数据排布及对齐规则
数据排布
硬件内部为了提高计算效率,其数据使用特殊的排布方式以使得卷积运算中同一批次乘加用到的feature map和kernel在内存中相邻排放。 下面简要介绍D-Robotics 处理器中数据排布(layout)的概念。
神经网络模型中的变量可以用一个4维的张量表示,每个数字是这个张量中的元素,我们称之为自然排布。 将不同维度的不同元素按一定规则紧密排列在一起,形成一个独立的小块(block),然后将这些小块看成新的元素,组成新的4维张量, 我们称之为带有数据排布的张量。
输入输出数据会用到不同的layout数据排布,用户可通过API获取layout描述信息,不同的layout数据不可以直接比较。
需要注意的是,在进行数据排布转换时,如果需要padding,则padding的值建议设置为零。
此处介绍两种数据排布: NHWC_NATIVE 和 NCHW_NATIVE ,以 NHWC_NATIVE 为例,其数据排布如下:
| N0H0W0C0 | N0H0W0C1 | …… |
| N0H0W1C0 | N0H0W1C1 | …… |
| …… | …… | …… |
| N0H1W0C0 | N0H1W0C1 | …… |
| …… | …… | …… |
| N1H0W0C0 | N1H0W0C1 | …… |
| …… | …… | …… |
一个NHW*C大小的张量可用如下4重循环表示:
for (int32_t n = 0; n < N; n++) {
for (int32_t h = 0; h < H; h++) {
for (int32_t w = 0; w < W; w++) {
for (int32_t c = 0; c < C; c++) {
int32_t native_offset = n*H*W*C + h*W*C + w*C + c;
}
}
}
}
其中 NCHW_NATIVE 和 NHWC_NATIVE 相比,只是排布循环顺序不一样,此处不再单独列出。
下文中提到的native都特指该layout。
BPU对齐限制规则
本节内容介绍使用BPU的对齐限制规则。
模型输入要求
BPU不限制模型输入大小或者奇偶。既像YOLO这种416x416的输入可以支持,对于像SqueezeNet这种227x227的输入也可以支持。 对于NV12输入比较特别,要求HW都是偶数,是为了满足UV是Y的一半的要求。
对齐和有效数据
BPU对数据有对齐限制。对齐要求和真实的数据排布用 hbDNNTensorProperties 中的 validShape , alignedShape 和 stride 表示。
-
validShape是有效的shape; -
alignedShape是满足对齐要求的shape, 由于硬件特性,alignedShape均由四维数据表示; -
stride表示validShape各维度的步长,其中,NV12输入的模型比较特殊,其stride均为0,因为NV12输入的模型只要求W 16对齐。
目前四维模型的张量可以通过 validShape 和 alignedShape 获取正确的数据排布,若使用 RDK Ultra 模型中大于四维模型的张量可以通过 validShape 和 stride 获取正确的数据排布。
NV12介绍
YUV格式
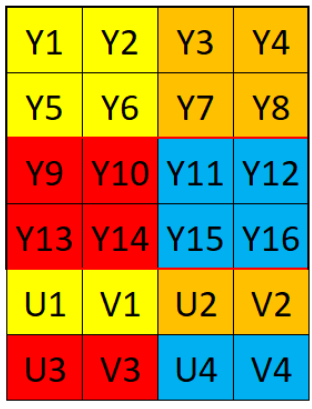
YUV格式主要用于优化彩色视频信号的传输。 YUV分为三个分量:Y表示明亮度,也就是灰度值;而U和V表示的则是色度,作用是描述影像色彩及饱和度,用于指定像素的颜色。
NV12排布
NV12图像格式属于YUV颜色空间中的YUV420SP格式,每四个Y分量共用一组U分量和V分量,Y连续排序,U与V交叉排序。
排列方式如下: