conv.weight)
* VALUE (Tuple): (deployment device(BPU/CPU), module type)
"""
Example usage:
import numpy as np
import torch
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn import qat
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.quantization import (
prepare_qat_fx,
convert_fx,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
default_qat_out_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch.utils.quant_profiler import check_deploy_device
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
class _ConvBlock(nn.Module):
def __init__(self, channels=3):
super().__init__()
self.conv = nn.Conv2d(channels, channels, 1)
self.prelu = torch.nn.PReLU()
def forward(self, input):
x = self.conv(input)
x = self.prelu(x)
return torch.nn.functional.selu(x)
class _SeluModule(nn.Module):
def forward(self, input):
return torch.nn.functional.selu(input)
class HybridModel(nn.Module):
def __init__(self, channels=3):
super().__init__()
self.quant = QuantStub()
self.conv0 = nn.Conv2d(channels, channels, 1)
self.prelu = torch.nn.PReLU()
self.conv1 = _ConvBlock(channels)
self.conv2 = nn.Conv2d(channels, channels, 1)
self.conv3 = nn.Conv2d(channels, channels, 1)
self.conv4 = nn.Conv2d(channels, channels, 1)
self.selu = _SeluModule()
self.dequant = DeQuantStub()
self.identity = torch.nn.Identity()
self.add = FloatFunctional()
def forward(self, input):
x = self.quant(input)
x = self.conv0(x)
x = self.identity(x)
x = self.prelu(x)
x = torch.nn.functional.selu(x)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.identity(x)
y = self.conv4(x)
x = self.add.add(x, y)
x = self.selu(x)
return self.dequant(x)
# **RDK X3** set BERNOULLI2, **RDK Ultra** set to BAYES.
set_march(March.BAYES)
shape = np.random.randint(10, 20, size=4).tolist()
infer_shape = [1] + shape[1:]
infer_data = torch.rand(size=infer_shape)
model = HybridModel(shape[1])
model(infer_data)
# use fx interface for heterogeneous
qat_model = prepare_qat_fx(
model,
{
"": default_qat_8bit_fake_quant_qconfig,
"module_name": [("conv4", default_qat_out_8bit_fake_quant_qconfig)],
},
hybrid=True,
hybrid_dict={
"module_name": ["conv1.conv", "conv3"],
"module_type": [_SeluModule],
},
)
qat_model(infer_data)
check_deploy_device(qat_model)
quantize_model = convert_fx(qat_model)
check_deploy_device(quantize_model)
Will be presented in table format, simultaneously displayed on the screen and saved in deploy_device.txt as follows. Each column from left to right in the table represents:
- name: The name defined for this operation in the model.
- deploy device: The actual device on which the operation runs during deployment, either CPU or BPU.
- type: The invocation form of this operation in the model, either module or function.
name deploy device type
------------------------------ --------------- --------
conv0 BPU module
prelu_input_dequant CPU module
prelu CPU module
selu CPU function
conv1.conv CPU module
conv1.prelu CPU module
selu_1 CPU function
selu_1_activation_post_process CPU module
conv2 BPU module
conv3_input_dequant CPU module
conv3 CPU module
conv3_activation_post_process CPU module
add_1 BPU method
selu_2_input_dequant CPU module
selu_2 CPU function
dequant CPU module
Comparison of TorchScript and HBDK Results
When encountering situations where the inference results of fixed-point PT generated by horizon_plugin_pytorch do not match the compiled HBM inference results, you can use this tool to check whether the inference results of PT and the results parsed by HBDK are consistent. This tool will output the comparison of each op in PT and the corresponding op in HBDK after parsing.
When encountering inconsistencies between the inference results of fixed-point PT and HBM results or on-board results, please ensure that the preprocessing and postprocessing processes are consistent. In addition, the parsing of PT by HBDK is only one step in the compilation process, and the HBM inference results and the final on-board inference results are determined by HBDK and runtime, etc. Even if this tool is used to check and confirm that the inference results of fixed-point PT are consistent with the results parsed by HBDK, it still cannot guarantee consistency with the final on-board results. For verification of subsequent processes, please contact the HBDK or runtime development team.
# from horizon_plugin_pytorch.utils.quant_profiler import script_profile
def script_profile(
model: Union[torch.nn.Module, torch.jit.ScriptModule],
example_inputs: Any,
out_dir: Optional[str] = None,
march: Optional[str] = None,
mark_node_func: Optional[Callable] = None,
compare_with_hbdk_parser: bool = True,
):
"""
Obtain the results of each op in the ScriptModel and compare them with the results parsed by HBDK.
This function will obtain the results of each op in the ScriptModel and store the results in the "horizon_script_result.pt" file using torch.save, and also return the results in the form of a dictionary.
Parameters:
model: The model to be checked. It must be a fixed-point model or a ScriptModule after tracing.
example_inputs: Model inputs.
out_dir: The path to save the results. If None, it will be saved in the current path. Default is None.
march: BPU architecture to use. If None, it will automatically use get_march() to get the current specified architecture.
Default is None. For **RDK X3**, set to BERNOULLI2, for **RDK Ultra**, set to BAYES.
mark_node_func: Function to mark which nodes in the ScriptModule need to save results.
If None, use the default marking function. Default is None.
compare_with_hbdk_parser: Whether to compare the results of each op in the ScriptModule with the results parsed by HBDK.
Default is True, it will compare with the parsing results of HBDK and output the comparison results on the screen.
