Deep Exploration
Customizing qconfig
Customizing qconfig requires users to have a clear understanding of the specific processor restrictions, a detailed understanding of the working principles of the training tools, and a detailed understanding of how to reflect the processor restrictions through qconfig. Quantization training requires a certain training cost, and errors in qconfig definition may result in the model not being able to converge properly or the model not being able to compile. Therefore, it is not recommended for ordinary users to customize qconfig.
The horizon_plugin_pytorch uses the partial function method provided by PyTorch to define qconfig. For the usage of this method, please refer to the official documentation. Users who are not familiar with this method should learn it before continuing to read.
Currently, qconfig handles two types of information:
- Quantization information of activation
- Quantization information of weight
Quantization information of Activation
activation_8bit_fake_quant = FakeQuantize.with_args(
observer=MovingAveragePerTensorMinMaxObserver,
dtype="qint8",
ch_axis=0,
averaging_constant=0 # Custom parameter for observer
)
Quantization information of Weight
weight_8bit_fake_quant = FakeQuantize.with_args(
observer=MovingAveragePerChannelMinMaxObserver,
dtype="qint8",
ch_axis=0,
averaging_constant=1 # Custom parameter for observer
)
QConfig
By encapsulating the quantization information of activation and weight using Qconfig, qconfig can be obtained.
qat_8bit_qconfig = QConfig(
activation=activation_8bit_fake_quant, weight=weight_8bit_fake_quant
)
Introduction to FX Quantization
TheoryBefore reading this document, it is recommended to read torch.fx — PyTorch documentation to have a preliminary understanding of the FX mechanism in PyTorch.
FX adopts a symbolic execution approach to build graphs at the level of nn.Module or functions, enabling automated fusion and other graph-based optimizations.
Quantization Process
Fuse (Optional)
FX is able to perceive the computation graph, allowing for automated operator fusion. Users no longer need to manually specify the operators to be fused; they can simply call the interface.
fused_model = horizon.quantization.fuse_fx(model)
- Note that
fuse_fxdoes not have aninplaceparameter because it needs to perform symbolic tracing on the model to generate aGraphModule, thus in-place modification is not possible. fused_modelandmodelshare almost all attributes (including sub-modules and operators), so please refrain from modifyingmodelafter fusion, as it may affectfused_model.- Users do not need to call the
fuse_fxinterface explicitly, as the subsequentprepare_qat_fxinterface internally integrates the fusion process.
Prepare
Before calling the prepare_qat_fx interface, users must set the global march according to the target hardware platform. The interface will first perform the fusion process (even if the model has already been fused) and then replace the qualifying operators in the model with implementations from horizon.nn.qat.
- Users can choose the appropriate qconfig (Calibration or QAT), but note that the two qconfigs cannot be mixed.
- Similar to
fuse_fx, this interface does not support theinplaceparameter, and refrain from any modifications to the input model afterprepare_qat_fx.
# Set march to BERNOULLI2 for RDK X3, and to BAYES for RDK Ultra.
horizon.march.set_march(horizon.march.March.BAYES)
qat_model = horizon.quantization.prepare_qat_fx(
model,
{
"": horizon.qconfig.default_calib_8bit_fake_quant_qconfig,
"module_name": {
"<module_name>": custom_qconfig,
},
},)
Convert
- Similar to
fuse_fx, this interface does not support theinplaceparameter, and refrain from any modifications to the input model afterconvert_fx.
quantized_model = horizon.quantization.convert_fx(qat_model)
Eager Mode Compatibility
In most cases, the quantization interfaces in FX can directly replace the quantization interfaces in eager mode (prepare_qat -> prepare_qat_fx, convert -> convert_fx). However, they cannot be mixed with the interfaces in eager mode. Some models may require modifications in the code structure under the following circumstances.- Unsupported operations in FX: The operations supported by torch's symbolic trace are limited, for example, it does not support using non-static variables as conditional statements, and default does not support packages outside of torch (such as numpy). Additionally, unexecuted conditional branches will be discarded.
- Operations to avoid being handled by FX: If torch operations are used in the pre and post-processing of the model, FX will treat them as part of the model during trace, which may lead to unexpected behavior (e.g., replacing certain function calls with FloatFunctional).
