Principles and Steps of PTQ
Introduction
Model conversion refers to the process of converting the original floating-point model to the Heterogeneous Line model. The original floating-point model (also referred to as the floating-point model in some places in this article) refers to the model you trained using DL frameworks such as TensorFlow/PyTorch, with a computational precision of float32. The Heterogeneous Line model is a model format that is suitable for running on the Heterogeneous Line processor. This chapter will repeatedly use these two model terms. To avoid misunderstandings, please understand this concept before reading further.
The complete development process of the model with the Heterogeneous Line algorithm toolchain requires five important stages: Floating-point Model Preparation, Model Verification, Model Conversion, Performance Evaluation, and Accuracy Evaluation, as shown in the following diagram:
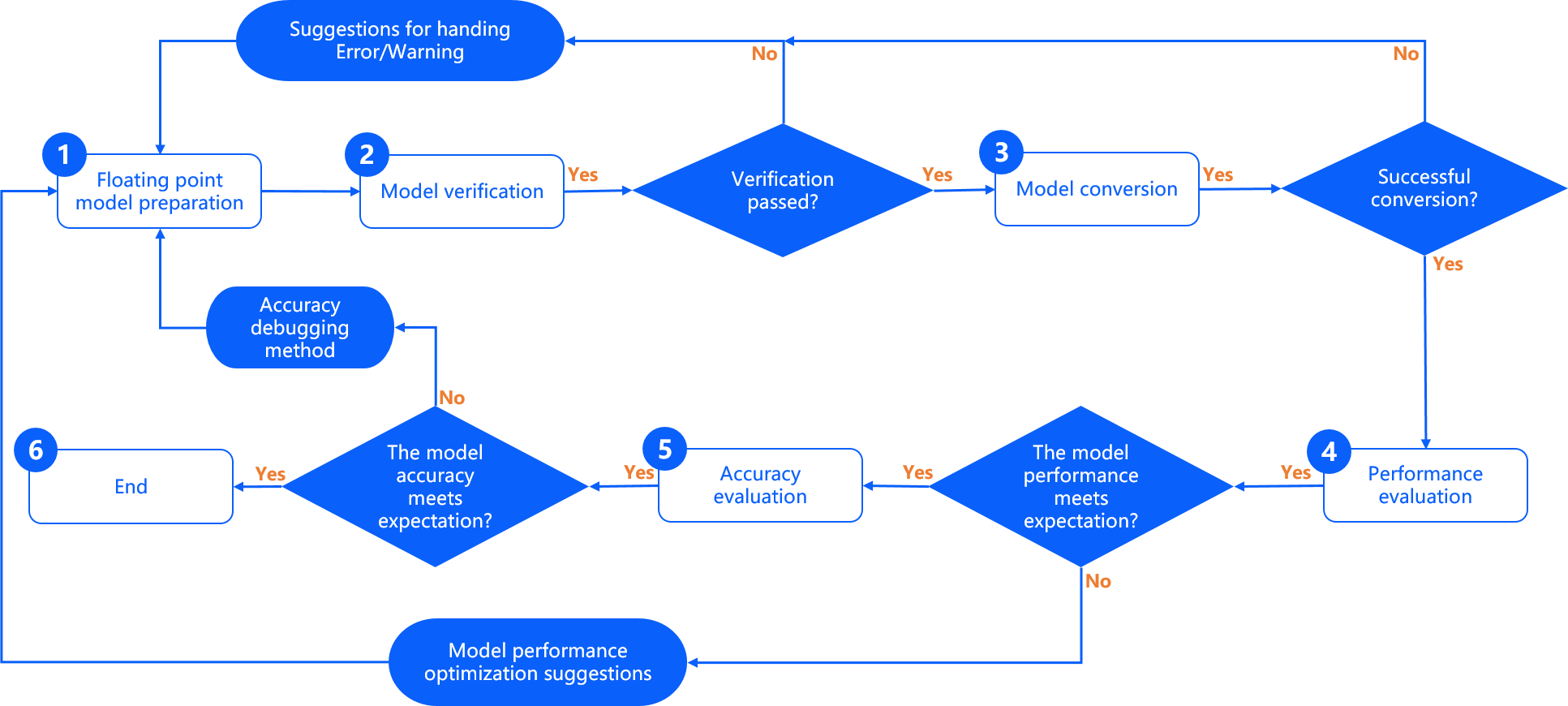
Floating-point Model Preparation This stage is used to ensure that the format of the original floating-point model is supported by the Heterogeneous Line model conversion tool. The original floating-point model is obtained from the available model trained by DL frameworks such as TensorFlow/PyTorch. For specific floating-point model requirements and recommendations, please refer to the Floating-point Model Preparation section.
Model Verification This stage is used to verify whether the original floating-point model meets the requirements of the Heterogeneous Line algorithm toolchain. Heterogeneous Line provides the hb_mapper checker tool for checking floating-point models. For specific usage, please refer to the Model Verification section.
Model Conversion This stage is used to perform the conversion from the floating-point model to the Heterogeneous Line heterogeneous model. After this stage, you will obtain a model that can run on the Heterogeneous Line processor. Heterogeneous Line provides the hb_mapper makertbin conversion tool to complete key steps such as model optimization, quantization, and compilation. For specific usage, please refer to the Model Conversion section.
Performance Evaluation This stage is mainly used to evaluate the inference performance of the Heterogeneous Line heterogeneous model. Heterogeneous Line provides tools for model performance evaluation, which you can use to verify whether the model performance meets the application requirements. For specific usage instructions, please refer to the Model Performance Analysis and Tuning section.
Accuracy Evaluation This stage is mainly used to evaluate the inference accuracy of the Heterogeneous Line heterogeneous model. Heterogeneous Line provides tools for model accuracy evaluation. For specific usage instructions, please refer to the Model Accuracy Analysis and Tuning section.
Model Preparation
The floating-point model obtained from publicly available DL frameworks is the input for the Heterogeneous Line model conversion tool. Currently, the conversion tool supports the following DL frameworks:
| Framework | Caffe | PyTorch | TensorFlow | MXNet | PaddlePaddle |
|---|---|---|---|---|---|
| Heterogeneous Line Toolchain | Supported | Supported (via ONNX conversion) | Supported (via ONNX conversion) | Supported (via ONNX conversion) | Supported (via ONNX conversion) |
Among these frameworks, the caffemodel exported by the Caffe framework is directly supported. PyTorch, TensorFlow, MXNet, and other DL frameworks are indirectly supported through conversion to the ONNX format.
For the conversion from different frameworks to ONNX, there are currently corresponding standard solutions, as follows:
-
Pytorch2Onnx: PyTorch official API supports exporting models directly as ONNX models. Refer to the link: https://pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html
-
Tensorflow2Onnx: Conversion based on the onnx/tensorflow-onnx in the ONNX community. Refer to the link: https://github.com/onnx/tensorflow-onnx
-
MXNet2Onnx: MXNet official API supports exporting models directly as ONNX models. Refer to the link:https://github.com/dotnet/machinelearning/blob/main/test/Microsoft.ML.Tests/OnnxConversionTest.cs
-
More ONNX conversion support for other frameworks, please refer to the link: https://github.com/onnx/tutorials#converting-to-onnx-format
We also provide tutorials on how to export ONNX and visualize models for Pytorch, PaddlePaddle, and TensorFlow2 frameworks. Please refer to:
-
Operators used in floating-point models need to comply with the operator constraint conditions of the D-Robotics algorithm toolchain. Please refer to the Supported Operator List section for details.
-
Currently, the conversion tool only supports the conversion of models with output count less than or equal to 32.
-
Supports quantization of
caffe 1.0version floating-point models andir_version ≤ 7,opset=10,opset=11versions of ONNX floating-point models into fixed-point models supported by Horizon. For the mapping between the IR version of the ONNX model and the ONNX version, please refer to the ONNX official documentation. -
Model input dimensions only support
fixed 4 dimensionsinput NCHW or NHWC (N dimension can only be 1), for example: 1x3x224x224 or 1x224x224x3. Dynamic dimensions and non-4D inputs are not supported. -
Do not include
post-processing operatorsin floating-point models, such as NMS operators.
Model Validation
Before formally converting the model, please use the hb_mapper checker tool to validate the model and ensure that it complies with the constraints supported by the D-Robotics processor.
It is recommended to refer to the script methods 01_check_X3.sh or 01_check_Ultra.sh in the model conversion horizon_model_convert_sample example package of D-Robotics for examples of caffe, onnx, and other models.
Validate the model using the hb_mapper checker tool
The usage of the hb_mapper checker tool is as follows:
hb_mapper checker --model-type $`{`model_type`}` \
--march $`{`march`}` \
--proto $`{`proto`}` \
--model $`{`caffe_model/onnx_model`}` \
--input-shape $`{`input_node`}` $`{`input_shape`}` \
--output $`{`output`}`
hb_mapper checker parameters explanation:
--model-type
Specifies the model type of the input for checking, currently only supports setting caffe or onnx.
--march
Specifies the D-Robotics processor type to be adapted, can be set to bernoulli2 or bayes; set to bernoulli2 for RDK X3 and bayes for RDK Ultra.
--proto
This parameter is only useful when model-type is set to caffe, and its value is the prototxt file name of the Caffe model.
--model
When model-type is specified as caffe, its value is the caffemodel file name of the Caffe model.
When model-type is specified as onnx, its value is the name of the ONNX model file.
--input-shape
Optional parameter, explicitly specifies the input shape of the model.
Its value is {`input_name`}` `{`NxHxWxC/NxCxHxW`}, with a space between input_name and the shape.
For example, if the model input is named data1 and the input shape is [1,224,224,3],
then the configuration should be --input-shape data1 1x224x224x3.
If the configured shape here is inconsistent with the shape information inside the model, the shape configured here takes precedence.
Note that --input-shape only accepts one name-shape combination. If your model has multiple input nodes,
you can configure the --input-shape parameter multiple times in the command.
The --output parameter has been deprecated. The log information is stored in hb_mapper_checker.log by default.
Handling Exceptions in Checking
If the model checking step terminates abnormally or error messages are displayed, it means that the model verification fails. Please refer to the error information printed on the terminal or the hb_mapper_checker.log log file generated in the current path for error information and modification suggestions.
For example: The following configuration contains an unrecognized operator type Accuracy:
layer `{`
name: "data"
type: "Input"
top: "data"
input_param `{` shape: `{` dim: 1 dim: 3 dim: 224 dim: 224 `}` `}`
`}`
layer `{`
name: "Convolution1"
type: "Convolution"
bottom: "data"
top: "Convolution1"
convolution_param `{`
num_output: 128
bias_term: false
pad: 0
kernel_size: 1
group: 1
stride: 1
weight_filler `{`
type: "msra"
`}`
`}`
`}`
layer `{`
name: "accuracy"
type: "Accuracy"
bottom: "Convolution3"
top: "accuracy"
include `{`
phase: TEST
`}`
`}`
After using hb_mapper checker to check this model, you will get the following information in the hb_mapper_checker.log:
ValueError: Not support layer name=accuracy type=Accuracy
- If the model check step is terminated abnormally or there is an error message, it means that the model verification fails. Please confirm the error message and modification suggestions according to the terminal print or the generated
hb_mapper_checker.loglog file in the current path. You can find the solution to the error in the "Model Quantization Errors and Solutions" section. If the above steps still cannot resolve the problem, please contact the D-Robotics technical support team or submit your question in the D-Robotics Official Developer Community. We will provide support within 24 hours.
Interpretation of the check results
If there is no ERROR, then the check is successful. The hb_mapper checker tool will directly output the following information:
==============================================
Node ON Subgraph Type
----------
conv1 BPU id(0) HzSQuantizedConv
conv2_1/dw BPU id(0) HzSQuantizedConv
conv2_1/sep BPU id(0) HzSQuantizedConv
conv2_2/dw BPU id(0) HzSQuantizedConv
conv2_2/sep BPU id(0) HzSQuantizedConvconv3_1/dw BPU id(0) HzSQuantizedConv
conv3_1/sep BPU id(0) HzSQuantizedConv
...
The result of each line represents the checking status of a model node, with four columns: Node, ON, Subgraph, and Type. They represent the node name, the hardware on which the node is executed, the subgraph to which the node belongs, and the D-Robotics operator name to which the node is mapped. If the model contains CPU operators in the network structure, the hb_mapper checker tool will split the part before and after the CPU operator into two subgraphs.
Optimization Guide for Checking Results
Ideally, all operators in the model's network structure should run on the BPU, which means there is only one subgraph. If there are CPU operators causing multiple subgraphs to be split, the "hb_mapper checker" tool will provide the specific reasons for the appearance of the CPU operators. Below are examples of model verification on RDK X3 and RDK Ultra.
- The Caffe model running on "RDK X3" has a structure of Reshape + Pow + Reshape. According to the operator constraint list on "RDK X3", we can see that the Reshape operator is currently running on the CPU, and the shape of Pow is also non-4D, which does not meet the constraints of the X3 BPU operator.
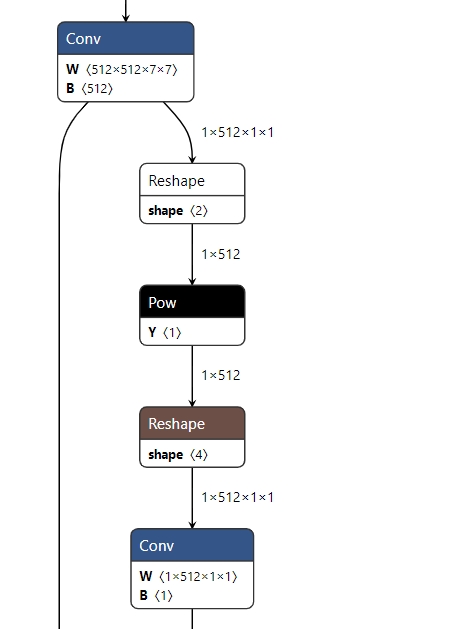
Therefore, the final checking result of the model will also show segmentation, as follows:
2022-05-25 15:16:14,667 INFO The converted model node information:
====================================================================================
Node ON Subgraph Type
-------------
conv68 BPU id(0) HzSQuantizedConv
sigmoid16 BPU id(0) HzLut
axpy_prod16 BPU id(0) HzSQuantizedMul
UNIT_CONV_FOR_eltwise_layer16_add_1 BPU id(0) HzSQuantizedConv
prelu49 BPU id(0) HzPRelu
fc1 BPU id(0) HzSQuantizedConv
fc1_reshape_0 CPU -- Reshape
fc_output/square CPU -- Pow
fc_output/sum_pre_reshape CPU -- Reshape
fc_output/sum BPU id(1) HzSQuantizedConv
fc_output/sum_reshape_0 CPU -- Reshape
fc_output/sqrt CPU -- Pow
fc_output/expand_pre_reshape CPU -- Reshape
fc_output/expand BPU id(2) HzSQuantizedConv
fc1_reshape_1 CPU -- Reshape
fc_output/expand_reshape_0 CPU -- Reshape
fc_output/op CPU -- Mul
- The ONNX model running on "RDK Ultra" has a structure of Mul + Add + Mul. According to the operator constraint list on "RDK Ultra", we can see that Mul and Add operators are supported on five dimensions for BPU execution, but they need to meet the constraints of the Ultra BPU operators; otherwise, they will fall back to CPU computation.
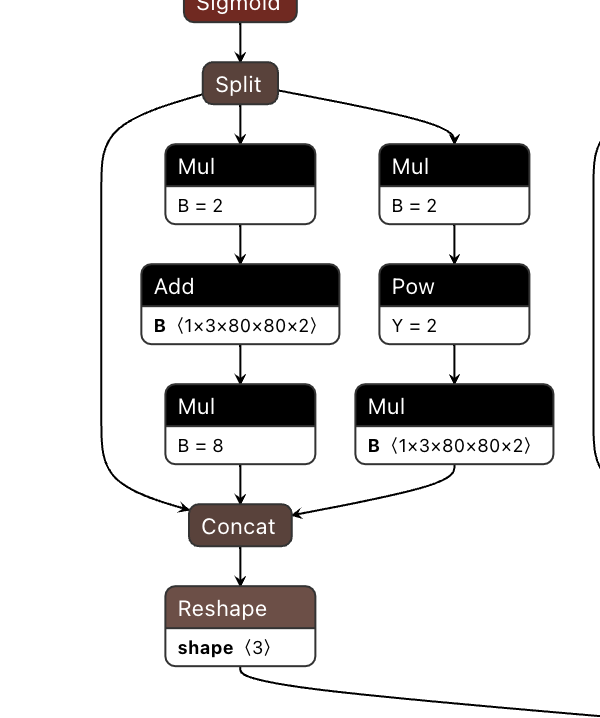
Therefore, the final checking result of the model will also show segmentation, as follows:
====================================================================================
Node ON Subgraph Type
-------------------------------------------------------------------------------------
Reshape_199 BPU id(0) Reshape
Transpose_200 BPU id(0) Transpose
Sigmoid_201 BPU id(0) HzLut
Split_202 BPU id(0) Split
Mul_204 CPU -- Mul
Add_206 CPU -- Add
Mul_208 CPU -- Mul
Mul_210 CPU -- Mul
Pow_211 BPU id(1) HzLut
Mul_213 CPU -- Mul
Concat_214 CPU -- Concat
Reshape_215 CPU -- Reshape
Conv_216 BPU id(0) HzSQuantizedConv
Reshape_217 BPU id(0) Reshape
Transpose_218 BPU id(0) Transpose
Sigmoid_219 BPU id(0) HzLut
Split_220 BPU id(0) Split
Mul_222 CPU -- Mul
Add_224 CPU -- Add
Mul_226 CPU -- Mul
Mul_228 CPU -- Mul
Pow_229 BPU id(2) HzLut
Mul_231 CPU -- Mul
Concat_232 CPU -- Concat
Reshape_233 CPU -- Reshape
Conv_234 BPU id(0) HzSQuantizedConv
Reshape_235 BPU id(0) Reshape
Transpose_236 BPU id(0) Transpose
Sigmoid_237 BPU id(0) HzLut
Split_238 BPU id(0) Split
Mul_240 CPU -- Mul
Add_242 CPU -- Add
Mul_244 CPU -- Mul
Mul_246 CPU -- Mul
Pow_247 BPU id(3) HzLut
Mul_249 CPU -- Mul
Concat_250 CPU -- Concat
Reshape_251 CPU -- Reshape
According to the hints provided by hb_mapper checker, generally, the operators running on BPU will have better performance. In this case, you can remove the CPU operators like pow and reshape from the model and calculate the corresponding functions in the post-processing to reduce the number of subgraphs.
However, multiple subgraphs will not affect the overall conversion process but will affect the performance of the model to a large extent. It is recommended to adjust the model operators to run on BPU as much as possible. You can refer to the BPU operator support list in the D-Robotics Processor Operator Support List to replace the CPU operators with BPU operators with the same functions or move the CPU operators in the model to the pre- and post-processing of the model for CPU calculations.
Model conversion
The model conversion phase will convert the floating-point model to a D-Robotics heterogeneous model, and after this phase, you will have a model that can run on the D-Robotics processor.
Before performing the conversion, please make sure that the validation model process has been successfully passed.
The model conversion is completed using the hb_mapper makertbin tool, during which important processes such as model optimization and calibration quantization will be performed. Calibration requires preparing calibration data according to the model preprocessing requirements.
In order to facilitate your comprehensive understanding of model conversion, this section will introduce calibration data preparation, conversion tool usage, conversion internal process interpretation, conversion result interpretation, and conversion output interpretation in order.
Preparing Calibration Data
During the model conversion, the calibration stage will require about 100 calibration input samples, and each sample is an independent data file. To ensure the accuracy of the converted model, we hope that these calibration samples come from the training set or validation set you used to train the model, and not use very rare abnormal samples, such as solid color images, images without any detection or classification objects, etc.
In the conversion configuration file, the "preprocess_on" parameter corresponds to two different preprocessing sample requirements under the enabled and disabled states, respectively. (For detailed configuration of parameters, please refer to the relevant instructions in the calibration parameter group below)
When "preprocess_on" is disabled, you need to perform the same preprocessing of the samples taken from the training set/validation set as the model inference before the calibration. The calibrated samples after processing will have the same data type ("input_type_train"), size ("input_shape"), and layout ("input_layout_train") as the original model.
For models with featuremap inputs, you can use the "numpy.tofile" command to save the data as a float32 format binary file. The tool chain will read it based on the "numpy.fromfile" command during calibration.
For example, for the original floating-point model trained using ImageNet for classification, which has only one input node, the input information is described as follows:
- Input type: BGR
- Input layout: NCHW
- Input size: 1x3x224x224
The data preprocessing for model inference using the validation set is as follows:
- Scale the image to maintain the aspect ratio, with the shorter side scaled to 256.
- Use the "center_crop" method to obtain a 224x224 size image.
- Subtract the mean by channel.
- Multiply the data by a scale factor.
