3.3.4 yolov5 模型示例介绍
示例简介
YOLOv5 目标检测示例是一个位于 /app/pydev_demo/07_yolov5_sample/ 中的 Python 接口 开发代码示例,用于演示如何使用 YOLOv5 模型进行目标检测任务。 YOLOv5 是 YOLO 系列的最新版本,相比 YOLOv3 具有更高的检测精度和更快的推理速度。该示例展示了如何对静态图像进行目标检测,识别图像中的多种对象,并在图像上绘制检测框和置信度信息。
效果展示
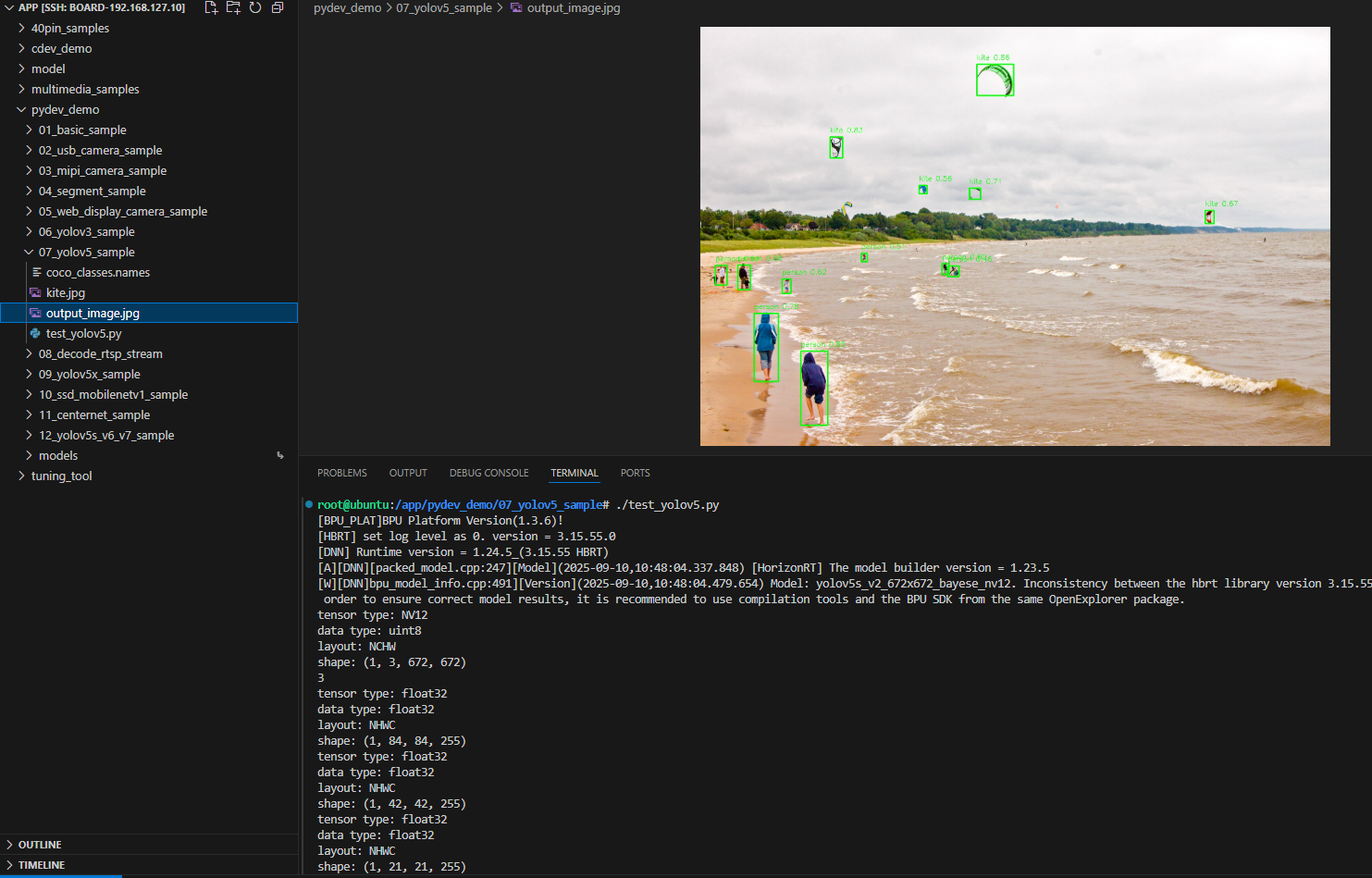
硬件准备
硬件连接
该示例只需要 RDK 开发板本身,无需额外的外设连接。确保开发板正常供电并启动系统。