Returns:
output (dict<str, tensor>): A dictionary recording the results of each op in the pt, in the following format:
* KEY (str): op name, consistent with the name of each op parsed by HBDK
* VALUE (tensor): op result
"""
Example:
import torch
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.quantization.quantize_fx import (
convert_fx,
prepare_qat_fx,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch.utils.quant_profiler import script_profile
class Net(nn.Module):
def __init__(self, share_op=True):
super(Net, self).__init__()
self.quant_stubx = QuantStub()
self.quant_stuby = QuantStub()
self.unused = nn.ReLU()
self.mul_op = FloatFunctional()
self.cat_op = FloatFunctional()
self.add_op = FloatFunctional()
self.quantized_ops = nn.Sequential(
nn.ReLU(),
nn.Sigmoid(),
nn.Softmax(),
nn.SiLU(),
horizon_nn.Interpolate(
scale_factor=2, recompute_scale_factor=True
),
horizon_nn.Interpolate(
scale_factor=2.3, recompute_scale_factor=True
),
nn.AvgPool2d(kernel_size=4),
nn.Upsample(scale_factor=1.3, mode="bilinear"),
nn.UpsamplingBilinear2d(scale_factor=0.7),
)
self.dequant_stub = DeQuantStub()
self.share_op = share_op
def forward(self, x, y):
x = self.quant_stubx(x)
y = self.quant_stuby(y)
y = self.add_op.add(x, y)
x = self.cat_op.cat((x, y), 1)
if self.share_op:
x = self.cat_op.cat((x, y), dim=1)
a, b = x.split(15, dim=1)
x = self.mul_op.mul(a, b)
x = self.quantized_ops(x)
x = self.dequant_stub(x)
return x
# Set BERNOULLI2 for RDK X3 and BAYES for RDK Ultra.
set_march(March.BAYES)
device = torch.device("cpu")
data = torch.rand((1, 10, 5, 5), device=device)
data = (data, data)
float_net = Net().to(device)
float_net(*data)
qat_net = prepare_qat_fx(float_net, {"": default_qat_8bit_fake_quant_qconfig})
qat_net = qat_net.to(device)
qat_net(*data)
bpu_net = convert_fx(qat_net)
script_module = torch.jit.trace(bpu_net.eval(), data)
# Set BERNOULLI2 for RDK X3 and BAYES for RDK Ultra.
script_profile(bpu_net, data, march=March.BAYES)
The compared results will be displayed on the screen as follows:
name if equal
------------------------------------------ ----------
arg0 True
arg1 True
_hz_cat True
_hz_cat_1 True
_aten_split.0 True
_aten_split.1 True
_hz_mul True
_quantized_ops_0_aten_relu True
_quantized_ops_1_hz_lut True
_quantized_ops_2_aten_max_val True
_quantized_ops_2_aten_max_arg True
_quantized_ops_2_hz_sub True
_quantized_ops_2_exp_hz_segment_lut True
_quantized_ops_2_hz_sum True
_quantized_ops_2_reciprocal_hz_segment_lut True
_quantized_ops_2_hz_mul True
_quantized_ops_3_hz_lut True
_quantized_ops_4_hz_interpolate True
_quantized_ops_5_hz_interpolate True
_quantized_ops_6_hz_avg_pool2d True
_quantized_ops_7_hz_interpolate True
_quantized_ops_8_hz_interpolate True
Torch run pt output is same with hbdk parser.
Comparison of Results from Different Versions of TorchScript Models
When encountering issues where the fixed-point PT inference results of the same model are inconsistent after the version change of horizon_plugin_pytorch, after ensuring consistency in the preprocessing and postprocessing processes of different versions, you can use this tool to compare the results of each op in different versions of PT.
# from horizon_plugin_pytorch.utils.quant_profiler import compare_script_models
def compare_script_models(
model1: torch.jit.ScriptModule,
model2: torch.jit.ScriptModule,
example_inputs: Any,
march: Optional[str] = None,
):
"""
Compare the results of two ScriptModules.
This function compares whether the results of each op in the ScriptModule generated by different versions of horizon_plugin_pytorch for the same model are consistent.
Parameters:
model1: ScriptModule generated by a certain version of horizon_plugin_pytorch.
model2: ScriptModule generated by another version of horizon_plugin_pytorch.
example_inputs: Model inputs.
march: BPU architecture to use. If None, it will automatically use get_march() to get the current specified architecture.
Default is None. For **RDK X3**, set to BERNOULLI2, for **RDK Ultra**, set to BAYES.