The sample processing code for the example model mentioned above is as follows:
To avoid excessive code length, the implementation code of various simple transformers is not included. For specific usage, please refer to the chapter "Transformer Usage" in the Toolchain section.
It is recommended to refer to the preprocessing steps of the sample models in the D-Robotics model conversion "horizon_model_convert_sample" sample package, such as caffe and onnx models: "02_preprocess.sh" and "preprocess.py".
# This example uses skimage, there may be differences if using opencv
# It is worth noting that the transformers do not reflect the mean subtraction and scale multiplication operations
# The mean and scale operations have been integrated into the model, please refer to the norm_type/mean_value/scale_value configuration below
def data_transformer():
transformers = [
# Scale the long side and short side to maintain the aspect ratio, with the shorter side scaled to 256
ShortSideResizeTransformer(short_size=256),
# Use CenterCrop to obtain a 224x224 image
CenterCropTransformer(crop_size=224),
# Convert NHWC layout from skimage to NCHW layout required by the model
HWC2CHWTransformer(),
# Convert channel order from RGB to BGR required by the model
RGB2BGRTransformer(),
# Adjust the value range from [0.0, 1.0] to the value range required by the model
ScaleTransformer(scale_value=255)
]
return transformers
# src_image represents the original image in the calibration set
# dst_file represents the file name for storing the final calibration sample data
def convert_image(src_image, dst_file, transformers):
image = skimage.img_as_float(skimage.io.imread(src_file))
for trans in transformers:
image = trans(image)
# The input_type_train specified by the model is UINT8 for BGR value type
image = image.astype(np.uint8)
# Store the calibration sample data in binary format to the data file
image.tofile(dst_file)
if __name__ == '__main__':
# The following represents the original calibration image set (pseudo code)
src_images = ['ILSVRC2012_val_00000001.JPEG', ...]
# The following represents the final calibration file name (no restrictions on the file extension) (pseudo code)
# calibration_data_bgr_f32 is cal_data_dir specified in your configuration file
dst_files = ['./calibration_data_bgr_f32/ILSVRC2012_val_00000001.bgr', ...]
transformers = data_transformer()
for src_image, dst_file in zip(src_images, dst_files):
convert_image(src_image, dst_file, transformers)
When preprocess_on is enabled, the calibration samples can be in any image format supported by skimage. The conversion tool will resize these images to the size required by the input node of the model, and use the result as the input for calibration. This operation is simple but does not guarantee the accuracy of quantization, so we strongly recommend that you use the method of disabling preprocess_on.
Please note that the input_shape parameter in the YAML file specifies the input data size of the original float model. If it is a dynamic input model, you can set the input size after conversion using this parameter, and the size of the calibration data should be the same as input_shape.
For example: If the shape of the input node of the original float model is ?x3x224x224 (where "?" indicates a placeholder, i.e., the first dimension of the model is a dynamic input), and the input_shape in the conversion configuration file is set to 8x3x224x224, then the size of each calibration data that the user needs to prepare is 8x3x224x224. (Note that models with input shapes where the first dimension is not 1 do not support modifying the model batch information through the input_batch parameter.)
Convert the Model Using the hb_mapper makertbin Tool
hb_mapper makertbin provides two modes, with and without the fast-perf mode enabled.When the "fast-perf" mode is enabled, it will generate a bin model that can run at the highest performance on the board during the conversion process. The tool mainly performs the following operations:
-
Run BPU executable operators on the BPU as much as possible (if using "RDK Ultra", you can specify the operators running on the BPU through the node_info parameter in the yaml file. "RDK X3" is automatically optimized and cannot specify operators through the yaml configuration file).
-
Delete CPU operators at the beginning and end of the model that cannot be deleted, including: Quantize/Dequantize, Transpose, Cast, Reshape, etc.
-
Compile the model with the highest performance optimization level O3.
It is recommended to refer to the script methods of the example models in the D-Robotics Model Conversion "horizon_model_convert_sample" package, such as caffe and onnx example models: "03_build_X3.sh" or "03_build_Ultra.sh".
The usage of the hb_mapper makertbin command is as follows:
Without enabling the "fast-perf" mode:
hb_mapper makertbin --config ${config_file} \
--model-type ${model_type}
With the "fast-perf" mode enabled:
hb_mapper makertbin --fast-perf --model ${caffe_model/onnx_model`}` --model-type $`{`model_type`}` \
--proto ${caffe_proto} \
--march ${march}
Explanation of hb_mapper makertbin parameters:
--help
Display help information and exit.
-c, --config
The configuration file for model compilation, in yaml format. The file name uses the .yaml suffix. The complete configuration file template is as follows.
--model-type
Used to specify the model type for conversion input, currently supports setting "caffe" or "onnx".
--fast-perf
Enable the fast-perf mode. After enabling this mode, it will generate a bin model that can run at the highest performance on the board during the conversion process, making it convenient for you to evaluate the model's performance.
If you enable the fast-perf mode, you also need to configure the following:
--model
Caffe or ONNX floating-point model file.--proto
Used to specify the prototxt file of the Caffe model.
--march Microarchitecture of BPU. Set it to "bernoulli2" if using "RDK X3", and set it to "bayes" if using "RDK Ultra".
-
For "RDK X3 yaml configuration file", fill in the template file RDK X3 Caffe model quantization yaml template or RDK X3 ONNX model quantization yaml template directly.
-
For "RDK Ultra yaml configuration file", fill in the template file RDK Ultra Caffe model quantization yaml template or RDK Ultra ONNX model quantization yaml template directly.
-
If the hb_mapper makertbin step terminates abnormally or shows an error message, it means that the model conversion has failed. Please check the error message and modification suggestions in the terminal printout or in the
hb_mapper_makertbin.loglog file generated in the current path. You can find the solution for the error in the Model Quantization Errors and Solutions section. If the problem cannot be solved after these steps, please contact the D-Robotics technical support team or submit your question in the D-Robotics Official Technical Community. We will provide support within 24 hours.
Explanation of Parameters in Model Conversion YAML Configuration
Either a Caffe model or an ONNX model can be used, that is, either caffe_model + prototxt or onnx_model can be chosen.
In other words, either a Caffe model or an ONNX model can be used.
# Model parameter group
model_parameters:
# Original Caffe floating-point model description file
prototxt: '***.prototxt'
# Original Caffe floating-point model data model file
caffe_model: '****.caffemodel'
# Original ONNX floating-point model file
onnx_model: '****.onnx'
# Target processor architecture for conversion, keep the default value, bernoulli2 for D-Robotics RDK X3 and bayes for RDK Ultra
march: 'bernoulli2'
# Prefix of the model file for execution on the board after conversion
output_model_file_prefix: 'mobilenetv1'
# Directory for storing the output of the model conversion
working_dir: './model_output_dir'
# Specify whether the converted hybrid heterogeneous model retains the ability to output intermediate results of each layer, keep the default value
layer_out_dump: False
# Specify the output nodes of the model
output_nodes: `{`OP_name`}`
# Batch deletion of nodes of a certain typeremove_node_type: Dequantize
# Remove specified node by name
remove_node_name: `{`OP_name`}`
# Input parameters group
input_parameters:
# Name of the input node in the original floating-point model
input_name: "data"
# Data format of the input to the original floating-point model (same number and order as input_name)
input_type_train: 'bgr'
# Data layout of the input to the original floating-point model (same number and order as input_name)
input_layout_train: 'NCHW'
# Shape of the input to the original floating-point model
input_shape: '1x3x224x224'
# Batch size given to the network during execution, default value is 1
input_batch: 1
# Pre-processing method applied to the input data in the model
norm_type: 'data_mean_and_scale'
# Mean value subtracted from the image in the pre-processing method, if channel means, values must be separated by spaces
mean_value: '103.94 116.78 123.68'
# Scale value applied to the image in the pre-processing method, if channel scales, values must be separated by spaces
scale_value: '0.017'
# Data format that the transformed hybrid heterogeneous model needs to adapt to (same number and order as input_name)
input_type_rt: 'yuv444'
# Special format of the input data
input_space_and_range: 'regular'
# Data layout that the transformed hybrid heterogeneous model needs to adapt to (same number and order as input_name), not required if input_type_rt is nv12
input_layout_rt: 'NHWC'
# Calibration parameters group
calibration_parameters:
# Directory where the calibration samples for model calibration are stored
cal_data_dir: './calibration_data'
# Data storage type of the binary files for calibration data
cal_data_type: 'float32'
# Enable automatic processing of calibration image samples (using skimage read and resize to input node size)
#preprocess_on: False# Algorithm type for calibration, with default calibration algorithm as the first priority
calibration_type: 'default'
# Parameters for max calibration mode
# max_percentile: 1.0
# Force the OP to run on CPU, generally not needed, can be enabled during model accuracy tuning phase for precision optimization
# run_on_cpu: {OP_name}
# Force the OP to run on BPU, generally not needed, can be enabled during model performance tuning phase for performance optimization
# run_on_bpu: {OP_name}
# Specify whether to calibrate for each channel
# per_channel: False
# Specify the data precision for output nodes
# optimization: set_model_output_int8
# Compiler parameter group
compiler_parameters:
# Compilation strategy selection
compile_mode: 'latency'
# Whether to enable debug information for compilation, keep the default False
debug: False
# Number of cores for model execution
core_num: 1
# Optimization level for model compilation, keep the default O3
optimize_level: 'O3'
# Specify the input data source as 'pyramid' for the input named 'data'
#input_source: {"data": "pyramid"}
# Specify the maximum continuous execution time for each function call in the model
#max_time_per_fc: 1000
# Specify the number of processes during model compilation
#jobs: 8
# This parameter group does not need to be configured, only enabled when there are custom CPU operators
#custom_op:
# Calibration method for custom OP, recommend using registration method
#custom_op_method: register
# Implementation files for custom OP, multiple files can be separated with ";", this file can be generated from a template, see the custom OP documentation for details
#op_register_files: sample_custom.py# The folder where the custom OP implementation file is located, please use a relative path
#custom_op_dir: ./custom_op
The configuration file mainly includes four parameter groups: model parameter group, input information parameter group, calibration parameter group, and compilation parameter group.
In your configuration file, all four parameter groups need to exist, and specific parameters can be optional or mandatory. Optional parameters can be omitted.
The specific format for setting parameters is: param_name: 'param_value' ;
If there are multiple values for a parameter, separate each value with the ';' symbol: param_name: 'param_value1; param_value2; param_value3' ;
For specific configuration methods, please refer to: run_on_cpu: 'conv_0; conv_1; conv12' .
- When the model is a multi-input model, it is recommended to explicitly specify optional parameters such as
input_nameandinput_shapeto avoid errors in parameter correspondence order. - When configuring the
marchas bayes, which means performing RDK Ultra model conversion, if you configure the optimization leveloptimize_levelas O3, hb_mapper makerbin will automatically provide caching capabilities. That is, when you use hb_mapper makerbin to compile the model for the first time, it will automatically create a cache file. In subsequent compilations with the same working directory, this file will be automatically called, reducing your compilation time.
- Please note that if you set
input_type_rttonv12oryuv444, the input size of the model cannot have odd numbers. - Please note that currently RDK X3 does not support the combination of
input_type_rtasyuv444andinput_layout_rtasNCHW. - After the model conversion is successful, if an OP that meets the constraints of BPU operators still runs on the CPU, the main reason is that the OP belongs to the passive quantization OP. For information about passive quantization, please read the section Active and Passive Quantization Logic in the Algorithm Toolchain.
The following is a description of the specific parameter information. There will be many parameters, and we will introduce them in the order of the parameter groups mentioned above.
-
Model Parameter Group
| Parameter Name | Description | Value Range | Optional/Required |
|---|---|---|---|
prototxt | Purpose: Specifies the filename of the Caffe float model prototxt file. Description: Mandatory for hb_mapper makertbin with model-type set to caffe. | N/A | Optional |
caffe_model | Purpose: Specifies the filename of the Caffe float model caffemodel file. Description: Mandatory for hb_mapper makertbin with model-type set to caffe. | N/A | Optional |
onnx_model | Purpose: Specifies the filename of the ONNX float model onnx file. Description: Mandatory for hb_mapper makertbin with model-type set to onnx. | N/A | Optional |
march | Purpose: Specifies the platform architecture supported by the mixed-heterogeneous model to be produced. Description: Two available options correspond to the BPU micro-framework for RDK X3 and RDK Ultra. Choose based on your platform. | bernoulli2 or bayes | Required |
output_model_file_prefix | Purpose: Specifies the prefix for the converted mixed-heterogeneous model's output file name. Description: Prefix for the output integer model file name. | N/A | Required |
working_dir | Purpose: Specifies the directory where the model conversion output will be stored. Description: If the directory does not exist, the tool will automatically create it. | N/A | Optional (default: model_output) |
layer_out_dump | Purpose: Enables the ability to retain intermediate layer values in the mixed-heterogeneous model. Description: Intermediate layer values are used for debugging purposes. Disable this in normal scenarios. | True or False | Optional (default: False) |
output_nodes | Purpose: Specifies the model's output nodes. Description: Generally, the conversion tool automatically identifies the model's output nodes. This parameter is used to support specifying some intermediate layers as outputs. Provide specific node names, following the same format as the param_value description. Note that setting this parameter prevents the tool from automatically detecting outputs; the nodes you specify become the entire output. | N/A | Optional |
remove_node_type | Purpose: Sets the type of nodes to remove. Description: Hidden parameter, not setting or leaving blank won't affect the model conversion process. This parameter is used to support specifying node types to delete. Removed nodes must appear at the beginning or end of the model, connected to inputs or outputs. Caution: Nodes will be deleted in order, dynamically updating the model structure. The tool checks if a node is at an input or output before deletion. Order matters. | "Quantize", "Transpose", "Dequantize", "Cast", "Reshape". Separate by ";". | Optional |
remove_node_name | Purpose: Sets the name of nodes to remove. Description: Hidden parameter, not setting or leaving blank won't affect the model conversion process. This parameter is used to support specifying node names to delete. Removed nodes must appear at the beginning or end of the model, connected to inputs or outputs. Caution: Nodes will be deleted in order, dynamically updating the model structure. The tool checks if a node is at an input or output before deletion. Order matters. | N/A | Optional |
set_node_data_type | Purpose: Configures the output data type of a specific op as int16, only supported for RDK Ultra configuration! Description: In the model conversion process, most ops default to int8 for input and output data types. This parameter allows you to specify the output data type of a specific op as int16 under certain constraints. See the int16 configuration details for more information. Note: This functionality has been merged into the node_info parameter, which will be deprecated in future versions. | Supported operators listed in the model operator support list for RDK Ultra. | Optional |
debug_mode | Purpose: Saves calibration data for precision debugging analysis. Description: This parameter saves calibration data for precision debugging analysis in .npy format. This data can be directly loaded into the model for inference. If not set, you can save the data yourself and use the precision debugging tool for analysis. | "dump_calibration_data" | Optional |
node_info | Purpose: Supports configuring the input and output data types of specific ops as int16, and forces certain ops to run on CPU or BPU. Only supported for RDK Ultra configuration! Description: To reduce YAML parameters, we've combined the capabilities of set_node_data_type, run_on_cpu, and run_on_bpu into this parameter and expanded it to support configuring the input data type of specific ops as int16.Usage of node_info:- Run an op on BPU/CPU (example with BPU): node_info: {"node_name": {"ON": "BPU", }}- Run an op on BPU and configure its input and output data types: node_info: {"node_name": {"ON": "BPU", "InputType": "int16", "OutputType": "int16" }}- Run on multiple operators: node_info: {"/model.0/conv/Conv": {"ON": "BPU","InputType": "int16","OutputType": "int16"},"/model.0/act/Mul": {"ON": "BPU","InputType": "int16","OutputType": "int16"},"/model.2/Concat": {"ON": "BPU","InputType": "int16","OutputType": "int16"}}* InputType: 'int16' applies to all inputs. For specifying a particular input's data type, append a number, e.g., 'InputType0': 'int16' for the first input, 'InputType1': 'int16' for the second input.* OutputType doesn't support specifying a particular output, applying to all outputs. It doesn't support individual types like OutputType0 or OutputType1.Value Range: Refer to the model operator support list for RDK Ultra for supported int16 ops and those that can run on CPU or BPU. Default Configuration: None | Optional |
-
Input Parameters Group
| Parameter Name | Description | Value Range | Optional/Required |
|---|---|---|---|
input_name | Purpose: Specifies the input node name of the original floating-point model. Description: Not required when the floating-point model has only one input node. Must be configured for models with multiple input nodes to ensure accurate order of type and calibration data inputs. Multiple values can be set as described for param_value. | N/A | Optional |
input_type_train | Purpose: Specifies the input data type of the original floating-point model. Description: Each input node must have a configured data type. For models with multiple input nodes, the order should match that in input_name. Multiple values can be set as described for param_value. Data types available: refer to the explanation in the "Conversion Internal Process" section. | Values: rgb, bgr, yuv444, gray, featuremap | Required |
input_layout_train | Purpose: Specifies the input data layout of the original floating-point model. Description: Each input node requires a specific layout, which must match the model's original layout. Order should align with input_name. Multiple values can be set as described for param_value. Learn more about layouts in the "Conversion Internal Process" section. | Values: NHWC, NCHW | Required |
input_type_rt | Purpose: The input format needed for the converted heterogeneous model. Description: Specifies the desired input format, not necessarily matching the original model's format, but important for the platform to feed data into the model. One type per input node, with order matching input_name. Multiple values can be set as described for param_value. Data types available: refer to the explanation in the "Conversion Internal Process" section. | Values: rgb, bgr, yuv444, nv12, gray, featuremap | Required |
input_layout_rt | Purpose: The input data layout for the converted heterogeneous model. Description: Specifies the desired input layout for each node, which can differ from the original model. For NV12 input_type_rt, this parameter is unnecessary. Order should match input_name. Multiple values can be set as described for param_value. Learn more about layouts in the "Conversion Internal Process" section. | Values: NCHW, NHWC | Optional (if input_type_rt is NV12) |
input_space_and_range | Purpose: Specifies the special format of input data, particularly for ISP outputs in yuv420 format. Description: Used for adapting to different ISP formats, valid only if input_type_rt is set to nv12. Choices: regular for common yuv420, bt601_video for another video standard. Keep as regular unless specifically needed. | Values: regular, bt601_video | Optional |
input_shape | Purpose: Specifies the dimensions of the input data for the original floating-point model. Description: Dimensions should be separated by x, e.g., 1x3x224x224. Can be omitted for single-input models with the tool automatically reading size information from the model file. Order should match input_name. Multiple values can be set as described for param_value. | N/A | Optional |
input_batch | Purpose: The number of batches for the converted heterogeneous model to adapt to. Description: The batch size for the converted heterogeneous bin model, not affecting the ONNX model's batch size. Defaults to 1 if not specified. Only applicable for single-input models where the first dimension of input_shape is 1. | Range: 1-128 | Optional |
norm_type | Purpose: The preprocessing method added to the model's input data. Description: no_preprocess means no preprocessing; data_mean for mean subtraction; data_scale for scaling; data_mean_and_scale for both mean subtraction and scaling. Must be consistent with the order of input_name. Multiple values can be set as described for param_value. See the "Conversion Internal Process" section for impact. | Values: data_mean_and_scale, data_mean, data_scale, no_preprocess | Required |
mean_value | Purpose: The image mean value for the preprocessing method. Description: Required if norm_type includes data_mean_and_scale or data_mean. Two configuration options: a single value for all channels or channel-specific values (separated by spaces). Channel count should match norm_type nodes. Set to 'None' for nodes without mean processing. Multiple values can be set as described for param_value. | N/A | Optional |