Both of these situations can be avoided using the "wrap" method, illustrated below using RetinaNet as an example.
from horizon_plugin_pytorch.utils.fx_helper import wrap as fx_wrap
class RetinaNet(nn.Module):
def __init__(
self,
backbone: nn.Module,
neck: Optional[nn.Module] = None,
head: Optional[nn.Module] = None,
anchors: Optional[nn.Module] = None,
targets: Optional[nn.Module] = None,
post_process: Optional[nn.Module] = None,
loss_cls: Optional[nn.Module] = None,
loss_reg: Optional[nn.Module] = None,
):
super(RetinaNet, self).__init__()
self.backbone = backbone
self.neck = neck
self.head = head
self.anchors = anchors
self.targets = targets
self.post_process = post_process
self.loss_cls = loss_cls
self.loss_reg = loss_reg
def rearrange_head_out(self, inputs: List[torch.Tensor], num: int):
outputs = []
for t in inputs:
outputs.append(t.permute(0, 2, 3, 1).reshape(t.shape[0], -1, num))
return torch.cat(outputs, dim=1)
def forward(self, data: Dict):
feat = self.backbone(data["img"])
feat = self.neck(feat) if self.neck else feat
cls_scores, bbox_preds = self.head(feat)
if self.post_process is None:
return cls_scores, bbox_preds
# Wrap the operations that do not need to be traced into a method. FX will no longer focus on the logic inside the method,
# only preserving it as it is (the modules called within the method can still be set with qconfig, and can be replaced
# by prepare_qat_fx and convert_fx)
return self._post_process( data, feat, cls_scores, bbox_preds)
@ fx_warp() # fx_wrap supports directly decorate class method
def _post_process(self, data, feat, cls_scores, bbox_preds)
anchors = self.anchors(feat)
# The judgment of self.training must be encapsulated, otherwise, after the symbolic trace, this judgment
# The logic will be lost
if self.training:
cls_scores = self.rearrange_head_out(
cls_scores, self.head.num_classes
)
bbox_preds = self.rearrange_head_out(bbox_preds, 4)
gt_labels = [
torch.cat(
[data["gt_bboxes"][i], data["gt_classes"][i][:, None] + 1],
dim=-1,
)
for i in range(len(data["gt_classes"]))
]
gt_labels = [gt_label.float() for gt_label in gt_labels]
_, labels = self.targets(anchors, gt_labels)
avg_factor = labels["reg_label_mask"].sum()
if avg_factor == 0:
avg_factor += 1
cls_loss = self.loss_cls(
pred=cls_scores.sigmoid(),
target=labels["cls_label"],
weight=labels["cls_label_mask"],
avg_factor=avg_factor,
)
reg_loss = self.loss_reg(
pred=bbox_preds,
target=labels["reg_label"],
weight=labels["reg_label_mask"],
avg_factor=avg_factor,
)
return {
"cls_loss": cls_loss,
"reg_loss": reg_loss,
}
else:
preds = self.post_process(
anchors,
cls_scores,
bbox_preds,
[torch.tensor(shape) for shape in data["resized_shape"]],
)
assert (
"pred_bboxes" not in data.keys()
), "pred_bboxes has been in data.keys()"data["pred_bboxes"] = preds
return data
RGB888 Data Deployment
Scenario
In the BPU, the output images from the image pyramid are in a centered YUV444 format with a data range of [-128, 127]. However, your training dataset might be in RGB format, which requires preprocessing to align with the BPU's input requirements. During training, it's recommended to convert RGB images to YUV to ensure compatibility with the model's inference pipeline.
Since the compiler currently doesn't support color space conversions, users can manually insert color space conversion nodes to bypass these limitations.
Brief on YUV Format
YUV is commonly used to describe color spaces in analog television systems. In BT.601, YUV has two standards: YUV studio swing (Y: 16-235, UV: 16-240) and YUV full swing (YUV: 0-255). The BPU supports full swing YUV.
Preprocessing RGB Input during Training
When training, you can use horizon.functional.rgb2centered_yuv or horizon.functional.bgr2centered_yuv to convert RGB images to the BPU-supported YUV format. For example, the rgb2centered_yuv function definition is as follows:
def rgb2centered_yuv(input: Tensor, swing: str = "studio") -> Tensor:
"""Convert color space.
