文本图片特征检索
功能介绍
CLIP 是由OpenAI提出的一种多模态机器学习模型。该模型通过对大规模图像和文本对进行对比学习, 能够同时处理图像和文本, 并将它们映射到一个共享的向量空间中。本示例展示在RDK平台上利用CLIP进行图片管理与文本搜图的功能。
代码仓库: (https://github.com/D-Robotics/hobot_clip.git)
应用场景:利用CLIP图像特征提取器, 对图片进行管理, 进行图文搜图, 以图搜图等。
项目组成
项目包含几个节点:
- clip_encode_image: 图像编码器边缘端推理节点, 支持两种模式:
- 本地模式:支持回灌输入, 输出图像编码特征。
- 服务模式:基于Ros Action Server, 支持Clinet节点发送推理请求, 计算返回的图像编码特征。
- clip_encode_text: 图像编码器边缘端推理节点, 支持两种模式:
- 本地模式:支持回灌输入, 输出文本编码特征。
- 服务模式:基于Ros Action Server, 支持Clinet节点发送推理请求, 计算返回的文本编码特征。
- clip_manage: CLIP中继节点, 负责收发, 支持两种模式:
- 入库模式:向图像编码节点 clip_encode_image 发送编码请求, 获取目标文件夹中图像编码特征, 将图像编码特征存储到本地SQLite数据库中。
- 检索模式:向文本编码节点 clip_encode_text 发送编码请求, 获取目标文本编码特征。进一步将文本特征与数据库图像特征进行匹配, 获得匹配结果。
- clip_msgs: CLIP系统的话题消息, action server的控制消息。
支持平台
| 平台 | 运行方式 | 示例功能 |
|---|---|---|
| RDK X5, RDK X5 Module | Ubuntu 22.04 (Humble) | · 启动CLIP 入库/检索, 入库结果保存在本地/检索结果显示在Web |
| RDK S100, RDK S100P | Ubuntu 22.04 (Humble) | · 启动CLIP 入库/检索, 入库结果保存在本地/检索结果显示在Web |
算法信息
| 模型 | 平台 | 输入尺寸 | 推理帧率(fps) |
|---|---|---|---|
| clip image encoder | X5 | 1x3x224x224 | 4.6 |
| clip image encoder | S100 | 1x3x224x224 | 166.92 |
准备工作
RDK平台
-
RDK已烧录好Ubuntu 22.04系统镜像。
-
RDK已成功安装TogetheROS.Bot。
依赖安装
pip3 install onnxruntime
pip3 install ftfy
pip3 install wcwidth
pip3 install regex
模型下载
# 从Web端下载运行示例需要的模型文件。
wget http://archive.d-robotics.cc/models/clip_encode_text/text_encoder.tar.gz
sudo tar -xf text_encoder.tar.gz -C config
使用介绍
RDK平台
模式1 入库
设置clip_mode为“0”, 将"/root/config"目录下的图片文件入库, 存在"clip.db"数据库中。
(用户可根据需要, 更换需要入库的图片文件夹路径clip_storage_folder、存放的数据库名clip_db_file, 建议使用绝对路径。)
- RDK X5
- RDK S100
# 配置ROS2环境
source /opt/tros/humble/setup.bash
# 从tros.b的安装路径中拷贝出运行示例需要的配置文件。
cp -r /opt/tros/${TROS_DISTRO}/lib/clip_encode_image/config/ .
# 启动launch文件
ros2 launch clip_manage hobot_clip_manage.launch.py clip_mode:=0 clip_db_file:=clip.db clip_storage_folder:=/root/config
# 配置ROS2环境
source /opt/tros/humble/setup.bash
# 从tros.b的安装路径中拷贝出运行示例需要的配置文件。
cp -r /opt/tros/${TROS_DISTRO}/lib/clip_encode_image/config/ .