scale_value | Purpose: The scale coefficient for the preprocessing method. Description: Required if norm_type includes data_mean_and_scale or data_scale. Similar to mean_value, two configurations are allowed: a single value for all channels or channel-specific values (separated by spaces). Channel count should match norm_type nodes. Set to 'None' for nodes without scale processing. Multiple values can be set as described for param_value. | N/A | Optional |
-
Calibration Parameter Group
| Parameter Name | Description | Value Range | Optional/Required |
|---|---|---|---|
cal_data_dir | Specifies the directory containing calibration samples for model calibration. Description: The data in this directory should adhere to the input configuration requirements. Please refer to the section on Preparing Calibration Data for more details. When configuring multiple input nodes, the order of the specified nodes must strictly match that in input_name. Multiple value configurations can be done as described earlier for param_value. For calibration_type of load, skip, this parameter is not needed. Note: To facilitate your use, if no cal_data_type configuration is found, we will infer the data type based on the file extension. If the file extension ends with _f32, it will be considered float32; otherwise, uint8. However, we strongly recommend constraining the data type using the cal_data_type parameter. | N/A | Optional |
cal_data_type | Specifies the binary file data storage type for calibration data. Description: The data storage type used by the model during calibration. If not specified, the tool will determine the type based on the file name suffix. | float32, uint8 | Optional |
preprocess_on | Enables automatic preprocessing of image calibration samples. Description: This option is only applicable to models with 4D image inputs. Do not enable this for non-4D models. When enabled, the tool reads jpg/bmp/png files in the cal_data_dir and resizes them to the required dimensions for input nodes. It is recommended to keep this parameter disabled to ensure calibration accuracy. Refer to the Preparing Calibration Data section for more information on its impact. | True, False | Optional |
calibration_type | Calibration algorithm type to use. Description: Both kl and max are public calibration quantization algorithms, whose basic principles can be found in online resources. When using load, the QAT model must be exported using a plugin. mix is an integrated search strategy that automatically determines sensitive quantization nodes and selects the best method at the node granularity, ultimately constructing a calibration combination that leverages the advantages of multiple methods. default is an automated search strategy that attempts to find a relatively better combination of calibration parameters from a series. We suggest starting with default. If the final accuracy does not meet expectations, refer to the Precision Tuning section for suggested parameter adjustments. If you just want to verify the model performance without accuracy requirements, try the skip mode, which uses random numbers for calibration and does not require calibration data, suitable for initial model structure validation. Note: Using the skip mode results in models calibrated with random numbers, which are not suitable for accuracy validation. | default, mix, kl, max, load, skip | Required |
max_percentile | Parameter for the max calibration method, used to adjust the cutoff point for max calibration.Description: Only valid when calibration_type is set to max. Common options include: 0.99999/0.99995/0.99990/0.99950/0.99900. Start with calibration_type set to default, and adjust this parameter if the final accuracy is unsatisfactory, as advised in the Precision Tuning section. | 0.0 - 1.0 | Optional |
per_channel | Controls whether to calibrate each channel individually within a featuremap. Description: Effective when calibration_type is not set to default. Start with default and adjust this parameter if necessary, as suggested in the Precision Tuning section. | True, False | Optional |
run_on_cpu | Forces operators to run on CPU. Description: Although CPU performance is inferior to BPU, it provides float precision calculations. Specify this parameter if you're certain that some operators need to run on CPU. Set values to specific node names in your model, following the same configuration method as described earlier for param_value. Note: In RDK Ultra, this parameter functionality has been merged into the node_info parameter and is planned to be deprecated in future versions. It continues to be available in RDK X3. | N/A | Optional |
run_on_bpu | Forces an operator to run on BPU. Description: To maintain the accuracy of the quantized model, occasionally, the conversion tool may place some operators that can run on BPU on CPU. If you have higher performance requirements and are willing to accept slightly more quantization loss, you can explicitly specify that an operator runs on BPU. Set values to specific node names in your model, following the same configuration method as described earlier for param_value. Note: In RDK Ultra, this parameter functionality has been merged into the node_info parameter and is planned to be deprecated in future versions. It continues to be available in RDK X3. | N/A | Optional |
optimization | Sets the model output format to int8 or int16. Description: If set to set_model_output_int8, the model will output in low-precision int8 format; if set to set_model_output_int16, the model will output in low-precision int16 format. Note: RDK X3 only supports set_model_output_int8, while RDK Ultra supports both set_model_output_int8 and set_model_output_int16. | set_model_output_int8, set_model_output_int16 | Optional |
-
Compiler Parameters
| Parameter Name | Description | Value Range | Optional/Required |
|---|---|---|---|
compile_mode | Purpose: Select the compilation strategy. Description: Choose between latency for inference time optimization or bandwidth for DDR access bandwidth optimization. For models without significant bandwidth exceedance, use the latency strategy is recommended. | Value Range: latency, bandwidth.Default: latency. | Required |
debug | Purpose: Enable debug information in the compilation process. Description: Enabling this parameter saves performance analysis results in the model, allowing you to view layer-wise BPU operator performance (including compute, compute time, and data movement time) in the generated static performance assessment files. It is recommended to keep it disabled by default. | Value Range: True, False.Default: False. | Optional |
core_num | Purpose: Number of cores for model execution. Description: D-Robotics Platform supports using multiple AI accelerator cores simultaneously for inference tasks. Multiple cores are beneficial for larger input sizes, with double-core speed typically around 1.5 times that of single-core. If your model has large inputs and追求极致速度, set core_num=2. Note: This option is not supported for RDK Ultra, please do not configure. | Value Range: 1, 2.Default: 1. | Optional |
optimize_level | Purpose: Model compilation optimization level. Description: The optimization levels range from O0 (no optimization, fastest compile) to O3 (higher optimization, slower compile). Normal performance models should use O3 for optimal performance. Lower levels can be used for faster development or debugging processes. | Value Range: O0, O1, O2, O3.Default: None. | Required |
input_source | Purpose: Set the source of input data for the on-board bin model. Description: This parameter is for engineering environment compatibility. Configure after model validation. Options include ddr (memory), pyramid, and resizer. Note: If set to resizer, the model's h*w should be less than 18432. In an engineering environment, adapting pyramid and resizer sources requires specific configuration, e.g., if the model input name is data and the source is memory (ddr), set as {`"data": "ddr"`}. | Value Range: ddr, pyramid, resizerDefault: None (auto-selected based on input_type_rt). | Optional |
max_time_per_fc | Purpose: Maximum continuous execution time per function call (in us). Description: In the compiled data instruction model, each inference on BPU is represented by one or more function calls (BPU execution granularity). A value of 0 means no limit. This parameter limits the max execution time per function call, allowing the model to be interrupted if necessary. See the section on Model Priority Control for details. - This parameter is for implementing model preemption; ignore if not needed. - Model preemption is only supported on development boards, not PC simulators. | Value Range: 0 or 1000-4294967295.Default: 0. | Optional |
jobs | Purpose: Number of processes for compiling the bin model. Description: Sets the number of processes during bin model compilation, potentially improving compile speed. | Value Range: Up to the maximum number of supported cores on the machine. Default: None. | Optional |
-
Custom Operator Parameter Group
| Parameter Name | Description of Configuration | Range of Values | Optional/Mandatory |
|---|---|---|---|
custom_op_method | Purpose: Select strategy for custom operator. Description: Currently, only the 'register' strategy is supported. | Range: register.Default: None. | Optional |
op_register_files | Purpose: Names of Python files implementing the custom operator(s). Description: Multiple files can be separated by ;. | Range: None. Default: None. | Optional |
custom_op_dir | Purpose: Path to the directory containing the Python files for the custom operator(s). Description: Please use relative path when setting the path. | Range: None. Default: None. | Optional |
RDK Ultra int16 Configuration Instructions
In the process of model conversion, most operators in the model will be quantized to int8 for computation. By configuring the "node_info" parameter, you can specify in detail that the input/output data type of a specific op is int16 for computation (the specific supported operator range can be referred to the RDK Ultra operator support list in the "Supported Operator List" chapter). The basic principle is as follows:
After you configure the input/output data type of a certain op as int16, the model conversion will automatically update and check the int16 configuration of the op's input/output context. For example, when configuring the input/output data type of op_1 as int16, it actually implicitly specifies that the previous/next op of op_1 needs to support int16 computation. For unsupported scenarios, the model conversion tool will print a log to indicate that the int16 configuration combination is temporarily unsupported and will fallback to int8 computation.
Pre-processing HzPreprocess Operator Instructions
The pre-processing HzPreprocess operator is a pre-processing operator node inserted after the model input node during the model conversion process of D-Robotics Model Conversion Tool. It is used to normalize the input data of the model. This section mainly introduces the parameters "norm_type", "mean_value", "scale_value", and the explanation of the HzPreprocess operator node generated by the model pre-processing.
norm_type Parameter Explanation
-
Parameter Function: This parameter is used to add the input data pre-processing method to the model.
-
Parameter Value Range and Explanation:
- "no_preprocess" indicates no data pre-processing is added.
- "data_mean" indicates subtraction of mean value pre-processing.is provided.
- "data_scale" indicates multiplication by scale factor pre-processing.
- "data_mean_and_scale" indicates subtraction of mean value followed by multiplication by scale factor pre-processing.
When there are multiple input nodes, the order of the set nodes must strictly match the order in "input_name".
mean_value Parameter Explanation
-
Parameter Function: This parameter represents the mean value subtracted from the image for the specified pre-processing method.
-
Usage: This parameter needs to be configured when "norm_type" is set to "data_mean_and_scale" or "data_mean".
-
Parameter Explanation:
- When there is only one input node, only one value needs to be configured, indicating that all channels will subtract this mean value.
- When there are multiple nodes, provide values that match the number of channels (these values are separated by spaces), indicating that each channel will subtract a different mean value.
- The number of configured input nodes must match the number of nodes configured in "norm_type".
- If there is a node that does not require mean processing, configure it as "None".
scale_value Parameter Explanation
-
Parameter Function: This parameter represents the scale factor for the specified pre-processing method.
-
Usage: This parameter needs to be configured when "norm_type" is set to "data_mean_and_scale" or "data_scale".- Parameter description:
- When there is only one input node, only one value needs to be configured, which represents the scaling factor for all channels.
- When there are multiple nodes, provide the same number of values as the number of channels (these values are separated by spaces), which represents different scaling factors for each channel.
- The number of configured input nodes must be consistent with the number of nodes configured for
norm_type. - If there is a node that does not require
scaleprocessing, configure it as'None'.
Formula and example explanation
- Formula for data normalization during model training
The mean and scale parameters in the YAML file need to be calculated based on the mean and std during training.
The calculation formula for data normalization in the preprocessing node (i.e. in the HzPreprocess node) is norm_data = (data - mean) * scale.
Taking yolov3 as an example, the preprocessing code during training is as follows:
def base_transform(image, size, mean, std):
x = cv2.resize(image, (size, size).astype(np.float32))
x /= 255
x -= mean
x /= std
return x
class BaseTransform:
def __init__(self, size, mean=(0.406, 0.456, 0.485), std=(0.225, 0.224, 0.229)):
self.size = size
self.mean = np.array(mean, dtype=np.float32)
self.std = np.array(std, dtype=np.float32)
The formula becomes: norm_data = (\fracdata{`255`}` - mean) * \frac`{`1`}std``,
Rewritten as the calculation method in the HzPreprocess node: norm_data = (\fracdata{`255`}` - mean) * \frac`{`1`}std = (data - 255mean) * \frac1{`255std`},
Therefore: mean_yaml = 255 mean, scale_yaml = \frac1{`255std`}.
- Formula during model inference
By configuring the parameters in the YAML configuration file, whether to add the HzPreprocess node is determined. When configuring mean/scale, when performing model conversion, a HzPreprocess node will be added to the input, which can be understood as performing a convolution operation on the input data.
The calculation formula in the HzPreprocess node is: ((input (range [-128,127]) + 128) - mean) * scale, where weight = scale, bias = (128 - mean) * scale.
- After adding mean/scale in the YAML, there is no need to include MeanTransformer and ScaleTransformer in the preprocessing.
- Adding mean/scale in the YAML will place the parameters within the HzPreprocess node, which is a BPU (Base Processing Unit) node.
Conversion Internal Process Interpretation
During the model conversion stage, the floating-point model is transformed into the D-Robotics mixed heterogeneous model. In order to efficiently run this heterogeneous model on embedded devices, the model conversion focuses on solving two key issues: input data processing and model optimization compilation. This section will discuss these two key issues in detail.
Input Data Processing: The D-Robotics X3 processor provides hardware-level support for certain types of model input pathways. For example, in the case of the video pathway, the video processing subsystem provides functions such as image cropping, scaling, and other image quality optimization for image acquisition. The output of these subsystems is in the YUV420 NV12 format, while the algorithm models are typically trained on more common image formats such as BGR/RGB.
D-Robotics provides the following solutions for this situation:
-
Each converted model provides two types of descriptions: one for describing the input data of the original floating-point model (
input_type_trainandinput_layout_train), and the other for describing the input data of the processor we need to interface with (input_type_rtandinput_layout_rt). -
Mean/scale operations on image data are also common, but these operations are not suitable for the data formats supported by processors such as YUV420 NV12. Therefore, we have embedded these common image preprocessing operations into the model.
After processing through the above two methods, the input part of the heterogeneous model ***.bin generated during the model conversion stage will look like the following:

The data layouts shown in the above figure include NCHW and NHWC, where N represents the number, C represents the channel, H represents the height, and W represents the width. The two different layouts reflect different memory access characteristics. NHWC is more commonly used in TensorFlow models, while NCHW is used in Caffe. The D-Robotics processor does not restrict the use of data layouts, but there are two requirements: first, input_layout_train must be consistent with the data layout of the original model; second, prepare the data with the data layout consistent with input_layout_rt on the processor, as the correct data layout is the basis for successful data parsing.
The model conversion tool will automatically add data conversion nodes based on the data formats specified by input_type_rt and input_type_train. According to D-Robotics's actual usage experience, not all possible type combinations are needed. To prevent misuse, we only provide a few fixed type combinations, as shown in the table below:
input_type_train \ input_type_rt | nv12 | yuv444 | rgb | bgr | gray | featuremap |
|---|---|---|---|---|---|---|
| yuv444 | Y | Y | N | N | N | N |
| rgb | Y | Y | Y | Y | N | N |
| bgr | Y | Y | Y | Y | N | N |
| gray | N | N | N | N | Y | N |
| featuremap | N | N | N | N | N | Y |
The first row in the table represents the types supported by input_type_rt, and the first column represents the types supported by input_type_train. The Y/N indicates whether the conversion from input_type_rt to input_type_train is supported. In the final produced bin model after model conversion, the conversion from input_type_rt to input_type_train is an internal process, so you only need to pay attention to the data format of input_type_rt. Understanding the requirements of each input_type_rt is important for preparing inference data for embedded applications. The following are explanations of each format of input_type_rt:
-
RGB, BGR, and gray are common image formats, and each value is represented by UINT8.
-
YUV444 is a common image format, and each value is represented by UINT8.
-
NV12 is a common YUV420 image format, and each value is represented by UINT8.
-
A special case of nv12 is when "input_space_and_range" is set to "bt601_video" (refer to the previous description of the "input_space_and_range" parameter). In contrast to the regular nv12 case, the value range in this case changes from [0,255] to [16,235], and each value is still represented by UINT8.
-
The data format type for the input feature map of the model only requires the data to be four-dimensional, and each value is represented by float32. For example, models processing radar and audio often use this format.
The calibration data only needs to be processed until input_type_train, and be careful not to perform duplicate normalization operations.
The "input_type_rt" and "input_type_train" are fixed in the algorithm toolchain's processing flow. If you are certain that no conversion is needed, you can set both "input_type" configurations to be the same. This way, "input_type" will be treated as a pass-through without affecting the actual execution performance of the model.
Similarly, the data preprocessing is also fixed in the flow. If you don't need any preprocessing, you can disable this feature by configuring norm_type, without affecting the actual execution performance of the model.
The model optimization compilation completes several important stages, including model parsing, model optimization, model calibration and quantization, and model compilation. The internal workflow is shown in the following diagram:
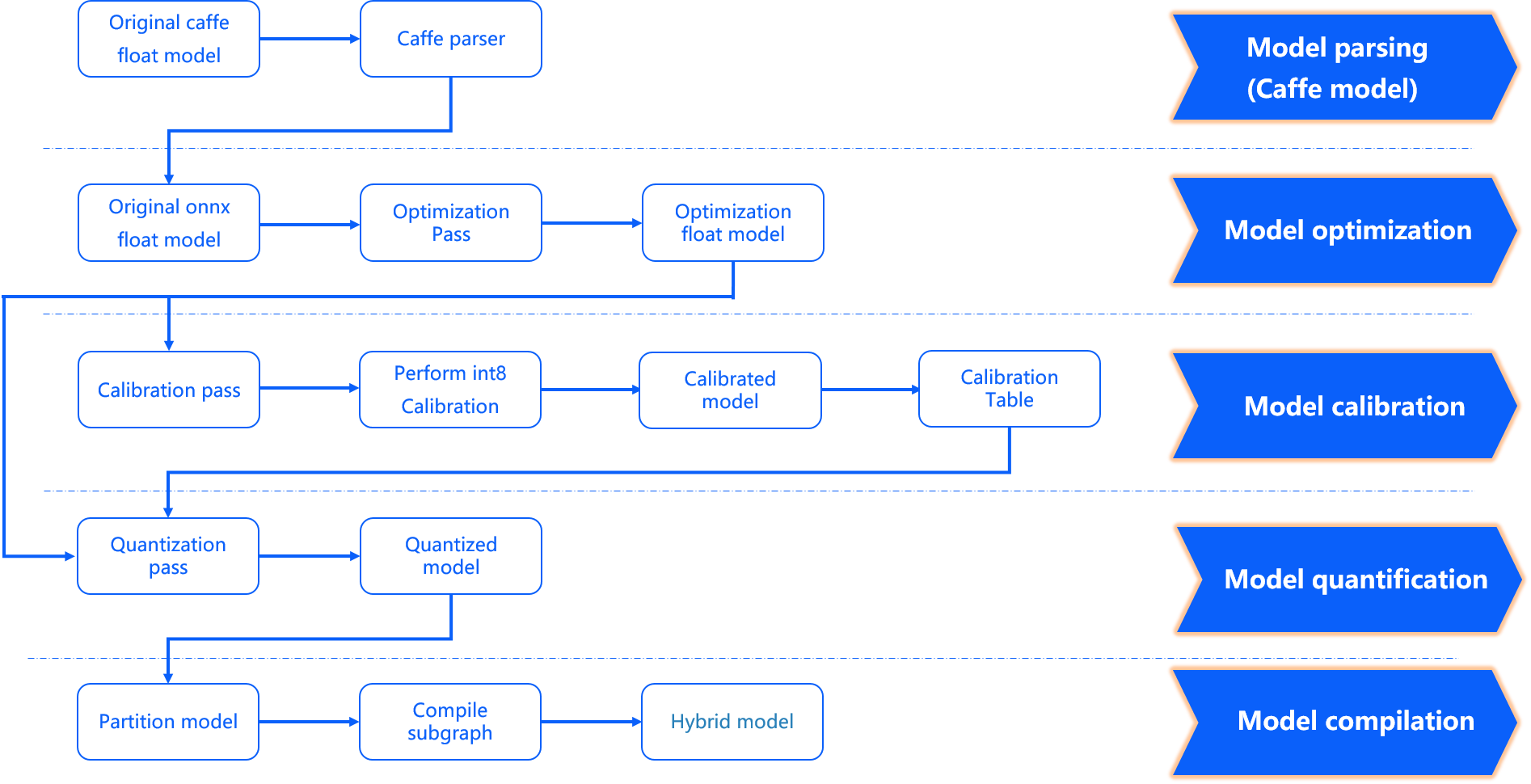
- "input_type_rt*" represents the intermediate format of input_type_rt.
- The X3 processor architecture only supports inference with "NHWC" data. Please use the visualization tool Netron to view the data layout of the input nodes in the "quantized_model.onnx" and decide whether to add "layout conversion" in the preprocessing.
In the model parsing stage, for a Caffe floating-point model, it will be transformed into an ONNX floating-point model. The original floating-point model will determine whether to include a data preprocessing node based on the configuration parameters in the transformation configuration YAML file. This stage produces an "original_float_model.onnx". This ONNX model still has a calculation precision of float32, but it includes a data preprocessing node in the input part.
Ideally, this preprocessing node should complete the complete conversion from "input_type_rt" to "input_type_train". In reality, the entire type conversion process will be completed in collaboration with the D-Robotics processor hardware. The ONNX model does not include the hardware conversion. Therefore, the real input type of ONNX will use an intermediate type, which is the result type of the hardware processing of "input_type_rt". The data layout (NCHW/NHWC) will remain consistent with the input layout of the original floating-point model. Each "input_type_rt" has a specific corresponding intermediate type, as shown in the following table:
| nv12 | yuv444 | rgb | bgr | gray | featuremap |
|---|---|---|---|---|---|
| yuv444_128 | yuv444_128 | RGB_128 | BGR_128 | GRAY_128 | featuremap |
The bold part in the table is the data type specified by "input_type_rt", and the second row represents the specific intermediate type corresponding to a specific "input_type_rt". This intermediate type is the input type of the "original_float_model.onnx". Each type is explained as follows:
- yuv444_128 represents yuv444 data subtracting 128, and each value is represented by int8.
- RGB_128 represents RGB data subtracting 128, and each value is represented by int8.
- BGR_128 represents BGR data subtracting 128, and each value is represented by int8.
- GRAY_128 represents gray data subtracting 128, and each value is represented by int8.- featuremap is a four-dimensional tensor data, and each value is represented as float32.
Model Optimization Phase implements some optimization strategies for the model that are suitable for the D-Robotics platform, such as BN fusion into Conv. The output of this phase is an optimized_float_model.onnx file. The computational precision of this ONNX model is still float32, and the optimization will not affect the computational results of the model. The requirements for the input data of the model are still consistent with the original_float_model mentioned earlier.
Model Calibration Phase uses the calibration data provided by you to calculate the necessary quantization threshold parameters. These parameters will be directly input into the quantization phase without generating new model states.
Model Quantization Phase uses the parameters obtained from calibration to complete model quantization. The output of this phase is a quantized_model.onnx file. The computational precision of this model is int8, and using this model can evaluate the accuracy loss caused by quantization. The basic data format and layout of the input for this model remain the same as the original_float_model, but the layout and numerical representation have changed. The overall changes compared to the original_float_model input are described as follows:
- The data layout of "RDK X3" is NHWC.
- When the value of "input_type_rt" is non-"featuremap", the data type of the input is INT8. Conversely, when the value of "input_type_rt" is "featuremap", the data type of the input is float32.
The relationship between the data layout is as follows:
- Original model input layout: NCHW.
- input_layout_train: NCHW.
- origin.onnx input layout: NCHW.
- calibrated_model.onnx input layout: NCHW.
- quanti.onnx input layout: NHWC.
That is, the input layout of input_layout_train, origin.onnx, and calibrated_model.onnx is consistent with the original model input layout.
Please note that if input_type_rt is nv12, the input layout of quanti.onnx is NHWC.
Model Compilation Phase uses the D-Robotics model compiler to convert the quantized model into the computation instructions and data supported by the D-Robotics platform. The output of this phase is a *.bin model, which is the model that can be run on the D-Robotics embedded platform, and it is the final output of the model conversion.
Interpretation of Conversion Results
This section will introduce the interpretation of the successful conversion status and the analysis methods for unsuccessful conversions. To confirm the successful model conversion, you need to confirm from three aspects: the "makertbin" status information, similarity information, and the "working_dir" output. Regarding the "makertbin" status information, the console will output a clear prompt message at the end of the information when the conversion is successful, as follows:
2021-04-21 11:13:08,337 INFO Convert to runtime bin file successfully!
2021-04-21 11:13:08,337 INFO End Model Convert
The similarity information also exists in the console output of "makertbin". Before the "makertbin" status information, its content is in the following format:
======================================================================
Node ON Subgraph Type Cosine Similarity Threshold
``````bash
…… …… …… …… 0.999936 127.000000
…… …… …… …… 0.999868 2.557209
…… …… …… …… 0.999268 2.133924
…… …… …… …… 0.996023 3.251645
…… …… …… …… 0.996656 4.495638
The output content listed above, Nodes, ON, Subgraph and Type are consistent with the interpretation of the hb_mapper checker tool, please refer to the previous section Check Results;
Threshold is the calibration threshold for each layer, which is used to provide feedback to D-Robotics technical support in abnormal conditions, and does not need to be paid attention to under normal conditions;
The column of Cosine Similarity reflects the cosine similarity of the output results of the corresponding operator in the Node column between the original floating-point model and the quantization model.
In general, the cosine similarity of output nodes in the model >= 0.99 can be considered to be normal, and if the similarity of output nodes is lower than 0.8, there is obvious loss of accuracy. Of course, Cosine Similarity only provides a reference for the stability of quantized data, and there is no obvious direct relationship with the impact on model accuracy. To obtain accurate accuracy information, you need to read the section Model Accuracy Analysis and Tuning.
The conversion output is stored in the path specified by the conversion configuration parameter working_dir. After the model conversion is successfully completed, you can obtain the following files in this directory (the *** part is specified by the conversion configuration parameter output_model_file_prefix):
- ***_original_float_model.onnx
- ***_optimized_float_model.onnx
- ***_calibrated_model.onnx
- ***_quantized_model.onnx
- ***.bin
The usage of each output is explained in the section Conversion Output Interpretation.
Before running on the board, we recommend that you complete the model performance evaluation and tuning process described in Performance Evaluation of the Model to avoid extending the model conversion issues to the subsequent embedded end.
If any of the three aspects of successful model conversion mentioned above are missing, it indicates that there is an error in the model conversion. In general, the makertbin tool will output error information to the console when an error occurs. For example, when converting a Caffe model without configuring the prototxt and caffe_model parameters in the YAML file, the model conversion tool gives the following prompt:
2021-04-21 14:45:34,085 ERROR Key 'model_parameters' error:
Missing keys: 'caffe_model', 'prototxt'
2021-04-21 14:45:34,085 ERROR yaml file parse failed. Please double check your input
2021-04-21 14:45:34,085 ERROR exception in command: makertbin
If the log information output to the console cannot help you find the problem, please refer to the section Model Quantization Errors and Solutions for troubleshooting. If the above steps still cannot solve the problem, please contact the D-Robotics technical support team or submit your issue in the official D-Robotics developer community, and we will provide support within 24 hours.
Conversion Output Interpretation
As mentioned earlier, the successful conversion of the model produces four parts, each of which will be introduced in this section:
- ***_original_float_model.onnx
- ***_optimized_float_model.onnx
- ***_calibrated_model.onnx
- ***_quantized_model.onnx
- ***.bin
The process of generating ***_original_float_model.onnx can refer to the explanation in Conversion Interpretation. The computation accuracy of this model is exactly the same as the original float model used in the conversion input. One important change is the addition of some data preprocessing computations to adapt to the D-Robotics platform (an additional preprocessing operator node called "HzPreprocess" has been added, which can be viewed using the netron tool to open the onnx model. For details about this operator, please see Preprocessing Parameters of Operator HzPreprocess). In general, you do not need to use this model. However, if you encounter abnormal results in the conversion process and the troubleshooting method mentioned earlier does not solve your problem, please provide this model to D-Robotics's technical support team, or submit your questions in the D-Robotics Official Technical Community. This will help you quickly resolve your issue.
The process of generating ***_calibrated_model.onnx can refer to the explanation in Conversion Interpretation. This model is produced by the model conversion toolchain, which optimizes the float model's structure and obtains the quantization parameters for each node by calculating with calibration data, which are saved in the calibration node as intermediate products.
The process of generating ***_optimized_float_model.onnx can refer to the explanation in Conversion Interpretation. This model undergoes some operator-level optimization operations, such as operator fusion. By comparing it with the original_float model visually, you can clearly see some changes at the operator structure level, but these do not affect the model's computation accuracy. In general, you do not need to use this model. However, if you encounter abnormal results in the conversion process and the troubleshooting method mentioned earlier does not solve your problem, please provide this model to D-Robotics's technical support team, or submit your questions in the D-Robotics Official Technical Community. This will help you quickly resolve your issue.
The process of generating ***_quantized_model.onnx can refer to the explanation in Conversion Interpretation. This model has completed the calibration and quantization process. To evaluate the accuracy loss of the quantized model, you can read the content on model accuracy analysis and optimization in the following sections. This model is necessary for accuracy verification. For specific usage, please refer to the introduction in Model Accuracy Analysis and Optimization.
***.bin is the model that can be loaded and run on the D-Robotics processor. With the content introduced in the "Runtime Application Development Guide" section on on-board operation, you can quickly deploy and run the model on the D-Robotics processor. However, to ensure that the model's performance and accuracy meet your expectations, we recommend completing the performance and accuracy analysis process introduced in Model Conversion and Model Accuracy Analysis and Optimization before entering the application development and deployment stages.
In general, the model that can be run on the D-Robotics processor can be obtained after the model conversion stage. However, to ensure that the performance and accuracy of the model meet the application requirements, D-Robotics recommends completing the performance evaluation and accuracy evaluation steps after each conversion.
The model conversion process generates the onnx model, which is an intermediate product for users to verify the model's accuracy. Therefore, it does not guarantee its compatibility between versions. If you use the evaluation script in the example to evaluate the onnx model on a single image or on a test set, please use the onnx model generated by the current version of the tool for operation.
Model Performance Analysis
This section introduces how to use the tools provided by D-Robotics to evaluate the model's performance. By using these tools, you can obtain performance results that are consistent with actual on-board execution. If you find that the evaluation results do not meet your expectations, it is recommended that you try to solve the performance issues based on the optimization suggestions provided by D-Robotics, rather than extending the model's performance issues to the application development stage.
Performance Evaluation on Development Machine
Use the "hb_perf" tool to evaluate the model's performance. The usage is as follows:
hb_perf ***.bin
If the analysis is performed on the "pack" model, it is necessary to add the "-p" parameter, and the command becomes "hb_perf -p ***.bin".
For information about the "pack" model, please refer to the introduction in the other model tools (optional) section.
:::The ***.bin in the command is the quantized model generated in the model conversion step. After the command execution is completed, a hb_perf_result folder will be generated in the current directory, which contains the specific model analysis results.
Here is an example of the evaluation results for the MobileNetv1 model:
hb_perf_result/
└── mobilenetv1_224x224_nv12
├── MOBILENET_subgraph_0.html
├── MOBILENET_subgraph_0.json
├── mobilenetv1_224x224_nv12
├── mobilenetv1_224x224_nv12.html
├── mobilenetv1_224x224_nv12.png
└── temp.hbm
Open the mobilenetv1_224x224_nv12.html main page in a browser. Its content is as shown in the following figure:
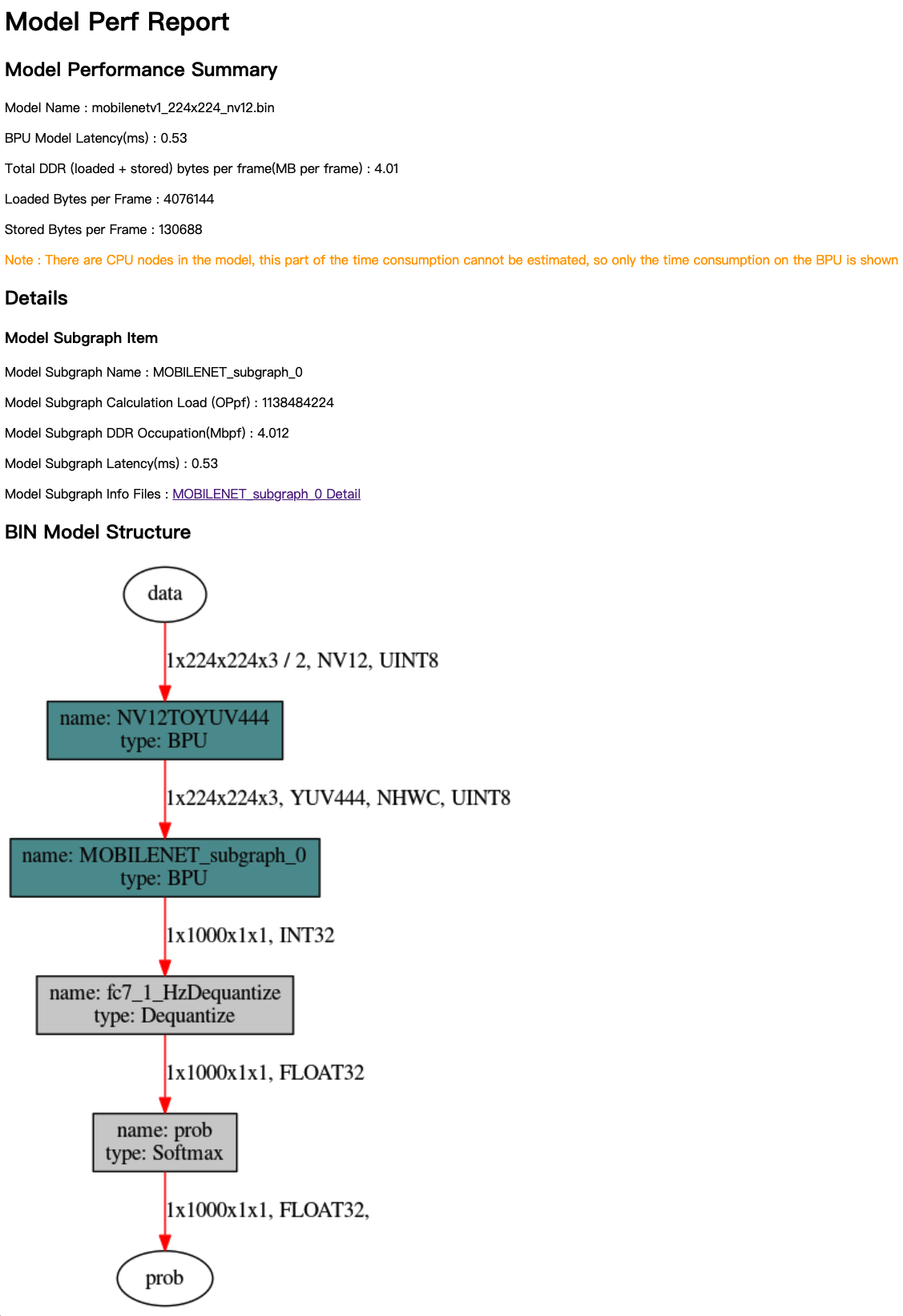
The analysis results mainly consist of three parts: Model Performance Summary, Details, and BIN Model Structure. Model Performance Summary provides an overall performance evaluation of the bin model, with the following metrics:
- Model Name - The name of the model.
- Model Latency (ms) - The overall time taken for calculating one frame of the model (in milliseconds).
- Total DDR (loaded+stored) bytes per frame (MB per frame) - The total amount of DDR used for loading and storing data in the BPU section of the model (in MB per frame).
- Loaded Bytes per Frame - The amount of data loaded per frame during the model execution.
- Stored Bytes per Frame - The amount of data stored per frame during the model execution.
The BIN Model Structure provides a visualization of the subgraphs in the bin model. The nodes in dark cyan represent the nodes running on the BPU, while the gray nodes represent the nodes computed on the CPU.
When viewing the Details and BIN Model Structure, you need to understand the concept of subgraphs. If there are CPU operators in the model network structure, the model conversion tool will split the parts of the BPU calculation before and after the CPU operators into two independent subgraphs. For more information, please refer to the section on Model Verification.
Details provide specific information for each BPU subgraph in the model. In the mobilenetv1_224x224_nv12.html main page, the metrics for each subgraph are as follows:
- Model Subgraph Name - The name of the subgraph.
- Model Subgraph Calculation Load (OPpf) - The calculation load of the subgraph per frame.
- Model Subgraph DDR Occupation (Mbpf) - The amount of data read and written by the subgraph per frame (in MB).
- Model Subgraph Latency (ms) - The calculation time of the subgraph per frame (in milliseconds).
Each subgraph result provides detailed reference information.
The reference information page may vary depending on whether you have enabled the debug configuration.
The Layer Details shown in the following figure can only be obtained when the debug parameter is set to True in the YAML configuration file.
For more information on configuring the debug parameter, please refer to the section on Using hb_mapper makertbin tool to convert models.
Layer Details provide analysis at the specific operator level and can be used as a reference in the model debugging and analysis stage. For example, if certain BPU operators are causing low model performance, the analysis results can help you locate the specific operator.
Please translate the following content into English, maintaining the original format and content: 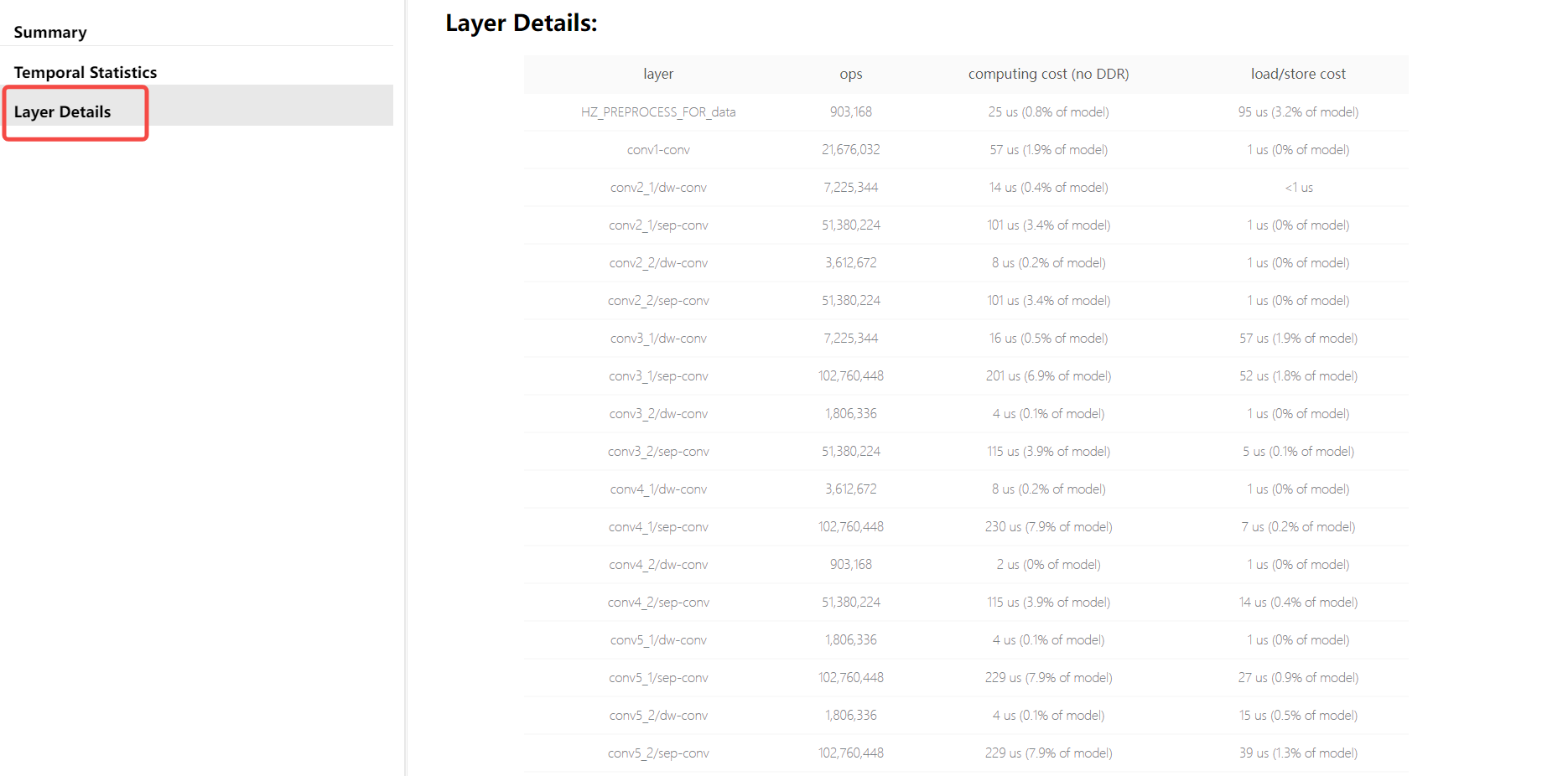
The results obtained from the "hb_perf" tool can help you understand the subgraph structure of the bin model and the static analysis metrics of the BPU calculation part in the model. It is important to note that the analysis results do not include the performance evaluation of the CPU part. If you need to evaluate the performance of CPU calculation, please test the model performance on the development board.
Performance Testing on Development Board
To quickly evaluate the performance of the model on the development board, please use the "hrt_model_exec perf" tool. This tool allows you to evaluate the inference performance of the model and obtain model information directly on the development board.
Before using the "hrt_model_exec perf" tool, please make sure to:
-
Refer to the system update section to complete the system update on the development board.
-
Copy the bin model obtained on the Ubuntu development machine to the development board (recommended to put it in the /userdata directory). The development board is a Linux system, and you can use common Linux methods such as "scp" to complete this copying process.
The command for the "hrt_model_exec perf" tool on the development board is as follows (note that it should be executed on the development board):
./hrt_model_exec perf --model_file mobilenetv1_224x224_nv12.bin \
--model_name="" \
--core_id=0 \
--frame_count=200 \
--perf_time=0 \
--thread_num=1 \
--profile_path="."
Explanation of hrt_model_exec perf parameters:
model_file:
The name of the bin model to be analyzed for performance.
model_name:
The name of the bin model to be analyzed for performance. If "model_file" contains only one model, it can be omitted.
core_id:
Default value is "0", which represents any core. "0" stands for any core, "1" stands for core 0, and "2" stands for core 1. If you want to analyze the maximum frame rate of dual cores, set it to "0".
frame_count:
Default value is "200", which sets the number of inference frames. The tool will execute the specified number of times before analyzing the average time. This takes effect when "perf_time" is "0".
perf_time:
Default value is "0", expressed in minutes. Set the inference time, and the tool will execute for the specified time before analyzing the average time.
thread_num:
Default value is "1", which sets the number of running threads. The value range is between [1, 8]. If you want to analyze the maximum frame rate, increase the number of threads.
profile_path:
Default closed, the log path for statistical tool is generated. The analysis results introduced by this parameter will be stored in the profiler.log and profiler.csv files in the specified directory.
The following example is the actual test result on the RDK X3 development board. After the command is executed, you will get the following log on the console:
Running condition:
Thread number is: 1
Frame count is: 200
core number is: 1
Program run time: 818.985000 ms
Perf result:
Frame totally latency is: 800.621155 ms
Average latency is: 4.003106 ms
Frame rate is: 244.204717 FPS
In the evaluation results, "Average latency" and "Frame rate" respectively indicate the average single-frame inference latency and the model's maximum frame rate. If you want to obtain the maximum frame rate of the model running on the board, try adjusting the value of "thread_num" and find the optimal value for the number of threads. Different values will output different performance results.