Convert images from RGB format to centered YUV444 BT.601
Args:
input: input image in RGB format, ranging 0~255
swing: "studio" for YUV studio swing (Y: -112~107,
U, V: -112~112)
"full" for YUV full swing (Y, U, V: -128~127).
default is "studio"
Returns:
output: centered YUV image
"""
The input is an RGB image, and the output is a centered YUV image. To match the BPU data flow format, set swing to "full"`.
Real-time Conversion of YUV Input during Inference
We recommend converting RGB images to YUV during training to avoid extra overhead and accuracy loss during inference. However, if you've trained with RGB images, you can use horizon.functional.centered_yuv2rgb or horizon.functional.centered_yuv2bgr for on-the-fly conversion at inference time. These functions should be inserted after the QuantStub in your model.
For instance, the centered_yuv2rgb operator definition looks like this:
def centered_yuv2rgb(
input: QTensor,
swing: str = "studio",
mean: Union[List[float], Tensor] = (128.0,),
std: Union[List[float], Tensor] = (128.0,),
q_scale: Union[float, Tensor] = 1.0 / 128.0,
) -> QTensor:
To align with BPU's YUV format, set swing to "full"`.
The operator adjusts the input according to the following steps:
- Converts the image to RGB using the formula corresponding to the given
swing. - Normalizes the RGB image using provided
meanandstd. - Quantizes the RGB image using the given
q_scale.

Note: This operator is designed specifically for deployment and should not be used during training.
Insertion of the Operator
To integrate this operator into your model, follow these steps after QAT model conversion:
- Retrieve the scale value from the QuantStub and the normalization parameters used during training.
- Convert the QAT model to a quantized model using
convert_fx. - Insert the
centered_yuv2rgboperator after the QuantStub, providing the gathered parameters. - Manually set the QuantStub's
scaleparameter to 1.
Here's an example:
import torch
from horizon_plugin_pytorch.quantization import (
QuantStub,
prepare_qat_fx,
convert_fx,
)
from horizon_plugin_pytorch.functional import centered_yuv2rgb
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch import set_march
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.quant = QuantStub()
self.conv = torch.nn.Conv2d(3, 3, 3)
self.bn = torch.nn.BatchNorm2d(3)
self.relu = torch.nn.ReLU()
def forward(self, input):
x = self.quant(input)
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
def set_qconfig(self):
self.qconfig = default_qat_8bit_fake_quant_qconfig
data = torch.rand(1, 3, 28, 28)
net = Net()
# Set march to BERNOULLI2 for RDK X3, and to BAYES for RDK Ultra.
set_march("bayes")
net.set_qconfig()
qat_net = prepare_qat_fx(net)
qat_net(data)
quantized_net = convert_fx(qat_net)
traced = quantized_net
print("Before centered_yuv2rgb")
traced.graph.print_tabular()
# Replace QuantStub nodes with centered_yuv2rgb
patterns = ["quant"]
for n in traced.graph.nodes:
if any(n.target == pattern for pattern in patterns):
with traced.graph.inserting_after(n):
new_node = traced.graph.call_function(centered_yuv2rgb, (n,), {"swing": "full"})
n.replace_all_uses_with(new_node)
new_node.args = (n,)
traced.quant.scale.fill_(1.0)
traced.recompile()
print("\nAfter centered_yuv2rgb")
traced.graph.print_tabular()
The graph comparison will show the insertion of the color space conversion node:
Before centered_yuv2rgb
opcode name target args kwargs
----------- ------- -------- ---------- --------
placeholder input_1 input () {}
call_module quant quant (input_1,) {}
call_module conv conv (quant,) {}
output output output (conv,) {}
After centered_yuv2rgb
opcode name target args kwargs
------------- ---------------- --------------------------------------------- ------------------- -----------------
placeholder input_1 input () {}
call_module quant quant (input_1,) {}
call_function centered_yuv2rgb <function centered_yuv2rgb at 0x7fa1c2b48040> (quant,) {'swing': 'full'}
call_module conv conv (centered_yuv2rgb,) {}
output output output (conv,) {}
Model Segmented Deployment
Scenario
In some scenarios, users may need to split a model, which was trained as a whole, into multiple segments for deployment on the board. For example, in a two-stage detection model like the one shown in the figure below, if DPP needs to be executed on the CPU and its output (roi) is used as the input for RoiAlign, users need to split the model into Stage1 and Stage2 and compile them separately. During runtime, the fixed-point data output by the backbone is directly used as the input for RoiAlign.