"""
import torch
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
from horizon_plugin_pytorch import nn as horizon_nn
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn.quantized import FloatFunctional
from horizon_plugin_pytorch.quantization.quantize_fx import (
convert_fx,
prepare_qat_fx,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch.utils.quant_profiler import compare_script_models
class Net(nn.Module):
def __init__(self, share_op=True):
super(Net, self).__init__()
self.quant_stubx = QuantStub()
self.quant_stuby = QuantStub()
self.unused = nn.ReLU()
self.mul_op = FloatFunctional()
self.cat_op = FloatFunctional()
self.add_op = FloatFunctional()
self.quantized_ops = nn.Sequential(
nn.ReLU(),
nn.Sigmoid(),
nn.Softmax(),
nn.SiLU(),
horizon_nn.Interpolate(
scale_factor=2, recompute_scale_factor=True
),
horizon_nn.Interpolate(
scale_factor=2.3, recompute_scale_factor=True
),
nn.AvgPool2d(kernel_size=4),
nn.Upsample(scale_factor=1.3, mode="bilinear"),
nn.UpsamplingBilinear2d(scale_factor=0.7),
)
self.dequant_stub = DeQuantStub()
self.share_op = share_op
def forward(self, x, y):
x = self.quant_stubx(x)
y = self.quant_stuby(y)
y = self.add_op.add(x, y)
x = self.cat_op.cat((x, y), 1)
if self.share_op:
x = self.cat_op.cat((x, y), dim=1)
a, b = x.split(15, dim=1)
x = self.mul_op.mul(a, b)
x = self.quantized_ops(x)
x = self.dequant_stub(x)
return x
# **RDK X3** set BERNOULLI2, **RDK Ultra** set BAYES。
set_march(March.BAYES)
device = torch.device("cpu")
data = torch.rand((1, 10, 5, 5), device=device)
data = (data, data)
float_net = Net().to(device)
float_net(*data)
qat_net = prepare_qat_fx(float_net, {"": default_qat_8bit_fake_quant_qconfig})
qat_net = qat_net.to(device)
qat_net(*data)
bpu_net = convert_fx(qat_net)
script_module = torch.jit.trace(bpu_net.eval(), data)
# Actual usage requires inputting two different versions of ScriptModules.
compare_script_models(script_module, script_module, data)
会在屏幕输出如下结果:
name if equal
------------------------------------------ ----------
arg0 True
arg1 True
_hz_add True
_hz_cat True
_hz_cat_1 True
_aten_split.0 True
_aten_split.1 True
_hz_mul True
_quantized_ops_0_aten_relu True
_quantized_ops_1_hz_lut True
_quantized_ops_2_aten_max_arg True
_quantized_ops_2_aten_max_val True
_quantized_ops_2_hz_sub True
_quantized_ops_2_exp_hz_segment_lut True
_quantized_ops_2_hz_sum True
_quantized_ops_2_reciprocal_hz_segment_lut True
_quantized_ops_2_hz_mul True
_quantized_ops_3_hz_lut True
_quantized_ops_4_hz_interpolate True
_quantized_ops_5_hz_interpolate True
_quantized_ops_6_hz_avg_pool2d True
_quantized_ops_7_hz_interpolate True
_quantized_ops_8_hz_interpolate True
All ops in two ScriptModules are same.
Model Memory Occupation Analysis Tool
The Plugin provides a tool for analyzing the memory occupation of the model, which helps you locate memory bottlenecks and save memory by using techniques such as checkpoint and saved tensor.
# from horizon_plugin_pytorch.utils.quant_profiler import show_cuda_memory_consumption
def show_cuda_memory_consumption(
model: torch.nn.Module,
example_inputs: Any,
device: torch.device,
check_leaf_module=None,
out_dir: Optional[str] = None,
file_name: Optional[str] = None,
custom_backward=None,
):
"""
Evaluate the memory consumption of the model during forward and backward process.
The result will be saved as an html file.
Known issue: When checkpoint is used in the model, the names of some backward entries
will be displayed as forward, because the checkpoint causes the forward hook to be called
during the backward process.
Args:
model: The model to be evaluated.
example_inputs (Any[Tensor]): Input to the model.
device: The device to be used for evaluation.
check_leaf_module: Check if a module is a leaf node. Default is None, using the
predefined is_leaf_module, which treats all ops defined in horizon_plugin_pytorch
and unsupported floating point ops as leaf nodes.
out_dir: Path to save the html result. Default is None, which saves to the current path.
file_name: Name of the saved html file. If not specified, defaults to mem_info.
custom_backward: Perform backward operation with model outputs. Must set retain_graph=False.
Default is None, in which case the model output must be a single Tensor.
"""
Usage example:
# Define MobilenetV1 here (omitted)
float_net = MobilenetV1()
show_cuda_memory_consumption(float_net, data, torch.device("cuda"))
The following results will be generated in the directory specified by the current or out_dir parameter.