The information obtained from the console only provides an overview. The node_profiler.log file generated by setting the "profile_path" parameter records more abundant model performance information:
{
"perf_result": {
"FPS": 244.20471681410527,
"average_latency": 4.003105640411377
},
"running_condition": {
"core_id": 0,
"frame_count": 200,
"model_name": "mobilenetv1_224x224_nv12",
"run_time": 818.985,
"thread_num": 1
}
}
***
{
"chip_latency": {
"BPU_inference_time_cost": {
"avg_time": 3.42556,
"model_latency": {
"BPU_MOBILENET_subgraph_0": {
"avg_time": 3.42556,
"max_time": 3.823,
"min_time": 3.057
},
"Dequantize_fc7_1_HzDequantize": {
"avg_time": 0.12307,
"max_time": 0.274,
"min_time": 0.044
},
"MOBILENET_subgraph_0_output_layout_convert": {
"avg_time": 0.025945,
"max_time": 0.069,
"min_time": 0.012
},
"Preprocess": {
"avg_time": 0.009245,
"max_time": 0.027,
"min_time": 0.003
},
"Softmax_prob": `{`
"avg_time": 0.13366999999999998,
"max_time": 0.338,
"min_time": 0.042
}
},
"task_latency": {
"TaskPendingTime": {
"avg_time": 0.04952,
"max_time": 0.12,
"min_time": 0.009
},
"TaskRunningTime": {
"avg_time": 3.870965,
"max_time": 4.48,
"min_time": 3.219
}
}
} "max_time": 3.823,
"min_time": 3.057
},
"CPU_inference_time_cost": {
"avg_time": 0.29193,
"max_time": 0.708,
"min_time": 0.101
}
},
"model_latency": {
"BPU_MOBILENET_subgraph_0": {
"avg_time": 3.42556,
"max_time": 3.823,
"min_time": 3.057
},
"Dequantize_fc7_1_HzDequantize": {
"avg_time": 0.12307,
"max_time": 0.274,
"min_time": 0.044},
"MOBILENET_subgraph_0_output_layout_convert": {
"avg_time": 0.025945,
"max_time": 0.069,
"min_time": 0.012
},
"Preprocess": {
"avg_time": 0.009245,
"max_time": 0.027,
"min_time": 0.003
},
"Softmax_prob": {
"avg_time": 0.13366999999999998,
"max_time": 0.338,
"min_time": 0.042
}
},
"task_latency": {
"TaskPendingTime": {
"avg_time": 0.04952,
"max_time": 0.12,
"min_time": 0.009
},
"TaskRunningTime": {
"avg_time": 3.870965,
"max_time": 4.48,
"min_time": 3.219
}
}
}
The above log corresponds to the bin visualization diagram in the Estimating Performance using hb_perf section of the BIN Model Structure. Each node in the diagram has a corresponding node in the profiler.log file, which can be matched by the "name". Additionally, the profiler.log file also records the execution time of each node, providing reference for optimizing model operators. Since the BPU nodes in the model have special requirements for input and output, such as special layout and padding alignment requirements, the input and output data of BPU nodes need to be processed.
- "Preprocess": Indicates padding and layout conversion operations on model input data, and its time consumption is recorded in "Preprocess".
- "xxxx_input_layout_convert": Indicates padding and layout conversion operations on the input data of BPU nodes, and its time consumption is recorded in "xxxx_input_layout_convert".
- "xxxx_output_layout_convert": Indicates removal of padding and layout conversion operations on the output data of BPU nodes, and its time consumption is recorded in "xxxx_output_layout_convert". "Profiler" analysis is a commonly used operation in model performance tuning. As mentioned in the previous Interpreting Check Results section, the CPU operators do not need to be focused on during the check phase. In this phase, the specific time consumption of CPU operators can be observed, and model performance tuning can be performed based on the time consumption of the corresponding operators.
If the model's time consumption is severe, you can also optimize the performance in the following ways:
- Single-frame single-core: When a frame of data comes in, a model is used to perform inference on a single core.
- Single-frame dual-core: The model is specified as a dual-core model during compilation (core_num: 2 in the yaml configuration file). After running, it will automatically occupy the resources of both cores. Then, when a frame of data comes in, it will be split into two parts and calculated separately, and finally reassembled. This mode has a more obvious optimization effect on large models and may increase latency. However, small models may actually slow down due to this dual-core scheduling.
- Dual-frame dual-core: Two cores are used to independently process data frames using separate models. The latency will not be reduced, but the frame rate can reach about double.
Model Performance Optimization
Based on the performance analysis results above, you may find that the model performance is not as expected. This section introduces D-Robotics's suggestions and measures to improve model performance, including checking YAML configuration parameters, handling CPU operators, high-performance model design suggestions, and using Horizon-friendly structures and models.
Some of the modification suggestions in this section may affect the parameter space of the original floating-point model. Therefore, you need to retrain the model. To avoid repeatedly adjusting and training the model during performance tuning, it is recommended that you use random parameters to export the model for performance verification until you obtain satisfactory model performance.
Check YAML parameters that affect model performance
In the YAML configuration file for model conversion, some parameters actually affect the final performance of the model. Please check if they have been correctly configured according to the model expectations. For the specific meanings and functions of each parameter, please refer to the "Compiler Parameters" section.
layer_out_dump: Specifies whether to output intermediate results of the model during model conversion. This is generally only used for debugging purposes. If set toTrue, an additional dequantization output node will be added to each convolution operator, which will significantly reduce the performance of the model after it is deployed. Therefore, when evaluating performance, be sure to set this parameter toFalse.compile_mode: This parameter is used to select the optimization direction when compiling the model, which can be either "bandwidth" or "latency". When focusing on performance, please set it tolatency.optimize_level: This parameter is used to select the optimization level of the compiler. In practical use, it should be set toO3to achieve the best performance.core_num: Note: This parameter only applies to RDK X3. When set to2, it can run on two cores simultaneously, reducing the inference delay per frame, but it will also affect the overall throughput.debug: Setting this parameter toTruewill enable the debug mode of the compiler, which can output related information for performance simulation, such as frame rate and DDR bandwidth usage. It is generally used during performance evaluation. When delivering for commercialization, you can turn off this parameter to reduce the model size and improve model execution efficiency.max_time_per_fc: This parameter is used to control the execution duration of the function call of compiled model data instructions, thereby implementing model priority preemption. Modifying this parameter to change the execution duration of the preempted model's function call will affect the performance of the model after deployment.
Handling CPU operators
According to the evaluation of the hrt_model_exec perf tool, if it can be confirmed that the performance bottleneck of the model is caused by CPU operators, in this case, it is recommended that you refer to the contents of the "Supported Operator List" section to check if the current CPU operator running on the CPU has the BPU support capability.
If the operator has the BPU support capability in the Supported Operator List, it means that the parameters of the operator exceed the constraints of BPU support. It is recommended that you adjust the corresponding original floating-point model calculation parameters to within the constraints. To quickly understand the specific parameters that exceed the constraints, it is recommended that you use the method described in the "Model Check" section to check again. The tool will directly provide parameter prompts that exceed the BPU support range.
Modifying the parameters of the original floating-point model and its impact on model calculation accuracy needs to be controlled by yourself. For example, exceeding the range of parameters such as input_channel or output_channel of Convolution is a relatively typical case. After reducing the channels, the operator will be supported by BPU, but making only this modification may also affect the model accuracy.
If the operator does not have the BPU support capability, you need to perform corresponding optimization operations based on the following situations:
-
CPU operator is in the middle of the model
For the case where the CPU operator is in the middle of the model, it is recommended that you try parameter adjustment, operator replacement, or modify the model first.
-
CPU operator is at the beginning or end of the model
For the case where the CPU operator is at the beginning or end of the model, please refer to the following example below, using quantization/dequantization nodes as an example:
-
For nodes connected to the input and output of the model, you can add the "remove_node_type" parameter in the YAML file's "model_parameters" configuration group and recompile the model.
remove_node_type: "Quantize; Dequantize" -
The bin model can be modified using the hb_model_modifier tool:
hb_model_modifier x.bin -a Quantize -a Dequantize -
For models like the one in the picture below that are not connected to input and output nodes, the hb_model_modifier tool needs to be used to determine if the connected nodes support deletion. The nodes can then be deleted one by one in order.
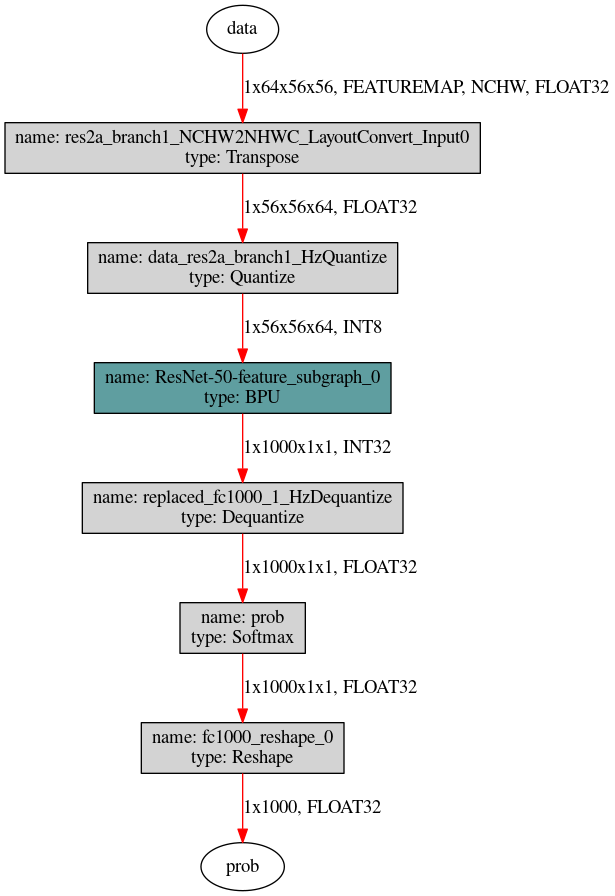
First, use the hb_perf tool to get the model structure image, and then use the following two commands to remove the Quantize nodes from top to bottom. For the Dequantize nodes, they can be deleted one by one from bottom to top. The name of the node that can be deleted at each step can be checked using
hb_model_modifier x.bin.hb_model_modifier x.bin -r res2a_branch1_NCHW2NHWC_LayoutConvert_Input0
hb_model_modifier x_modified.bin -r data_res2a_branch1_HzQuantize
-
Suggestions for High-Performance Model Design
Based on performance evaluation results, the percentage of time consumed on the CPU may be small, indicating that the bottleneck is the long BPU inference time. In such cases, all BPU computing resources are already being used, so the next step is to improve resource utilization to optimize performance. Each processor has its own hardware characteristics, and how well the computation parameters of the algorithm model match the respective hardware characteristics directly affects the computational resource utilization. The higher the fit, the higher the utilization rate, and vice versa.
This section focuses on the hardware characteristics of D-Robotics Processors. D-Robotics provides processors designed to accelerate CNN (Convolutional Neural Network) processing, with the main computing resources focused on various convolution calculations. We recommend designing models that are primarily based on convolution calculations, as operators outside of convolution will reduce the utilization rate of computational resources, and the impact on performance varies depending on the specific OP.
-
Other Suggestions
The computation efficiency of
depthwise convolutionon D-Robotics Processors is close to 100%, so for models likeMobileNet, BPU has an efficiency advantage.It is recommended to reduce the input and output dimensions of the BPU segment in model design to reduce the time consumed by quantization, dequantization nodes, and the bandwidth pressure on the hardware. For typical segmentation models, it is recommended to directly integrate the Argmax operator into the model itself. However, please note that Argmax can only be accelerated by BPU if the following conditions are met:
- In Caffe, the Softmax layer defaults to axis=1, while the ArgMax layer defaults to axis=0. The replacement operator should maintain consistency in the axis.
- The channel of Argmax should be less than or equal to 64, otherwise it can only be computed on the CPU.
-
BPU-Oriented Efficiency Model Optimization
D-Robotics's BPU has targeted optimizations for
depthwise convolutionandgroup convolution. Therefore, we recommend using models with a Depthwise+Pointwise structure, such as MobileNetv2, EfficientNet_lite, and the custom-designed VarGNet based on GroupConv, as the backbone of the model to achieve higher performance benefits.We are continually exploring more model structures and business models, and we will provide more diverse models for your reference. These outputs will be periodically updated to https://github.com/D-Robotics/rdk_model_zoo . If you still cannot find a suitable model, please feel free to reach out to us on the D-Robotics Official Technical Community. We will provide more targeted guidance and suggestions based on your specific problems.
Model Accuracy Analysis
PTQ post-quantization method based on tens or hundreds of calibration data unavoidably incurs certain precision loss. D-Robotics's PTQ conversion tool has been extensively verified through practical use, and in most cases, the precision loss of the model can be kept within 1%.
This section first introduces how to correctly analyze the model precision. If the evaluation shows that the precision is lower than expected, you can refer to the content in the Precision Optimization section for model precision optimization.
Precision Analysis
As mentioned earlier, the output of a successfully converted model includes the following four parts:
- ***_original_float_model.onnx
- ***_optimized_float_model.onnx
- ***_quantized_model.onnx
- ***.bin
Although the final bin model is the one deployed on D-Robotics processors, for the convenience of quickly obtaining the model precision on Ubuntu/CentOS development machines, we also support using ***_quantized_model.onnx for precision testing. The quantized model ***_quantized_model.onnx has consistent precision performance with the bin model running on the X3 processor.
We recommend using the D-Robotics development library to load the ONNX model for inference. The basic process is as follows:
-
The sample code is applicable to quantized models as well as original and optimized models. You can prepare the data for model inference according to the input types and layout requirements of different models.
-
It is recommended to refer to the precision validation method of the sample models in the "horizon_model_convert_sample" package for D-Robotics model conversion, such as caffe, onnx, etc.: "04_inference.sh" and "postprocess.py".
# Load D-Robotics dependency libraries
from horizon_tc_ui import HB_ONNXRuntime
# Prepare the feed_dict for model execution
def prepare_input_dict(input_names):
feed_dict = dict()
for input_name in input_names:
# your_custom_data_prepare represents your custom data
# Prepare the data based on the input node's type and layout requirements
feed_dict[input_name] = your_custom_data_prepare(input_name)
return feed_dict
if __name__ == '__main__':
# Create an inference session
sess = HB_ONNXRuntime(model_file='***_quantized_model.onnx')
# Get the input node names
input_names = [input.name for input in sess.get_inputs()]
# or
input_names = sess.input_names
# Get the output node names
output_names = [output.name for output in sess.get_outputs()]
# or
output_names = sess.output_names
# Prepare model input data
feed_dict = prepare_input_dict(input_names)
# Start model inference, the return value of inference is a list, which corresponds to the specified names in output_names one by one
# The input image type range is (RGB/BGR/NV12/YUV444/GRAY)
outputs = sess.run(output_names, feed_dict, input_offset=128)
# The input data type range is (FEATURE)
outputs = sess.run_feature(output_names, feed_dict, input_offset=0)
In the above code, the input_offset parameter has a default value of 128. For models with preprocessing nodes, a -128 operation is required here. If there is no preprocessing node before the model input, input_offset needs to be set as 0.
For models with multiple inputs:
-
If all input_type_rt belong to (RGB/BGR/NV12/YUV444/GRAY), you can use the
sess.runmethod for inference. -
If all input_type_rt belong to (FEATUREMAP), you can use the
sess.run_featuremethod for inference. -
Please note that currently, mixed input_type_rt of FEATUREMAP and non-FEATUREMAP is not supported to use sess.* methods for inference.
In addition, the your_custom_data_prepare function, which represents the input data preparation process, is the part most prone to misoperation.
Compared with the accuracy verification process during the design and training of your original floating-point model, it is recommended that you adjust the inference input data after data preprocessing: mainly the data format (RGB, NV12, etc.), data precision (int8, float32, etc.), and data arrangement (NCHW or NHWC).
The adjustment method is determined by the four parameters input_type_train, input_layout_train, input_type_rt, and input_layout_rt set in the yaml configuration file during model conversion, and their detailed rules can be found in the Conversion Interpretation section.
For example, consider the original floating-point model trained with ImageNet for classification, which has only one input node. This node takes in a three-channel image in BGR order, and the input data layout is NCHW. During the design and training of the original floating-point model, the data preprocessing before inference on the validation set is as follows:
- Scale the image proportionally to have a short side of 256 pixels.
- Use the
center_cropmethod to obtain a 224x224 image. - Subtract the mean value across channels.
- Multiply the data by a scale factor.
When using D-Robotics as the conversion tool for this original floating-point model, set input_type_train to bgr, input_layout_train to NCHW, input_type_rt to bgr, and input_layout_rt to NHWC.
According to the rules mentioned in the Conversion Interpretation section, the input accepted by ***_quantized_model.onnx should be bgr_128 with NHWC arrangement.
Based on the previous example code, the data processing in the your_custom_data_prepare part would be as follows:
# This example uses skimage, it may be different if you use OpenCV
# It is worth noting that the transformers do not include the subtraction of mean and multiplication by scale
# The mean and scale operations have been integrated into the model, refer to the configuration of norm_type/mean_value/scale_value mentioned earlier
def your_custom_data_prepare_sample(image_file):
# Read the image using skimage, already in NHWC layout
image = skimage.img_as_float(skimage.io.imread(image_file))
# Scale the image proportionally to have a short side of 256 pixels
image = ShortSideResize(image, short_size=256)
# Use CenterCrop to obtain a 224x224 imageimage = CenterCrop(image, crop_size=224)
# Skimage reads the channels in RGB order, we need BGR order for RGB2BGR conversion
image = RGB2BGR(image)
# If the original model uses NCHW format as input (except for input_type_rt with nv12), convert to CHW format
if layout == "NCHW":
image = HWC2CHW(image)
# Skimage reads the values in the range of [0.0, 1.0], adjust to the range required for BGR
image = image * 255
# Subtract 128 for bgr_128
image = image - 128
# Convert to int8 for bgr_128
image = image.astype(np.int8)
return image
Precision Optimization
Based on the previous precision analysis, if you determine that the model's quantization accuracy does not meet expectations, the following two main scenarios can be addressed:
-
Significant Loss (greater than 4%) This issue is often caused by inappropriate YAML configuration or an imbalanced validation dataset. It is recommended to follow D-Robotics's suggested steps for troubleshooting one by one.
-
Small Loss (1.5% to 3%) After excluding issues from scenario 1, if there's still a slight loss in accuracy, it's usually due to the model's inherent sensitivity. In this case, use D-Robotics's provided precision tuning tools for optimization.
-
After Trying 1 and 2 If the precision still doesn't meet expectations, try using our precision debugging tool for further attempts.
The overall process for addressing precision issues is illustrated below:
Significant Loss (Greater than 4%)
If the model suffers from a loss greater than 4%, it's typically because of incorrect YAML configuration or an imbalanced calibration dataset. You should check the following aspects:
Pipeline Check
The pipeline refers to the entire process from data preprocessing, model conversion, inference, post-processing, to accuracy evaluation. Please refer to the corresponding chapters in the text for checks.
In practical problem-solving experiences, we've found that most issues arise from changes during the original float model training phase that aren't promptly updated in the model conversion stage, leading to unexpected accuracy validation results.
Model Conversion Configuration Check
-
input_type_rtandinput_type_train: These parameters determine the data format required for the mixed-heterogeneous post-converted model compared to the original float model. Ensure they match your expectations, especially regarding the BGR and RGB channel order. -
norm_type,mean_value,scale_value, etc. Verify that these parameters are correctly configured. Directly inserting mean and scale operations through the conversion configuration can lead to duplicate preprocessing, which is a common mistake.
Data Processing Consistency Check
This part applies mainly to users who prepare calibration data and evaluation code using reference algorithm toolchain development packages. Common errors include:
-
Incorrect
read_modespecification: In02_preprocess.sh, you can specify the image reading method with the--read_modeparameter, supportingopencvandskimage. Similarly, inpreprocess.py, ensure theimread_modeparameter is set correctly. Usingskimagemay read RGB channels with values between0~1asfloat, whileopencvreads BGR with values between0~255asuint8. -
Incorrect storage format for calibration datasets: D-Robotics uses
numpy.tofilefor saving calibration data, which does not preserve shape or type information. Ifinput_type_trainis not in "featuremap" format, the program will infer the data type based on whether the calibration data path contains "f32". From X3 algorithm toolchain v2.2.3a, a new parametercal_data_typehas been added to set the binary file data storage type. -
Inconsistent transformer implementation: D-Robotics provides common preprocessing functions in
/horizon_model_convert_sample/01_common/python/data/transformer.py. Differences in ResizeTransformer implementation might exist, such as using OpenCV's default interpolation method (linear). To modify other interpolation methods, edit thetransformer.pysource code and ensure consistency with the training-time preprocessing code. Refer to the Transformer Usage section for more details. -
Continue using the original float model's data processing library during the D-Robotics algorithm toolchain. For less robust models, discrepancies in resize, crop, and other common functions across libraries can affect precision.
