Sunrise camera 开发说明
Sunrise camera 系统设计
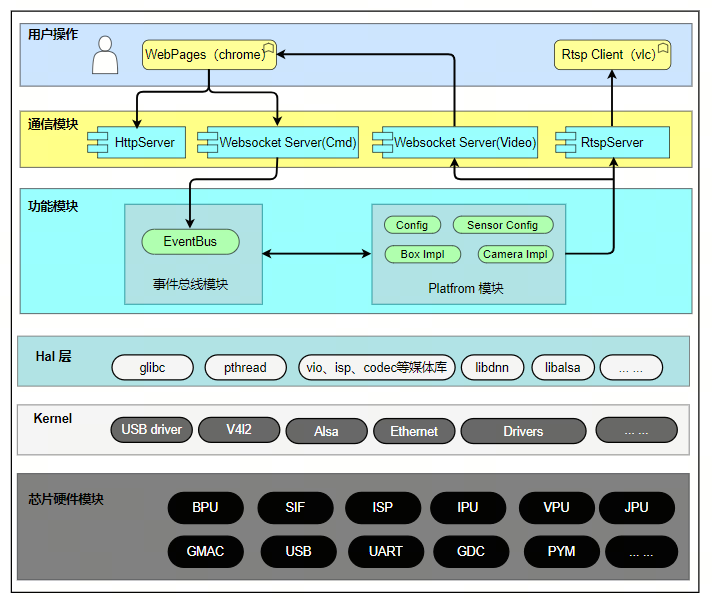
系统框图
Sunrise camera 实现了智能摄像机、智能分析盒等多种应用方案。
Sunrise camera 源码包括用户操作层的 WebPages、通信模块层、功能模块层;本文档主要介绍这三个模块的设计。
Hal 层模块包括多媒体相关模块调用接口库, BPU 模块推理库等;
Kernel 版本包含标准驱动库的基础上,系统 BSP。
软件框图如下所示:
��微核设计
微核架构( microkernel architecture )又称为“插件架构”( plug-in architecture ),指的是软件的内核相对较小,主要功能和业务逻辑都通过插件实现。
内核( core )通常只包含系统运行的最小功能。插件则是互相独立的,插件之间的通信,应该减少到最低,避免出现互相依赖的问题。
架构优缺点
优点
良好的功能延伸性,需要什么功能,开发插件即可。
功能之间是隔离的,插件可以独立的加载和卸载,容易部署。
可定制性高,适应不同的开发需要。
可以渐进式开发,逐步添加功能。
缺点
扩展性差,内核通常是一个独立单元,不容易做成分布式。
开发难度相对较高,因为涉及到插件与内核的通信,以及插件登记。
Sunrise camera 架构视图
模块划分
| 模块 | 目录 | 描述 |
|---|---|---|
| 事件总线模块 | communicate | 实现模块的事件注册、事件接收、事件分发 |
| 公共库模块 | common | 公共操作函数, log/lock,线程操作,队列操作等 |
| Camera 模块 | Platform | 芯片平台相关代码,实现硬件差异部分的封装 |
| 对外交互模块 | Transport | 设备和外接交互部分, rtspserver、 websocket 等 |
| 主程序入口 | Main | Main 函数入口 |
顶层代码结构
.