快速开始
代码以及板端位置
进入到 /app/pydev_demo/07_yolov5_sample/ 位置,可以看到 YOLOv5 示例包含以下文件:
root@ubuntu:/app/pydev_demo/07_yolov5_sample# tree
.
├── coco_classes.names
├── kite.jpg
└── test_yolov5.py
编译以及运行
Python 示例无需编译,直接运行即可:
python3 test_yolov5.py
执行效果
运行后,程序会加载预训练的 YOLOv5 模型,对 kite.jpg 图像进行目标检测,并生成带有检测框的结果图像 output_image.jpg。
root@ubuntu:/app/pydev_demo/07_yolov5_sample# ./test_yolov5.py
[BPU_PLAT]BPU Platform Version(1.3.6)!
[HBRT] set log level as 0. version = 3.15.55.0
[DNN] Runtime version = 1.24.5_(3.15.55 HBRT)
[A][DNN][packed_model.cpp:247][Model](2025-09-10,10:48:04.337.848) [HorizonRT] The model builder version = 1.23.5
[W][DNN]bpu_model_info.cpp:491][Version](2025-09-10,10:48:04.479.654) Model: yolov5s_v2_672x672_bayese_nv12. Inconsistency between the hbrt library version 3.15.55.0 and the model build version 3.15.47.0 detected, in order to ensure correct model results, it is recommended to use compilation tools and the BPU SDK from the same OpenExplorer package.
tensor type: NV12
data type: uint8
layout: NCHW
shape: (1, 3, 672, 672)
3
tensor type: float32
data type: float32
layout: NHWC
shape: (1, 84, 84, 255)
tensor type: float32
data type: float32
layout: NHWC
shape: (1, 42, 42, 255)
tensor type: float32
data type: float32
layout: NHWC
shape: (1, 21, 21, 255)
bbox: [593.949768, 80.819038, 672.215027, 147.131607], score: 0.856997, id: 33, name: kite
bbox: [215.716019, 696.537476, 273.653442, 855.298706], score: 0.852251, id: 0, name: person
bbox: [278.934448, 236.631256, 305.838867, 281.294922], score: 0.834647, id: 33, name: kite
bbox: [115.184196, 615.987, 167.202667, 761.042542], score: 0.781627, id: 0, name: person
bbox: [577.261719, 346.008453, 601.795349, 370.308624], score: 0.705358, id: 33, name: kite
bbox: [1083.22998, 394.714569, 1102.146729, 422.34787], score: 0.673642, id: 33, name: kite
bbox: [80.515938, 511.157104, 107.181572, 564.28363], score: 0.662, id: 0, name: person
bbox: [175.470078, 541.949219, 194.192871, 572.981812], score: 0.623189, id: 0, name: person
bbox: [518.504333, 508.224396, 533.452759, 531.92926], score: 0.597822, id: 0, name: person
bbox: [469.970398, 340.634796, 486.181305, 358.508972], score: 0.5593, id: 33, name: kite
bbox: [32.987705, 512.65033, 57.665741, 554.898804], score: 0.508812, id: 0, name: person
bbox: [345.142609, 486.988464, 358.24762, 504.551331], score: 0.50672, id: 0, name: person
bbox: [530.825439, 513.695679, 555.200256, 536.498352], score: 0.459818, id: 0, name: person
draw result time is : 0.03627920150756836
详细介绍
示例程序参数选项说明
YOLOv5 目标检测示例不需要命令行参数,直接运行即可。程序会自动加载同目录下的 kite.jpg 图像进行检测处理。
软件架构说明
YOLOv5 目标检测示例的软件架构包含以下几个核心部分:
-
模型加载:使用 pyeasy_dnn 模块加载预训练的 YOLOv5 模型
-
图像预处理:将输入图像转换为模型需要的 NV12 格式和指定尺寸( 672x672 )
-
模型推理:调用模型进行前向计算,生成特征图
-
后处理:使用 libpostprocess 库解析模型输出,生成检测结果
-
结果可视化:在原图上绘制检测框和类别信息
-
结果保存:将可视化结果保存为图像文件

API 流程说明
-
模型加载: models = dnn.load('../models/yolov5s_672x672_nv12.bin')
-
图像预处理:调整图像尺寸并转换为 NV12 格式
-
模型推理: outputs = models[0].forward(nv12_data)
-
后处理配置:设置后处理参数(尺寸、阈值等)
-
结果解析:调用后处理库解析输出张量
-
结果可视化:在原图上绘制检测框和标签信息
-
结果保存:将结果保存为图像文件

FAQ
Q: YOLOv5 和 YOLOv3 有什么区别?
A: YOLOv5 在网络结构、训练策略和后处理算法上都有改进,通常具有更高的检测精度和更快的推理速度。
Q: 运行示例时出现 "No module named 'hobot_dnn'" 错误怎么办?
A: 请确保已正确安装 RDK 的 Python 环境, hobot_dnn 模块等官方提供的专用推理库。
Q: 如何更换测试图片?
A: 将新的图片文件放置在示例目录下,并在代码中修改 img_file = cv2.imread(' 你的图片路径 ')。
Q: 检��测结果不准确怎么办?
A: YOLOv5 模型是针对 COCO 数据集训练的,对于特定场景可能需要进行微调或使用更适合的模型。
Q: 如何调整检测阈值?
A: 在代码中修改 yolov5_postprocess_info.score_threshold 的值,例如改为 0.5 可以提高检测灵敏度。
Q: 可以实时处理视频流吗?
A: 当前示例是针对单张图像设计的,但可以修改代码以实现视频流的实时目标检测。
Q: 如何获取其他尺寸的 YOLOv5 模型?
A: 可以参考 model_zoo 仓库 或者 工具链的基础模型仓库
Q: 如何进一步提高检测速度?
A: 可以尝试使用更轻量的 YOLOv5 变体,如 YOLOv5n 或 YOLOv5s,或者降低输入图像的分辨率。