-
Ensure a reasonable validation image set. The calibration dataset should contain around "a hundred" images, covering various scenarios in the data distribution. For multi-task or multi-class models, the validation set should cover all prediction branches or classes.
-
Avoid using abnormal images that deviate from the data distribution, such as overexposed ones.
-
Re-validate the accuracy using the
***_original_float_model.onnxmodel. Normally, this model's accuracy should align to the original float model's accuracy to three to five decimal places. If the alignment is not met, it indicates the need for a more thorough review of your data processing.
Minor Accuracy Improvement
In general, to reduce the difficulty of accuracy tuning, it is recommended that you set the calibration_type to default. Default is an automatic search function that selects the optimal calibration method based on the cosine similarity of the output nodes of the first calibration data, selecting from methods such as max, max-Percentile 0.99995, and KL. The selected calibration method can be found in the conversion log with a hint like "Select kl method." If the accuracy results of the automatic search still do not meet expectations, the following suggestions can be tried for tuning:
Adjust Calibration Method
-
Manually specify the
calibration_type, which can be set tokl/max. -
Set the calibration_type to max, and configure max_percentile to different percentiles (ranging from 0 to 1). We recommend trying 0.99999, 0.99995, 0.9999, 0.9995, 0.999, and observing the changes in model accuracy through these five configurations to find the best percentile.
-
Try enabling
per_channeland use it in combination with any calibration method mentioned above.
Adjust Calibration Dataset
-
Try increasing or decreasing the data quantity appropriately (usually, fewer calibration data are required for detection scenarios compared to classification scenarios). Additionally, observe cases with missed detections in the model output and increase the calibration data for those scenarios.
-
Avoid using abnormal data such as pure black or pure white, and try to minimize the use of background images without targets as calibration data. Cover typical scenario tasks comprehensively to make the distribution of the calibration dataset approximate to the training dataset.
Retreat Some Tail Operators to High-precision CPU Computation
-
Usually, we only try to retreat "1 to 2" operators of the model output layer to the CPU. Having too many operators on the CPU will significantly affect the final model performance, and the judgment can be based on observing the cosine similarity of the model.
-
To specify operators running on the CPU, use the
run_on_cpuparameter in the YAML file. Specify the node name to indicate the corresponding operator running on the CPU (e.g., run_on_cpu: conv_0). -
If there is an error during model compilation after specifying run_on_cpu, please contact the D-Robotics technical support team.
Accuracy Debugging ToolsAfter trying the above two methods for accuracy fine-tuning, if your accuracy still does not meet expectations, we provide an accuracy debug tool to help you locate the problem.
This tool can assist you in analyzing the quantization error of the calibration model at the node level and quickly identify nodes with accuracy issues.
If you are using the RDK Ultra product, you can also try precision tuning by configuring some ops to calculate in int16 ( RDK X3 does not support int16 calculation for ops):
During the model conversion process, most ops are calculated using int8 data by default. In some cases, using int8 calculation for some ops may result in noticeable accuracy loss. For RDK Ultra products, the algorithm toolchain already provides the ability to specify certain ops to calculate in int16 bit, as described in the int16 configuration parameter configuration. By configuring ops that are sensitive to quantization loss (with cosine similarity as a reference) to calculate in int16 bit, accuracy loss in some scenarios can be resolved.
During the process of model conversion, accuracy loss may occur due to the quantization process from floating point to fixed point. The main reasons for accuracy loss may include:
-
Certain nodes in the model are sensitive to quantization and introduce large errors, referred to as sensitivity issues.
-
Accumulated errors in each node of the model result in large calibration errors for the overall model, mainly including: accumulated errors caused by weight quantization, accumulated errors caused by activation quantization, and accumulated errors caused by full quantization.
In response to this situation, D-Robotics provides an accuracy debug tool to help you independently locate accuracy issues that occur during the model quantization process. This tool can assist you in analyzing the quantization error of the calibration model at the node level and ultimately help you quickly identify nodes with accuracy exceptions.
The accuracy debug tool provides various analysis functions for your use, such as:
-
Obtaining the quantization sensitivity of nodes.
-
Obtaining the accumulated error curve of the model.
-
Obtaining the data distribution of specified nodes.
-
Obtaining box plots of data distribution between input data channels of specified nodes, etc.
Instructions for Use
Using the accuracy debug tool mainly involves the following steps:
-
In the
model parameterssection of the YAML file, configure the parameterdebug_mode="dump_calibration_data"to save the calibration data. -
Import the debug module and load the calibration model and data.
-
Analyze the models with noticeable accuracy loss using the APIs or command line provided by the accuracy debug tool.
For the current version of the accuracy debug tool: For the RDK Ultra corresponding to the bayes architecture model, both command line and API methods are supported for debugging, while for the RDK X3 corresponding to the bernoulli2 architecture model, only the API method is supported for debug.
The overall process is shown in the following diagram:
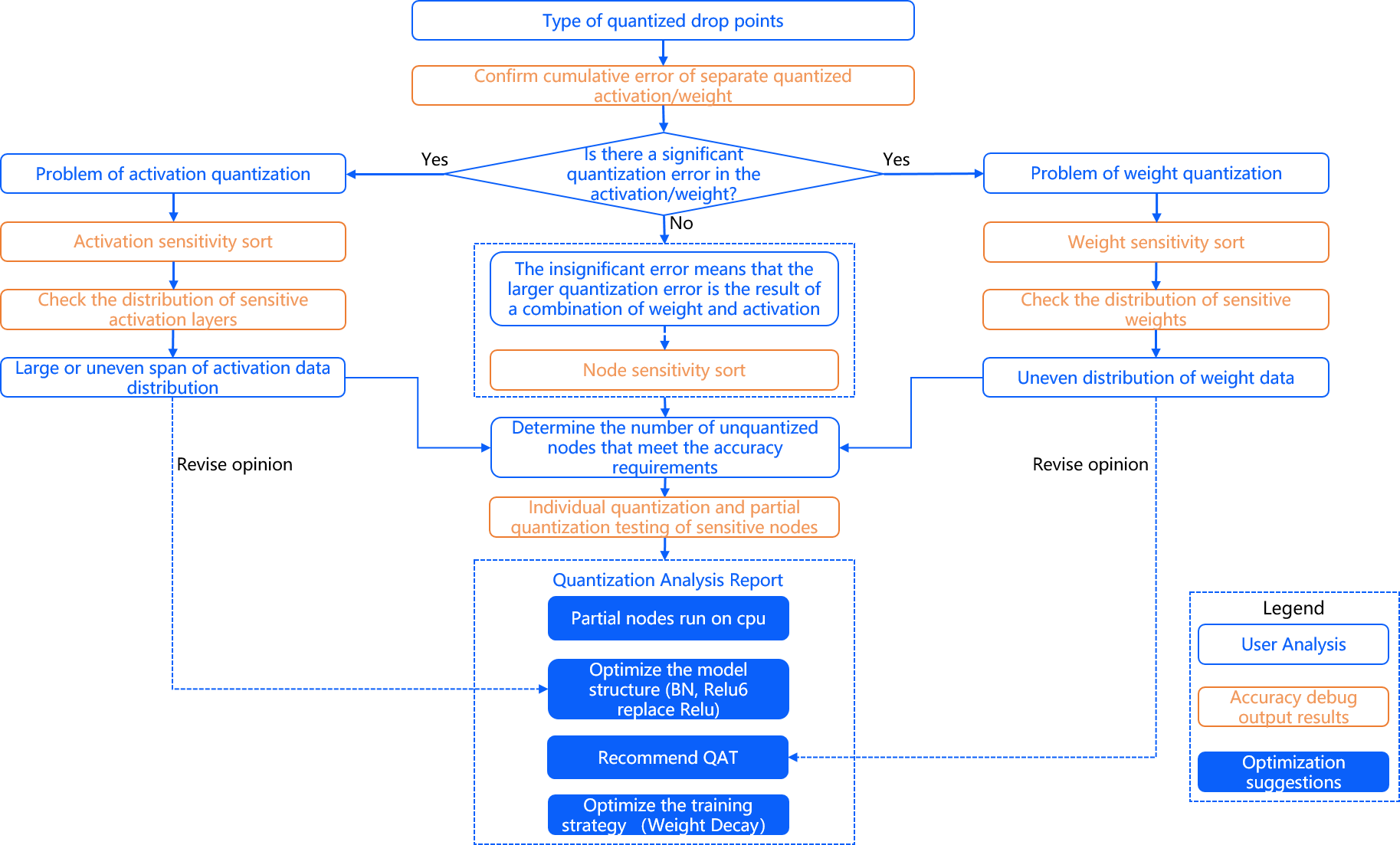
Saving Calibration Models and Data
To enable the accuracy debug feature, the debug_mode="dump_calibration_data" needs to be set in the YAML file, and the calibration data (calibration_data) and the corresponding calibrated model (calibrated_model.onnx) need to be saved. Specifically:
-
Calibration Data (calibration_data): During the calibration phase, the model performs forward inference on these data to obtain the quantization parameters for each quantized node, including the scaling factor (scale) and threshold.
-
Calibrated Model (calibrated_model.onnx): The quantization parameters obtained during the calibration phase for each quantized node are saved in the calibration nodes to generate the calibrated model.
Difference between the saved calibration data here and the calibration data generated by 02_preprocess.sh:
The calibration data obtained by 02_preprocess.sh is data in the BGR color space, which will be transformed from BGR to the actual input format of the model, such as YUV444 or gray, within the toolchain.
The calibration data saved here is in the form of .npy after color space conversion and preprocessing. This data can be directly loaded using np.load() and input into the model for inference.
Interpretation of Calibrated Model (calibrated_model.onnx):
The calibrated model is an intermediate product obtained by the model transformation toolchain. It is obtained by calculating the quantization parameters for each node based on the calibration data and saving them in the calibration nodes. The main characteristic of the calibrated model is that it contains calibration nodes, which have a node type of HzCalibration. These calibration nodes are mainly divided into two categories: activation calibration nodes and weight calibration nodes.
The input of an activation calibration node is the output of the previous node, and the input data is quantized and then de-quantized based on the quantization parameters (scales and thresholds) saved in the activation calibration node.
The input of a weight calibration node is the original floating-point weights of the model, which are quantized and then de-quantized based on the quantization parameters (scales and thresholds) saved in the weight calibration node.
Other nodes in the calibrated model, excluding the above calibration nodes, are referred to as ordinary nodes by the accuracy debug tools. The types of ordinary nodes include Conv, Mul, Add, etc.
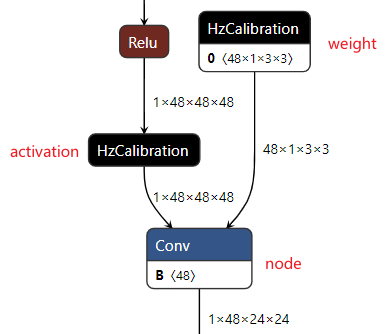
The folder structure of the calibration_data is as follows:
|--calibration_data: Calibration Data
|----input.1: The folder is named after the input nodes of the model, and the corresponding input data is saved in it.
|--------0.npy
|--------1.npy
|-------- ...
|----input.2: For models with multiple inputs, multiple folders will be saved.
|--------0.npy
|--------1.npy
|-------- ...
- Importing and Using the Precision Debug Module
Next, you need to import the debug module in your code and use the get_sensitivity_of_nodes interface to retrieve the quantization sensitivity of nodes (defaulting to the cosine similarity of model outputs).
Details about the parameters of get_sensitivity_of_nodes can be found in the corresponding chapter.
# Import the debug module
import horizon_nn.debug as dbg
# Import the log module
import logging
# Set the log level to INFO if verbose=True
logging.getLogger().setLevel(logging.INFO)
# Retrieve the quantization sensitivity of nodes
node_message = dbg.get_sensitivity_of_nodes(
model_or_file='./calibrated_model.onnx',
metrics=['cosine-similarity', 'mse'],
calibrated_data='./calibration_data/',
output_node=None,
node_type='node',
data_num=None,
verbose=True,
interested_nodes=None)
- Analysis Results Display
Here are the printed results when verbose=True:
==========================node==========================
Node cosine-similarity mse
--------------------------------------------------------
Conv_3 0.999009567957658 0.027825591154396534
MaxPool_2 0.9993462241612948 0.017706592209064044
Conv_6 0.9998359175828787 0.004541242333988731
MaxPool_5 0.9998616805443397 0.0038416787014844325
Conv_0 0.9999297948984 0.0019312848587735342
Gemm_19 0.9999609772975628 0.0010773885699633795
Conv_8 0.9999629625907311 0.0010301886404004807
Gemm_15 0.9999847687207736 0.00041888411550854263
MaxPool_12 0.9999853235024673 0.0004039733791544747
Conv_10 0.999985763659844 0.0004040437432614943
Gemm_17 0.9999913985912616 0.0002379088904350423
In addition, the API will return the quantization sensitivity information of the nodes to you in the form of a dictionary (Dict) for subsequent use and analysis.
Out:
`{`'Conv_3': `{`'cosine-similarity': '0.999009567957658', 'mse': '0.027825591154396534'`}`,
'MaxPool_2': `{`'cosine-similarity': '0.9993462241612948', 'mse': '0.017706592209064044'`}`,
'Conv_6': `{`'cosine-similarity': '0.9998359175828787', 'mse': '0.004541242333988731'`}`,
'MaxPool_5': `{`'cosine-similarity': '0.9998616805443397', 'mse': '0.0038416787014844325'`}`,
'Conv_0': `{`'cosine-similarity': '0.9999297948984', 'mse': '0.0019312848587735342'`}`,
'Gemm_19': `{`'cosine-similarity': '0.9999609772975628', 'mse': '0.0010773885699633795'`}`,
'Conv_8': `{`'cosine-similarity': '0.9999629625907311', 'mse': '0.0010301886404004807'`}`,
'Gemm_15': `{`'cosine-similarity': '0.9999847687207736', 'mse': '0.00041888411550854263'`}`,
'MaxPool_12': `{`'cosine-similarity': '0.9999853235024673', 'mse': '0.0004039733791544747'`}`,
'Conv_10': `{`'cosine-similarity': '0.999985763659844', 'mse': '0.0004040437432614943'`}`,
'Gemm_17': `{`'cosine-similarity': '0.9999913985912616', 'mse': '0.0002379088904350423'`}``}`
For more functions, please refer to the "Function Description" section.
The precision debugging tool can also be checked by the command hmct-debugger -h/--help to see the sub-commands corresponding to each function.
The detailed parameters and usage of each sub-command are described in the "Function Description" section.
Function Description
- get_sensitivity_of_nodes
Function: Get the quantization sensitivity of the nodes.
Command format:
hmct-debugger get-sensitivity-of-nodes MODEL_OR_FILE CALIBRATION_DATA --other options
You can use hmct-debugger get-sensitivity-of-nodes -h/--help to view related parameters.
Parameter group:
| Parameter Name | Parameter Description | Value Range | Optional/Required |
|---|---|---|---|
model_or_file | Description: Specify the calibration model. Note: Required. Specify the calibration model to be analyzed. | Range: N/A Default: N/A. | Required |
metrics 或 - m | Description: The measurement method for quantization sensitivity of nodes. Note: Specify the calculation method of the quantization sensitivity of nodes. This parameter can be a list, which means that the quantization sensitivity is calculated in multiple ways, but the output results are sorted based on the calculation method in the first position of the list. The higher the ranking, the larger the error introduced by quantizing the node. | Range: 'cosine-similarity' , 'mse' , 'mre' , 'sqnr' , 'chebyshev' Default: 'cosine-similarity'. | Optional |
calibrated_data | Description: Specify the calibration data. Note: Required. Specify the calibration data needed for analysis. | Range: N/A. Default: N/A. | Required |
output_node 或 -o | Description: Specify the output node. Note: This parameter allows you to specify intermediate nodes as outputs and calculate the quantization sensitivity of the nodes. If the default parameter is None, the precision debugging tool will obtain the final output of the model and calculate the quantization sensitivity based on it. | Range: Ordinary nodes with corresponding calibration nodes in the calibration model. Default: None. | Optional |
node_type 或 -n | Description: Node type. Note: The type of node to calculate the quantization sensitivity, including: 'node' (ordinary node), 'weight' (weight calibration node), 'activation' (activation calibration node). | Range: 'node' , 'weight' , 'activation'. Default: 'node'. | Optional |
verbose or -v | Parameter Function:Choose whether to print the information on the terminal. Parameter Description:If True, the quantization sensitivity information will be printed on the terminal. If there are multiple metrics in metrics, they will be sorted according to the first one. | Value Range:True 、 False.Default Configuration: False. | Optional |
interested_nodes or -i | Parameter Function:Set interested nodes. Parameter Description:If specified, only the quantization sensitivity of this node will be obtained, and the remaining nodes will not be obtained. At the same time, if this parameter is specified, the priority will be given to interested_nodes rather than node_type. If the default parameter None is maintained, the quantization sensitivity of all quantizable nodes in the model will be calculated. | Value Range:All nodes in the calibrated model. Default Configuration:None. | Optional |
Function Usage:
# Import the debug module
import horizon_nn.debug as dbg
# Import the log module
import logging
# Set the log level to INFO if verbose=True
logging.getLogger().setLevel(logging.INFO)
# Get the sensitivity of nodes
node_message = dbg.get_sensitivity_of_nodes(
model_or_file='./calibrated_model.onnx',
metrics=['cosine-similarity', 'mse'],
calibrated_data='./calibration_data/',
output_node=None,
node_type='node',
data_num=None,
verbose=True,
interested_nodes=None)
Command-line Usage:
hmct-debugger get-sensitivity-of-nodes calibrated_model.onnx calibration_data -m ['cosine-similarity','mse'] -v True
Result Display:
Description: First, you set the node type that needs to calculate the sensitivity through node_type. Then, the tool obtains all nodes in the calibrated model that meet node_type and obtains the quantization sensitivity of these nodes.
When verbose is set to True, the tool will print the quantization sensitivity of the nodes on the terminal after sorting them. The higher the sorting order, the greater the quantization error introduced by the node.
When verbose=True, the print result is as follows:
==========================node==========================
Node cosine-similarity mse
--------------------------------------------------------
Conv_3 0.999009567957658 0.027825591154396534
MaxPool_2 0.9993462241612948 0.017706592209064044
Conv_6 0.9998359175828787 0.004541242333988731
MaxPool_5 0.9998616805443397 0.0038416787014844325
Conv_0 0.9999297948984 0.0019312848587735342
Gemm_19 0.9999609772975628 0.0010773885699633795
Conv_8 0.9999629625907311 0.0010301886404004807
Gemm_15 0.9999847687207736 0.00041888411550854263
MaxPool_12 0.9999853235024673 0.0004039733791544747
Conv_10 0.999985763659844 0.0004040437432614943
Gemm_17 0.9999913985912616 0.0002379088904350423
Return:
{'Conv_3': `{`'cosine-similarity': '0.999009567957658', 'mse': '0.027825591154396534'`}`,
'MaxPool_2': `{`'cosine-similarity': '0.9993462241612948', 'mse': '0.017706592209064044'`}`,
'Conv_6': `{`'cosine-similarity': '0.9998359175828787', 'mse': '0.004541242333988731'`}`,
'MaxPool_5': `{`'cosine-similarity': '0.9998616805443397', 'mse': '0.0038416787014844325'`}`,
'Conv_0': `{`'cosine-similarity': '0.9999297948984', 'mse': '0.0019312848587735342'`}`,
'Gemm_19': `{`'cosine-similarity': '0.9999609772975628', 'mse': '0.0010773885699633795'`}`,
'Conv_8': `{`'cosine-similarity': '0.9999629625907311', 'mse': '0.0010301886404004807'`}`,
'Gemm_15': `{`'cosine-similarity': '0.9999847687207736', 'mse': '0.00041888411550854263'`}`,
'MaxPool_12': `{`'cosine-similarity': '0.9999853235024673', 'mse': '0.0004039733791544747'`}`,
'Conv_10': `{`'cosine-similarity': '0.999985763659844', 'mse': '0.0004040437432614943'`}`,
'Gemm_17': `{`'cosine-similarity': '0.9999913985912616', 'mse': '0.0002379088904350423'`}`} ...}
- plot_acc_error
This is a function that quantifies a single node in a floating-point model and calculates the error between the output of this node in the model and the corresponding output in the floating-point model, generating a cumulative error curve.
Command Line Format:
hmct-debugger plot-acc-error MODEL_OR_FILE CALIBRATION_DATA --other options
You can view related parameters by using hmct-debugger plot-acc-error -h/--help.