├── common # 公共库模块代码
├── communicate # 事件总线模块
├── config # 编译配置目录
├── main # 主入口程序
├── Makefile # 编译脚本
├── makefile.param # 编译配置
├── Platform # Camera 模块,平台、应用场景代码,芯片 IP 相关代码都在本目录下实现
├── start_app.sh # 启动脚本
├── sunrise_camera.service # 开启自启动配置文件
├── third_party # 依赖的第三方库
├── Transport # rtspserver 和 websocket 模块代码实现
├── VERSION # 版本信息
└── WebServer # web 页面的程序和资源文件
编译
- 登录设备,进入目录:
/app/multimedia_samples/sunrise_camera - 执行命令:
make - 生成的目标文件:
sunrise_camera
root@ubuntu:/app/multimedia_samples/sunrise_camera# ls sunrise_camera/bin/
log sunrise_camera www
事件总线模块( communicate )
概述
事件总线模块,最小运行单位;根据编译选项调用不同模块的注册接口函数,并且完成不同模块 CMD 的接收和分发。
当模块间交互时,接收到的 CMD 如果已经注册和使能,则中转到受理子模块处理,处理完成后向请求模块返回处理结果。
当模块间交互时,接收到的 CMD 没有注册或者未使能,则 CMD 调用失败。
功能描述
- 模块插件静态插拔控制
- 模块 CMD 指令中转
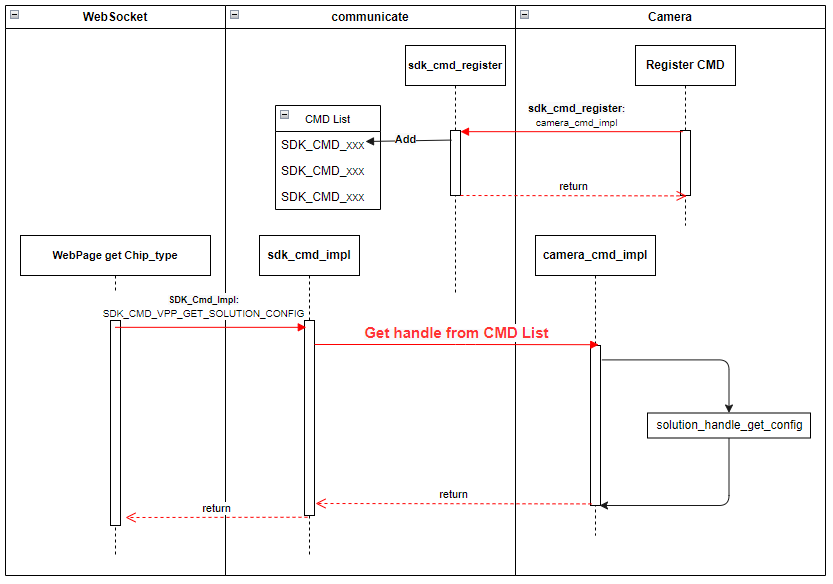
示例:
camera 子模块中定义了 SDK_CMD_CAMERA_GET_CHIP_TYPE 命令,调用 camera_cmd_register 函数注册该 CMD 后,当 websocket 子模块收到 web 页面请求获取芯片类型时, websocket 模块可以通过以下代码调用 camera 子模块中的接口。
整个过程如下图所示:
模块代码结构
.
├── include
│ ├── sdk_common_cmd.h # 定义系统中所有子模块的 CMD
│ ├── sdk_common_struct.h # 定义每个 CMD 对应使用到的数据结构
│ └── sdk_communicate.h # 定义本模块接口函数
├── Makefile
└── src
└── sdk_communicate.c # 接口代码实现
接口描述
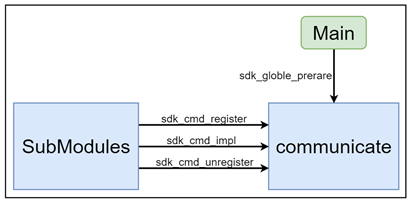
sdk_globle_prerare
各子模块的 xxx_cmd_register() 函数会集中放到这个函数中,主程序启动时,通过调用本接口将所有子模块需要注册并使能的的 CMD 注册进子系统中。
每个子模块都要实现 xxx_cmd_register(),在该函数中实现子模块 CMD 注册。这是整个系统能够正常运行的基本前提。
示例:
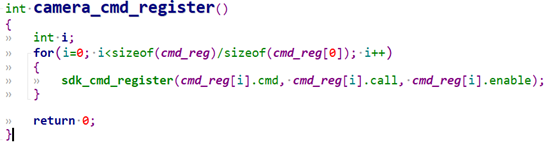
sdk_cmd_register
CMD 注册接口。
sdk_cmd_unregister
CMD 注销接口。
sdk_cmd_impl
子模��块通过调用本接口实现调用其他子模块实现的接口功能。
公共库模块( common )
概述
程序公共库类,包含但不限于日志操作、锁操作、线程封装、base64 ;
本模块主要把编程中会使用到的公共类、公共函数进行封装;避免相同操作的函数实现在多处出现。
本模块的更新影响所有模块,需要谨慎操作。
功能描述
无
模块代码结构
.
├── Makefile # 编译脚本
├── makefile.param
└── utils
├── include # 头文件
│ ├── aes256.h
│ ├── base64.h
│ ├── cJSON_Direct.h
│ ├── cmap.h
│ ├── common_utils.h
│ ├── cqueue.h
│ ├── gen_rand.h
│ ├── lock_utils.h
│ ├── mqueue.h
│ ├── mthread.h
│ ├── nalu_utils.h
│ ├── sha256.h
│ ├── stream_define.h
│ ├── stream_manager.h
│ └── utils_log.h
├── Makefile
└── src # 实现源码
├── aes256.c
├── base64.c
├── cJSON_Direct.c
├── cmap.c
├── common_utils.c
├── cqueue.c
├── gen_rand.c
├── lock_utils.c
├── mqueue.c
├── mthread.c
├── nalu_utils.c
├── sha256.c
├── stream_manager.c
└── utils_log.c
Platform 模块
概述
模块主要包括:视频编码、 ISP 控制、图像控制、抓拍、视频输出、算法运算等。
本模块内部结构如下:
api_vpp 作为本模块入口,定义支持的 CMD 命令集;
solution_handle 完成应用配置读写、场景接口赋值;
vpp_camera_impl、 vpp_box_impl 实现应用场景功能;
vp_wrap 实现多媒体模块的接口封装;
bpu_wrap 模块实现算法推理接口和后处理方法的封装。
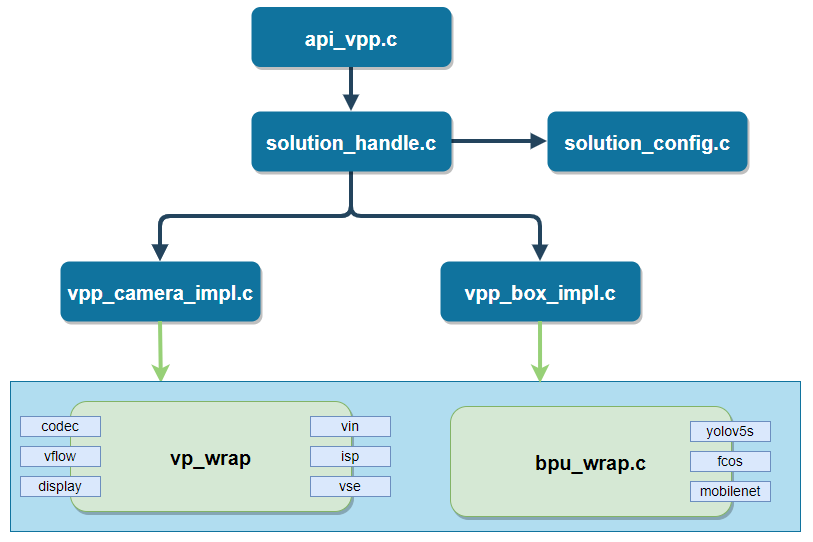
功能描述
新增一个应用场景的实现,只要实现 vpp_ops_t 结构体定义的接口即可。
typedef struct vpp_ops {
int (*init_param)(void); // 初始化 VIN、 VSE、 VENC、 BPU 等模块的配置参数
int (*init)(void); // sdk 初始化,根据配置初始化
int (*uninit)(void); // 反初始化
int (*start)(void); // 启动媒体相关的各个模块
int (*stop)(void); // 停止
// 本模块支持的 CMD 都通过以下两个接口简直实现
int (*param_set)(SOLUTION_PARAM_E type, char* val, unsigned int length);
int (*param_get)(SOLUTION_PARAM_E type, char* val, unsigned int* length);