Method

-
Model Modification: As shown in the figure above, on the basis of a model that can be quantization-aware trained (QAT) normally, users need to insert a
QuantStubafter the segmentation point beforeprepare_qat. Note that ifhorizon_plugin_pytorch.quantization.QuantStubis used,scalemust be set to None. -
QAT Training: Perform quantization-aware training on the modified model as a whole. The inserted
QuantStubwill record the scale of the input data for Stage2 in the buffer. -
Conversion to Fixed-Point: Convert the trained QAT model to fixed-point representation using the
convertinterface. -
Splitting and Compilation: Split the model according to the form after deployment on the board, and trace and compile each segmented model separately. Note that although the input for Stage2 is quantized data during training, the
example_inputfor tracing Stage2 still needs to be in floating-point format. The insertedQuantStubin Stage2 will be responsible for configuring the scale of the data correctly and quantizing it.
Operator Fusion
The operator fusion supported by the training tool can be divided into two categories: 1. Absorbing BN; 2. Fusing Add and ReLU(6).### Absorb BN
The purpose of absorbing BN is to reduce the computational cost of the model. Since BN is a linear transformation process, when BN appears together with Conv, the parameters of BN can be absorbed into the parameters of Conv, thereby eliminating the computation of BN in the deployed model.
The calculation process of absorption is as follows:
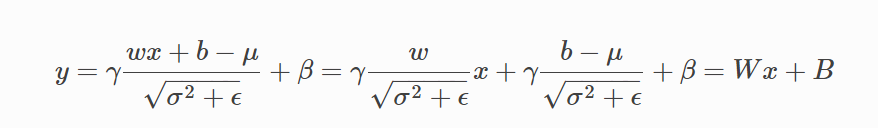
By absorbing BN, Conv2d + BN2d can be simplified to Conv2d.

Fusion of Add and ReLU(6)
Unlike CUDA Kernel Fusion, which fuses CUDA Kernels to improve computational speed, the fusion supported by the training toolkit focuses more on the quantization level.
BPU hardware has been optimized for common model structures. When calculating the combination of Conv -> Add -> ReLU, the hardware can preserve high-precision state for data passing between operators, thus improving the overall numerical precision of the model. Therefore, during quantization of the model, we can treat Conv -> Add -> ReLU as a whole.
Since the training toolkit quantizes the model based on torch.nn.Module, in order to treat Conv -> Add -> ReLU as a whole during quantization, they need to be merged into a single Module.
Operator fusion not only preserves high-precision state for intermediate results, but also eliminates the process of converting intermediate results to low-precision representation. Therefore, the execution speed is faster compared to not fusing the operators.
(Since operator fusion can improve both model precision and speed, it is generally recommended to fuse all possible parts.)
Operator Fusion
The training tools support two main categories of operator fusion: 1. Absorbing Batch Normalization (BN); 2. Fusing Add and ReLU(6).
Absorbing Batch Normalization (BN)
The purpose of absorbing BN is to reduce model computation. Since BN is a linear transformation, when it follows a Conv layer, the BN parameters can be absorbed into the Conv parameters, eliminating BN computations during deployment.
The absorption process looks like this:
By absorbing BN, a Conv2d + BN2d sequence can be simplified to just Conv2d.
Fusing Add, ReLU(6)
Unlike CUDA Kernel Fusion that aims to improve computational speed, the fusion supported by training tools leans more towards quantization. The BPU hardware optimizes common model structures, allowing for high-precision data transfer between Conv, Add, and ReLU operators, enhancing overall numerical precision. During quantization, these operators can be treated as a single unit.
Since training tools quantize models at the torch.nn.Module level, to treat Conv -> Add -> ReLU as a whole during quantization, they need to be merged into a single Module.
Operator fusion not only retains high precision intermediate results but also eliminates the need for converting them to low-precision representation, resulting in faster execution compared to non-fused scenarios.
Note: Operator fusion is generally beneficial due to its improvements in both model accuracy and speed, so it should be applied to all eligible parts.