Parameter Groups:
| Parameter Name | Description | Value Range | Optional/Required |
|---|---|---|---|
save_dir or -s | Purpose: Path to save the results. Description: Optional, specifies the path for saving the analysis results. | N/A | Optional |
calibrated_data | Purpose: Specifies calibration data. Description: Required, specifies the calibration data to be analyzed. | N/A | Required |
model_or_file | Purpose: Specifies the calibrated model. Description: Required, specifies the calibrated model to be analyzed. | N/A | Required |
quantize_node or -q | Purpose: Quantizes a specified node in the model and visualizes the cumulative error curve. Description: Optional parameter. Specifies the node in the model to be quantized, ensuring that all other nodes remain unquantized. The parameter can be a nested list to handle single or partial node quantization. Examples: - quantize_node=['Conv_2','Conv_9']: Quantizes Conv_2 and Conv_9 individually while keeping others unquantized. - quantize_node=[['Conv_2'],['Conv_9','Conv_2']]: Tests model cumulative error with both Conv_2 and Conv_9 quantized separately. - Special parameters: 'weight' and 'activation'. When: - quantize_node = ['weight']: Only quantizes weights, not activations. - quantize_node = ['activation']: Only quantizes activations, not weights. - quantize_node = ['weight','activation']: Weights and activations are quantized separately. Note: Both quantize_node and non_quantize_node cannot be None, one must be provided. | All nodes in the calibrated model. | Optional |
non_quantize_node or -nq | Purpose: Specifies the type of nodes for which to calculate cumulative error. Description: Optional parameter. Specifies nodes that should not be quantized, with all others quantized. Similar to quantize_node, it can be a nested list for single or partial node de-quantization. See the examples for quantize_node.Note: Both quantize_node and non_quantize_node cannot be None, one must be provided. | All nodes in the calibrated model. | Optional |
metric or -m | Purpose: Error measurement method. Description: Sets the way to compute model errors. | Options: 'cosine-similarity', 'mse', 'mre', 'sqnr', 'chebyshev' | Optional |
average_mode or -a | Purpose: Specifies the output mode for the cumulative error curve. Description: Defaults to False. If set to True, the average of the cumulative errors is returned as the result. | Options: True, False | Optional |
# Import the debug module
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir: str,
calibrated_data: str or CalibrationDataSet,
model_or_file: ModelProto or str,
quantize_node: List or str,
non_quantize_node: List or str,
metric: str = 'cosine-similarity',
average_mode: bool = False)
Analysis Result Display
1. Test the accumulated error of specific quantized nodes
- Specify a single node for quantization
Configuration: quantize_node=['Conv_2', 'Conv_90'], quantize_node is a single list.
API function usage:
# Import the debug module
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
quantize_node=['Conv_2', 'Conv_90'],
metric='cosine-similarity',
average_mode=False)
Command line usage:
hmct-debugger plot-acc-error calibrated_model.onnx calibrated_data -q ['Conv_2','Conv_90']
Description: When the quantize_node is a single list, for the specified quantize_node, each node in the quantize_node is quantized separately while keeping other nodes in the model unquantized. After obtaining the corresponding model, the error between the output of each node in the model and the corresponding node in the floating-point model is calculated, resulting in an accumulated error curve.
When average_mode = False:
When average_mode = True:
average_mode
The default value of average_mode is False. For some models, it is not possible to determine which quantization strategy is more effective based on the accumulated error curve. Therefore, average_mode needs to be set to True. In this mode, the average of the accumulated errors of the previous n nodes is used as the accumulated error of the nth node.
The specific calculation method is as follows, for example:
When average_mode=False, accumulate_error=[1.0, 0.9, 0.9, 0.8].
When average_mode=True, accumulate_error=[1.0, 0.95, 0.933, 0.9].
- Specify multiple nodes for quantization
Configuration: quantize_node=[['Conv_2'], ['Conv_2', 'Conv_90']], where quantize_node is a nested list
API usage:
# Import the debug module
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
quantize_node=[['Conv_2'], ['Conv_2', 'Conv_90']],
metric='cosine-similarity',
average_mode=False)
Command line usage:
hmct-debugger plot-acc-error calibrated_model.onnx calibration_data -q [['Conv_2'],['Conv_2','Conv_90']]
Description: When quantize_node is a nested list, for the quantize_node you set, each node specified in each sub-list of quantize_node is quantized while keeping other nodes in the model unquantized. After obtaining the corresponding model, calculate the error between the output of each node in the model and the corresponding node in the floating-point model, and obtain the corresponding cumulative error curve.
- partial_qmodel_0: Quantize only the Conv_2 node, other nodes are unquantized;
- partial_qmodel_1: Quantize both the Conv_2 and Conv_90 nodes, other nodes are unquantized.
When average_mode=False:
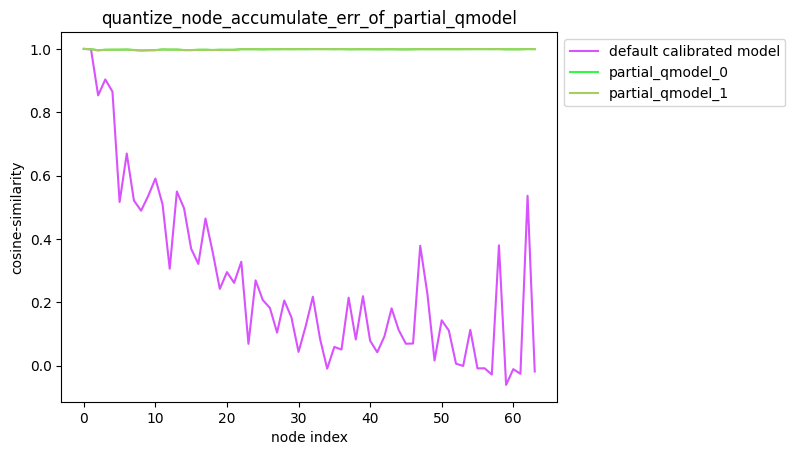
When average_mode=True:
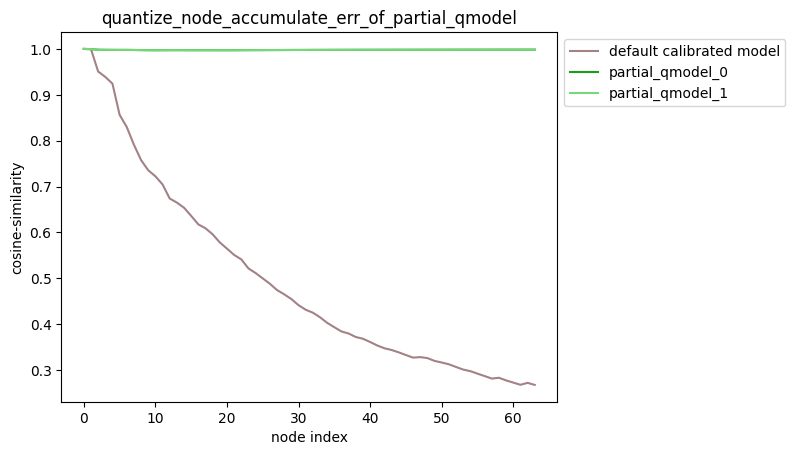
2. Accumulated error test after dequantizing partial nodes in the model
- Specify single nodes to be unquantized
Configuration: non_quantize_node=['Conv_2', 'Conv_90'], non_quantize_node is a single list.
API usage:
# Import the debug module
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
non_quantize_node=['Conv_2', 'Conv_90'],
metric='cosine-similarity',
average_mode=True)
Command line usage:
hmct-debugger plot-acc-error calibrated_model.onnx calibration_data -nq ['Conv_2','Conv_90'] -a True
Description: When non_quantize_node is a single list, for the non_quantize_node you set, each node specified in non_quantize_node is dequantized while keeping other nodes fully quantized. After obtaining the corresponding model,For each node in the model, calculate the error between its output and the corresponding output of the floating-point model, and obtain the cumulative error curve.
When average_mode = False:
When average_mode = True:
- Specifying multiple nodes as non-quantized
Configuration: non_quantize_node=[['Conv_2'], ['Conv_2', 'Conv_90']], where non_quantize_node is a nested list.
API usage:
# Import the debug module
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
non_quantize_node=[['Conv_2'], ['Conv_2', 'Conv_90']],
metric='cosine-similarity',
average_mode=False)
Command line usage:
hmct-debugger plot-acc-error calibrated_model.onnx calibration_data -nq [['Conv_2'],['Conv_2','Conv_90']]
Description: When non_quantize_node is a nested list, for the non_quantize_node you set, each single list in non_quantize_node specifies a node that is not quantized, while the rest of the nodes in the model are quantized. After obtaining the corresponding model, calculate the error between the output of each node in the model and the corresponding output of the floating-point model, and obtain the cumulative error curve.
-
partial_qmodel_0: Conv_2 node is not quantized, while the rest of the nodes are quantized;
-
partial_qmodel_1: Conv_2 and Conv_90 nodes are not quantized, while the rest of the nodes are quantized.
When average_mode = False:
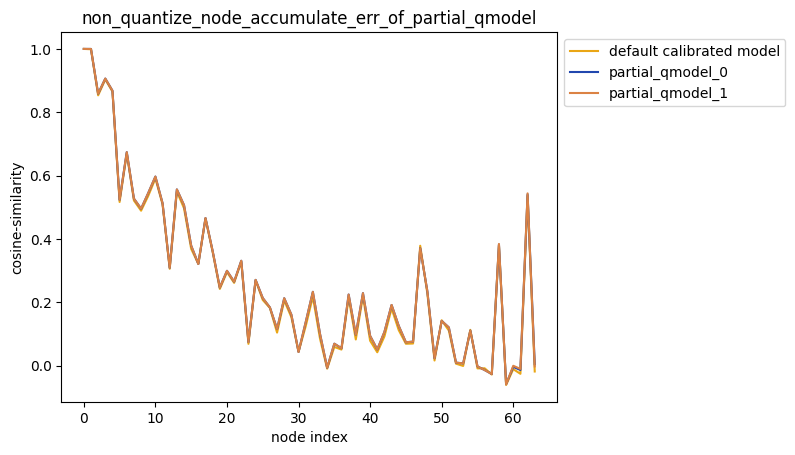 When
When average_mode = True:
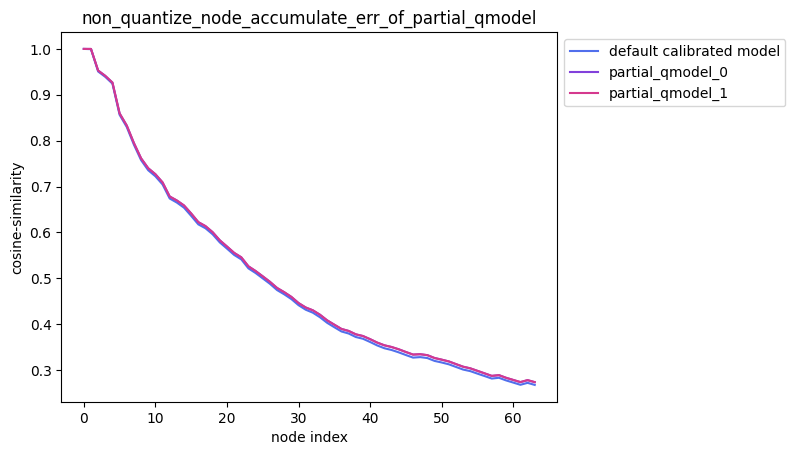
Testing Technique:
When quantifying accuracy in the testing phase, you may compare the accuracy of multiple quantization strategies based on their quantization sensitivity. You can refer to the following usage:
# Import the debug module
import horizon_nn.debug as dbg
# Firstly, use the quantization sensitivity sorting function to get the quantization sensitivity sorting of the nodes in the model
node_message = dbg.get_sensitivity_of_nodes(
model_or_file='./calibrated_model.onnx',
metrics='cosine-similarity',
calibrated_data='./calibration_data/',
output_node=None,
node_type='node',
verbose=False,
interested_nodes=None)
# Node_message is a dictionary, with its key being the name of the node
nodes = list(node_message.keys())
# Use `nodes` to specify the nodes that are not quantized, which can be easily used
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
non_quantize_node=[nodes[:1],nodes[:2]],
metric='cosine-similarity',
average_mode=True)
3. Quantize Activation and Weight Separately
Configuration Method: quantize_node=['weight','activation'].
API Usage:
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',quantize_node = ['weight', 'activation'],
metric = 'cosine-similarity',
average_mode = False)
Command-line usage:
hmct-debugger plot_acc_error calibrated_model.onnx calibration_data -q ['weight', 'activation']
Description: quantize_node can also directly specify 'weight' or 'activation'. When:
-
quantize_node = ['weight']: only quantize weights, do not quantize activations.
-
quantize_node = ['activation']: only quantize activations, do not quantize weights.
-
quantize_node = ['weight', 'activation']: quantize weights and activations separately.
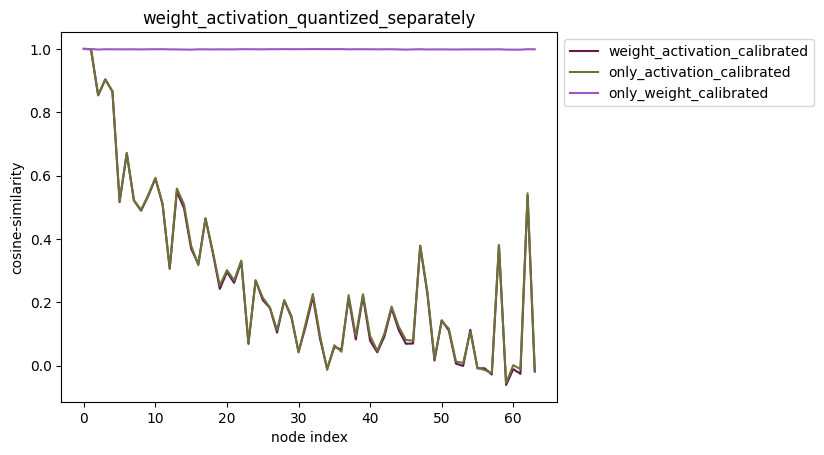
- plot_distribution
Function: Select nodes, obtain the outputs of the nodes in both the floating-point model and the calibrated model, and get the output data distribution. In addition, subtract the two output results to obtain the error distribution between the two outputs.
Command-line format:
hmct-debugger plot-distribution MODEL_OR_FILE CALIBRATION_DATA --other options
Use hmct-debugger plot-distribution -h/--help to view related parameters.
Parameter groups:
| Parameter Name | Parameter Configuration Explanation | Value Range Explanation | Optional/Required |
|---|---|---|---|
save_dir or -s | Parameter Function: Save directory. Parameter Explanation: Optional, specify the save path of the analysis results. | Value Range: None. Default Configuration: None. | Optional |
model_or_file | Parameter Function: Specify the calibrated model. Parameter Explanation: Required, specify the calibrated model to be analyzed. | Value Range: None. Default Configuration: None. | Required |
calibrated_data | Parameter Function: Specify the calibrated data. Parameter Explanation: Required, specify the calibration data required for analysis. | Value Range: None. Default Configuration: None. | Required |
nodes_list or -n | Parameter Function: Specify the nodes to be analyzed. Parameter Explanation: Required, specify the nodes to be analyzed. If the node type in nodes_list is: - Weight calibration node: Draw the data distribution of the original weights and the calibrated weights. - Activation calibration node: Draw the data distribution of the input of the activation calibration node. - Normal node: Draw the output data distribution of the node before and after quantization, and draw the error distribution between the two. Note: nodes_list is of type list, and a series of nodes can be specified, and the above three types of nodes can be specified at the same time. | Value Range: All nodes in the calibrated model. Default Configuration: None. | Required |
# Import the debug module
import horizon_nn.debug as dbg
dbg.plot_distribution(
save_dir: str,
model_or_file: ModelProto or str,
calibrated_data: str or CalibrationDataSet,
nodes_list: List[str] or str)
Analysis Result Display:
API Usage:
# Import the debug module
import horizon_nn.debug as dbg
dbg.plot_distribution(
save_dir='./',
model_or_file='./calibrated_model.onnx',
calibrated_data='./calibration_data',
nodes_list=['317_HzCalibration', # Activation node
'471_HzCalibration', # Weight node
'Conv_2']) # Regular node
Command Line Usage:
hmct-debugger plot-distribution calibrated_model.onnx calibration_data -n ['317_HzCalibration','471_HzCalibration','Conv_2']
node_output:
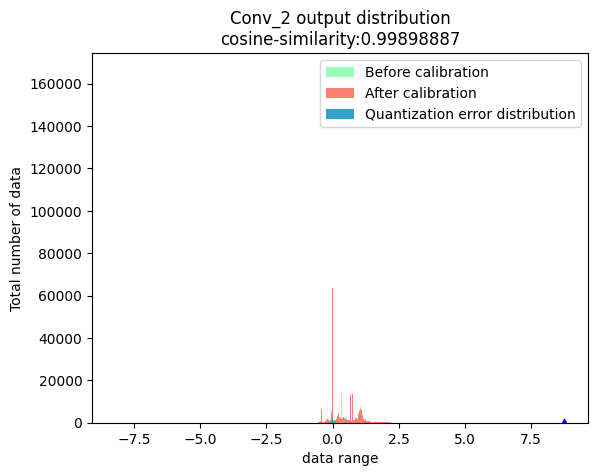
weight:
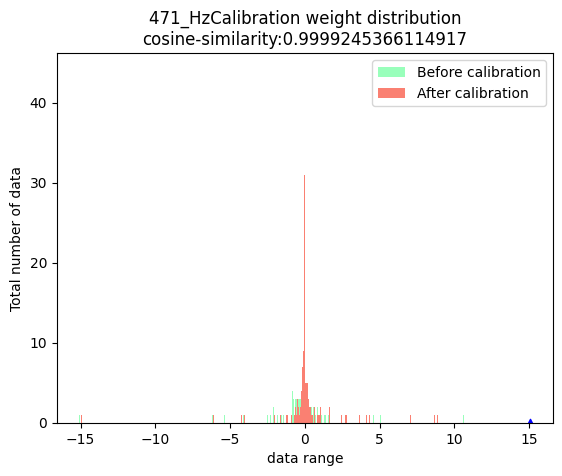
activation:
In the three graphs above, the blue triangles represent the maximum absolute value of the data. The red dashed line represents the minimum calibration threshold.
- get_channelwise_data_distribution****Function: Draw a box plot of the data distribution between specified calibration node input data channels.
Command line format:
hmct-debugger get-channelwise-data-distribution MODEL_OR_FILE CALIBRATION_DATA --other options
Related parameters can be viewed by hmct-debugger get-channelwise-data-distribution -h/--help.
Parameter group:
| Parameter Name | Parameter Configuration | Value Range Description | Optional/Required |
|---|---|---|---|
save_dir or -s | Parameter purpose: Save path. Parameter description: Optional, specify the save path for analysis results. | Value range: None. Default configuration: None. | Optional |
model_or_file | Parameter purpose: Specify the calibration model. Parameter description: Required, specify the calibration model to be analyzed. | Value Range: None. Default configuration: None. | Required |
calibrated_data | Parameter purpose: Specify the calibration data. Parameter description: Required, specify the calibration data required for analysis. | Value Range: None. Default configuration: None. | Required |
nodes_list or -n | Parameter purpose: Specify the calibration node. Parameter description: Required, specify the calibration node. | Value Range: All weight calibration nodes and activation calibration nodes in the calibration model. Default configuration: None. | Required |
axis or -a | Parameter purpose: Specify the dimension where the channel is located. Parameter description: The position of the channel information in the shape. The parameter defaults to None. For activation calibration nodes, the second dimension of the input data is assumed to represent the channel information, that is, axis=1; For weight calibration nodes, the axis parameter in the node attribute will be read as the channel information. | Value Range: Less than the dimension of the node input data. Default configuration: None. | Optional |
# Import debug module
import horizon_nn.debug as dbg
dbg.get_channelwise_data_distribution(
save_dir: str,
model_or_file: ModelProto or str,
calibrated_data: str or CalibrationDataSet,
nodes_list: List[str],
axis: int = None)
Analysis result display:
Description: For the calibration node list set by the user, the dimension of the channel is obtained from the parameter axis, and the data distribution between the input data channels of the node is obtained. The axis parameter defaults to None. If the node is a weight calibration node, the dimension where the channel is located is default to 0; if the node is an activation calibration node, the dimension where the channel is located is default to 1.
