5.2.10 视觉语言模型
功能介绍
本章节介如何在RDK平台体验端侧 Vision Language Model (VLM)。得益于书生大模型 的优秀成果, 我们在RDK平台上实现了量化与部署。同时, 本示例基于 llama.cpp 中 KV Cache 的强大管理能力, 结合 RDK 平台 BPU 模块的计算优势, 实现了本地 VLM 模型部署。
代码仓库: (https://github.com/D-Robotics/hobot_llamacpp.git)
支持平台
| 平台 | 运行方式 | 示例功能 |
|---|---|---|
| RDK X5, RDK X5 Module | Ubuntu 22.04 (Humble) | 端侧视觉语言大模型体验 |
| RDK S100 | Ubuntu 22.04 (Humble) | 端侧视觉语言大模型体验 |
准备工作
RDK平台
- RDK为4GB内存版本
- RDK已烧录好Ubuntu 22.04系统镜像。
- RDK已成功安装TogetheROS.Bot。
- 下载安装功能包
sudo apt update
sudo apt install tros-humble-hobot-llamacpp
注意
如果sudo apt update命令执行失败或报错,请查看常见问题章节的Q10: apt update 命令执行失败或报错如何处理?解决。
使用方式
RDK平台
运行程序前,需要下载模型文件到运行路径,命令如下:
- RDK X5
- RDK S100
wget https://hf-mirror.com/D-Robotics/InternVL2_5-1B-GGUF-BPU/resolve/main/Qwen2.5-0.5B-Instruct-Q4_0.gguf
wget https://hf-mirror.com/D-Robotics/InternVL2_5-1B-GGUF-BPU/resolve/main/rdkx5/vit_model_int16_v2.bin
wget https://hf-mirror.com/D-Robotics/InternVL2_5-1B-GGUF-BPU/resolve/main/Qwen2.5-0.5B-Instruct-Q4_0.gguf
wget https://hf-mirror.com/D-Robotics/InternVL2_5-1B-GGUF-BPU/resolve/main/rdks100/vit_model_int16.hbm
使用命令srpi-config修改ION memory大小为2.5GB,设置方法参考RDK用户手册配置工具srpi-config使用指南Performance Options章节。
重启后设置CPU最高频率为1.5GHz,以及调度模式为performance,命令如下:
sudo bash -c 'echo 1 > /sys/devices/system/cpu/cpufreq/boost'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu1/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu2/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu3/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu4/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu5/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu6/cpufreq/scaling_governor'
sudo bash -c 'echo performance >/sys/devices/system/cpu/cpu7/cpufreq/scaling_governor'
目前提供两种体验方式,一种直接终端输入图片,文本体验,一种订阅图片和文本消息,然后将结果以文本方��式发布出去。
单图推理体验
- RDK X5
- RDK S100
source /opt/tros/humble/setup.bash
cp -r /opt/tros/${TROS_DISTRO}/lib/hobot_llamacpp/config/ .
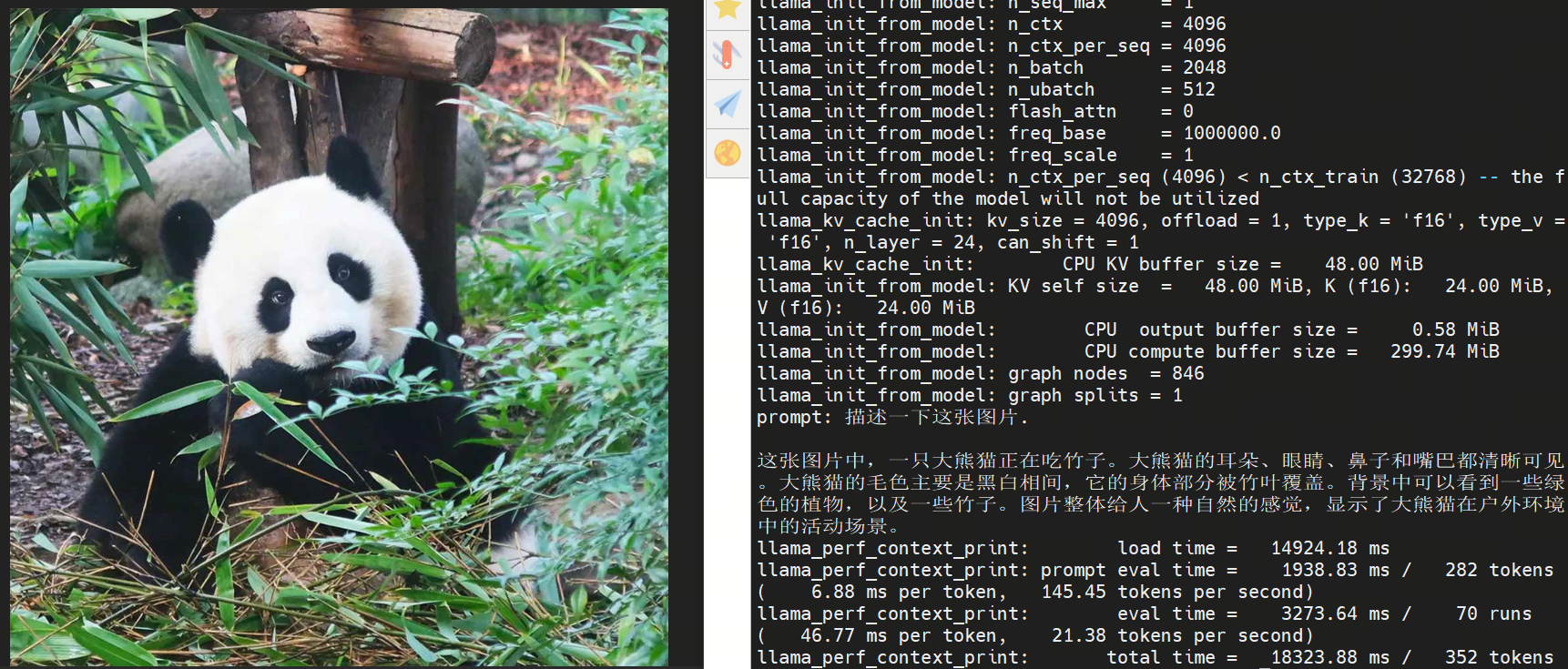
ros2 run hobot_llamacpp hobot_llamacpp --ros-args -p feed_type:=0 -p image:=config/image2.jpg -p image_type:=0 -p user_prompt:="描述一下这张图片." -p model_file_name:=vit_model_int16_v2.bin
source /opt/tros/humble/setup.bash
cp -r /opt/tros/${TROS_DISTRO}/lib/hobot_llamacpp/config/ .
ros2 run hobot_llamacpp hobot_llamacpp --ros-args -p feed_type:=0 -p image:=config/image2.jpg -p image_type:=0 -p user_prompt:="描述一下这张图片." -p model_file_name:=vit_model_int16.hbm
程序启动后,可使用本地图片与自定义提示词进行输出。
注意事项
确认开发板内存为4GB,同时修改ION memory大小为2.5GB,否则会导致模型加载失败。