- mem_info.html

Tips for Debugging Quantized Training Precision
Reference Process
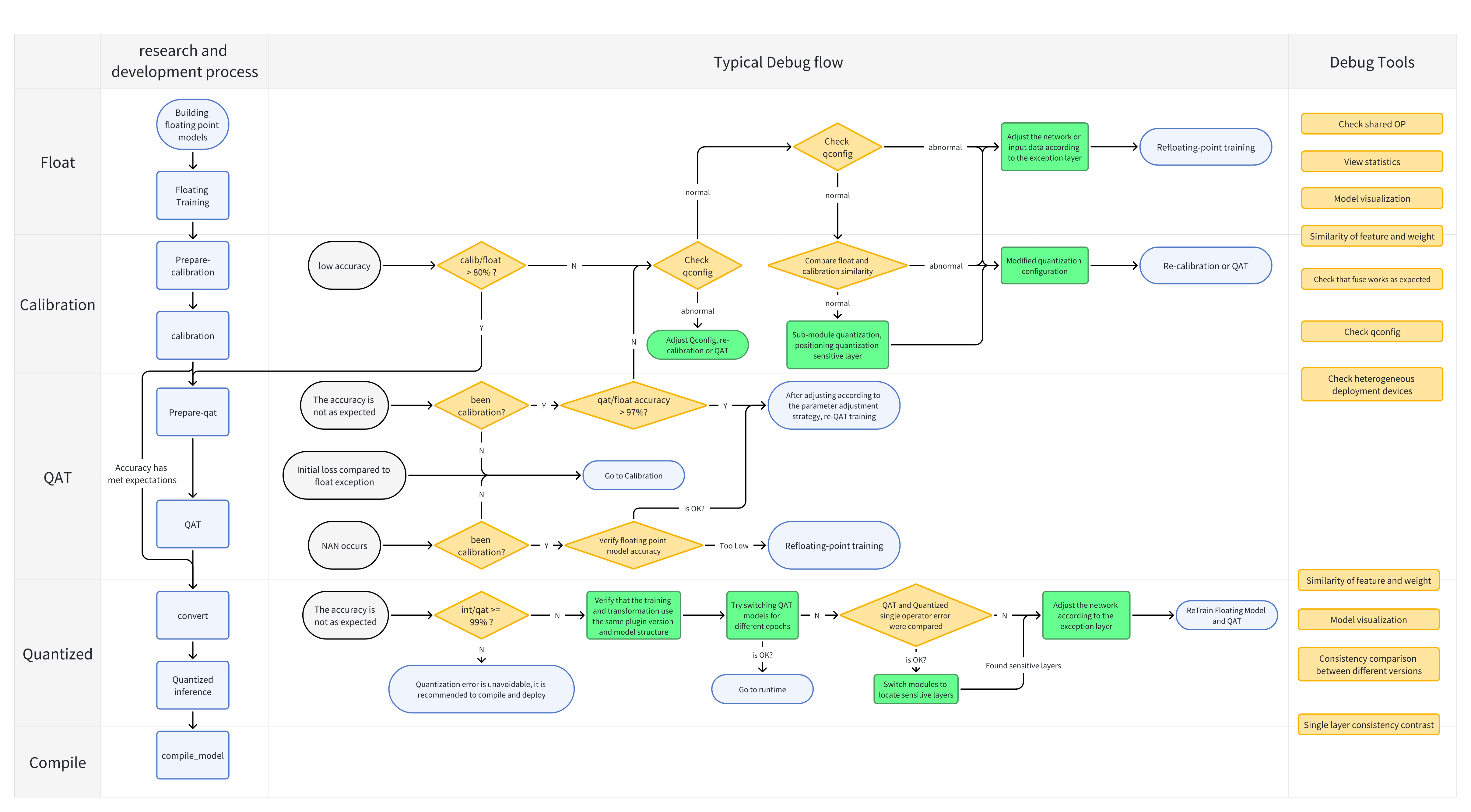
Introduction
Quantized training tools simulate quantization during training to make the deployed quantization precision as close as possible to floating-point precision. The amount of loss in quantization precision compared to floating-point precision is determined by many factors. This chapter provides some recommended practices for users to optimize their quantized training precision.
Because quantized training is based on fine-tuning the floating-point model, the optimization guidelines described in this chapter are effective on the basis of a floating-point model that meets the expected precision.
Quantized training is essentially model training, but the limitations of the deployment platform have increased the difficulty of model training. This article summarizes some experiences from horizon_plugin_pytorch in the hope of helping users tune their models.
Recommended Hyperparameter Configuration
Except for the hyperparameters listed in the table below, keep the rest consistent between the QAT and floating-point stages.
| Hyperparameter | Adjustment Policy |
|---|---|
| LR | lr=0.001, with 2 lr decays of scale=0.1 lr=0.0001, with 1 lr decay of scale=0.1 |
| Epoch | 10% to 20% of the floating-point epoch |
Anomalies in Precision
During QAT training or deployment of quantized models, the following common anomalies may occur:
-
The expected precision is not achieved in QAT, but the loss relative to float is not significant;
In this case, we recommend that you improve the precision according to the parameter adjustment strategy.
-
NAN appears
This is generally caused by gradient explosion leading to numerical overflow and NAN. We recommend that you try the following steps one by one:
-
Check if the floating-point model precision is normal. If there are issues or low precision in the floating-point stage of the model, it may cause this problem. It is recommended to fully train and converge the floating-point model before using QAT.
-
Check for the presence of nan or inf values in the data and labels.
-
Lower the learning rate or use a warmup strategy.
-
Use torch.nn.utils.clip_grad_norm_ to perform gradient clipping.
-
If none of the above methods work, it is recommended to debug the quantization exception layer.
- QAT initial loss is significantly abnormal compared to float
If the initial loss of QAT is significantly abnormal compared to float and there is no rapid decrease, it is recommended to debug the quantization exception layer.
- Relative loss of Quantized is larger than QAT precision loss
In general, the relative loss of Quantized compared to QAT is very small. If there is a larger loss or unexpected phenomenon, it is recommended to:
- First confirm if it is a model-induced loss of precision, rather than inconsistency in preprocessing and postprocessing.
- Confirm if it is a loss of precision at the model level, and recommend debugging the quantization exception layer.
- Calibration precision is low
In this case, it is recommended to debug the quantization exception layer.
Parameter tuning strategy
Besides adjusting the learning rate as mentioned in the Recommended Configuration, it is suggested to consider the following aspects to improve the accuracy of quantization training:
-
Quantization Parameter Initialization
Using quantization parameters that better match the statistical characteristics of the data for parameter initialization can improve the accuracy of QAT; we recommend using Calibration before QAT.
NoteIf the accuracy of Calibration is not significantly different from floating-point, it is best not to adjust the activation scale further, i.e., set activation averaging_constant=0.0; specific settings can be found in Custom Qconfig.
-
Transform (Data Augmentation)
It is recommended to keep it consistent with floating-point by default during QAT, or it can be appropriately weakened, such as removing color conversion for classification, and reducing the range of scale for RandomResizeCrop.