} vpp_ops_t;
启动一个应用方案(以启动 vpp_camera 为例)的流程如下:
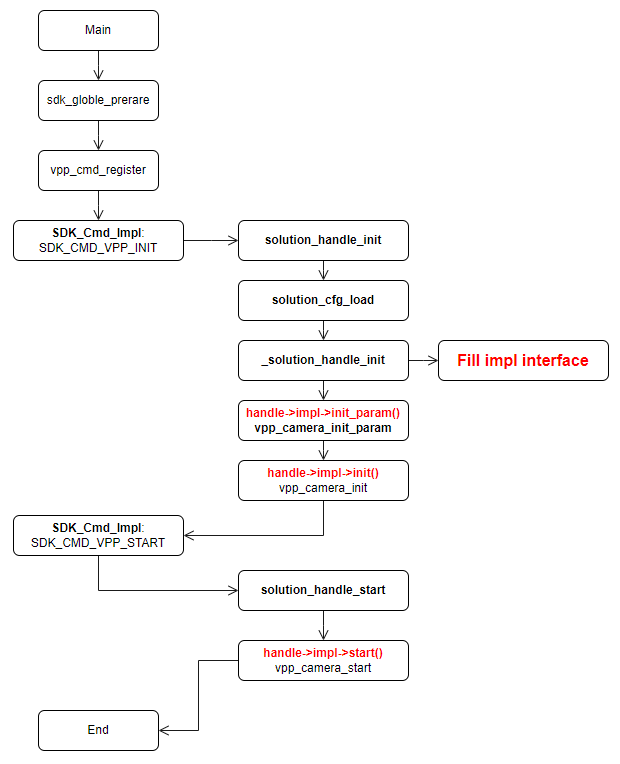
其他子模块的初始化、启动流程都可以参考本流程图。
模块代码结构
代码路径: Platform/S100
.
├── api # CMD 注册
├── bpu_wrap # bpu 算法接口使用封装
├── main # CMD 注册的实际功能接口实现
├── Makefile # 编译脚本
├── makefile.param # 编译配置
├── model_zoom # 算法模型仓库
├── test_data # 存放测试用的视频码流文件和程序配置文件
├── vpp_impl # 应用方案的功能实现
├── vp_sensors -> ../../../vp_sensors/ # Camera Sensor 配置代码,本目录下的代码与其他 sample 模块共用
└── vp_wrap # 多媒体接口的封装
对外交互模块( Transport )
概述
遵循传输协议与终端或平台交互的具体子模块;包含通过网络、 rtspserver 和 websocket 通信模块;
交互模块是模块间交互最多的部分,需要严格遵守设计约定。在向其他模块请求数据时都要通过定义的模块 CMD 进行处理。
Meida Server 模块
本模块是对 ZLMediakit 的封装实现,把 ZLMediakit 封装成 init、 create_media、push_video 等几个简单接口。目前支持 H264和H265 码流的推流。
本模块的启动和使用可以参考 主程序入口 章节的流程介绍。
Wesocket Server 模块
本模块完成与 web 上的操作交互,在 web 上进行相应操作后, websocket server 接收到相应 kind 的命令和参数,在代码 handle_user_massage.c 的 handle_user_msg 函数中处理进行相应的功能处理,如果要添加新的交互命令,请在该函数中增加。
目前支持的交互命令:场景切换、场景参数获取和设置、获取芯片类型、 h264 码率设置、系统时间同步、 websocket 码流拉流和停止等。
主程序入口( main )
概述
主程序入口,模块启动。
当前基本的子模块启动顺序如下,需要注意各模块启动顺序需要根据子模块间的依赖关系顺序启动。
执行流程
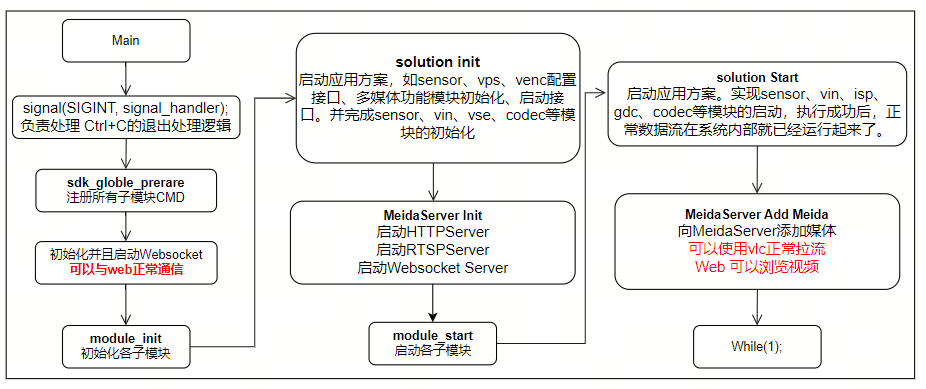
WebServer
概述
本模块通过 ZLMediakit 实现 HTTP协议的 web 服务,让用户可以直接通过浏览器预览视频和配置应用场景。
功能描述
WebServer/www目录下提供了: 资源文件、web 页面、 css、 js 程序。
使用 BPU 进行算法推理
概述
本模块完成算法模型加载、数据前处理、推理、算法后处理并返回 json 格式的结果。