# 启动launch文件
ros2 launch clip_manage hobot_clip_manage.launch.py clip_mode:=0 clip_image_model_file_name:=config/full_model_11.hbm clip_db_file:=clip.db clip_storage_folder:=/root/config
模式2 检索
设置clip_mode为“1”, 文本检索图片库clip.db, 输入文本为"a diagram", 检索结果存放在result目录下。
(用户可根据需要, 更换需要待检索的数据库名clip_db_file、待检索的文本名clip_text、检索结果路径clip_result_folder)
- RDK X5
- RDK S100
# 配置ROS2环境
source /opt/tros/humble/setup.bash
# 启动launch文件
ros2 launch clip_manage hobot_clip_manage.launch.py clip_mode:=1 clip_db_file:=clip.db clip_result_folder:=result clip_text:="a diagram"
# 配置ROS2环境
source /opt/tros/humble/setup.bash
# 启动launch文件
ros2 launch clip_manage hobot_clip_manage.launch.py clip_mode:=1 clip_image_model_file_name:=config/full_model_11.hbm clip_db_file:=clip.db clip_result_folder:=result clip_text:="a diagram"
检索结果可视化
打开另一个终端:启动Web服务查看检索结果, 确保index.html和检索结果result为同一级目录。
cp -r /opt/tros/${TROS_DISTRO}/lib/clip_manage/config/index.html .
python -m http.server 8080
结果分析
模式1 入库
入库成功终端日志:
[clip_manage-3] [WARN] [0000434374.492834334] [image_action_client]: Action client recved goal
[clip_manage-3] [WARN] [0000434374.493161250] [image_action_client]: Action client got lock
[clip_manage-3] [WARN] [0000434374.493402834] [image_action_client]: Sending goal, type: 1, urls size: 0
[clip_encode_image-1] [WARN] [0000434374.494557250] [encode_image_server]: Received goal request with type: 1
[clip_encode_image-1] [WARN] [0000434374.495408375] [encode_image_server]: Executing goal
[clip_encode_image-1] [WARN] [0000434379.674204836] [ClipImageNode]: Sub img fps: 1.58, Smart fps: 1.58, preprocess time ms: 1422, infer time ms: 218, post process time ms: 0
[clip_encode_image-1] [WARN] [0000434380.881684628] [ClipImageNode]: Sub img fps: 3.31, Smart fps: 3.31, preprocess time ms: 44, infer time ms: 216, post process time ms: 0