-
Optimizer
By default, keep it consistent with floating-point during QAT, or you can try SGD. If the optimizer used for floating-point training affects LR setting, such as OneCycle, it is recommended not to keep it consistent with floating-point and use SGD instead.
If the above strategies still cannot effectively improve the quantization accuracy, please try Debug Quantization Exception Layers.
Debug quantization exception layer
At a fundamental level, the abnormal quantization accuracy of models is caused by insufficient numerical resolution of some quantized layers. Currently, in QAT tools, the input and output (feature maps) of operators correspond to a quantization parameter (per-tensor), while the weights correspond to a set of quantization parameters (per-channel). Therefore, for a group of quantized data, the higher the numerical resolution after quantization, the smaller the impact on quantization accuracy.
We recommend the following steps to identify layers that may have insufficient quantization resolution:
-
Confirm if the quantization configuration meets expectations
The quantization configuration determines the quantization strategy for a layer, which is crucial. In general, we recommend using the default int8 quantization configuration, and special configurations are only necessary in certain cases, such as not quantizing network outputs.
It is suggested to use the Quantization Configuration Check to verify if the quantization configuration meets expectations (checking of calibration models is not currently supported).
-
Find layers with quantization abnormalities using Debug Tools
There are several typical phenomena of quantization abnormalities that can be identified using the Statistics Tool and Similarity Comparison Tool:
-
Abnormal statistics for certain layers in the model, such as a large value range or uneven histogram distribution (outliers).
-
Low similarity for certain layers (float vs calibration or qat vs quantized).
-
High error rate for individual operators in certain layers (float vs calibration or qat vs quantized).
NoteThe similarity comparison tool is suitable for comparing the similarity between
float and calibration,qat and quantizedmodels. When dealing with QAT accuracy abnormalities, considering QAT will change the distribution of model outputs or weights, please do not use the similarity comparison tool.These three phenomena may occur simultaneously, for example, when there is low similarity, there may also be a high error rate for individual operators, as well as abnormal statistics. It is also possible that only one of these phenomena occurs, such as only having large statistics without any other abnormalities. There are many possible causes for these phenomena, and we recommend troubleshooting gradually starting from the model itself:
-
Model Input
There are generally two types of model inputs: raw data (images, radar, etc.) and auxiliary inputs of the model (such as transformer positional encoding). These data need to be quantized before being used as inputs to the quantized network.
Due to the symmetric uniform quantization used by the QAT tool, if the model input data itself requires high numerical resolution or has non-symmetric (relative to 0) characteristics, it is recommended to make improvements using the following methods:
-
Normalize the input data with respect to 0 during data preprocessing before inputting it.
-
Adjust the physical meaning of the input data and use symmetric, low-range, and low-resolution data as input.
-
Check if the quantization configuration is reasonable. For example, it is recommended to use a fixed quantization scale of 1/128.0 for image inputs. However, a fixed scale may not be suitable for all data and requires specific analysis.
-
If high data resolution is required and cannot be adjusted, it is recommended to use int16 quantization.
NoteCurrently, only the RDK Ultra with BPU architecture as "BAYES" supports setting "int16" quantization.
Taking image input as an example, since the original image (whether it is RGB or YUV) has a range of [0, 255], it is not suitable for symmetric quantization. After normalization with respect to 0, the input range becomes [-1, 1], and it can be directly quantized using a fixed scale of 1/128.0.
NoteDebug Cost: In the above suggestions, the first 2 points require retraining with floating-point precision, while the last 2 points require retraining with QAT. -
-
Model Output
Model output often has physical meaning and may require high resolution, making it unsuitable for int8 quantization. It is recommended to:
-
Output without quantization. Currently, when conv2d is used as the network output, it supports output without quantization.
-
If quantized output is needed due to BPU performance or other reasons, it is recommended to use int16 quantization or reduce the output data resolution by adjusting the physical meaning of the output.
NoteCurrently, only RDK Ultra with BPU architecture "BAYES" supports setting "int16" quantization.
NoteDebug Cost: In the above suggestions, if the physical meaning of the output is adjusted according to the second point, retraining with floating-point precision is required; otherwise, retraining with QAT is needed.
-
Intermediate Layers of the Model
-
Output (feature map)
From the implementation perspective, there are two types of operators: 1. Single-grain operators, such as conv2d; 2. Complex operators implemented by multiple smaller operators, such as layernorm. Here, the focus is on the overall output of the operator, ignoring the output of smaller operators within complex operators.
If the numerical range of the operator output is large, it is recommended to:
-
Limit the values within a certain range by modifying the model structure. Different schemes can be used for different operators, such as adding BN after conv2d, replacing relu with relu6, etc.
-
Use int16 quantization.
NoteCurrently, only RDK Ultra with BPU architecture "BAYES" supports setting "int16" quantization.
- If encountering patterns like conv-[bn]-[add]-relu, trying to specify the use of relu6 in the QAT stage may be effective (not guaranteed).
NoteDebug Cost: In the above suggestions, after adjusting according to the first point, retraining with floating-point precision is required; otherwise, retraining with QAT is needed.
-
-
Weight
If the numerical range of the weight in a certain layer is large, you can:
- Try adjusting the weight decay. It is recommended to make appropriate adjustments around 4e-5, avoiding values that are too large or too small. Too small weight decay may result in large weight variance, while too large weight decay may lead to chain reactions, such as large weight variance in network layer outputs.
CautionDebug cost: retraining float required after adjustment.
-
Operators
If the quantized error is significantly larger than the unquantized error after quantization of a certain layer, it indicates that there may be some limitations in the quantized implementation of this operator. Generally, the following types of operators have larger quantization errors:
-
Multi-input operators, such as "cat". If there is a large difference in input value range, it may result in large numbers overpowering small numbers, leading to abnormal accuracy. Try the following improvements:
a. Restrict the input range through various means to make the values of multiple inputs similar.
b. Use int16 quantization.
CautionCurrently, only the RDK Ultra with "BAYES" as the BPU architecture supports setting "int16" quantization.
-
Non-linear activation operators, such as "reciprocal". If the operator itself has large fluctuations in certain interval values, it is generally implemented through table lookup. Due to the limited number of table entries, insufficient resolution may occur when the output is in a steep range. Try the following improvements:
-
Evaluate whether this operator can be omitted or replaced with other operators.
-
Limit the input range to a more gentle interval.
-
Use int16 quantization.
CautionCurrently, only the RDK Ultra with "BAYES" as the BPU architecture supports setting "int16" quantization.
-
If the QAT precision is normal but the quantized precision is insufficient, try manually adjusting the table lookup parameters.
-
-
Complex operators, such as "layernorm" and "softmax". They are generally composed of multiple small operators, which may also cause accuracy problems due to the aforementioned non-linear activation operators. Try the following improvements:
-
Evaluate whether this operator can be omitted or replaced with other operators.
-
If the QAT precision is normal but the quantized precision is insufficient, try manually adjusting the table lookup parameters. Both "layernorm" and "softmax" support manual parameter adjustment.
-
-
CautionCurrently, only the RDK Ultra with "BAYES" as the BPU architecture supports setting "int16" quantization.
Debug cost: If it is necessary to adjust the input range or operator in the above three cases, retraining float is required. If int16 quantization is to be used, retraining QAT is required. If only manually adjusting the table lookup parameters, it is only necessary to convert the QAT model to the quantized model again.
- Network structure When implementing the network structure, if there is shared operator in multiple branches, it may cause the quantization parameter to quantize multiple branch outputs at the same time, which may result in insufficient resolution of the quantized output. It is recommended to split the shared operator into multiple operators.
CautionDebug cost: Re-training QAT is needed.
-
-
Find the quantization abnormal layer by quantizing in a modular way.
If the quantization abnormal layer cannot be located using the debug tool, it is necessary to analyze which module's quantization leads to quantization accuracy error by quantizing in a modular way. After locating the relevant module or operator, it indicates that the numerical resolution after quantization of this module is insufficient, and it is recommended to try using int16 quantization. For specific steps of modular quantization, please refer to Step Quantization Tool (used when the Calibration or QAT model has accuracy exception) and Single Operator Precision Debugging Tool (used when the fixed-point model has accuracy exceptions).
Currently, only the RDK Ultra with BPU architecture as "BAYES" supports setting int16 quantization.
Debug cost: Re-training QAT is needed after using int16 quantization.
Currently, only the RDK Ultra with BPU architecture as "BAYES" supports setting int16 quantization.
- Using int16 will reduce deployment performance. Please choose according to the specific situation;
- Some operators do not support int16 quantization, see the operator support list for details;
- In order to further improve accuracy, users can choose heterogeneous mode deployment. It should be noted that this method has a significant impact on performance.
Cross-device Inference Instructions for Quantized Deployment PT Models
The pt model deployed with quantization requires that the device used when tracing and the device used for subsequent inference are consistent.
If the user tries to modify the device of the pt model directly through the to(device) operation, it may cause an error in the model forward. Torch official has explained this, see TorchScript-Frequently Asked Questions — PyTorch documentation.
The following example illustrates:
import torch
class Net(torch.nn.Module):
def forward(self, x: torch.Tensor):
y = torch.ones(x.shape, device=x.device)
z = torch.zeros_like(x)
return y + z
script_mod = torch.jit.trace(
Net(), torch.rand(2, 3, 3, 3, device=torch.device("cpu"))
)
script_mod.to(torch.device("cuda"))
print(script_mod.graph)
# graph(%self : __torch__.Net,
# %x : Float(2, 3, 3, 3, strides=[27, 9, 3, 1], requires_grad=0, device=cpu)):
# %4 : int = prim::Constant[value=0]()
# %5 : int = aten::size(%x, %4)
# %6 : Long(device=cpu) = prim::NumToTensor(%5)
# %16 : int = aten::Int(%6)
# %7 : int = prim::Constant[value=1]()
# %8 : int = aten::size(%x, %7)
# %9 : Long(device=cpu) = prim::NumToTensor(%8)
# %17 : int = aten::Int(%9)
# %10 : int = prim::Constant[value=2]()
# %11 : int = aten::size(%x, %10)
# %12 : Long(device=cpu) = prim::NumToTensor(%11)
# %18 : int = aten::Int(%12)
# %13 : int = prim::Constant[value=3]()
# %14 : int = aten::size(%x, %13)
# %15 : Long(device=cpu) = prim::NumToTensor(%14)
# %19 : int = aten::Int(%15)
# %20 : int[] = prim::ListConstruct(%16, %17, %18, %19)
# %21 : NoneType = prim::Constant()
# %22 : NoneType = prim::Constant()
# %23 : Device = prim::Constant[value="cpu"]()
# %24 : bool = prim::Constant[value=0]()
# %y : Float(2, 3, 3, 3, strides=[27, 9, 3, 1], requires_grad=0, device=cpu) = aten::ones(%20, %21, %22, %23, %24)
# %26 : int = prim::Constant[value=6]()
# %27 : int = prim::Constant[value=0]()
# %28 : Device = prim::Constant[value="cpu"]()
# %29 : bool = prim::Constant[value=0]()
# %30 : NoneType = prim::Constant()
# %z : Float(2, 3, 3, 3, strides=[27, 9, 3, 1], requires_grad=0, device=cpu) = aten::zeros_like(%x, %26, %27, %28, %29, %30)
# %32 : int = prim::Constant[value=1]()
# %33 : Float(2, 3, 3, 3, strides=[27, 9, 3, 1], requires_grad=0, device=cpu) = aten::add(%y, %z, %32)
# return (%33)
As can be seen, after calling to(torch.device("cuda")), the aten::ones and aten::zeros_like operations in the model's graph still have the prim::Constant[value="cpu"]() device parameter. Therefore, when forward pass the model, their outputs will still be cpu tensors. This is because to(device) can only move the buffer (weight, bias, etc.) in the model and cannot modify the graph of the ScriptModule.