模块运行时序如下:
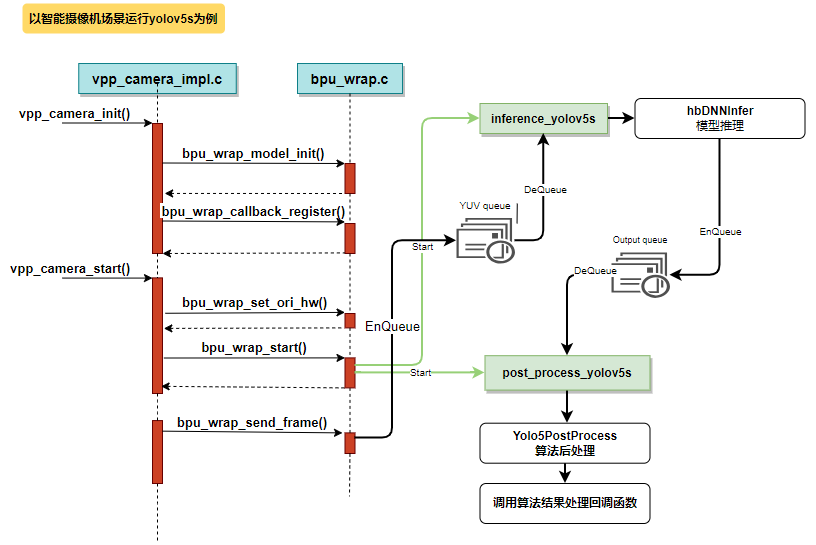
添加一个新模型流程
当前 sunrise_camera 仅支持少量算法模型的运行,在实际应用中不可避免要跑其他的模型来测试效果,本节描述新增一个算法模型的基本步骤。
| 项目 | 源码文件 | 说明 |
|---|---|---|
| 准备算法模型 | 放到 Platform/s100/model_zoom 目录下(*.hbm) | 在本目录添加可以在开发板上运行的定点算法模型 (系统自带的模型文文件存储在:/opt/hobot/model/s100/basic/) |
| 添加模型配置 | bpu_wrap.c | 在 bpu_models 中添加新模型的名称、指定算法模型文件,推理和后处理函数接口 |
| 推理线程处理函数 | bpu_wrap.c | 在处理函数中准备输出 tensor,调用 hbDNNInfer 推理,得到结果后,把结果放入 output 队列。示例:inference_yolov5s |
| 后处理线程函数 | bpu_wrap.c | 从 output 队列中取出算法结果,调用后处理方法进行处理,得到 json 格式的结果字符串。如果设置了回调函数,则调用回调。示例:post_process_yolov5s |
| 后处理代码 | yolov5_post_process.cpp | 算法模型都要对应后处理方法,比如分类模型要把返回的 id 和类型名对应起来,检测模型要把检测框映射到原始图像的位置上。 |
| Web 页面上增加渲染处理 | WebServer/www/js/DisplayWindowManager.js | 非必须 |
准备算法模型
开发板上支持运行的算法模型有两种后缀名, bin 文件和 hbm 文件:
- bin 模型:通过算法工具链转换( PTQ )得到的模型,以 bin 作为后缀
- hbm 模型:通过定点模型训练框架( QAT )直接训练得到的算法模型
算法模型的详细开发说明请参考《量化工具链开发指南》文档。
添加初始化过程
在 bpu_wrap.c 中的 bpu_models 数组中定义新的算法模型,添加新模型的名称、指定算法模型文件,推理和后处理函数接口:
bpu_model_descriptor bpu_models[] = {
{
.model_name = "yolov5s", // 算法名称, web 客户端上会显示这个名称给用户选择
.model_path = "../model_zoom/yolov5s_672x672_nv12.bin", // 算法模型文件
.inference_func = inference_yolov5s, // 推理函数
.post_proc_func = post_process_yolov5s // 后处理函数,如果这部分比较简单,可以合并到推理函数中一起处理
},
... ( 省略 ) ...