[clip_encode_image-1] [WARN] [0000434380.882277045] [encode_image_server]: Goal complete, task_result: 1
[clip_manage-3] [WARN] [0000434381.704573129] [image_action_client]: Get Result errorcode: 0
[clip_manage-3] [WARN] [0000434381.704934504] [ClipNode]: Storage finish, current num of database: 7.
模式2 检索
检索成功终端日志:
[clip_manage-3] [WARN] [0000435148.509009119] [ClipNode]: Query start, num of database: 7.
[clip_manage-3] [WARN] [0000435148.509820786] [ClipNode]: Query finished! Cost 1 ms.
[clip_encode_text_node-2] [WARN] [0000435148.514026703] [clip_encode_text_node]: Clip Encode Text Node work success.
[clip_manage-3] [WARN] [0000435148.532558536] [ClipNode]: Query Result config/CLIP.png, similarity: 0.289350
[clip_manage-3] [WARN] [0000435148.540040328] [ClipNode]: Query Result config/dog.jpg, similarity: 0.228837
[clip_manage-3] [WARN] [0000435148.547667078] [ClipNode]: Query Result config/target_class.jpg, similarity: 0.224744
[clip_manage-3] [WARN] [0000435148.555092286] [ClipNode]: Query Result config/target.jpg, similarity: 0.207572
[clip_manage-3] [WARN] [0000435148.562450494] [ClipNode]: Query Result config/raw_unet.jpg, similarity: 0.198459
[clip_manage-3] [WARN] [0000435148.569500536] [ClipNode]: Query Result config/people.jpg, similarity: 0.174074
[clip_manage-3] [WARN] [0000435148.576885453] [ClipNode]: Query Result config/test.jpg, similarity: 0.174074
[clip_manage-3] [WARN] [0000435148.584450703] [text_action_client]: Get Result errorcode: 0
检索结果可视化
在PC端的浏览器输入http://IP:8080 即可查看图像检索结果(IP为设备IP地址)。
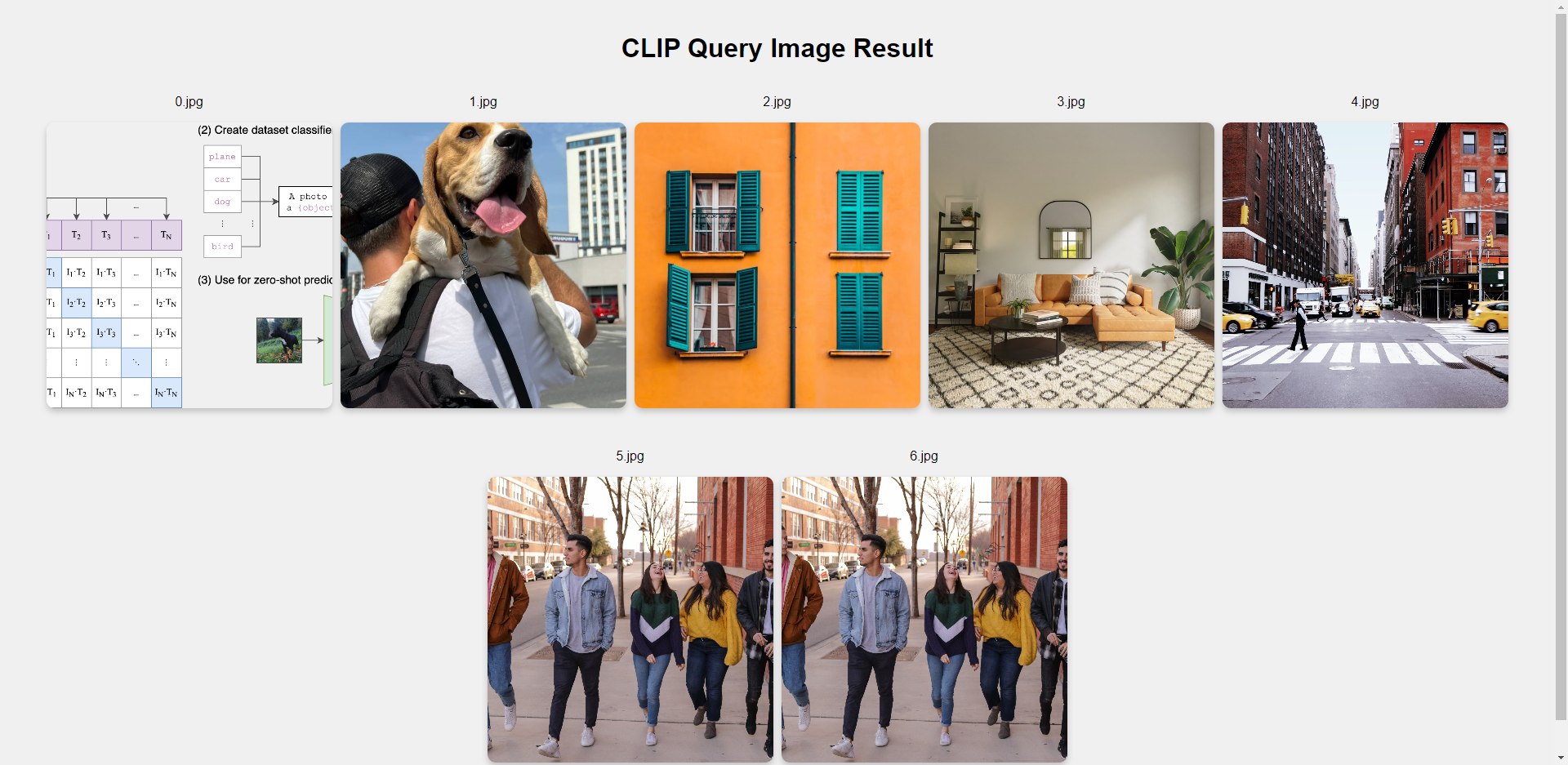
结果分析:按顺序依次可以看到检索文本与图片相似度依次检索结果。其中只有CLIP.png图片为本示例提供, 其他�图片为用户实际config中图片, 因此预期可视化结果中只有首张图与示例中相同。