The official solution to the above limitation is to determine the device on which the pt model will be executed before tracing, and trace on the corresponding device.
For the above limitation, the training tool recommends the following solutions based on specific scenarios:
PT model execution device inconsistent with trace
For cases where the pt model will only run on the GPU and only the card number needs to be modified, we recommend using cuda:0, which is the zeroth card, for tracing. When using the model, users can use the torch.cuda.set_device interface to map any physical card to the logical "zero card". In this case, the model traced using cuda:0 will actually run on the specified physical card.If the device used during trace and the device used during execution are inconsistent (e.g., CPU and GPU), users can use the horizon_plugin_pytorch.jit.to_device interface to migrate the device of the pt model. This interface will search for the device parameters in the model graph and replace them with the desired values. The effect is as follows:
from horizon_plugin_pytorch.jit import to_device
script_mod = to_device(script_mod, torch.device("cuda"))
print(script_mod.graph)
# graph(%self : __torch__.Net,
# %x.1 : Tensor):
# %38 : bool = prim::Constant[value=0]()
# %60 : Device = prim::Constant[value="cuda"]()
# %34 : NoneType = prim::Constant()
# %3 : int = prim::Constant[value=0]()
# %10 : int = prim::Constant[value=1]()
# %17 : int = prim::Constant[value=2]()
# %24 : int = prim::Constant[value=3]()
# %41 : int = prim::Constant[value=6]()
# %4 : int = aten::size(%x.1, %3)
# %5 : Tensor = prim::NumToTensor(%4)
# %8 : int = aten::Int(%5)
# %11 : int = aten::size(%x.1, %10)
# %12 : Tensor = prim::NumToTensor(%11)
# %15 : int = aten::Int(%12)
# %18 : int = aten::size(%x.1, %17)
# %19 : Tensor = prim::NumToTensor(%18)
# %22 : int = aten::Int(%19)
# %25 : int = aten::size(%x.1, %24)
# %26 : Tensor = prim::NumToTensor(%25)
# %32 : int = aten::Int(%26)
# %33 : int[] = prim::ListConstruct(%8, %15, %22, %32)
# %y.1 : Tensor = aten::ones(%33, %34, %34, %60, %38)
# %z.1 : Tensor = aten::zeros_like(%x.1, %41, %3, %60, %38, %34)
# %50 : Tensor = aten::add(%y.1, %z.1, %10)
# return (%50)
Multi-GPU parallel inference
In this scenario, users need to obtain the pt model on cuda:0 through trace or to_device, and open a separate process for each card, setting different default cards for each process using torch.cuda.set_device. A simple example is as follows:
import os
import torch
import signal
import torch.distributed as dist
import torch.multiprocessing as mp
from horizon_plugin_pytorch.jit import to_device
model_path = "path_to_pt_model_file"
def main_func(rank, world_size, device_ids):
torch.cuda.set_device(device_ids[rank])
dist.init_process_group("nccl", rank=rank, world_size=world_size)
model = to_device(torch.jit.load(model_path), torch.device("cuda"))
# Data loading, model forward, accuracy calculation, etc. are omitted here
def launch(device_ids):
try:
world_size = len(device_ids)
mp.spawn(
main_func,
args=(world_size, device_ids),
nprocs=world_size,
join=True,
)
# Close all child processes when Ctrl+c is pressed
except KeyboardInterrupt:
os.killpg(os.getpgid(os.getpid()), signal.SIGKILL)
launch([0, 1, 2, 3])
The above operations on the pt model are consistent with the approach of torch.nn.parallel.DistributedDataParallel. For data loading and model accuracy calculation, please refer to Getting Started with Distributed Data Parallel — PyTorch Tutorials.
Common Issues
Import error
Error 1: Cannot find the extension library(_C.so)
Solution:
- Make sure the horizon_plugin_pytorch version matches the cuda version
- In python3, find the execution path of horizon_plugin_pytorch and check if there are .so files in that directory. There may be multiple versions of horizon_plugin_pytorch coexisting, and only one desired version should be kept by uninstalling the rest.
Error 2: RuntimeError: Cannot load custom ops. Please rebuild the horizon_plugin_pytorch
Solution: Confirm whether the local CUDA environment is normal, such as path, version, etc.
Unable to prepare_calibration/qat
RuntimeError: Only Tensors created explicitly by the user (graph leaves) support the deepcopy protocol at the momentSolution: This error usually occurs when the model contains non-leaf tensors. Please try the following solutions:
- Set the inplace parameter of "prepare_calibration/qat" to True.
- Normally, the operators defined in horizon_plugin_pytorch do not cause this error. Please check if there are any non-leaf tensors defined in the custom operators of the model.
Error in forward after prepare_qat
TypeError: when calling function <built-in method conv2d of type object at >
Solution: This error occurs when a custom operator inherits a module operator from torch, which causes "prepare_qat" to fail to convert to a qat module. It is recommended to call conv2d using submodule.
Compilation Error
ValueError 'unsupported node', aten::unbind
Solution: This error occurs when a tensor is treated as a list and is passed to zip for processing, and eventually calls the "iter" method of the tensor, which internally uses the unbind operation. Please check your code.
Abnormal Quantization Precision
The QAT/Quantized precision does not meet expectations, and there may be NAN or QAT initial loss is significantly different from float.
Solution: Please refer to the Quantization Training Precision Tuning Guide
Error when using torch.jit.load to load pt file
RuntimeError: Unknown builtin op: horizon::bpu_scale_quantization
Solution: Please check if you have imported horizon_plugin_pytorch before using torch.jit.load. Otherwise, the corresponding D-Robotics operator cannot be found during loading. It is recommended to use horizon.jit.save/load to save and load pt files to avoid such errors. In addition, when saving pt using horizon.jit.save, the version number of horizon_plugin_pytorch will also be saved, and horizon.jit.load will check if the current horizon_plugin_pytorch version is compatible with the saved pt. If not, a corresponding warning will be output.
Common Misunderstandings
Incorrect Settings
Modules that do not need quantization are set with a non-None qconfig, such as pre-processing, loss functions, etc.
Correct approach: Only set qconfig for modules that need to be quantized.
The march is not set correctly, which may cause the model compilation failure or inconsistent deployment accuracy.
Correct approach: Select the correct BPU architecture based on the processor to be deployed, for example:
## For RDK Ultra, use Bayes
horizon.march.set_march(horizon.march.March.Bayes)
## For RDK X3, use Bernoulli2
horizon.march.set_march(horizon.march.March.Bernoulli2)
The model output nodes are not set to high-precision output, resulting in quantization precision not meeting expectations.
Example of incorrect setting: Assuming the model is defined as follows:
class ToyNet(nn.Module):
def __init__(self):
self.conv0 = nn.Conv2d(4,4,3,3)
self.relu0 = nn.ReLU()
self.classifier = nn.Conv2d(4,4,3,3)
def forward(self, x):
out = self.conv0(x)
out = self.relu(out)
out = self.classifier(out)
return out
# Incorrect qconfig setting example:
float_model = ToyNet()
qat_model = prepare_qat_fx(
float_model,
{
"": default_qat_8bit_fake_quant_qconfig, # Set the entire network to int8 quantization
},
)
Correct approach: To improve model accuracy, set the model output node to high precision. The example is as follows:
qat_model = prepare_qat_fx(
float_model,
{
"module_name": {
"classifier": default_qat_out_8bit_fake_quant_qconfig, # Set the output of the network classifier layer to high precision
},
"": default_qat_8bit_fake_quant_qconfig, # Set other layers to int8 quantization
},
)
Method-related error
Calibration process uses multiple GPUs.
Due to limitations at the moment, Calibration does not support multiple GPUs. Please perform Calibration operations using a single GPU.
The model input image data uses formats such as RGB instead of centered YUV444, which can result in inconsistent model deployment accuracy.
Correct approach: Due to D-Robotics hardware limitations, we recommend that users directly use the YUV444 format as the network input for training from the beginning.
Using the QAT model for model accuracy evaluation and monitoring during quantization training can cause delayed detection of deployment accuracy anomalies.
Correct approach: The reason for the discrepancy between QAT and Quantized is that the QAT stage cannot fully simulate the pure fixed-point calculation logic in the Quantized stage. It is recommended to use the quantized model for model accuracy evaluation and monitoring.
quantized_model = convert_fx(qat_model.eval())
acc = evaluate(quantized_model, eval_data_loader, device)
Network-related error
Multiple calls to the same member defined through FloatFunctional().
Incorrect example:class ToyNet(nn.Module): def init(self): self.add = FloatFunctional()
def forward(self, x, y, z) out = self.add(x, y) return self.add(out, z)
Correct Approach: It is forbidden to call the same variable defined by FloatFunctional() multiple times in forward.
class ToyNet(nn.Module):
def __init__(self):
self.add0 = FloatFunctional()
self.add1 = FloatFunctional()
def forward(self, x, y, z)
out = self.add0.add(x, y)
return self.add1.add(out, z)
Operator Class Error
Some operators in the quantized model have not undergone pre-calibration or QAT, such as a post-processing operator that wants to accelerate on BPU, but has not gone through the quantization stage. This will cause quantized inference failure or abnormal precision during deployment.
Correct Approach: In the quantized stage, operators can be added directly, such as color space conversion operators. For specific guidelines on adding operators, please refer to the documentation. However, not all operators can be added directly. For example, the "cat" operator must have the real quantization parameters obtained in the calibration or QAT stage to avoid affecting the final precision. If you have similar requirements, you need to adjust the network structure and you can consult the framework developer.
Model Class Error
Floating-point model overfitting.
Common methods to determine model overfitting:
- After slightly transforming the input data, the output results vary greatly.
- Model parameters have large assignments.
- Model activations are large.
Correct Approach: Solve floating-point model overfitting problem on your own.