Implementation Principle
Thanks to the graph analysis capability provided by FX, the training tools can automatically analyze the model's computation graph and apply fusion patterns to eligible sections. Submodules are replaced to implement the fusion operation. Here's an example:
Absorbing BN and fusing Add, ReLU(6) can be done using the same mechanism, so there's no need to differentiate during fusion.
import torch
from torch import nn
from torch.quantization import DeQuantStub
from horizon_plugin_pytorch.quantization import QuantStub
from horizon_plugin_pytorch.quantization import fuse_fx
class ModelForFusion(nn.Module):
def __init__(self):
super(ModelForFusion, self).__init__()
self.quantx = QuantStub()
self.quanty = QuantStub()
self.conv = nn.Conv2d(3, 3, 3)
self.bn = nn.BatchNorm2d(3)
self.relu = nn.ReLU()
self.dequant = DeQuantStub()
def forward(self, x, y):
x = self.quantx(x)
y = self.quanty(y)
x = self.conv(x)
x = self.bn(x)
x = x + y
x = self.relu(x)
x = self.dequant(x)
return x
float_model = ModelForFusion()
fused_model = fuse_fx(float_model)
print(fused_model)
"""
ModelForFusion(
(quantx): QuantStub()
(quanty): QuantStub()
(conv): Identity()
(bn): Identity()
(relu): Identity()
(dequant): DeQuantStub()
(_generated_add_0): ConvAddReLU2d(
(conv): Conv2d(3, 3, kernel_size=(3, 3), stride=(1, 1))
(relu): ReLU()
)
)
...
def forward(self, x, y):
quantx = self.quantx(x); x = None
quanty = self.quanty(y); y = None
_generated_add_0 = self._generated_add_0
add_1 = _generated_add_0(quantx, quanty); quantx = quanty = None
dequant = self.dequant(add_1); add_1 = None
return dequant
"""
After applying operator fusion, the BN is absorbed into the Conv, and Conv, Add, and ReLU are fused into a single Module (_generated_add_0). Original submodules are replaced with Identity, and the calls to them are removed from the forward function.
FX automatically replaces the + operator in the model with a Module named _generated_add_0 to support fusion and quantization operations.
Supported Operator Combinations
The current supported combinations for fused operators are defined in the following function:
import operator
import torch
from torch import nn
from horizon_plugin_pytorch import nn as horizon_nn
def register_fusion_patterns():
convs = (
nn.Conv2d,
nn.ConvTranspose2d,
nn.Conv3d,
nn.Linear,
)
bns = (nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d, nn.SyncBatchNorm)
adds = (
nn.quantized.FloatFunctional.add,
horizon_nn.quantized.FloatFunctional.add,
torch.add,
operator.add, # The '+' operator used in code
)
relus = (nn.ReLU, nn.ReLU6, nn.functional.relu, nn.functional.relu6)
for conv in convs:
for bn in bns:
for add in adds:
for relu in relus:
# Conv BN
register_fusion_pattern((bn, conv))(ConvBNAddReLUFusion)
# Conv ReLU
register_fusion_pattern((relu, conv))(ConvBNAddReLUFusion)
# Conv Add
register_fusion_pattern((add, conv, MatchAllNode))(
ConvBNAddReLUFusion
) # Conv output as first input to add
register_fusion_pattern((add, MatchAllNode, conv))(
ConvBNAddedReLUFusion
) # Conv output as second input to add
# Conv BN ReLU
register_fusion_pattern((relu, (bn, conv)))(
ConvBNAddReLUFusion
)
# Conv BN Add
register_fusion_pattern((add, (bn, conv), MatchAllNode))(
ConvBNAddReLUFusion
)
register_fusion_pattern((add, MatchAllNode, (bn, conv)))(
ConvBNAddedReLUFusion
)
# Conv Add ReLU
register_fusion_pattern((relu, (add, conv, MatchAllNode)))(
ConvBNAddReLUFusion
)
register_fusion_pattern((relu, (add, MatchAllNode, conv)))(
ConvBNAddedReLUFusion
)
# Conv BN Add ReLU
register_fusion_pattern(
(relu, (add, (bn, conv), MatchAllNode))
)(ConvBNAddReLUFusion)
register_fusion_pattern(
(relu, (add, MatchAllNode, (bn, conv)))
)(ConvBNAddedReLUFusion)
These patterns define which combinations of Conv, BN, Add, and ReLU operators can be fused.