};
算法任务启动时,根据 model_name 启动相应的推理线程和算法后处理线程。
推�理线程处理函数
在推理线程中实现输出结果 tensor 的准备;从 yuv 队列中取出 yuv 数据,调用 HB_BPU_runModel 推理得到算法结果;再把算法结果推进 output Queue,供后处理使用。
static void *inference_yolov5s(void *ptr)
{
// 准备模型输出节点 tensor, 5 组输出 buff 轮转,简单处理,理论上后处理的速度是要比算法推理更快的
hbDNNTensor output_tensors[5][3];
int32_t cur_ouput_buf_idx = 0;
for (i = 0; i < 5; i++) {
ret = prepare_output_tensor(output_tensors[i], dnn_handle);
if (ret) {
SC_LOGE("prepare model output tensor failed");
return NULL;
}
}
while (privThread->eState == E_THREAD_RUNNING) {
// 获取需要进行算法运算的图像数据,格式基本都是 NV12 的 yuv
if (mQueueDequeueTimed(&bpu_handle->m_input_queue, 100, (void**)&input_tensor) != E_QUEUE_OK)
continue;
// 模型推理 infer
hbDNNInferCtrlParam infer_ctrl_param;
HB_DNN_INITIALIZE_INFER_CTRL_PARAM(&infer_ctrl_param);
ret = hbDNNInfer(&task_handle,
&output,
&input_tensor->m_dnn_tensor,
dnn_handle,
&infer_ctrl_param);
// 后处理数据入队
Yolo5PostProcessInfo_t *post_info;
post_info = (Yolo5PostProcessInfo_t *)malloc(sizeof(Yolo5PostProcessInfo_t));
… …
mQueueEnqueue(&bpu_handle->m_output_queue, post_info);
cur_ouput_buf_idx++;
cur_ouput_buf_idx %= 5;
}
}
后处理线程函数
后处理线程中实现从 output queue 中获取算法结果;调用后处理函数;调用算法任务回调函数处理算法结果(当前的回调有作用的都是直接发送给 web,在 web 上渲染算法结果)。
static void *post_process_yolov5s(void *ptr)
{
tsThread *privThread = (tsThread*)ptr;
Yolov5PostProcessInfo_t *post_info;
mThreadSetName(privThread, __func__);
bpu_handle_t *bpu_handle = (bpu_handle_t *)privThread->pvThreadData;
while (privThread->eState == E_THREAD_RUNNING) {
// 从后处理数据队列中获取数据
if (mQueueDequeueTimed(&bpu_handle->m_output_queue, 100, (void**)&post_info) != E_QUEUE_OK)
continue;
char *results = Yolov5PostProcess(post_info); // 进行后处理,比如得到检测框、过滤低置信度的结果、把检测框的宽高缩放为显示视频的宽高等
if (results) {
if (NULL != bpu_handle->callback) {
// 算法任务结果回调,当前的应用场景是把算法结果通过 websocket 发送给浏览器
bpu_handle->callback(results, bpu_handle->m_userdata);
} else {
SC_LOGI("%s", results);
}
free(results);
}
if (post_info) {
free(post_info);
post_info = NULL;
}
}
mThreadFinish(privThread);
return NULL;
}
后处理代码
每个算法模型建议都添加一个后处理方法:
- yolov5 : yolo5_post_process.cpp
- mobilenet_v2 :分类模型的处理较简单,就是把 id 和类型名进行对应
在后处理方法中要完成以下几件事情:
分析输出结果,分类模型要完成类型名的匹配,检测模型要完成算法结果框到原始图像坐标的映射等;
算法结果处理成 json 格式。为了方便使用,在函数中进行 json 格式化,比如传导给 web,这里输出的结果可以直接使用。
// Yolov5 输出 tensor 格式
// 3 次下采样得到三组缩小后的 gred,然后对每个 gred 进行三次预测,最后输出结果