Weight calibration node:
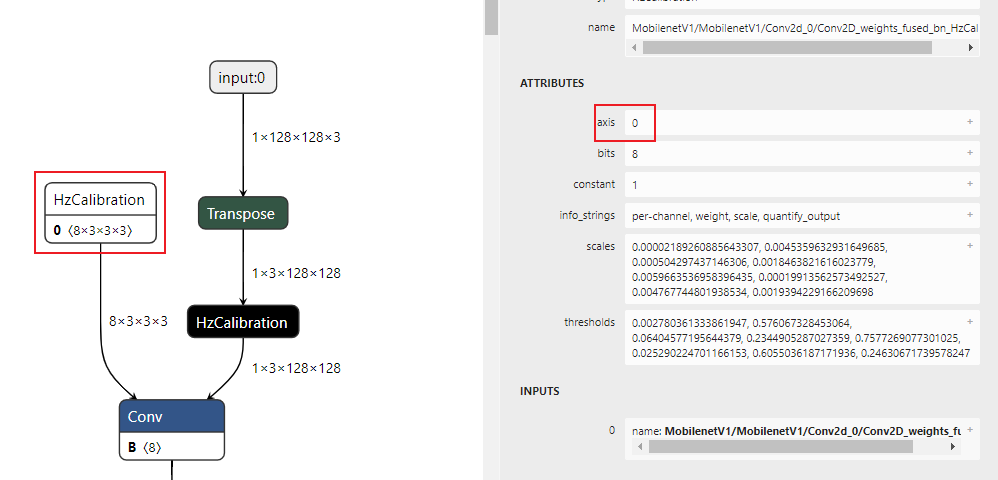
Activation calibration node:
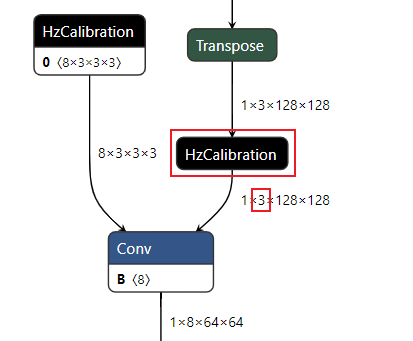
The output result is shown in the following figure:

Here's how the chart is structured:
-
The x-axis represents the number of channels in the input data nodes, with the legend indicating that there are 96 channels.
-
The y-axis shows the range of data distribution for each channel. The red solid line denotes the median of the channel data, while the blue dashed line indicates the mean.
-
runall
runall can be used on only RDK Ultra
Command Line Format:
hmct-debugger runall MODEL_OR_FILE CALIBRATION_DATA --other options
You can view related parameters using hmct-debugger runall -h/--help.
Parameter Groups:
| Parameter Name | Description | Value Range | Optional/Required |
|---|---|---|---|
model_or_file | Specifies the calibrated model. Description: Required, specifies the model to be analyzed. | N/A | Required |
calibrated_data | Specifies the calibration data. Description: Required, provides the data needed for analysis. | N/A | Required |
save_dir or -s | Specifies the save path. Description: Sets the path for saving the analysis results. | N/A | Optional |
ns_metrics or -nm | Measures node quantization sensitivity. Description: Defines the way to calculate node quantization sensitivity. It can be a list (List), calculating sensitivity in multiple ways but only the first method's result is sorted. A higher ranking indicates greater error introduced by quantizing the node. | Values: 'cosine-similarity', 'mse', 'mre', 'sqnr', 'chebyshev'.Default: 'cosine-similarity' | Optional |
output_node or -o | Specifies the output node. Description: Allows you to specify an intermediate node for output and calculate its quantization sensitivity. If left default (None), the precision debugger uses the model's final output to calculate sensitivity for all nodes. | N/A | Optional |
node_type or -nt | Node type. Description: The type of node to calculate sensitivity for, including: node (normal node), weight (weight calibration node), activation (activation calibration node). | Values: 'node', 'weight', 'activation'.Default: 'node' | Optional |
data_num or -dn | Number of data points for sensitivity calculation. Description: Sets the number of data points used for calculating node sensitivity. Defaults to None, using all data in calibration_data. Must be between 1 and the total number of calibration data points. | Range: Positive, less than or equal to the total calibration data count. Default: None | Optional |
verbose or -v | Enables terminal output. Description: If set to True, displays sensitivity information on the terminal. If metrics contains multiple measures, they are sorted based on the first one. | Values: True, False.Default: False | Optional |
interested_nodes or -i | Selects specific nodes of interest. Description: If specified, only retrieves sensitivity for the specified nodes, ignoring others. Takes priority over node_type if set. If left default (None), calculates sensitivity for all quantifiable nodes in the model. | N/A | Optional |
dis_nodes_list or -dnl | Analyzed nodes. Description: Specifies the nodes to analyze. For weight calibration nodes, it shows the original and calibrated weights distribution. For activation calibration nodes, it displays input data distribution. For normal nodes, it shows output data distribution before and after quantization, along with the error distribution. | N/A | Optional |
cw_nodes_list or -cn | Calibration nodes. Description: Specifies calibration nodes. | N/A | Optional |
axis or -a | Channel dimension. Description: Specifies the position of the channel information within the node's shape. Defaults to None, assuming axis=1 for activation calibration nodes, and reads the axis attribute from the node for weight calibration nodes. | Range: Less than the dimension of the node's input data. Default: None | Optional |
quantize_node or -qn | Quantizes specified nodes, showing cumulative error curves. Description: Optionally quantizes specified nodes, ensuring others remain unquantized. The parameter is a nested list to determine single-node or partial quantization. Examples: quantize_node=['Conv_2','Conv_9'], quantize_node=[['Conv_2'],['Conv_9','Conv_2']]. Special values: 'weight' and 'activation'.Range: All nodes in the calibrated model. Default: None | Optional | |
non_quantize_node or -nqn | Specifies nodes not to quantify for cumulative error calculation. Description: Optionally excludes specified nodes from quantization, ensuring all others are quantized. Follows similar logic as quantize_node with a nested list.Range: All nodes in the calibrated model. Default: None | Optional | |
ae_metric or -am | Cumulative error measurement. Description: Specifies the method for calculating model error. | Values: 'cosine-similarity', 'mse', 'mre', 'sqnr', 'chebyshev'.Default: 'cosine-similarity' | Optional |
average_mode or -avm | Cumulative error curve output mode. Description: Defaults to False. If set to True, returns the average value of the cumulative error as the result. | Values: True, False.Default: False | Optional |
API Usage Example:
import horizon_nn.debug as dbg
dbg.runall(model_or_file='calibrated_model.onnx',
calibrated_data='calibration_data')
Command Line Usage Example:
hmct-debugger runall calibrated_model.onnx calibration_data
The runall workflow:

When all parameters are set to defaults, the tool performs the following steps:
- Calculates quantization sensitivity for weight and activation calibration nodes.
- Draws data distributions for the top 5 nodes from step 1 for weight and activation calibration.
- Creates box plots for channel-wise data distribution for the nodes from step 2.
- Plots cumulative error curves when quantizing weights and activations separately.
If node_type='node', the tool retrieves the top 5 nodes and their corresponding calibration nodes, displaying data distributions and box plots.
Based on previous optimization experience, this strategy covers most scenarios. If issues persist, follow the Precision Optimization Checklist to gather detailed model configuration information, ensure all troubleshooting steps have been completed, and report the filled checklist, the original float model file, and relevant configuration files to the D-Robotics support team or the D-Robotics Official Technical Community for further assistance.
Other Tool Usage Instructions
This section primarily introduces the usage of debugging tools other than model conversion tools. These tools assist developers in model modification, analysis, and data preprocessing tasks. The list of tools is as follows:
- hb_perf
- hb_pack
- hb_model_info
- hb_model_modifier
- hb_model_verifier
- hb_eval_preprocess
hb_perf Tool
hb_perf is a tool for analyzing the performance of D-Robotics's quantized mixed models.
- Usage
hb_perf [OPTIONS] BIN_FILE
- Command Line Arguments
hb_perf command-line arguments:
--version
Displays the version and exits.
-m
Followed by the model name. When specifying BIN_FILE as a packed model, only outputs information about the specified model.
--help
Displays help information.
- Output Explanation
The model information will be saved in the hb_perf_result folder in the current directory. There will be a subfolder with the same name as the model, containing an HTML file with its details. The directory structure would look like this example:
hb_perf_result/
└── mobilenetv1
├── mobilenetv1
├── mobilenetv1.html
├── mobilenetv1.png
├── MOBILENET_subgraph_0.html
├── MOBILENET_subgraph_0.json
└── temp.hbm
If the model was not compiled in debug mode (compiler_parameters.debug:True) during the build process, hb_perf may produce the following warning:
2021-01-12 10:41:40,000 WARNING bpu model don't have per-layer perf info.
2021-01-12 10:41:40,000 WARNING if you need per-layer perf info, please enable [compiler_parameters.debug:True] when using makertbin.
This warning indicates that per-layer performance information is not included in the subgraph information but does not affect the generation of overall model information.
"hb_pack" Tool
"hb_pack" is a tool used to package multiple mixed model (*.bin) files into one model file.
- Usage
hb_pack [OPTIONS] BIN_FILE1 BIN_FILE2 BIN_FILE3 -o comb.bin
- Command Line Options
Command line options for hb_pack
--version
Display version and exit.
-o, --output_name
The output name for the packed model.
--help
Display help information.
- Output Description
The packed model will be output in the current directory folder, and the model will be named with the specified name "output_name". The compilation information and performance information of all sub-models in the packed model can be obtained through "hb_model_info" and "hb_perf".
Note that "hb_pack" does not support repackaging of a model that has already been packed. Otherwise, the workspace will generate the following prompt:
ERROR exception in command: pack
ERROR model: xxx.bin is a packed model, it can not be packed again!
"hb_model_info" Tool
"hb_model_info" is a tool used to parse the dependency and parameter information of the mixed model (*.bin) during compilation.
- Usage
hb_model_info $`{`model_file`}`
- Command Line Options
Command line options for hb_model_info
--version
Show version and exit.
-m
Followed by the model name. When BIN_FILE is specified as the pack model, only the model compilation information of the specified model will be output.
--help
Display help information.
- Description of Output
The output section will be some input information during model compilation, as shown below:
The version number information in the code block below will change with the release package version. This is only an example.
Start hb_model_info....
hb_model_info version 1.3.35
******** efficient_det_512x512_nv12 info *********
############# model deps info #############
hb_mapper version : 1.3.35
hbdk version : 3.23.3
hbdk runtime version: 3.13.7
horizon_nn version : 0.10.10
############# model_parameters info #############
onnx_model : /release/01_common/model_zoo/mapper/detection/efficient_det/efficientdet_nhwc.onnx
BPU march : bernoulli2
layer_out_dump : False
working dir : /release/04_detection/05_efficient_det/mapper/model_output
output_model_file_prefix: efficient_det_512x512_nv12
############# input_parameters info #############
------
---------input info : data ---------
input_name : data
input_type_rt : nv12
input_space&range : regular
input_layout_rt : None
input_type_train : rgb
input_layout_train : NCHW
norm_type : data_mean_and_scale
input_shape : 1x3x512x512
mean_value : 123.68,116.779,103.939,
scale_value : 0.017,
cal_data_dir : /release/04_detection/05_efficient_det/mapper/calibration_data_rgb_f32
---------input info : data end -------
------
############# calibration_parameters info #############
preprocess_on : False
calibration_type : max
############# compiler_parameters info #############hbdk_pass_through_params: --fast --O3
input-source : `{`'data': 'pyramid', '_default_value': 'ddr'`}`
--------- input/output types -
model input types : [<InputDataType.NV12: 7>]
model output types : [<InputDataType.F32: 5>, <InputDataType.F32: 5>, <InputDataType.F32: 5>, <InputDataTye.F32: 5>, <InputDataType.F32: 5>, <InputDataType.F32: 5>, <InputDataType.F32: 5>, <InputDataType.F32: 5>, <InputDataType.F32: 5>, <InpuDataType.F32: 5>]
When there are deleted nodes in the model, the names of the deleted nodes will be printed at the end of the model information output, and a file named "deleted_nodes_info.txt" will be generated, with each line recording the initial information of the corresponding deleted node. The names of the deleted nodes are shown below:
--------- deleted nodes -
deleted nodes: spconvretinanethead0_conv91_fwd_chw_HzDequantize
deleted nodes: spconvretinanethead0_conv95_fwd_chw_HzDequantize
deleted nodes: spconvretinanethead0_conv99_fwd_chw_HzDequantize
deleted nodes: spconvretinanethead0_conv103_fwd_chw_HzDequantize
deleted nodes: spconvretinanethead0_conv107_fwd_chw_HzDequantize
deleted nodes: spconvretinanethead0_conv93_fwd_chw_HzDequantize
deleted nodes: spconvretinanethead0_conv97_fwd_chw_HzDequantize
deleted nodes: spconvretinanethead0_conv101_fwd_chw_HzDequantize
deleted nodes: spconvretinanethead0_conv105_fwd_chw_HzDequantize
deleted nodes: spconvretinanethead0_conv109_fwd_chw_HzDequantize
hb_model_modifier Tool
The hb_model_modifier tool is used to delete the Transpose, Quantize nodes on the input side and the Transpose, Dequantize, Cast, Reshape, Softmax nodes on the output side in the *.bin model.
The information of the deleted nodes is stored in the BIN model, and can be viewed using hb_model_info.
- The hb_model_modifier tool can only delete nodes that are adjacent to the model input or output. If there are other nodes after the node to be deleted, it cannot be deleted.
- The model node name should not include special characters such as ";" and "," as this may affect the use of the tool.
- The tool does not support processing the packed model, otherwise it will prompt:
ERROR pack model is not supported. - The nodes to be deleted will be deleted one by one in order, and the model structure will be dynamically updated. Before deleting the node, it will also check if the node is at the input or output of the model, so the deletion order of the nodes is important.
Since deleting specific nodes will affect the input of the model, the tool is only suitable for cases where there is only one path after the model input, as shown in the figure below.
- Usage
- View deletable nodes:
hb_model_modifier model.bin
- Delete a single specified node (node1 is taken as an example)
hb_model_modifier model.bin -r node1
- Delete multiple specified nodes (e.g., node1, node2, node3):
hb_model_modifier model.bin -r node1 -r node2 -r node3
- Delete nodes of a certain class (e.g., Dequantize):
hb_model_modifier model.bin --all Dequantize
- Delete multiple types of nodes (e.g., Reshape, Cast, Dequantize):
hb_model_modifier model.bin -a Reshape -a Cast -a Dequantize
- Combine usage:
hb_model_modifier model.bin -a Reshape -a Cast -a Dequantize -r node1 -r node2 -r node3
- Command line arguments
Command line arguments for hb_model_modifier
--model_file
The name of the runtime model file.
-r
Followed by the name of the node to be deleted. If multiple nodes need to be deleted, multiple -r options need to be specified.
-o
Followed by the name of the modified model output (only effective when -r option is used).
-a --all
Followed by the node type. Supports one-click deletion of all corresponding types. If multiple type nodes need to be deleted, multiple -a options need to be specified.
- Output description
If the tool is not followed by any parameters, it will print out the deletable nodes available (i.e., all Transpose, Quantize, Dequantize, Cast, Reshape, Softmax nodes located at the input and output positions in the model).
The Quantize node is used to quantize the input data of the model from float type to int8 type, and its calculation formula is as follows:
qx = clamp(round(x / scale) + zero\_point, -128, 127)
round(x) performs floating-point rounding, and the clamp(x) function clamps the data to integer values between -128 and 127. zero_point i#### `hb_model_verifiers the asymmetrical quantization zero point offset value, and for symmetrical quantization, zero_point = 0.
The reference implementation of C++ is as follows:
int64_t quantized_value =
static_cast/<int64_t/>(std::round(value / static_cast/<double/(scale)));
quantized_value = std::min(std::max(quantized_value, min_int_value), max_int_value);
The Dequantize node is used to dequantize the output data of type "int8" or "int32" back to "float" or "double" type, with the following formula:
deqx = (x - zero\_point) * scale
The reference implementation in C++ is as follows:
static_cast/<float/>(value) * scale
Currently, the tool supports deletion of the following:
- The input side nodes are not Quantize or Transpose nodes;
- The output side nodes are not Transpose, Dequantize, Cast, Reshape, or Softmax nodes.
The tool prints the following information:
hb_model_modifier resnet50_64x56x56_featuremap.bin
2022-04-21 18:22:30,207 INFO Nodes that can be deleted: ['data_res2a_branch1_HzQuantize_TransposeInput0', 'fc1000_reshape_0']
After specifying the "-r" option, the tool will print the type of this node in the model, the information of the node stored in the bin file, and notify that the specified node has been deleted:
hb_model_modifier resnet50_64x56x56_featuremap.bin -r data_res2a_branch1_HzQuantize_TransposeInput0
Node 'data_res2a_branch1_HzQuantize_TransposeInput0' found, its OP type is 'Transpose'
Node 'data_res2a_branch1_HzQuantize_TransposeInput0' is removed
modified model saved as resnet50_64x56x56_featuremap_modified.bin
Then, you can use the "hb_model_info" tool to view the information of the deleted nodes. The information will be printed at the end of the output, and a "deleted_nodes_info.txt" file will be generated. Each line in the file records the initial information of the corresponding deleted node. The following shows the names of the deleted nodes that are printed:
hb_model_info resnet50_64x56x56_featuremap_modified.bin
Start hb_model_info....
hb_model_info version 1.7.0
********* resnet50_64x56x56_featuremap info *********
...
--------- deleted nodes -
deleted nodes: data_res2a_branch1_HzQuantize_TransposeInput0
hb_model_verifier Tool
The hb_model_verifier tool is used to verify the results of the specified quantized model and the runtime model.
This tool performs inference on the specified images using the quantized model, as well as the runtime model on the board and on the x86 simulator. If the IP address of the board is specified and the hrt_tools is installed on the board (if not, you can use the install.sh script under package/board in the toolchain SDK package to install it), the tool will also perform inference on the runtime model on the board. Similarly, if the host has installed hrt_tools (if not, you can use the install.sh script under package/host in the toolchain SDK package to install it), the tool will perform inference on the runtime model on the x86 host. After the inference, the tool compares the results of the three models pairwise and gives a conclusion of whether the results match. If no image is specified, the tool will use default images for inference (random tensor data will be generated for feature map models).
To obtain the package data package, please refer to the Deliverables Instructions.
- Usage
hb_model_verifier -q $`{`quanti_model`}` \
-b $`{`bin_model`}` \
-a $`{`board_ip`}` \
-i $`{`input_img`}` \
-d $`{`digits`}`
- Command-line Arguments
Command-line arguments of hb_model_verifier
-quanti_model, -q
Name of the quantized model.
--bin_model, -b
Name of the bin model.
--arm-board-ip, -a
IP address of the ARM board used for on-board testing.
--input-img, -i
Image used for inference testing. If not specified, default images or random tensors will be used. For binary image files, the suffix should be .bin.
--compare_digits, -d
Number of decimal places to compare the inference results. If not specified, the tool will compare up to five decimal places by default.
- Output Explanation
The results of the comparisons will be displayed in the terminal. The tool compares the ONNX model results, the simulator results, and the on-board results pairwise. If everything is fine, it should display the following:
Quanti onnx and Arm result Strict check PASSED
If there are inconsistencies between the quantized model and the runtime model, the specific information of the inconsistencies will be output.
The mismatch line num indicates the number of inconsistencies between the two types of models, including three types of inconsistencies:mismatch.line_miss num is the number of instances where the output results are inconsistent.
mismatch.line_diff num is the number of instances where the difference between the output results is significant.
mismatch.line_nan num is the number of instances where the output results are NaN.
total line num is the total number of output data.
mismatch rate is the ratio of inconsistent data instances to the total number of output data.
INFO mismatch line num: 39
INFO ****************************
INFO mismatch.line_miss num: 0
INFO mismatch.line_diff num: 39
INFO mismatch.line_nan num: 0
INFO ****************************
INFO total line num: 327680
INFO mismatch rate: 0.0001190185546875
hb_model_verifiercurrently only supports single-input models.- If the model has multiple outputs, only the results of the first output will be compared.
- Validating already-packed *.bin models is not supported yet, otherwise the following prompt will be displayed in the workspace:
ERROR pack model is not supported
hb_eval_preprocess Tool
Used for preprocessing image data in an x86 environment before evaluating model accuracy. Preprocessing refers to specific operations on image data before inputting it into the model. For example: resizing, cropping, and padding of image data.
- Usage
hb_eval_preprocess [OPTIONS]
- Command-line Options
Command-line options for hb_eval_preprocess
--version
Display version and exit.
-m, --model_name
Set the model name. Check the supported model ranges by using hb_eval_preprocess --help.
-i, --image_dir
Input image path.
-o, --output_dir
Output directory.
-v, --val_txt
Set the file name of the images required for evaluation. The preprocessed images will correspond to the image names in this file.
-h, --help
Display help information.
- Output content description
The "hb_eval_preprocess" command will generate image binary files in the directory specified by "--output_dir".
For more examples of using the "hb_eval_preprocess" tool in on-board model accuracy evaluation, please refer to the Data Preprocessing section in the "General Model Evaluation Instructions" of Embedded Application Development.