char* Yolov5PostProcess(Yolov5PostProcessInfo_t *post_info) {
hbDNNTensor *tensor = post_info->output_tensor;
std::vector<Detection> dets;
std::vector<Detection> det_restuls;
uint32_t i = 0;
char *str_dets;
// 根据置信度过滤检测框
for (i = 0; i < default_yolov5_config.strides.size(); i++) {
_postProcess(&tensor[i], post_info, i, dets);
}
// 计算交并比来合并检测框,传入交并比阈值 (0.65) 和返回 box 数量 (5000)
yolov5_nms(dets, post_info->nms_threshold, post_info->nms_top_k, det_restuls, false);
std::stringstream out_string;
// 算法结果转换成 json 格式
out_string << "\"timestamp\": ";
unsigned long timestamp = post_info->tv.tv_sec * 1000000 + post_info->tv.tv_usec;
out_string << timestamp;
out_string << ",\"detection_result\": [";
for (i = 0; i < det_restuls.size(); i++) {
auto det_ret = det_restuls[i];
out_string << det_ret;
if (i < det_restuls.size() - 1)
out_string << ",";
}
out_string << "]" << std::endl;
str_dets = (char *)malloc(out_string.str().length() + 1);
str_dets[out_string.str().length()] = '\0';
snprintf(str_dets, out_string.str().length(), "%s", out_string.str().c_str());
return str_dets;
}
Web 页面上增加渲染处理
本部分非必须实现部分,在当前的实现中,所有算法结果会渲染到 web 页面上,数据流程是在算法后处理返回 json 格式的结果后,通过 websocket 发送结果信息给到 web 页面,在 web 实现了一个画布,在画布上渲染算法结果。
// 通用的算法回调函数,目前都是通过 websocket 想 web 上发送
int32_t bpu_wrap_general_result_handle(char *result, void *userdata)
{
int32_t ret = 0;
int32_t pipeline_id = 0;
char *ws_msg = NULL;
if (userdata)
pipeline_id = *(int*)userdata;
// json 算法结果添加标志信息
// 分配内存
ws_msg = malloc(strlen(result) + 32);
if (NULL == ws_msg) {
SC_LOGE("Failed to allocate memory for ws_msg");
return -1;
}
sprintf(ws_msg, "{\"kind\":10, \"pipeline\":%d,", pipeline_id + 1);
strcat(ws_msg, result);
strcat(ws_msg, "}");
ret = SDK_Cmd_Impl(SDK_CMD_WEBSOCKET_SEND_MSG, (void*)ws_msg);
free(ws_msg);
return ret;
}
在 WebServer/www/js/WebSocketProtocolHandler.js 文件中已经支持了通用的分类和目标检测的算法处理逻辑,如果需要渲染新类型算法模型的结果,需要修改 js 代码。
// web 页面上 websocket 接收数据的处理函数
handleMessage(event) {
{
... ( 省略 ) ...
try {
const message = JSON.parse(event.data);
if (message && message.kind) {
// 解析命令类型并调用对应的回调函数
switch (message.kind) {
... ( 省略 ) ...
case this.REQUEST_TYPES.ALOG_RESULT:
if (this.userCallbacks.onAlogResult) {
this.userCallbacks.onAlogResult(message);
}
break;
... ( 省略 ) ...
default:
console.warn(`未知的命令类型: kind=${message.kind}`);
}
}
} catch (error) {
console.error("消息解析失败:", error);
}
}
... ( 省略 ) ...
}